En este documento se describen los pasos necesarios para crear una canalización que entrene automáticamente un modelo personalizado de forma periódica o cuando se inserten datos nuevos en el conjunto de datos mediante Vertex AI Pipelines y funciones de Cloud Run.
Objetivos
Estos son los pasos que debes seguir:
Adquirir y preparar un conjunto de datos en BigQuery.
Crea y sube un paquete de entrenamiento personalizado. Cuando se ejecuta, lee los datos del conjunto de datos y entrena el modelo.
Crea un flujo de procesamiento de Vertex AI. Esta canalización ejecuta el paquete de entrenamiento personalizado, sube el modelo al registro de modelos de Vertex AI, ejecuta el trabajo de evaluación y envía una notificación por correo electrónico.
Ejecuta el flujo de trabajo manualmente.
Crea una función de Cloud con un activador de Eventarc que ejecute el flujo cada vez que se inserten datos nuevos en el conjunto de datos de BigQuery.
Antes de empezar
Configura tu proyecto y tu cuaderno.
Configuración del proyecto
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Crear cuaderno
Usamos un cuaderno de Colab Enterprise para ejecutar parte del código de este tutorial.
Si no eres el propietario del proyecto, pídele a uno que te conceda los roles de gestión de identidades y accesos
roles/resourcemanager.projectIamAdminyroles/aiplatform.colabEnterpriseUser.Necesitas estos roles para usar Colab Enterprise y para conceder roles y permisos de gestión de identidades y accesos a ti mismo y a las cuentas de servicio.
En la Google Cloud consola, ve a la página Cuadernos de Colab Enterprise.
Colab Enterprise te pedirá que habilites las siguientes APIs obligatorias si aún no lo has hecho.
- API de Vertex AI
- API de Dataform
- API de Compute Engine
En el menú Región, selecciona la región en la que quieras crear tu cuaderno. Si no lo tienes claro, usa us-central1 como región.
Usa la misma región para todos los recursos de este tutorial.
Haz clic en Crear un cuaderno.
El nuevo cuaderno aparecerá en la pestaña Mis cuadernos. Para ejecutar código en tu cuaderno, añade una celda de código y haz clic en el botón Ejecutar celda.
Configurar el entorno de desarrollo
En tu cuaderno, instala los siguientes paquetes de Python 3.
! pip3 install google-cloud-aiplatform==1.34.0 \ google-cloud-pipeline-components==2.6.0 \ kfp==2.4.0 \ scikit-learn==1.0.2 \ mlflow==2.10.0Para definir el proyecto de Google Cloud CLI, ejecuta el siguiente comando:
PROJECT_ID = "PROJECT_ID" # Set the project id ! gcloud config set project {PROJECT_ID}Sustituye PROJECT_ID por el ID del proyecto. Si es necesario, puede encontrar el ID de su proyecto en la Google Cloud consola.
Concede roles a tu cuenta de Google:
! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/bigquery.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.user ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/storage.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/pubsub.editor ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/cloudfunctions.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.viewer ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.configWriter ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/iam.serviceAccountUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/eventarc.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.colabEnterpriseUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/artifactregistry.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/serviceusage.serviceUsageAdminHabilita las siguientes APIs
- API de Artifact Registry
- API de BigQuery
- API de Cloud Build
- Cloud Functions API
- API de registro en la nube
- Pub/Sub API
- API Admin de Cloud Run
- API de Cloud Storage
- API de Eventarc
- API de Uso de Servicio
- API de Vertex AI
! gcloud services enable artifactregistry.googleapis.com bigquery.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com logging.googleapis.com pubsub.googleapis.com run.googleapis.com storage-component.googleapis.com eventarc.googleapis.com serviceusage.googleapis.com aiplatform.googleapis.comAsigna roles a las cuentas de servicio de tu proyecto:
Ver los nombres de tus cuentas de servicio
! gcloud iam service-accounts listAnota el nombre de tu agente de servicio de Compute. Debe tener el formato
xxxxxxxx-compute@developer.gserviceaccount.com.Asigna los roles necesarios al agente de servicio.
! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID-compute@developer.gserviceaccount.com"" --role=roles/aiplatform.serviceAgent ! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID-compute@developer.gserviceaccount.com"" --role=roles/eventarc.eventReceiver
Adquirir y preparar un conjunto de datos
En este tutorial, crearás un modelo que predice la tarifa de un viaje en taxi en función de características como el tiempo, la ubicación y la distancia del trayecto. Usaremos datos del conjunto de datos público Viajes en taxi de Chicago. Este conjunto de datos incluye viajes en taxi desde el 2013 hasta la actualidad, que se han comunicado a la ciudad de Chicago en su calidad de agencia reguladora. Para proteger la privacidad de los conductores y los usuarios del taxi al mismo tiempo y permitir que el agregador analice los datos, el ID del taxi se mantiene constante para cualquier número de licencia de taxi, pero no muestra el número. Además, los tramos censales se suprimen en algunos casos y las horas se redondean a los 15 minutos más cercanos.
Para obtener más información, consulta Viajes en taxi de Chicago en Marketplace.
Crear un conjunto de datos de BigQuery
En la Google Cloud consola, ve a BigQuery Studio.
En el panel Explorador, busque su proyecto, haga clic en Acciones y, a continuación, en Crear conjunto de datos.
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, introduce
mlops. Para obtener más información, consulta Nombres de conjuntos de datos.En Tipo de ubicación, elige tu multirregión. Por ejemplo, elige EE. UU. (varias regiones de Estados Unidos) si usas
us-central1. Una vez creado el conjunto de datos, la ubicación no se puede cambiar.Haz clic en Crear conjunto de datos.
Para obtener más información, consulta cómo crear conjuntos de datos.
Crear y rellenar una tabla de BigQuery
En esta sección, creará la tabla e importará un año de datos del conjunto de datos público al conjunto de datos de su proyecto.
Ir a BigQuery Studio
Haz clic en Crear consulta de SQL y ejecuta la siguiente consulta de SQL haciendo clic en Ejecutar.
CREATE OR REPLACE TABLE `PROJECT_ID.mlops.chicago` AS ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2019 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )Esta consulta crea la tabla
<PROJECT_ID>.mlops.chicagoy la rellena con datos de la tabla públicabigquery-public-data.chicago_taxi_trips.taxi_trips.Para ver el esquema de la tabla, haga clic en Ir a tabla y, a continuación, en la pestaña Esquema.
Para ver el contenido de la tabla, haz clic en la pestaña Vista previa.
Crear y subir el paquete de entrenamiento personalizado
En esta sección, crearás un paquete de Python que contenga el código que lee el conjunto de datos, divide los datos en conjuntos de entrenamiento y de prueba, y entrena tu modelo personalizado. El paquete se ejecutará como una de las tareas de tu flujo de trabajo. Para obtener más información, consulta el artículo sobre cómo crear una aplicación de entrenamiento de Python para un contenedor prediseñado.
Crear el paquete de entrenamiento personalizado
En tu cuaderno de Colab, crea carpetas principales para la aplicación de entrenamiento:
!mkdir -p training_package/trainerCrea un archivo
__init__.pyen cada carpeta para convertirla en un paquete con el siguiente comando:! touch training_package/__init__.py ! touch training_package/trainer/__init__.pyPuedes ver los nuevos archivos y carpetas en el panel de la carpeta Archivos.
En el panel Archivos, crea un archivo llamado
task.pyen la carpeta training_package/trainer con el siguiente contenido.# Import the libraries from sklearn.model_selection import train_test_split, cross_val_score from sklearn.preprocessing import OneHotEncoder, StandardScaler from google.cloud import bigquery, bigquery_storage from sklearn.ensemble import RandomForestRegressor from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from google import auth from scipy import stats import numpy as np import argparse import joblib import pickle import csv import os # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--project-id', dest='project_id', type=str, help='Project ID.') parser.add_argument('--training-dir', dest='training_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the data and the trained model.') parser.add_argument('--bq-source', dest='bq_source', type=str, help='BigQuery data source for training data.') args = parser.parse_args() # data preparation code BQ_QUERY = """ with tmp_table as ( SELECT trip_seconds, trip_miles, fare, tolls, company, pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude, DATETIME(trip_start_timestamp, 'America/Chicago') trip_start_timestamp, DATETIME(trip_end_timestamp, 'America/Chicago') trip_end_timestamp, CASE WHEN (pickup_community_area IN (56, 64, 76)) OR (dropoff_community_area IN (56, 64, 76)) THEN 1 else 0 END is_airport, FROM `{}` WHERE dropoff_latitude IS NOT NULL and dropoff_longitude IS NOT NULL and pickup_latitude IS NOT NULL and pickup_longitude IS NOT NULL and fare > 0 and trip_miles > 0 and MOD(ABS(FARM_FINGERPRINT(unique_key)), 100) between 0 and 99 ORDER BY RAND() LIMIT 10000) SELECT *, EXTRACT(YEAR FROM trip_start_timestamp) trip_start_year, EXTRACT(MONTH FROM trip_start_timestamp) trip_start_month, EXTRACT(DAY FROM trip_start_timestamp) trip_start_day, EXTRACT(HOUR FROM trip_start_timestamp) trip_start_hour, FORMAT_DATE('%a', DATE(trip_start_timestamp)) trip_start_day_of_week FROM tmp_table """.format(args.bq_source) # Get default credentials credentials, project = auth.default() bqclient = bigquery.Client(credentials=credentials, project=args.project_id) bqstorageclient = bigquery_storage.BigQueryReadClient(credentials=credentials) df = ( bqclient.query(BQ_QUERY) .result() .to_dataframe(bqstorage_client=bqstorageclient) ) # Add 'N/A' for missing 'Company' df.fillna(value={'company':'N/A','tolls':0}, inplace=True) # Drop rows containing null data. df.dropna(how='any', axis='rows', inplace=True) # Pickup and dropoff locations distance df['abs_distance'] = (np.hypot(df['dropoff_latitude']-df['pickup_latitude'], df['dropoff_longitude']-df['pickup_longitude']))*100 # Remove extremes, outliers possible_outliers_cols = ['trip_seconds', 'trip_miles', 'fare', 'abs_distance'] df=df[(np.abs(stats.zscore(df[possible_outliers_cols].astype(float))) < 3).all(axis=1)].copy() # Reduce location accuracy df=df.round({'pickup_latitude': 3, 'pickup_longitude': 3, 'dropoff_latitude':3, 'dropoff_longitude':3}) # Drop the timestamp col X=df.drop(['trip_start_timestamp', 'trip_end_timestamp'],axis=1) # Split the data into train and test X_train, X_test = train_test_split(X, test_size=0.10, random_state=123) ## Format the data for batch predictions # select string cols string_cols = X_test.select_dtypes(include='object').columns # Add quotes around string fields X_test[string_cols] = X_test[string_cols].apply(lambda x: '\"' + x + '\"') # Add quotes around column names X_test.columns = ['\"' + col + '\"' for col in X_test.columns] # Save DataFrame to csv X_test.to_csv(os.path.join(args.training_dir,"test.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Save test data without the target for batch predictions X_test.drop('\"fare\"',axis=1,inplace=True) X_test.to_csv(os.path.join(args.training_dir,"test_no_target.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Separate the target column y_train=X_train.pop('fare') # Get the column indexes col_index_dict = {col: idx for idx, col in enumerate(X_train.columns)} # Create a column transformer pipeline ct_pipe = ColumnTransformer(transformers=[ ('hourly_cat', OneHotEncoder(categories=[range(0,24)], sparse = False), [col_index_dict['trip_start_hour']]), ('dow', OneHotEncoder(categories=[['Mon', 'Tue', 'Sun', 'Wed', 'Sat', 'Fri', 'Thu']], sparse = False), [col_index_dict['trip_start_day_of_week']]), ('std_scaler', StandardScaler(), [ col_index_dict['trip_start_year'], col_index_dict['abs_distance'], col_index_dict['pickup_longitude'], col_index_dict['pickup_latitude'], col_index_dict['dropoff_longitude'], col_index_dict['dropoff_latitude'], col_index_dict['trip_miles'], col_index_dict['trip_seconds']]) ]) # Add the random-forest estimator to the pipeline rfr_pipe = Pipeline([ ('ct', ct_pipe), ('forest_reg', RandomForestRegressor( n_estimators = 20, max_features = 1.0, n_jobs = -1, random_state = 3, max_depth=None, max_leaf_nodes=None, )) ]) # train the model rfr_score = cross_val_score(rfr_pipe, X_train, y_train, scoring = 'neg_mean_squared_error', cv = 5) rfr_rmse = np.sqrt(-rfr_score) print ("Crossvalidation RMSE:",rfr_rmse.mean()) final_model=rfr_pipe.fit(X_train, y_train) # Save the model pipeline with open(os.path.join(args.training_dir,"model.joblib"), 'wb') as model_file: pickle.dump(final_model, model_file)El código realiza las siguientes tareas:
- Selección de funciones.
- Transformar la hora de recogida y entrega de los datos de UTC a la hora local de Chicago.
- Extraer la fecha, la hora, el día de la semana, el mes y el año de la fecha y hora de recogida.
- Calcula la duración del viaje usando la hora de inicio y la de finalización.
- Identificar y marcar los trayectos que han empezado o finalizado en un aeropuerto en función de las zonas comunitarias.
- El modelo de regresión de bosque aleatorio se entrena para predecir la tarifa del viaje en taxi mediante el framework scikit-learn.
El modelo entrenado se guarda en un archivo pickle
model.joblib.El enfoque y la ingeniería de funciones seleccionados se basan en la exploración y el análisis de datos de Predicción de la tarifa de los taxis de Chicago.
En el panel Archivos, crea un archivo llamado
setup.pyen la carpeta training_package con el siguiente contenido.from setuptools import find_packages from setuptools import setup REQUIRED_PACKAGES=["google-cloud-bigquery[pandas]","google-cloud-bigquery-storage"] setup( name='trainer', version='0.1', install_requires=REQUIRED_PACKAGES, packages=find_packages(), include_package_data=True, description='Training application package for chicago taxi trip fare prediction.' )En tu cuaderno, ejecuta
setup.pypara crear la distribución de origen de tu aplicación de entrenamiento:! cd training_package && python setup.py sdist --formats=gztar && cd ..
Al final de esta sección, el panel Archivos debe contener los siguientes archivos y carpetas en training-package.
dist
trainer-0.1.tar.gz
trainer
__init__.py
task.py
trainer.egg-info
__init__.py
setup.py
Sube el paquete de entrenamiento personalizado a Cloud Storage
Crea un segmento de Cloud Storage.
REGION="REGION" BUCKET_NAME = "BUCKET_NAME" BUCKET_URI = f"gs://{BUCKET_NAME}" ! gcloud storage buckets create gs://$BUCKET_URI --location=$REGION --project=$PROJECT_IDSustituye los siguientes valores de los parámetros:
REGION: elige la misma región que al crear el cuaderno de Colab.BUCKET_NAME: el nombre del segmento.
Sube tu paquete de entrenamiento al depósito de Cloud Storage.
# Copy the training package to the bucket ! gcloud storage cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/
Crear un flujo de procesamiento
Un flujo de procesamiento es una descripción de un flujo de trabajo de MLOps como un gráfico de pasos denominado tareas de flujo de procesamiento.
En esta sección, se definen las tareas de la canalización, se compilan en YAML y se registra la canalización en Artifact Registry para que se pueda controlar la versión y ejecutar varias veces, ya sea por un solo usuario o por varios.
Aquí se muestra una visualización de las tareas de nuestra canalización, que incluyen el entrenamiento del modelo, la subida del modelo, la evaluación del modelo y la notificación por correo electrónico:
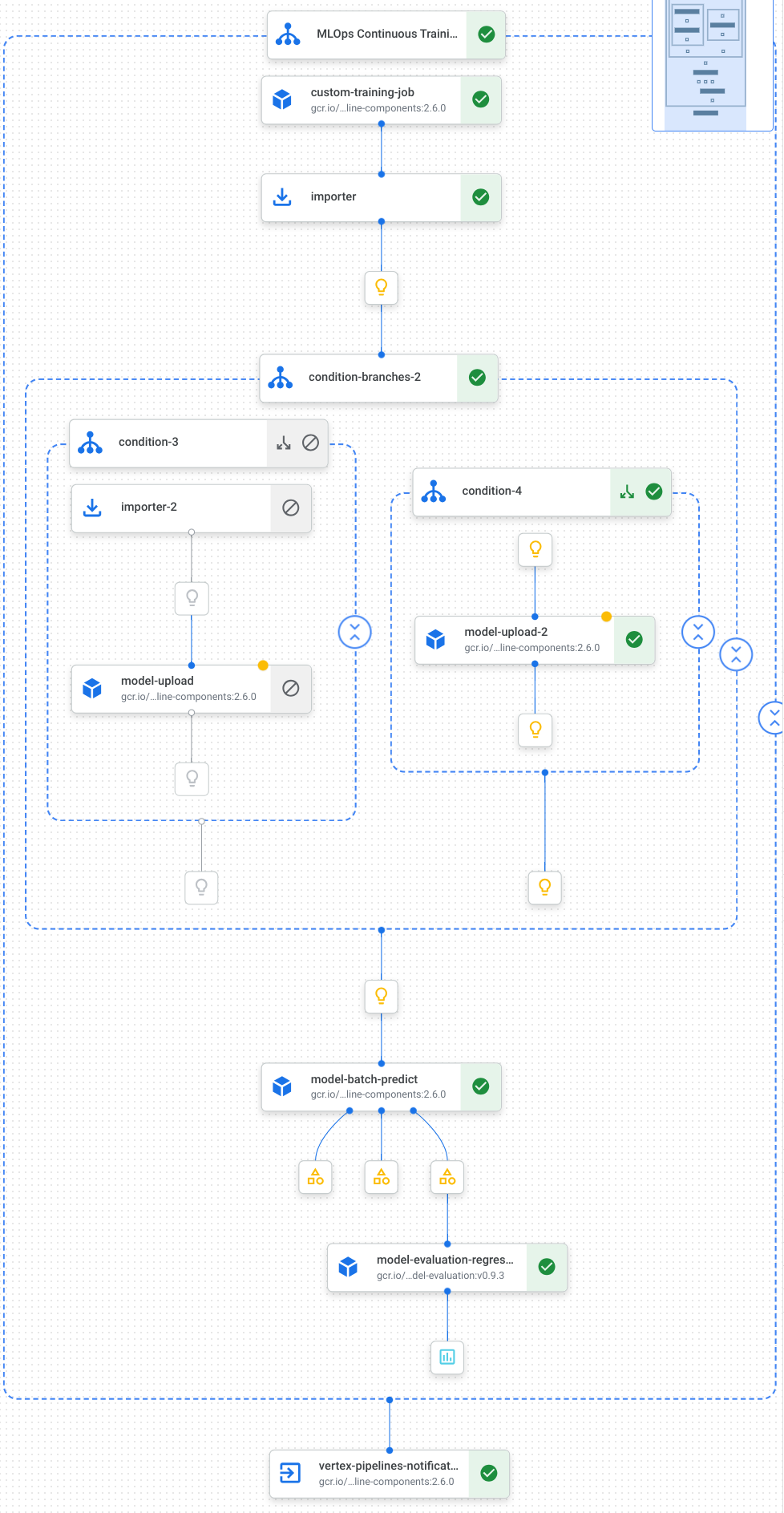
Para obtener más información, consulta cómo crear plantillas de canalizaciones.
Definir constantes e inicializar clientes
En tu cuaderno, define las constantes que se usarán en pasos posteriores:
import os EMAIL_RECIPIENTS = [ "NOTIFY_EMAIL" ] PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-pipeline-datatrigger-tutorial" WORKING_DIR = f"{PIPELINE_ROOT}/mlops-datatrigger-tutorial" os.environ['AIP_MODEL_DIR'] = WORKING_DIR EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" PIPELINE_FILE = PIPELINE_NAME + ".yaml"Sustituye
NOTIFY_EMAILpor una dirección de correo. Cuando se completa el trabajo de la canalización, tanto si se ha completado correctamente como si no, se envía un correo a esa dirección.Inicializa el SDK de Vertex AI con el proyecto, el bucket de almacenamiento provisional, la ubicación y el experimento.
from google.cloud import aiplatform aiplatform.init( project=PROJECT_ID, staging_bucket=BUCKET_URI, location=REGION, experiment=EXPERIMENT_NAME) aiplatform.autolog()
Definir las tareas del flujo de procesamiento
En tu cuaderno, define el flujo de procesamiento custom_model_training_evaluation_pipeline:
from kfp import dsl
from kfp.dsl import importer
from kfp.dsl import OneOf
from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp
from google_cloud_pipeline_components.types import artifact_types
from google_cloud_pipeline_components.v1.model import ModelUploadOp
from google_cloud_pipeline_components.v1.batch_predict_job import ModelBatchPredictOp
from google_cloud_pipeline_components.v1.model_evaluation import ModelEvaluationRegressionOp
from google_cloud_pipeline_components.v1.vertex_notification_email import VertexNotificationEmailOp
from google_cloud_pipeline_components.v1.endpoint import ModelDeployOp
from google_cloud_pipeline_components.v1.endpoint import EndpointCreateOp
from google.cloud import aiplatform
# define the train-deploy pipeline
@dsl.pipeline(name="custom-model-training-evaluation-pipeline")
def custom_model_training_evaluation_pipeline(
project: str,
location: str,
training_job_display_name: str,
worker_pool_specs: list,
base_output_dir: str,
prediction_container_uri: str,
model_display_name: str,
batch_prediction_job_display_name: str,
target_field_name: str,
test_data_gcs_uri: list,
ground_truth_gcs_source: list,
batch_predictions_gcs_prefix: str,
batch_predictions_input_format: str="csv",
batch_predictions_output_format: str="jsonl",
ground_truth_format: str="csv",
parent_model_resource_name: str=None,
parent_model_artifact_uri: str=None,
existing_model: bool=False
):
# Notification task
notify_task = VertexNotificationEmailOp(
recipients= EMAIL_RECIPIENTS
)
with dsl.ExitHandler(notify_task, name='MLOps Continuous Training Pipeline'):
# Train the model
custom_job_task = CustomTrainingJobOp(
project=project,
display_name=training_job_display_name,
worker_pool_specs=worker_pool_specs,
base_output_directory=base_output_dir,
location=location
)
# Import the unmanaged model
import_unmanaged_model_task = importer(
artifact_uri=base_output_dir,
artifact_class=artifact_types.UnmanagedContainerModel,
metadata={
"containerSpec": {
"imageUri": prediction_container_uri,
},
},
).after(custom_job_task)
with dsl.If(existing_model == True):
# Import the parent model to upload as a version
import_registry_model_task = importer(
artifact_uri=parent_model_artifact_uri,
artifact_class=artifact_types.VertexModel,
metadata={
"resourceName": parent_model_resource_name
},
).after(import_unmanaged_model_task)
# Upload the model as a version
model_version_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
parent_model=import_registry_model_task.outputs["artifact"],
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
with dsl.Else():
# Upload the model
model_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
# Get the model (or model version)
model_resource = OneOf(model_version_upload_op.outputs["model"], model_upload_op.outputs["model"])
# Batch prediction
batch_predict_task = ModelBatchPredictOp(
project= project,
job_display_name= batch_prediction_job_display_name,
model= model_resource,
location= location,
instances_format= batch_predictions_input_format,
predictions_format= batch_predictions_output_format,
gcs_source_uris= test_data_gcs_uri,
gcs_destination_output_uri_prefix= batch_predictions_gcs_prefix,
machine_type= 'n1-standard-2'
)
# Evaluation task
evaluation_task = ModelEvaluationRegressionOp(
project= project,
target_field_name= target_field_name,
location= location,
# model= model_resource,
predictions_format= batch_predictions_output_format,
predictions_gcs_source= batch_predict_task.outputs["gcs_output_directory"],
ground_truth_format= ground_truth_format,
ground_truth_gcs_source= ground_truth_gcs_source
)
return
Tu flujo de trabajo consta de un gráfico de tareas que utiliza los siguientes Google Cloud componentes de flujo de trabajo:
CustomTrainingJobOp: ejecuta trabajos de entrenamiento personalizados en Vertex AI.ModelUploadOp: sube el modelo de aprendizaje automático entrenado al registro de modelos.ModelBatchPredictOp: Crea una tarea de predicción por lotes.ModelEvaluationRegressionOp: evalúa una tarea por lotes de regresión.VertexNotificationEmailOp: Envía notificaciones por correo electrónico.
Compilar el flujo de procesamiento
Compila la canalización con el compilador de Kubeflow Pipelines (KFP) en un archivo YAML que contenga una representación hermética de tu canalización.
from kfp import dsl
from kfp import compiler
compiler.Compiler().compile(
pipeline_func=custom_model_training_evaluation_pipeline,
package_path="{}.yaml".format(PIPELINE_NAME),
)
Deberías ver un archivo YAML llamado vertex-pipeline-datatrigger-tutorial.yaml en tu directorio de trabajo.
Subir la canalización como plantilla
Crea un repositorio de tipo
KFPen Artifact Registry.REPO_NAME = "mlops" # Create a repo in the artifact registry ! gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFPSube la canalización compilada al repositorio.
from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."}) TEMPLATE_URI = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest"En la consola Google Cloud , comprueba que tu plantilla aparece en Plantillas de canalización.
Ejecutar el flujo de trabajo manualmente
Para asegurarte de que la canalización funciona, ejecútala manualmente.
En el cuaderno, especifica los parámetros necesarios para ejecutar la canalización como un trabajo.
DATASET_NAME = "mlops" TABLE_NAME = "chicago" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID, "--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False }Crea y ejecuta un trabajo de flujo de procesamiento.
# Create a pipeline job job = aiplatform.PipelineJob( display_name="triggered_custom_regression_evaluation", template_path=TEMPLATE_URI , parameter_values=parameters, pipeline_root=BUCKET_URI, enable_caching=False ) # Run the pipeline job job.run()La tarea tarda unos 30 minutos en completarse.
En la consola, debería ver una nueva ejecución de la canalización en la página Canalizaciones:
Una vez que se haya completado la ejecución de la canalización, deberías ver un modelo nuevo llamado
taxifare-prediction-modelo una nueva versión del modelo en el registro de modelos de Vertex AI:También debería ver una nueva tarea de predicción por lotes:
Ejecutar automáticamente el flujo de trabajo
Hay dos formas de ejecutar la canalización automáticamente: según una programación o cuando se insertan datos nuevos en el conjunto de datos.
Ejecutar la canalización según una programación
En tu cuaderno, llama a
PipelineJob.create_schedule.job_schedule = job.create_schedule( display_name="mlops tutorial schedule", cron="0 0 1 * *", # max_concurrent_run_count=1, max_run_count=12, )La expresión
cronprograma el trabajo para que se ejecute el día 1 de cada mes a las 00:00 (UTC).En este tutorial, no queremos que se ejecuten varios trabajos simultáneamente, por lo que asignamos el valor 1 a
max_concurrent_run_count.En la consola Google Cloud , comprueba que tu
scheduleaparezca en Programaciones de procesos.
Ejecutar la canalización cuando haya datos nuevos
Crear una función con un activador de Eventarc
Crea una función de Cloud (2.ª gen.) que ejecute la canalización cada vez que se inserten datos nuevos en la tabla de BigQuery.
En concreto, usamos Eventarc para activar la función cada vez que se produce un evento google.cloud.bigquery.v2.JobService.InsertJob. A continuación, la función ejecuta la plantilla de flujo de procesamiento.
Para obtener más información, consulta Desencadenadores de Eventarc y tipos de eventos admitidos.
En la Google Cloud consola, ve a las funciones de Cloud Run.
Haz clic en el botón Crear función. En la página Configuración:
Selecciona 2.ª gen. como entorno.
En Nombre de la función, usa mlops.
En Región, selecciona la misma región que tu segmento de Cloud Storage y tu repositorio de Artifact Registry.
En Activador, seleccione Otro activador. Se abrirá el panel Eventarc Trigger.
En Trigger Type (Tipo de activador), elija Google Sources (Fuentes de Google).
En Proveedor de eventos, elija BigQuery.
En Tipo de evento, elija
google.cloud.bigquery.v2.JobService.InsertJob.En Recurso, elija Recurso específico y especifique la tabla de BigQuery.
projects/PROJECT_ID/datasets/mlops/tables/chicagoEn el campo Región, selecciona una ubicación para el activador de Eventarc, si procede. Para obtener más información, consulta Ubicación del activador.
Haz clic en Guardar activador.
Si se te pide que concedas roles a cuentas de servicio, haz clic en Conceder todo.
Haz clic en Siguiente para ir a la página Código. En la página Código:
Define Runtime (Tiempo de ejecución) en Python 3.12.
Define Punto de entrada como
mlops_entrypoint.Con el editor insertado, abre el archivo
main.pyy sustituye el contenido por lo siguiente:Sustituye
PROJECT_ID,REGIONyBUCKET_NAMEpor los valores que has usado antes.import json import functions_framework import requests import google.auth import google.auth.transport.requests # CloudEvent function to be triggered by an Eventarc Cloud Audit Logging trigger # Note: this is NOT designed for second-party (Cloud Audit Logs -> Pub/Sub) triggers! @functions_framework.cloud_event def mlops_entrypoint(cloudevent): # Print out the CloudEvent's (required) `type` property # See https://github.com/cloudevents/spec/blob/v1.0.1/spec.md#type print(f"Event type: {cloudevent['type']}") # Print out the CloudEvent's (optional) `subject` property # See https://github.com/cloudevents/spec/blob/v1.0.1/spec.md#subject if 'subject' in cloudevent: # CloudEvent objects don't support `get` operations. # Use the `in` operator to verify `subject` is present. print(f"Subject: {cloudevent['subject']}") # Print out details from the `protoPayload` # This field encapsulates a Cloud Audit Logging entry # See https://cloud.google.com/logging/docs/audit#audit_log_entry_structure payload = cloudevent.data.get("protoPayload") if payload: print(f"API method: {payload.get('methodName')}") print(f"Resource name: {payload.get('resourceName')}") print(f"Principal: {payload.get('authenticationInfo', dict()).get('principalEmail')}") row_count = payload.get('metadata', dict()).get('tableDataChange',dict()).get('insertedRowsCount') print(f"No. of rows: {row_count} !!") if row_count: if int(row_count) > 0: print ("Pipeline trigger Condition met !!") submit_pipeline_job() else: print ("No pipeline triggered !!!") def submit_pipeline_job(): PROJECT_ID = 'PROJECT_ID' REGION = 'REGION' BUCKET_NAME = "BUCKET_NAME" DATASET_NAME = "mlops" TABLE_NAME = "chicago" base_output_dir = BUCKET_NAME BUCKET_URI = "gs://{}".format(BUCKET_NAME) PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-mlops-pipeline-tutorial" EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" REPO_NAME ="mlops" TEMPLATE_NAME="custom-model-training-evaluation-pipeline" TRAINING_JOB_DISPLAY_NAME="taxifare-prediction-training-job" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID,"--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False } TEMPLATE_URI = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest" print("TEMPLATE URI: ", TEMPLATE_URI) request_body = { "name": PIPELINE_NAME, "displayName": PIPELINE_NAME, "runtimeConfig":{ "gcsOutputDirectory": PIPELINE_ROOT, "parameterValues": parameters, }, "templateUri": TEMPLATE_URI } pipeline_url = "https://us-central1-aiplatform.googleapis.com/v1/projects/{}/locations/{}/pipelineJobs".format(PROJECT_ID, REGION) creds, project = google.auth.default() auth_req = google.auth.transport.requests.Request() creds.refresh(auth_req) headers = { 'Authorization': 'Bearer {}'.format(creds.token), 'Content-Type': 'application/json; charset=utf-8' } response = requests.request("POST", pipeline_url, headers=headers, data=json.dumps(request_body)) print(response.text)Abre el archivo
requirements.txty sustituye el contenido por lo siguiente:requests==2.31.0 google-auth==2.25.1
Haga clic en Desplegar para desplegar la función.
Insertar datos para activar el flujo de procesamiento
En la Google Cloud consola, ve a BigQuery Studio.
Haz clic en Crear consulta de SQL y ejecuta la siguiente consulta de SQL haciendo clic en Ejecutar.
INSERT INTO `PROJECT_ID.mlops.chicago` ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2022 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )Esta consulta de SQL para insertar filas nuevas en la tabla.
Para verificar si se ha activado el evento, busca
pipeline trigger condition meten el registro de tu función.Si la función se activa correctamente, deberías ver una nueva ejecución de la canalización en Vertex AI Pipelines. La tarea de la canalización tarda unos 30 minutos en completarse.
Limpieza
Para eliminar todos los recursos utilizados en este proyecto, puedes eliminar el proyecto Google Cloud que has usado en el tutorial. Google Cloud
De lo contrario, puedes eliminar los recursos que hayas creado para este tutorial.
Elimina el modelo de la siguiente manera:
En la sección Vertex AI, ve a la página Registro de modelos.
Junto al nombre de tu modelo, haz clic en el menú Acciones y elige Eliminar modelo.
Elimina las ejecuciones del flujo de procesamiento:
Ve a la página Ejecuciones de la canalización.
Junto al nombre de cada ejecución de la canalización, haz clic en el menú Acciones y elige Eliminar ejecución de la canalización.
Elimina las tareas de entrenamiento personalizadas:
Junto al nombre de cada trabajo de entrenamiento personalizado, haz clic en el menú Acciones y elige Eliminar trabajo de entrenamiento personalizado.
Elimina las tareas de predicción por lotes de la siguiente manera:
Junto al nombre de cada trabajo de predicción por lotes, haga clic en el menú Acciones y elija Eliminar trabajo de predicción por lotes.