Vertex AI 上的 Ray 集群提供两种扩缩选项:自动扩缩和手动扩缩。借助自动扩缩功能,集群可以根据 Ray 任务和因子所需的资源自动调整工作器节点的数量。如果您运行的是繁重的工作负载,并且不确定所需的资源,建议您使用自动扩缩。通过手动扩缩,用户可以更精细地控制节点。
自动扩缩可以降低工作负载成本,但会增加节点启动开销,并且配置起来可能比较棘手。如果您是 Ray 新手,请先从非自动扩缩集群开始,并使用手动扩缩功能。
自动扩缩
您可以通过指定工作器池的最小副本数 (min_replica_count) 和最大副本数 (max_replica_count) 来启用 Ray 集群的自动扩缩功能。
请注意以下几点:
- 配置所有工作器池的自动扩缩规范。
- 不支持自定义升/降采样速度。如需了解默认值,请参阅 Ray 文档中的缩放速度。
设置工作器池自动扩缩规范
使用 Google Cloud 控制台或 Vertex AI SDK for Python 启用 Ray 集群的自动缩放功能。
Vertex AI SDK 上的 Ray
from google.cloud import aiplatform import vertex_ray from vertex_ray import AutoscalingSpec autoscaling_spec = AutoscalingSpec( min_replica_count=1, max_replica_count=3, ) head_node_type = Resources( machine_type="n1-standard-16", node_count=1, ) worker_node_types = [Resources( machine_type="n1-standard-16", accelerator_type="NVIDIA_TESLA_T4", accelerator_count=1, autoscaling_spec=autoscaling_spec, )] # Create the Ray cluster on Vertex AI CLUSTER_RESOURCE_NAME = vertex_ray.create_ray_cluster( head_node_type=head_node_type, worker_node_types=worker_node_types, ... )
控制台
根据 OSS Ray 最佳实践建议,强制在 Ray 头节点上将逻辑 CPU 数量设置为 0,以便避免在头节点上运行任何工作负载。
在 Google Cloud 控制台中,前往“Ray on Vertex AI”页面。
点击创建集群,打开创建集群面板。
对于创建集群面板中的每个步骤,请查看或替换默认集群信息。点击继续以完成每个步骤:
点击创建。
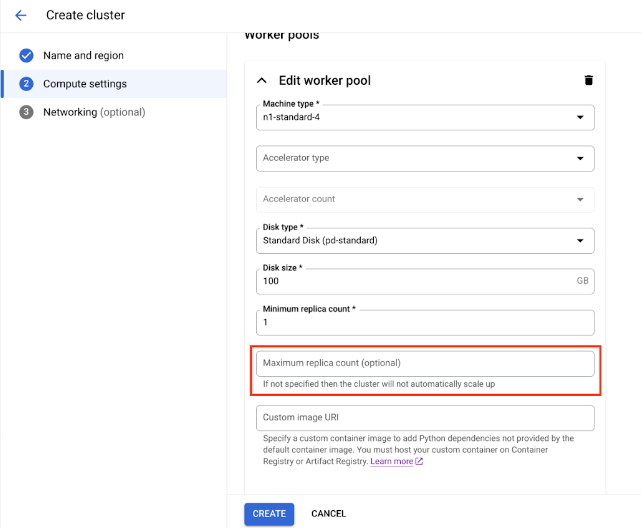
手动扩缩
当 Vertex AI 上的 Ray 集群的工作负载激增或减少时,您可以手动扩缩副本的数量以满足需求。例如,如果您有过剩的容量,可以缩减工作器池以节省费用。
VPC 对等互连的限制
在扩缩集群时,您只能更改现有工作器池中的副本数量。例如,您无法向集群添加或从中移除工作器池,也无法更改工作器池的机器类型。此外,工作器池的副本数量不能小于 1。
如果您使用 VPC 对等互连连接到集群,则节点数量上限会受到限制。节点数上限取决于集群在创建时具有的节点数。如需了解详情,请参阅节点数量上限计算。此数量上限不仅包括工作器池,还包括头节点。如果您使用默认网络配置,则节点数量不得超过创建集群文档中所述的上限。
子网分配最佳实践
使用专用服务访问通道 (PSA) 部署 Veo on Vertex AI 时,务必要确保分配的 IP 地址范围足够大且连续,以容纳集群可能扩缩到的最大节点数。如果为 PSA 连接预留的 IP 范围过小或碎片化,可能会导致 IP 地址耗尽,进而导致部署失败。
作为替代方案,我们建议部署 Ray on Vertex AI 并使用 Private Service Connect 接口,这样可将 IP 消耗量减少到 /28 子网。
专用服务访问通道监控
最佳实践是使用网络分析器,这是 Google Cloud 的 Network Intelligence Center 内的一款诊断工具,可自动监控您的虚拟私有云 (VPC) 网络配置,以检测错误配置和欠佳设置。网络分析器会持续运行,主动运行测试并生成分析洞见,帮助您在网络问题影响服务可用性之前发现、诊断并解决这些问题。
网络分析器能够监控用于专用服务访问通道 (PSA) 的子网,并提供与其相关的特定分析洞见。 对于管理使用 PSA 的 Cloud SQL、Memorystore 和 Vertex AI 等服务,这是一项关键功能。
网络分析器监控 PSA 子网的主要方式是针对已分配的范围提供 IP 地址利用率分析洞见。
PSA 范围利用率:网络分析器会主动跟踪您为 PSA 分配的专用 CIDR 块中 IP 地址的分配百分比。这一点非常重要,因为当您创建托管式服务(例如 Vertex AI)时,Google 会创建一个服务提供方 VPC 和其中的子网,并从您分配的地址块中提取 IP 地址范围。
主动提醒:如果 PSA 分配范围的 IP 地址利用率超过某个阈值(例如 75%),网络分析器会生成警告分析洞见。这样,系统会主动提醒您可能存在的容量问题,让您有时间在可用地址用完之前扩展分配的 IP 范围,以便为新的服务资源提供足够的地址。
专用服务访问通道子网更新
对于 Ray on Vertex AI 部署,Google 建议为 PSA 连接分配 /16 或 /17 CIDR 块。这样一来,便可提供足够大的连续 IP 地址块,以支持大幅伸缩,分别可容纳最多 65,536 个或 32,768 个唯一 IP 地址。这有助于防止 IP 耗尽,即使是大型 Ray 集群也是如此。
如果分配的 IP 地址空间用尽, Google Cloud 将返回以下错误:
未能创建子网。在分配的 IP 范围中找不到可用块。
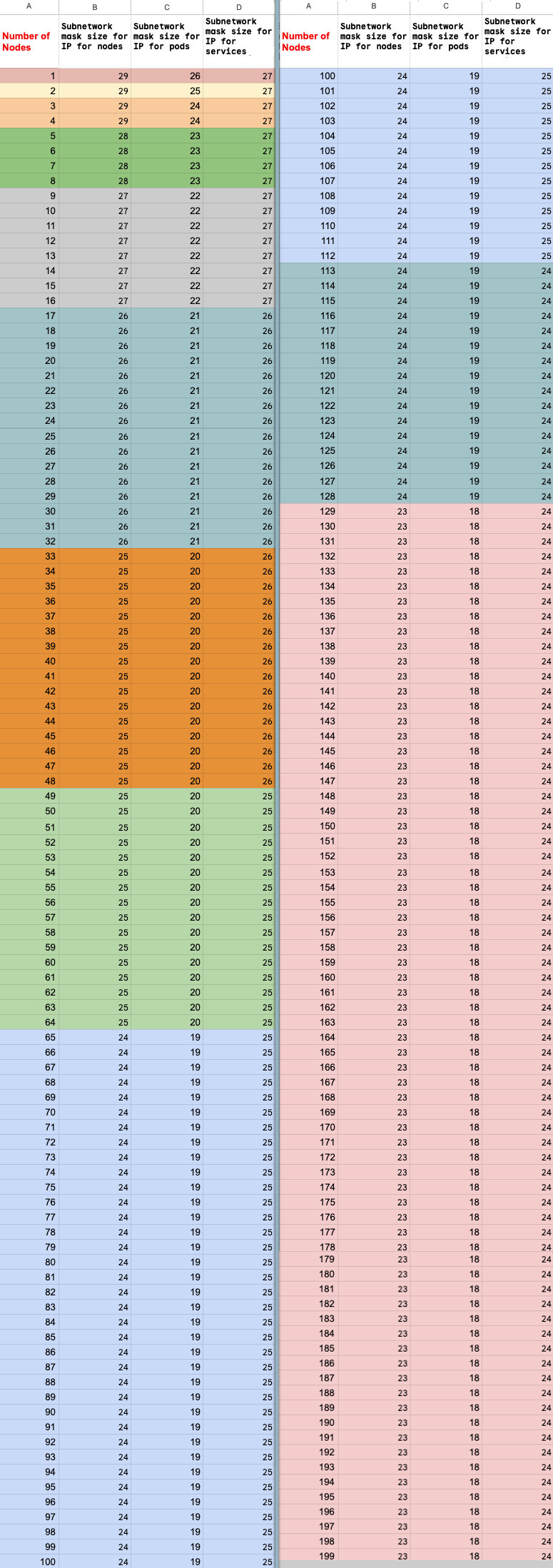
计算节点数上限
如果您使用专用服务访问通道(VPC 对等互连)连接到节点,请使用以下公式检查您未超过节点数上限 (M)(假设 f(x) = min(29, (32 -
ceiling(log2(x)))):
f(2 * M) = f(2 * N)f(64 * M) = f(64 * N)f(max(32, 16 + M)) = f(max(32, 16 + N))
Ray on Vertex AI 集群可以扩容到的节点总数上限 (M) 取决于您设置的初始节点总数 (N)。创建 Ray on Vertex AI 集群后,您可以将节点总数扩缩到 P 至 M 之间的值(含边界值),其中 P 是集群中的池数量。
集群中的初始节点总数和纵向扩容目标数量必须位于同一色块中。
更新副本数量
您可以使用 Google Cloud 控制台或 Vertex AI SDK for Python 更新工作器池的副本数量。如果集群包含多个工作器池,您可以在单个请求中单独更改每个副本数量。
Vertex AI SDK 上的 Ray
import vertexai import vertex_ray vertexai.init() cluster = vertex_ray.get_ray_cluster("CLUSTER_NAME") # Get the resource name. cluster_resource_name = cluster.cluster_resource_name # Create the new worker pools new_worker_node_types = [] for worker_node_type in cluster.worker_node_types: worker_node_type.node_count = REPLICA_COUNT # new worker pool size new_worker_node_types.append(worker_node_type) # Make update call updated_cluster_resource_name = vertex_ray.update_ray_cluster( cluster_resource_name=cluster_resource_name, worker_node_types=new_worker_node_types, )
控制台
在 Google Cloud 控制台中,前往“Ray on Vertex AI”页面。
在集群列表中,点击要修改的集群。
在集群详情页面上,点击修改集群。
在修改集群窗格中,选择要更新的工作器池,然后修改副本数量。
点击更新。
等待几分钟,直至集群完成更新。更新完成后,您可以在集群详细信息页面上看到更新后的副本数。
点击创建。