Este documento explica os passos necessários para criar um pipeline que prepara automaticamente um modelo personalizado de forma periódica ou quando são inseridos novos dados no conjunto de dados através das funções do Cloud Run e dos pipelines da Vertex AI.
Objetivos
Os seguintes passos abrangem este processo:
Adquira e prepare o conjunto de dados no BigQuery.
Crie e carregue um pacote de preparação personalizado. Quando executado, lê dados do conjunto de dados e prepara o modelo.
Crie um Vertex AI Pipeline. Este pipeline executa o pacote de preparação personalizado, carrega o modelo para o Registo de modelos do Vertex AI, executa a tarefa de avaliação e envia uma notificação por email.
Execute o pipeline manualmente.
Crie uma Cloud Function com um acionador do Eventarc que execute o pipeline sempre que novos dados forem inseridos no conjunto de dados do BigQuery.
Antes de começar
Configure o seu projeto e notebook.
Configuração do projeto
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Criar bloco de notas
Usamos um bloco de notas do Colab Enterprise para executar parte do código neste tutorial.
Se não for o proprietário do projeto, peça a um proprietário do projeto que lhe conceda as funções de IAM
roles/resourcemanager.projectIamAdmineroles/aiplatform.colabEnterpriseUser.Tem de ter estas funções para usar o Colab Enterprise e conceder funções e autorizações do IAM a si próprio e a contas de serviço.
Na Google Cloud consola, aceda à página Blocos de notas do Colab Enterprise.
O Colab Enterprise pede-lhe que ative as seguintes APIs necessárias se ainda não estiverem ativadas.
- API Vertex AI
- API Dataform
- API Compute Engine
No menu Região, selecione a região onde quer criar o seu bloco de notas. Se não tiver a certeza, use us-central1 como região.
Use a mesma região para todos os recursos neste tutorial.
Clique em Criar um novo bloco de notas.
O novo bloco de notas é apresentado no separador Os meus blocos de notas. Para executar código no seu bloco de notas, adicione uma célula de código e clique no botão Executar célula.
Configure o ambiente de programação
No seu bloco de notas, instale os seguintes pacotes Python3.
! pip3 install google-cloud-aiplatform==1.34.0 \ google-cloud-pipeline-components==2.6.0 \ kfp==2.4.0 \ scikit-learn==1.0.2 \ mlflow==2.10.0Defina o projeto da CLI Google Cloud executando o seguinte comando:
PROJECT_ID = "PROJECT_ID" # Set the project id ! gcloud config set project {PROJECT_ID}Substitua PROJECT_ID pelo ID do seu projeto. Se necessário, pode localizar o ID do projeto na Google Cloud consola.
Atribua funções à sua Conta Google:
! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/bigquery.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.user ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/storage.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/pubsub.editor ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/cloudfunctions.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.viewer ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/logging.configWriter ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/iam.serviceAccountUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/eventarc.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/aiplatform.colabEnterpriseUser ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/artifactregistry.admin ! gcloud projects add-iam-policy-binding PROJECT_ID --member="user:"EMAIL_ADDRESS"" --role=roles/serviceusage.serviceUsageAdminAtive as seguintes APIs
- API Artifact Registry
- API BigQuery
- API Cloud Build
- Cloud Functions API
- Cloud Logging API
- Pub/Sub API
- Cloud Run Admin API
- API Cloud Storage
- API Eventarc
- API Service Usage
- API Vertex AI
! gcloud services enable artifactregistry.googleapis.com bigquery.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com logging.googleapis.com pubsub.googleapis.com run.googleapis.com storage-component.googleapis.com eventarc.googleapis.com serviceusage.googleapis.com aiplatform.googleapis.comConceda funções às contas de serviço do seu projeto:
Veja os nomes das suas contas de serviço
! gcloud iam service-accounts listTome nota do nome do agente do serviço Compute. Deve estar no formato
xxxxxxxx-compute@developer.gserviceaccount.com.Conceda as funções necessárias ao agente do serviço.
! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID-compute@developer.gserviceaccount.com"" --role=roles/aiplatform.serviceAgent ! gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:"SA_ID-compute@developer.gserviceaccount.com"" --role=roles/eventarc.eventReceiver
Adquira e prepare o conjunto de dados
Neste tutorial, vai criar um modelo que prevê a tarifa de uma viagem de táxi com base em funcionalidades como o tempo de viagem, a localização e a distância. Vamos usar dados do conjunto de dados público Chicago Taxi Trips. Este conjunto de dados inclui viagens de táxi de 2013 até ao presente, comunicadas à cidade de Chicago na sua função de organismo regulador. Para proteger a privacidade dos condutores e dos utilizadores do táxi em simultâneo e permitir que o agregador analise os dados, o ID do táxi é mantido consistente para qualquer número de medalhão de táxi específico, mas não mostra o número. Os setores censitários são suprimidos em alguns casos e as horas são arredondadas aos 15 minutos mais próximos.
Para mais informações, consulte o artigo Viagens de táxi em Chicago no Marketplace.
Crie um conjunto de dados do BigQuery
Na Google Cloud consola, aceda ao BigQuery Studio.
No painel Explorador, localize o seu projeto, clique em Ações e, de seguida, clique em Criar conjunto de dados.
Na página Criar conjunto de dados:
Para o ID do conjunto de dados, introduza
mlops. Para mais informações, consulte o artigo sobre a nomenclatura de conjuntos de dados.Em Tipo de localização, escolha a sua região múltipla. Por exemplo, escolha US (várias regiões nos Estados Unidos) se estiver a usar o
us-central1. Após a criação de um conjunto de dados, não é possível alterar a localização.Clique em Criar conjunto de dados.
Para mais informações, veja como criar conjuntos de dados.
Crie e preencha a tabela do BigQuery
Nesta secção, cria a tabela e importa dados relativos a um ano do conjunto de dados público para o conjunto de dados do seu projeto.
Aceda ao BigQuery Studio
Clique em Criar consulta SQL e execute a seguinte consulta SQL clicando em Executar.
CREATE OR REPLACE TABLE `PROJECT_ID.mlops.chicago` AS ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2019 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )Esta consulta cria a tabela
<PROJECT_ID>.mlops.chicagoe preenche-a com dados da tabela públicabigquery-public-data.chicago_taxi_trips.taxi_trips.Para ver o esquema da tabela, clique em Aceder à tabela e, de seguida, clique no separador Esquema.
Para ver o conteúdo da tabela, clique no separador Pré-visualizar.
Crie e carregue o pacote de preparação personalizado
Nesta secção, cria um pacote Python que contém o código que lê o conjunto de dados, divide os dados em conjuntos de preparação e de teste, e prepara o seu modelo personalizado. O pacote é executado como uma das tarefas no seu pipeline. Para mais informações, consulte o artigo criar uma aplicação de preparação Python para um contentor pré-criado.
Crie o pacote de preparação personalizado
No seu bloco de notas do Colab, crie pastas principais para a aplicação de preparação:
!mkdir -p training_package/trainerCrie um ficheiro
__init__.pyem cada pasta para a tornar um pacote através do seguinte comando:! touch training_package/__init__.py ! touch training_package/trainer/__init__.pyPode ver os novos ficheiros e pastas no painel da pasta Ficheiros.
No painel Ficheiros, crie um ficheiro denominado
task.pyna pasta training_package/trainer com o seguinte conteúdo.# Import the libraries from sklearn.model_selection import train_test_split, cross_val_score from sklearn.preprocessing import OneHotEncoder, StandardScaler from google.cloud import bigquery, bigquery_storage from sklearn.ensemble import RandomForestRegressor from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from google import auth from scipy import stats import numpy as np import argparse import joblib import pickle import csv import os # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--project-id', dest='project_id', type=str, help='Project ID.') parser.add_argument('--training-dir', dest='training_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the data and the trained model.') parser.add_argument('--bq-source', dest='bq_source', type=str, help='BigQuery data source for training data.') args = parser.parse_args() # data preparation code BQ_QUERY = """ with tmp_table as ( SELECT trip_seconds, trip_miles, fare, tolls, company, pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude, DATETIME(trip_start_timestamp, 'America/Chicago') trip_start_timestamp, DATETIME(trip_end_timestamp, 'America/Chicago') trip_end_timestamp, CASE WHEN (pickup_community_area IN (56, 64, 76)) OR (dropoff_community_area IN (56, 64, 76)) THEN 1 else 0 END is_airport, FROM `{}` WHERE dropoff_latitude IS NOT NULL and dropoff_longitude IS NOT NULL and pickup_latitude IS NOT NULL and pickup_longitude IS NOT NULL and fare > 0 and trip_miles > 0 and MOD(ABS(FARM_FINGERPRINT(unique_key)), 100) between 0 and 99 ORDER BY RAND() LIMIT 10000) SELECT *, EXTRACT(YEAR FROM trip_start_timestamp) trip_start_year, EXTRACT(MONTH FROM trip_start_timestamp) trip_start_month, EXTRACT(DAY FROM trip_start_timestamp) trip_start_day, EXTRACT(HOUR FROM trip_start_timestamp) trip_start_hour, FORMAT_DATE('%a', DATE(trip_start_timestamp)) trip_start_day_of_week FROM tmp_table """.format(args.bq_source) # Get default credentials credentials, project = auth.default() bqclient = bigquery.Client(credentials=credentials, project=args.project_id) bqstorageclient = bigquery_storage.BigQueryReadClient(credentials=credentials) df = ( bqclient.query(BQ_QUERY) .result() .to_dataframe(bqstorage_client=bqstorageclient) ) # Add 'N/A' for missing 'Company' df.fillna(value={'company':'N/A','tolls':0}, inplace=True) # Drop rows containing null data. df.dropna(how='any', axis='rows', inplace=True) # Pickup and dropoff locations distance df['abs_distance'] = (np.hypot(df['dropoff_latitude']-df['pickup_latitude'], df['dropoff_longitude']-df['pickup_longitude']))*100 # Remove extremes, outliers possible_outliers_cols = ['trip_seconds', 'trip_miles', 'fare', 'abs_distance'] df=df[(np.abs(stats.zscore(df[possible_outliers_cols].astype(float))) < 3).all(axis=1)].copy() # Reduce location accuracy df=df.round({'pickup_latitude': 3, 'pickup_longitude': 3, 'dropoff_latitude':3, 'dropoff_longitude':3}) # Drop the timestamp col X=df.drop(['trip_start_timestamp', 'trip_end_timestamp'],axis=1) # Split the data into train and test X_train, X_test = train_test_split(X, test_size=0.10, random_state=123) ## Format the data for batch predictions # select string cols string_cols = X_test.select_dtypes(include='object').columns # Add quotes around string fields X_test[string_cols] = X_test[string_cols].apply(lambda x: '\"' + x + '\"') # Add quotes around column names X_test.columns = ['\"' + col + '\"' for col in X_test.columns] # Save DataFrame to csv X_test.to_csv(os.path.join(args.training_dir,"test.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Save test data without the target for batch predictions X_test.drop('\"fare\"',axis=1,inplace=True) X_test.to_csv(os.path.join(args.training_dir,"test_no_target.csv"),index=False,quoting=csv.QUOTE_NONE, escapechar=' ') # Separate the target column y_train=X_train.pop('fare') # Get the column indexes col_index_dict = {col: idx for idx, col in enumerate(X_train.columns)} # Create a column transformer pipeline ct_pipe = ColumnTransformer(transformers=[ ('hourly_cat', OneHotEncoder(categories=[range(0,24)], sparse = False), [col_index_dict['trip_start_hour']]), ('dow', OneHotEncoder(categories=[['Mon', 'Tue', 'Sun', 'Wed', 'Sat', 'Fri', 'Thu']], sparse = False), [col_index_dict['trip_start_day_of_week']]), ('std_scaler', StandardScaler(), [ col_index_dict['trip_start_year'], col_index_dict['abs_distance'], col_index_dict['pickup_longitude'], col_index_dict['pickup_latitude'], col_index_dict['dropoff_longitude'], col_index_dict['dropoff_latitude'], col_index_dict['trip_miles'], col_index_dict['trip_seconds']]) ]) # Add the random-forest estimator to the pipeline rfr_pipe = Pipeline([ ('ct', ct_pipe), ('forest_reg', RandomForestRegressor( n_estimators = 20, max_features = 1.0, n_jobs = -1, random_state = 3, max_depth=None, max_leaf_nodes=None, )) ]) # train the model rfr_score = cross_val_score(rfr_pipe, X_train, y_train, scoring = 'neg_mean_squared_error', cv = 5) rfr_rmse = np.sqrt(-rfr_score) print ("Crossvalidation RMSE:",rfr_rmse.mean()) final_model=rfr_pipe.fit(X_train, y_train) # Save the model pipeline with open(os.path.join(args.training_dir,"model.joblib"), 'wb') as model_file: pickle.dump(final_model, model_file)O código realiza as seguintes tarefas:
- Seleção de funcionalidades.
- Transformar a hora dos dados de recolha e entrega de UTC para a hora local de Chicago.
- Extrair a data, a hora, o dia da semana, o mês e o ano da data/hora de recolha.
- Calcular a duração da viagem com base na hora de início e de fim.
- Identificar e marcar viagens que começaram ou terminaram num aeroporto com base nas áreas comunitárias.
- O modelo de regressão de floresta aleatória é preparado para prever a tarifa da viagem de táxi através da framework scikit-learn.
O modelo preparado é guardado num ficheiro pickle
model.joblib.A abordagem e a engenharia de funcionalidades selecionadas baseiam-se na exploração e na análise de dados sobre a previsão da tarifa de táxi de Chicago.
No painel Ficheiros, crie um ficheiro denominado
setup.pyna pasta training_package com o seguinte conteúdo.from setuptools import find_packages from setuptools import setup REQUIRED_PACKAGES=["google-cloud-bigquery[pandas]","google-cloud-bigquery-storage"] setup( name='trainer', version='0.1', install_requires=REQUIRED_PACKAGES, packages=find_packages(), include_package_data=True, description='Training application package for chicago taxi trip fare prediction.' )No bloco de notas, execute
setup.pypara criar a distribuição de origem para a sua aplicação de preparação:! cd training_package && python setup.py sdist --formats=gztar && cd ..
No final desta secção, o painel Ficheiros deve conter os seguintes ficheiros e pastas em training-package.
dist
trainer-0.1.tar.gz
trainer
__init__.py
task.py
trainer.egg-info
__init__.py
setup.py
Carregue o pacote de treino personalizado para o Cloud Storage
Crie um contentor do Cloud Storage.
REGION="REGION" BUCKET_NAME = "BUCKET_NAME" BUCKET_URI = f"gs://{BUCKET_NAME}" ! gcloud storage buckets create gs://$BUCKET_URI --location=$REGION --project=$PROJECT_IDSubstitua os seguintes valores de parâmetros:
REGION: escolha a mesma região que escolhe quando cria o seu bloco de notas do Colab.BUCKET_NAME: o nome do contentor.
Carregue o pacote de preparação para o contentor do Cloud Storage.
# Copy the training package to the bucket ! gcloud storage cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/
Crie o seu pipeline
Um pipeline é uma descrição de um fluxo de trabalho de MLOps como um gráfico de passos denominado tarefas de pipeline.
Nesta secção, define as tarefas do pipeline, compila-as para YAML e regista o pipeline no Artifact Registry para que possa ser controlado por versões e executado várias vezes por um único utilizador ou por vários utilizadores.
Segue-se uma visualização das tarefas, incluindo a preparação do modelo, o carregamento do modelo, a avaliação do modelo e a notificação por email, no nosso pipeline:
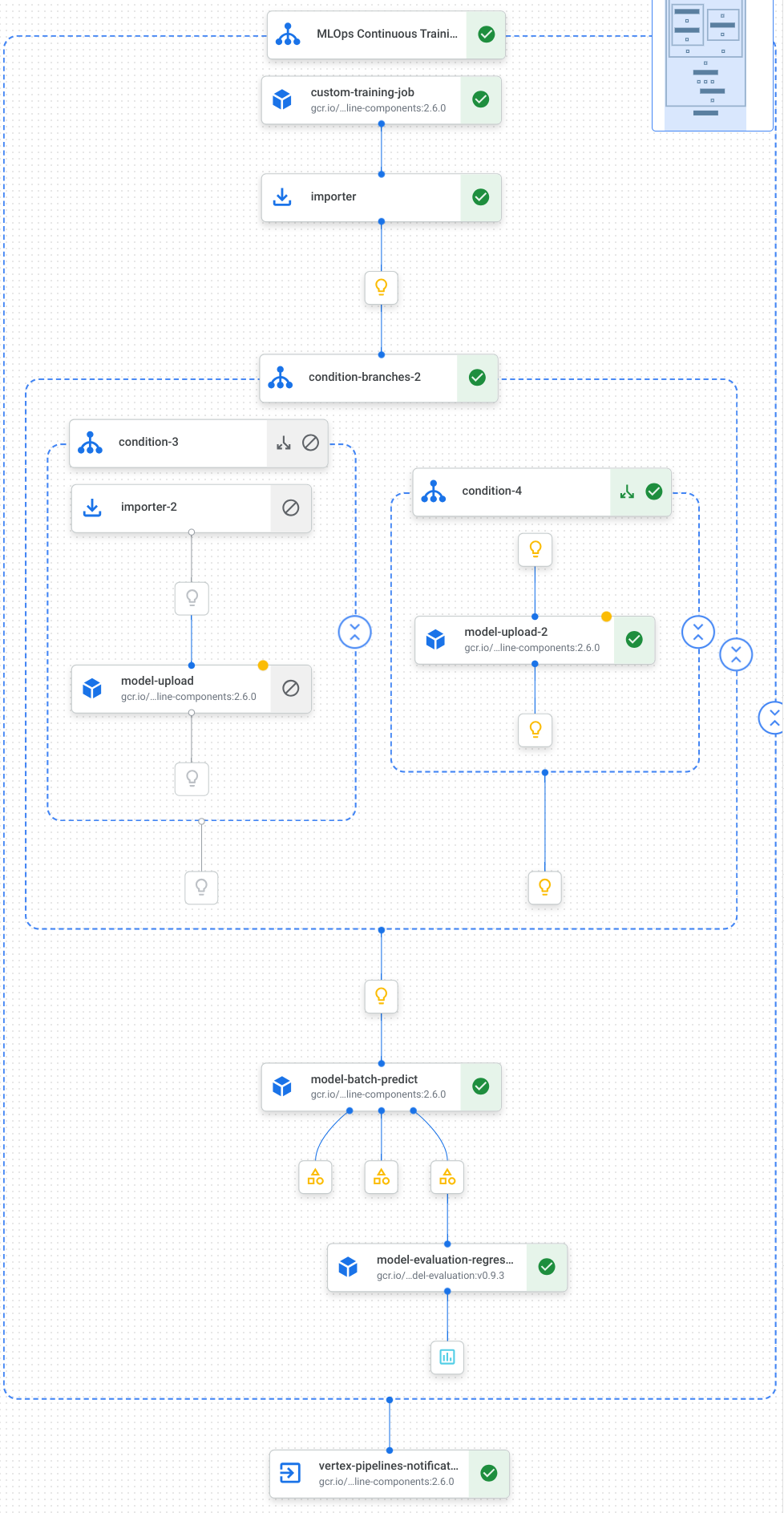
Para mais informações, consulte o artigo sobre criar modelos de pipelines.
Defina constantes e inicialize clientes
No bloco de notas, defina as constantes que vão ser usadas nos passos posteriores:
import os EMAIL_RECIPIENTS = [ "NOTIFY_EMAIL" ] PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-pipeline-datatrigger-tutorial" WORKING_DIR = f"{PIPELINE_ROOT}/mlops-datatrigger-tutorial" os.environ['AIP_MODEL_DIR'] = WORKING_DIR EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" PIPELINE_FILE = PIPELINE_NAME + ".yaml"Substitua
NOTIFY_EMAILpor um endereço de email. Quando a tarefa do pipeline é concluída, com êxito ou sem êxito, é enviado um email para esse endereço de email.Inicialize o SDK do Vertex AI com o projeto, o contentor de preparação, a localização e a experiência.
from google.cloud import aiplatform aiplatform.init( project=PROJECT_ID, staging_bucket=BUCKET_URI, location=REGION, experiment=EXPERIMENT_NAME) aiplatform.autolog()
Defina as tarefas da conduta
No bloco de notas, defina o pipeline custom_model_training_evaluation_pipeline:
from kfp import dsl
from kfp.dsl import importer
from kfp.dsl import OneOf
from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp
from google_cloud_pipeline_components.types import artifact_types
from google_cloud_pipeline_components.v1.model import ModelUploadOp
from google_cloud_pipeline_components.v1.batch_predict_job import ModelBatchPredictOp
from google_cloud_pipeline_components.v1.model_evaluation import ModelEvaluationRegressionOp
from google_cloud_pipeline_components.v1.vertex_notification_email import VertexNotificationEmailOp
from google_cloud_pipeline_components.v1.endpoint import ModelDeployOp
from google_cloud_pipeline_components.v1.endpoint import EndpointCreateOp
from google.cloud import aiplatform
# define the train-deploy pipeline
@dsl.pipeline(name="custom-model-training-evaluation-pipeline")
def custom_model_training_evaluation_pipeline(
project: str,
location: str,
training_job_display_name: str,
worker_pool_specs: list,
base_output_dir: str,
prediction_container_uri: str,
model_display_name: str,
batch_prediction_job_display_name: str,
target_field_name: str,
test_data_gcs_uri: list,
ground_truth_gcs_source: list,
batch_predictions_gcs_prefix: str,
batch_predictions_input_format: str="csv",
batch_predictions_output_format: str="jsonl",
ground_truth_format: str="csv",
parent_model_resource_name: str=None,
parent_model_artifact_uri: str=None,
existing_model: bool=False
):
# Notification task
notify_task = VertexNotificationEmailOp(
recipients= EMAIL_RECIPIENTS
)
with dsl.ExitHandler(notify_task, name='MLOps Continuous Training Pipeline'):
# Train the model
custom_job_task = CustomTrainingJobOp(
project=project,
display_name=training_job_display_name,
worker_pool_specs=worker_pool_specs,
base_output_directory=base_output_dir,
location=location
)
# Import the unmanaged model
import_unmanaged_model_task = importer(
artifact_uri=base_output_dir,
artifact_class=artifact_types.UnmanagedContainerModel,
metadata={
"containerSpec": {
"imageUri": prediction_container_uri,
},
},
).after(custom_job_task)
with dsl.If(existing_model == True):
# Import the parent model to upload as a version
import_registry_model_task = importer(
artifact_uri=parent_model_artifact_uri,
artifact_class=artifact_types.VertexModel,
metadata={
"resourceName": parent_model_resource_name
},
).after(import_unmanaged_model_task)
# Upload the model as a version
model_version_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
parent_model=import_registry_model_task.outputs["artifact"],
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
with dsl.Else():
# Upload the model
model_upload_op = ModelUploadOp(
project=project,
location=location,
display_name=model_display_name,
unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"],
)
# Get the model (or model version)
model_resource = OneOf(model_version_upload_op.outputs["model"], model_upload_op.outputs["model"])
# Batch prediction
batch_predict_task = ModelBatchPredictOp(
project= project,
job_display_name= batch_prediction_job_display_name,
model= model_resource,
location= location,
instances_format= batch_predictions_input_format,
predictions_format= batch_predictions_output_format,
gcs_source_uris= test_data_gcs_uri,
gcs_destination_output_uri_prefix= batch_predictions_gcs_prefix,
machine_type= 'n1-standard-2'
)
# Evaluation task
evaluation_task = ModelEvaluationRegressionOp(
project= project,
target_field_name= target_field_name,
location= location,
# model= model_resource,
predictions_format= batch_predictions_output_format,
predictions_gcs_source= batch_predict_task.outputs["gcs_output_directory"],
ground_truth_format= ground_truth_format,
ground_truth_gcs_source= ground_truth_gcs_source
)
return
O seu pipeline consiste num gráfico de tarefas que usam os seguintes Google Cloud componentes do pipeline:
CustomTrainingJobOp: Executa tarefas de preparação personalizadas na Vertex AI.ModelUploadOp: Carrega o modelo de aprendizagem automática preparado para o registo de modelos.ModelBatchPredictOp: Cria uma tarefa de previsão em lote.ModelEvaluationRegressionOp: Avalia uma tarefa em lote de regressão.VertexNotificationEmailOp: Envia notificações por email.
Compile a pipeline
Compile o pipeline através do compilador do Kubeflow Pipelines (KFP) num ficheiro YAML que contenha uma representação hermética do seu pipeline.
from kfp import dsl
from kfp import compiler
compiler.Compiler().compile(
pipeline_func=custom_model_training_evaluation_pipeline,
package_path="{}.yaml".format(PIPELINE_NAME),
)
Deve ver um ficheiro YAML denominado vertex-pipeline-datatrigger-tutorial.yaml no diretório de trabalho.
Carregue o pipeline como um modelo
Crie um repositório do tipo
KFPno Artifact Registry.REPO_NAME = "mlops" # Create a repo in the artifact registry ! gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFPCarregue o pipeline compilado para o repositório.
from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."}) TEMPLATE_URI = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest"Na Google Cloud consola, verifique se o seu modelo aparece em Modelos de pipeline.
Execute manualmente a tubagem
Para se certificar de que o pipeline funciona, execute-o manualmente.
No bloco de notas, especifique os parâmetros necessários para executar o pipeline como uma tarefa.
DATASET_NAME = "mlops" TABLE_NAME = "chicago" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID, "--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False }Crie e execute uma tarefa de pipeline.
# Create a pipeline job job = aiplatform.PipelineJob( display_name="triggered_custom_regression_evaluation", template_path=TEMPLATE_URI , parameter_values=parameters, pipeline_root=BUCKET_URI, enable_caching=False ) # Run the pipeline job job.run()A tarefa demora cerca de 30 minutos a ser concluída.
Na consola, deve ver uma nova execução do pipeline na página Pipelines:
Após a conclusão da execução do pipeline, deve ver um novo modelo denominado
taxifare-prediction-modelou uma nova versão do modelo no Registo de modelos da Vertex AI:Também deve ver uma nova tarefa de previsão em lote:
Executar automaticamente o pipeline
Existem duas formas de executar automaticamente o pipeline: de acordo com um agendamento ou quando são inseridos novos dados no conjunto de dados.
Execute o pipeline com base numa programação
No seu bloco de notas, chame
PipelineJob.create_schedule.job_schedule = job.create_schedule( display_name="mlops tutorial schedule", cron="0 0 1 * *", # max_concurrent_run_count=1, max_run_count=12, )A expressão
cronagenda a execução da tarefa no dia 1 de cada mês às 00:00 UTC.Para este tutorial, não queremos que vários trabalhos sejam executados em simultâneo, pelo que definimos
max_concurrent_run_countcomo 1.Na Google Cloud consola, verifique se o seu
scheduleaparece em Agendamentos de pipelines.
Executar o pipeline quando existirem novos dados
Crie uma função com um acionador do Eventarc
Crie uma função na nuvem (2.ª geração) que execute o pipeline sempre que novos dados forem inseridos na tabela do BigQuery.
Especificamente, usamos um Eventarc para acionar a função sempre que ocorre um evento google.cloud.bigquery.v2.JobService.InsertJob. Em seguida, a função executa o modelo de pipeline.
Para mais informações, consulte Acionadores do Eventarc e tipos de eventos suportados.
Na Google Cloud consola, aceda às funções do Cloud Run.
Clique no botão Criar função. Na página Configuração:
Selecione 2.ª geração como ambiente.
Para Nome da função, use mlops.
Para Região, selecione a mesma região que o seu contentor do Cloud Storage e o repositório do Artifact Registry.
Para Acionador, selecione Outro acionador. É aberto o painel Eventarc Trigger.
Para Tipo de acionador, escolha Origens Google.
Para Fornecedor de eventos, escolha BigQuery.
Para Tipo de evento, escolha
google.cloud.bigquery.v2.JobService.InsertJob.Para Recurso, escolha Recurso específico e especifique a tabela do BigQuery
projects/PROJECT_ID/datasets/mlops/tables/chicagoNo campo Região, selecione uma localização para o acionador do Eventarc, se aplicável. Consulte Localização do acionador para mais informações.
Clique em Guardar acionador.
Se lhe for pedido que conceda funções a contas de serviço, clique em Conceder tudo.
Clique em Seguinte para aceder à página Código. Na página Código:
Defina o ambiente de execução como Python 3.12.
Defina o Ponto de entrada como
mlops_entrypoint.Com o editor inline, abra o ficheiro
main.pye substitua o conteúdo pelo seguinte:Substitua
PROJECT_ID,REGIONeBUCKET_NAMEpelos valores que usou anteriormente.import json import functions_framework import requests import google.auth import google.auth.transport.requests # CloudEvent function to be triggered by an Eventarc Cloud Audit Logging trigger # Note: this is NOT designed for second-party (Cloud Audit Logs -> Pub/Sub) triggers! @functions_framework.cloud_event def mlops_entrypoint(cloudevent): # Print out the CloudEvent's (required) `type` property # See https://github.com/cloudevents/spec/blob/v1.0.1/spec.md#type print(f"Event type: {cloudevent['type']}") # Print out the CloudEvent's (optional) `subject` property # See https://github.com/cloudevents/spec/blob/v1.0.1/spec.md#subject if 'subject' in cloudevent: # CloudEvent objects don't support `get` operations. # Use the `in` operator to verify `subject` is present. print(f"Subject: {cloudevent['subject']}") # Print out details from the `protoPayload` # This field encapsulates a Cloud Audit Logging entry # See https://cloud.google.com/logging/docs/audit#audit_log_entry_structure payload = cloudevent.data.get("protoPayload") if payload: print(f"API method: {payload.get('methodName')}") print(f"Resource name: {payload.get('resourceName')}") print(f"Principal: {payload.get('authenticationInfo', dict()).get('principalEmail')}") row_count = payload.get('metadata', dict()).get('tableDataChange',dict()).get('insertedRowsCount') print(f"No. of rows: {row_count} !!") if row_count: if int(row_count) > 0: print ("Pipeline trigger Condition met !!") submit_pipeline_job() else: print ("No pipeline triggered !!!") def submit_pipeline_job(): PROJECT_ID = 'PROJECT_ID' REGION = 'REGION' BUCKET_NAME = "BUCKET_NAME" DATASET_NAME = "mlops" TABLE_NAME = "chicago" base_output_dir = BUCKET_NAME BUCKET_URI = "gs://{}".format(BUCKET_NAME) PIPELINE_ROOT = "{}/pipeline_root/chicago-taxi-pipe".format(BUCKET_URI) PIPELINE_NAME = "vertex-mlops-pipeline-tutorial" EXPERIMENT_NAME = PIPELINE_NAME + "-experiment" REPO_NAME ="mlops" TEMPLATE_NAME="custom-model-training-evaluation-pipeline" TRAINING_JOB_DISPLAY_NAME="taxifare-prediction-training-job" worker_pool_specs = [{ "machine_spec": {"machine_type": "e2-highmem-2"}, "replica_count": 1, "python_package_spec":{ "executor_image_uri": "us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest", "package_uris": [f"{BUCKET_URI}/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args":["--project-id",PROJECT_ID,"--training-dir",f"/gcs/{BUCKET_NAME}","--bq-source",f"{PROJECT_ID}.{DATASET_NAME}.{TABLE_NAME}"] }, }] parameters = { "project": PROJECT_ID, "location": REGION, "training_job_display_name": "taxifare-prediction-training-job", "worker_pool_specs": worker_pool_specs, "base_output_dir": BUCKET_URI, "prediction_container_uri": "us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest", "model_display_name": "taxifare-prediction-model", "batch_prediction_job_display_name": "taxifare-prediction-batch-job", "target_field_name": "fare", "test_data_gcs_uri": [f"{BUCKET_URI}/test_no_target.csv"], "ground_truth_gcs_source": [f"{BUCKET_URI}/test.csv"], "batch_predictions_gcs_prefix": f"{BUCKET_URI}/batch_predict_output", "existing_model": False } TEMPLATE_URI = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}/{TEMPLATE_NAME}/latest" print("TEMPLATE URI: ", TEMPLATE_URI) request_body = { "name": PIPELINE_NAME, "displayName": PIPELINE_NAME, "runtimeConfig":{ "gcsOutputDirectory": PIPELINE_ROOT, "parameterValues": parameters, }, "templateUri": TEMPLATE_URI } pipeline_url = "https://us-central1-aiplatform.googleapis.com/v1/projects/{}/locations/{}/pipelineJobs".format(PROJECT_ID, REGION) creds, project = google.auth.default() auth_req = google.auth.transport.requests.Request() creds.refresh(auth_req) headers = { 'Authorization': 'Bearer {}'.format(creds.token), 'Content-Type': 'application/json; charset=utf-8' } response = requests.request("POST", pipeline_url, headers=headers, data=json.dumps(request_body)) print(response.text)Abra o ficheiro
requirements.txte substitua o conteúdo pelo seguinte:requests==2.31.0 google-auth==2.25.1
Clique em Implementar para implementar a função.
Insira dados para acionar a conduta
Na Google Cloud consola, aceda ao BigQuery Studio.
Clique em Criar consulta SQL e execute a seguinte consulta SQL clicando em Executar.
INSERT INTO `PROJECT_ID.mlops.chicago` ( WITH taxitrips AS ( SELECT trip_start_timestamp, trip_end_timestamp, trip_seconds, trip_miles, payment_type, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, tips, tolls, fare, pickup_community_area, dropoff_community_area, company, unique_key FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips` WHERE pickup_longitude IS NOT NULL AND pickup_latitude IS NOT NULL AND dropoff_longitude IS NOT NULL AND dropoff_latitude IS NOT NULL AND trip_miles > 0 AND trip_seconds > 0 AND fare > 0 AND EXTRACT(YEAR FROM trip_start_timestamp) = 2022 ) SELECT trip_start_timestamp, EXTRACT(MONTH from trip_start_timestamp) as trip_month, EXTRACT(DAY from trip_start_timestamp) as trip_day, EXTRACT(DAYOFWEEK from trip_start_timestamp) as trip_day_of_week, EXTRACT(HOUR from trip_start_timestamp) as trip_hour, trip_seconds, trip_miles, payment_type, ST_AsText( ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1) ) AS pickup_grid, ST_AsText( ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1) ) AS dropoff_grid, ST_Distance( ST_GeogPoint(pickup_longitude, pickup_latitude), ST_GeogPoint(dropoff_longitude, dropoff_latitude) ) AS euclidean, CONCAT( ST_AsText(ST_SnapToGrid(ST_GeogPoint(pickup_longitude, pickup_latitude), 0.1)), ST_AsText(ST_SnapToGrid(ST_GeogPoint(dropoff_longitude, dropoff_latitude), 0.1)) ) AS loc_cross, IF((tips/fare >= 0.2), 1, 0) AS tip_bin, tips, tolls, fare, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, pickup_community_area, dropoff_community_area, company, unique_key, trip_end_timestamp FROM taxitrips LIMIT 1000000 )Esta consulta SQL para inserir novas linhas na tabela.
Para verificar se o evento foi acionado, pesquise
pipeline trigger condition metno registo da sua função.Se a função for acionada com êxito, deve ver uma nova execução do pipeline no Vertex AI Pipelines. A tarefa de pipeline demora cerca de 30 minutos a ser concluída.
Limpar
Para limpar todos os Google Cloud recursos usados para este projeto, pode eliminar o Google Cloud projeto que usou para o tutorial.
Caso contrário, pode eliminar os recursos individuais que criou para este tutorial.
Elimine o modelo da seguinte forma:
Na secção Vertex AI, aceda à página Registo de modelos.
Junto ao nome do modelo, clique no menu Ações e escolha Eliminar modelo.
Elimine as execuções da pipeline:
Aceda à página Execuções de pipelines.
Junto ao nome de cada execução do pipeline, clique no menu Ações e escolha Eliminar execução do pipeline.
Elimine as tarefas de preparação personalizada:
Junto ao nome de cada tarefa de preparação personalizada, clique no menu Ações e escolha Eliminar tarefa de preparação personalizada.
Elimine as tarefas de previsão em lote da seguinte forma:
Junto ao nome de cada tarefa de previsão em lote, clique no menu Ações e escolha Eliminar tarefa de previsão em lote.