Utiliser un modèle prédéfini à partir de la galerie de modèles
Restez organisé à l'aide des collections
Enregistrez et classez les contenus selon vos préférences.
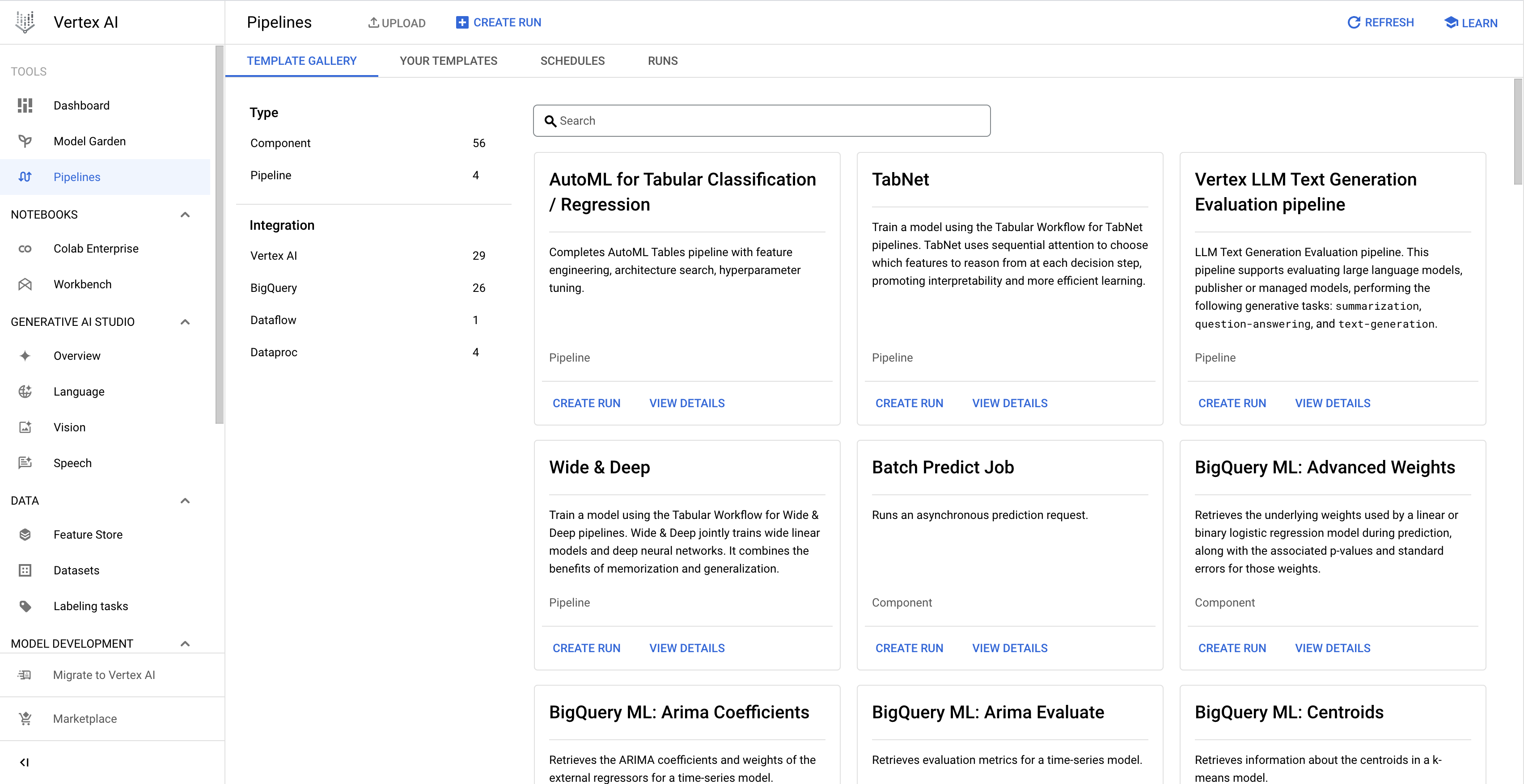
La galerie de modèles de Vertex AI Pipelines contient des modèles de pipeline et des composants conçus par Google, que vous pouvez utiliser pour créer des exécutions de pipeline ou les intégrer à vos propres pipelines.
Créer une exécution de pipeline à partir de la galerie de modèles
Suivez les instructions ci-dessous pour créer une exécution de pipeline à partir d'un modèle créé par Google à partir de la galerie de modèles. Vous pouvez également créer votre propre modèle de pipeline personnalisé, puis créer une exécution de pipeline basée sur celui-ci. Pour en savoir plus sur la création et l'utilisation d'un modèle de pipeline personnalisé, consultez la page Créer, importer et utiliser un modèle de pipeline.
Console
Suivez les instructions ci-dessous pour créer une exécution de pipeline à partir de la galerie de modèles:
Dans la console Google Cloud , dans la section Vertex AI, accédez à l'onglet Galerie de modèles sur la page Pipelines.
Facultatif: pour filtrer la liste des modèles de pipeline, dans le volet de gauche, sélectionnez les critères de filtre. Par exemple, pour n'afficher que les modèles de pipeline, sélectionnez Modèles sous Type.
Sur la fiche correspondant au modèle que vous souhaitez utiliser, cliquez sur Créer une exécution pour ouvrir la page Créer une exécution de pipeline.
Dans la section Détails de l'exécution, procédez comme suit :
(Facultatif) Modifiez le nom d'exécution par défaut qui identifie de manière unique l'exécution de pipeline.
Facultatif : pour planifier des exécutions récurrentes du pipeline, spécifiez la Planification d'exécution comme suit :
Sélectionnez Récurrente.
Sous Heure de début, indiquez à quel moment la planification devient active.
Pour planifier la première exécution immédiatement après la création de la programmation, sélectionnez Immédiatement.
Pour planifier la première exécution à une heure et une date spécifiques, sélectionnez Début.
Dans le champ Fréquence, spécifiez la fréquence de programmation et d'exécution du pipeline à l'aide d'une expression de programmation Cron basée sur unix-cron.
Sous Fin, indiquez le moment où la programmation se termine.
Pour indiquer que la programmation crée des exécutions du pipeline indéfiniment, sélectionnez Jamais.
Pour indiquer que la programmation se termine à une date et une heure spécifiques, sélectionnez Fin, puis spécifiez la date et l'heure de fin de la programmation.
Facultatif : pour spécifier que l'exécution du pipeline utilise un compte de service personnalisé, une clé de chiffrement gérée par le client (CMEK) ou un réseau VPC appairé, cliquez sur Options avancées, puis utilisez les instructions suivantes :
Pour spécifier un compte de service, sélectionnez-en un dans la liste déroulante Compte de service.
Si vous ne spécifiez pas de compte de service, Vertex AI Pipelines exécute votre pipeline à l'aide du compte de service Compute Engine par défaut.
Pour utiliser une CMEK, sélectionnez Utiliser une clé de chiffrement gérée par le client. La liste déroulante Sélectionner une clé gérée par le client s'affiche. Dans la liste déroulante Sélectionner une clé gérée par le client, choisissez la clé que vous souhaitez utiliser.
Pour utiliser un réseau VPC appairé dans ce pipeline exécuté, saisissez le nom du réseau VPC dans le champ Réseau VPC appairé.
Cliquez sur Continuer.
Dans la section Configuration de l'environnement d'exécution, configurez l'exécution du pipeline comme suit :
Sous Emplacement Cloud Storage, cliquez sur Parcourir pour sélectionner le bucket Cloud Storage où stocker les artefacts de sortie du pipeline, puis cliquez sur Sélectionner.
Facultatif : pour configurer la stratégie d'échec et le cache pour l'exécution du pipeline, cliquez sur Options avancées, puis suivez les instructions suivantes:
Pour configurer le pipeline de sorte qu'il continue à planifier des tâches après l'échec d'une tâche, sélectionnez Exécuter toutes les étapes du début à la fin. Cette option est sélectionnée par défaut.
Pour configurer le pipeline afin qu'il échoue après l'échec d'une tâche, sélectionnez Échouer cette exécution dès qu'une étape échoue.
Sous Configuration de la mise en cache, spécifiez la configuration du cache pour l'ensemble du pipeline.
Pour utiliser la configuration de cache au niveau des tâches pour le pipeline, sélectionnez Ne pas remplacer la configuration du cache au niveau des tâches.
Pour activer la mise en cache de toutes les tâches du pipeline et remplacer la configuration de cache au niveau des tâches, sélectionnez Activer la lecture à partir du cache pour toutes les étapes (plus rapide).
Pour désactiver la mise en cache de toutes les tâches du pipeline et remplacer la configuration de cache au niveau des tâches, sélectionnez Désactiver la lecture à partir du cache pour toutes les étapes (plus rapide).
Facultatif: si le pipeline comporte des paramètres, sous Paramètres du pipeline, spécifiez les paramètres d'exécution du pipeline.
Pour créer l'exécution de votre pipeline, cliquez sur Envoyer.
Sauf indication contraire, le contenu de cette page est régi par une licence Creative Commons Attribution 4.0, et les échantillons de code sont régis par une licence Apache 2.0. Pour en savoir plus, consultez les Règles du site Google Developers. Java est une marque déposée d'Oracle et/ou de ses sociétés affiliées.
Dernière mise à jour le 2025/09/04 (UTC).
[[["Facile à comprendre","easyToUnderstand","thumb-up"],["J'ai pu résoudre mon problème","solvedMyProblem","thumb-up"],["Autre","otherUp","thumb-up"]],[["Difficile à comprendre","hardToUnderstand","thumb-down"],["Informations ou exemple de code incorrects","incorrectInformationOrSampleCode","thumb-down"],["Il n'y a pas l'information/les exemples dont j'ai besoin","missingTheInformationSamplesINeed","thumb-down"],["Problème de traduction","translationIssue","thumb-down"],["Autre","otherDown","thumb-down"]],["Dernière mise à jour le 2025/09/04 (UTC)."],[],[],null,["The Vertex AI Pipelines **Template Gallery** contains Google-authored and components, which you can use to create pipeline runs or embed in your own pipelines.\n| **Note:** The **Template Gallery** contains pipeline templates and components that are generally available (GA) as well as templates in preview. To understand the terms of service of each template, refer to its associated documentation. For more information, see the [launch stage descriptions](https://cloud.google.com/products#product-launch-stages).\n\nCreate a pipeline run from the Template Gallery\n\nUse the following instructions to create a pipeline run from a Google-authored template from the **Template Gallery** . Alternatively, you can create your own custom pipeline template and then create a pipeline run based on it. For more information about creating and using a custom pipeline template, see [Create, upload, and use a pipeline template](/vertex-ai/docs/pipelines/create-pipeline-template). \n\nConsole**Note:** These instructions describe how to create a pipeline run using the default interface of the **Create pipeline run** page, which includes the **Run details** and the **Runtime configuration** sections. For some templates from the **Template gallery** , this page has additional sections. For example, the **AutoML for Tabular Classification / Regression** template also includes the **Training Method** , **Training options** , and **Compute and pricing** sections.\n\nUse the following instructions to create a pipeline run from the **Template Gallery**:\n\n1. In the Google Cloud console, in the **Vertex AI** section, go\n to the **Template Gallery** tab on the **Pipelines** page.\n\n [Go to Template Gallery](https://console.cloud.google.com/vertex-ai/pipelines/vertex-ai-templates)\n2. Optional: To filter the list of pipeline templates, in the left pane,\n select the filter criteria. For example, to show only pipeline templates,\n select **Templates** under **Type**.\n\n3. On the card corresponding to the template that you want to use, click\n **Create run** to open the **Create pipeline run** page.\n\n4. In the **Run details** section, do the following:\n\n 1. Optional: Modify the default **Run name** that uniquely identifies the pipeline run.\n\n 2. Optional: To schedule recurring pipeline runs, specify the **Run schedule**, as follows:\n\n 1. Select **Recurring**.\n\n 2. Under **Start time**, specify when the schedule becomes active.\n\n - To schedule the first run to occur immediately after schedule creation, select **Immediately**.\n\n - To schedule the first run to occur at a specific time and date, select **On**.\n\n 3. In the **Frequency** field, specify the frequency to schedule and execute the\n pipeline runs, using a cron schedule expression based on\n [unix-cron](https://man7.org/linux/man-pages/man5/crontab.5.html).\n\n 4. Under **Ends**, specify when the schedule ends.\n\n - To indicate that the schedule creates pipeline runs indefinitely, select **Never**.\n\n - To indicate that the schedule ends on a specific date and time, select **On**, and specify the end date and time for the schedule.\n\n 5. Optional: To specify that the pipeline run uses a custom service account, a\n customer-managed encryption key (CMEK), or a peered VPC network, click\n **Advanced options**, and then follow these instructions:\n\n - To specify a service account, select a service account from the\n **Service account** drop-down list.\n\n If you don't specify a service account,\n Vertex AI Pipelines runs your pipeline using the default\n Compute Engine service account.\n\n Learn more about [configuring a service account for use with\n Vertex AI Pipelines](/vertex-ai/docs/pipelines/configure-project#service-account).\n - To use a CMEK, select **Use a customer-managed encryption key** . The **Select a customer-managed key** drop-down list appears. In the **Select a customer-managed key** drop-down list, select the key that you want to use.\n\n - To use a peered VPC network in this pipeline run, enter the VPC\n network name in the **Peered VPC network** box.\n\n 3. Click **Continue**.\n\n5. In the **Runtime configuration** section, configure the pipeline run, as follows:\n\n 1. Under **Cloud storage location** , click **Browse** to select the\n Cloud Storage bucket for storing the pipeline output artifacts,\n and then click **Select**.\n\n 2. Optional: To configure the failure policy and the cache for the pipeline\n run, click **Advanced options**, and then use the following instructions:\n\n - Under **Failure policy** , specify the failure policy for the entire\n pipeline. [Learn more about pipeline failure policies.](/vertex-ai/docs/pipelines/configure-failure-policy)\n\n - To configure the pipeline to continue scheduling tasks after one task\n fails, select **Run all steps to completion**. This option is selected,\n by default.\n\n - To configure the pipeline to fail after one task fails, select\n **Fail this run as soon as one step fails**.\n\n - Under **Caching configuration**, specify the cache configuration for the\n entire pipeline.\n\n - To use the task-level cache configuration for task in the pipeline,\n select **Do not override task-level cache configuration**.\n\n - To turn on caching for all the tasks in the pipeline and override any\n task-level cache configuration, select\n **Enable read from cache for all steps (fastest)**.\n\n - To turn off caching for all the tasks in the pipeline and override any\n task-level cache configuration, select\n **Disable read from cache for all steps (fastest)**.\n\n 3. Optional: If your pipeline has parameters, under **Pipeline parameters**, specify\n your pipeline run parameters.\n\n6. To create your pipeline run, click **Submit**."]]