Os clusters do Ray na Vertex AI oferecem duas opções de escalonamento: escalonamento automático e escalonamento manual. O escalonamento automático permite que o cluster ajuste automaticamente o número de nós de trabalho com base nos recursos exigidos pelas tarefas e atores do Ray. Se você executar uma carga de trabalho pesada e não tiver certeza dos recursos necessários, recomendamos o escalonamento automático. O escalonamento manual oferece aos usuários um controle mais granular dos nós.
O escalonamento automático pode reduzir os custos de carga de trabalho, mas aumenta a sobrecarga de inicialização do nó e pode ser difícil de configurar. Se você é iniciante no Ray, comece com clusters sem escalonamento automático e use o recurso de escalonamento manual.
Escalonamento automático
Ative o recurso de escalonamento automático de um cluster do Ray especificando a contagem mínima
de réplicas (min_replica_count) e a contagem máxima de réplicas (max_replica_count) de
um pool de workers.
Observe o seguinte:
- Configure a especificação de escalonamento automático de todos os pools de workers.
- Não é possível usar a velocidade de aumento e redução personalizada. Para valores padrão, consulte Aumento e redução de velocidade na documentação do Ray.
Definir a especificação de escalonamento automático do pool de workers
Use o console do Google Cloud ou o SDK da Vertex AI para Python para ativar o recurso de escalonamento automático de um cluster do Ray.
SDK do Ray na Vertex AI
from google.cloud import aiplatform import vertex_ray from vertex_ray import AutoscalingSpec autoscaling_spec = AutoscalingSpec( min_replica_count=1, max_replica_count=3, ) head_node_type = Resources( machine_type="n1-standard-16", node_count=1, ) worker_node_types = [Resources( machine_type="n1-standard-16", accelerator_type="NVIDIA_TESLA_T4", accelerator_count=1, autoscaling_spec=autoscaling_spec, )] # Create the Ray cluster on Vertex AI CLUSTER_RESOURCE_NAME = vertex_ray.create_ray_cluster( head_node_type=head_node_type, worker_node_types=worker_node_types, ... )
Console
De acordo com as Práticas recomendadas do OSS Ray a configuração da contagem lógica de CPU como 0 no nó principal do Ray é aplicada para para evitar a execução de cargas de trabalho no nó principal.
No console Google Cloud , acesse a página do Ray na Vertex AI.
Clique em Criar cluster para abrir o painel Criar cluster.
Para cada etapa no painel Criar cluster, revise ou substitua as informações do cluster padrão. Clique em Continuar para concluir cada etapa:
- Em Nome e região, especifique um Nome e escolha um local para o cluster.
Em Configurações de computação, especifique a configuração do cluster do Ray no nó principal, incluindo tipo de máquina, tipo e contagem de aceleradores, tipo e tamanho de disco e contagem de réplicas. Também é possível adicionar um URI de imagem personalizada para especificar uma imagem de contêiner personalizada e adicionar dependências do Python não fornecidas pela imagem de contêiner padrão. Consulte Imagem personalizada.
Em Opções avançadas, é possível fazer o seguinte:
- Especifique sua própria chave de criptografia.
- Especifique uma conta de serviço personalizada.
- Se você não precisar monitorar as estatísticas de recursos da sua carga de trabalho durante o treinamento, desative a coleta de métricas.
Para criar um cluster com um pool de workers com escalonamento automático, forneça um valor para a contagem máxima de réplicas do pool de workers.
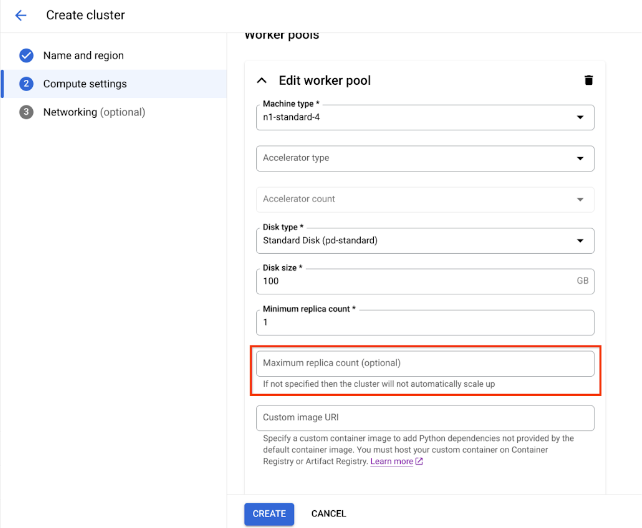
Clique em Criar.
Escalonamento manual
À medida que as cargas de trabalho aumentam ou diminuem nos clusters do Ray na Vertex AI, é possível escalonar manualmente o número de réplicas para corresponder à demanda. Por exemplo, se você tiver excesso de capacidade, reduzir escala vertical os pools de workers para economizar custos.
Limitações do peering de VPC
Ao escalonar clusters, é possível alterar apenas o número de réplicas nos pools de workers. Por exemplo, não é possível adicionar ou remover pools de workers do cluster ou mudar o tipo de máquina desses pools. Além disso, o número de réplicas dos pools de workers não pode ser menor que um.
Se você usar uma conexão de peering de VPC para se conectar aos clusters, haverá uma limitação no número máximo de nós. O número máximo de nós depende do número de nós que o cluster tinha quando você o criou. Para mais informações, consulte Cálculo do número máximo de nós. Esse número máximo inclui não apenas os pools de workers, mas também o nó principal. Se você usar a configuração de rede padrão, o número de nós não poderá exceder os limites máximos, conforme descrito na documentação Criar clusters.
Práticas recomendadas de alocação de sub-rede
Ao implantar o Ray na Vertex AI usando o acesso a serviços particulares (PSA), é fundamental garantir que o intervalo de endereços IP alocado seja suficientemente grande e contíguo para acomodar o número máximo de nós que seu cluster pode escalonar. O esgotamento de IP pode ocorrer se o intervalo de IP reservado para sua conexão PSA for muito pequeno ou fragmentado, causando falhas de implantação.
Como alternativa, recomendamos implantar o Ray na Vertex AI com uma interface do Private Service Connect, que reduz o consumo de IP para uma sub-rede /28.
Monitoramento do acesso a serviços particulares
Como prática recomendada, use o Network Analyzer, uma ferramenta de diagnóstico no Network Intelligence Center do Google Cloud que monitora automaticamente as configurações de rede da nuvem privada virtual (VPC) para detectar configurações incorretas e abaixo do ideal. O Network Analyzer opera continuamente, executando testes e gerando insights de forma proativa para ajudar você a identificar, diagnosticar e resolver problemas de rede antes que eles afetem a disponibilidade do serviço.
O Network Analyzer pode monitorar sub-redes usadas para acesso privado a serviços (PSA) e fornece insights específicos relacionados a elas. Essa é uma função essencial para gerenciar serviços como Cloud SQL, Memorystore e Vertex AI, que usam PSA.
A principal maneira de o Network Analyzer monitorar as sub-redes de PSA é fornecendo insights sobre a utilização de endereços IP para os intervalos alocados.
Utilização do intervalo de PSA: o Network Analyzer rastreia ativamente a porcentagem de alocação de endereços IP nos blocos CIDR dedicados que você alocou para o PSA. Isso é importante porque, ao criar um serviço gerenciado (como a Vertex AI), o Google cria uma VPC de produtor de serviços e uma sub-rede nela, extraindo um intervalo de IP do bloco alocado.
Alertas proativos: se a utilização de endereços IP de um intervalo alocado de PSA exceder um determinado limite (por exemplo, 75%), o Network Analyzer vai gerar um insight de aviso. Isso alerta proativamente sobre possíveis problemas de capacidade, tempo para expandir o intervalo de IP alocado antes de ficar sem endereços disponíveis para novos recursos de serviço.
Atualizações de sub-rede do Acesso a serviços particulares
Para implantações do Ray na Vertex AI, o Google recomenda alocar um bloco CIDR /16 ou /17 para sua conexão de PSA. Isso fornece um bloco contíguo de endereços IP grande o suficiente para oferecer suporte a um escalonamento significativo, acomodando até 65.536 ou 32.768 endereços IP exclusivos, respectivamente. Isso ajuda a evitar o esgotamento de IP, mesmo com clusters grandes do Ray.
Se você esgotar o espaço de endereços IP alocado, Google Cloud retornará este erro:
Falha ao criar sub-rede. Não foi possível encontrar blocos gratuitos em intervalos de IP alocados.
Recomendamos que você expanda o intervalo de sub-rede atual ou aloque um intervalo que acomode o crescimento futuro.
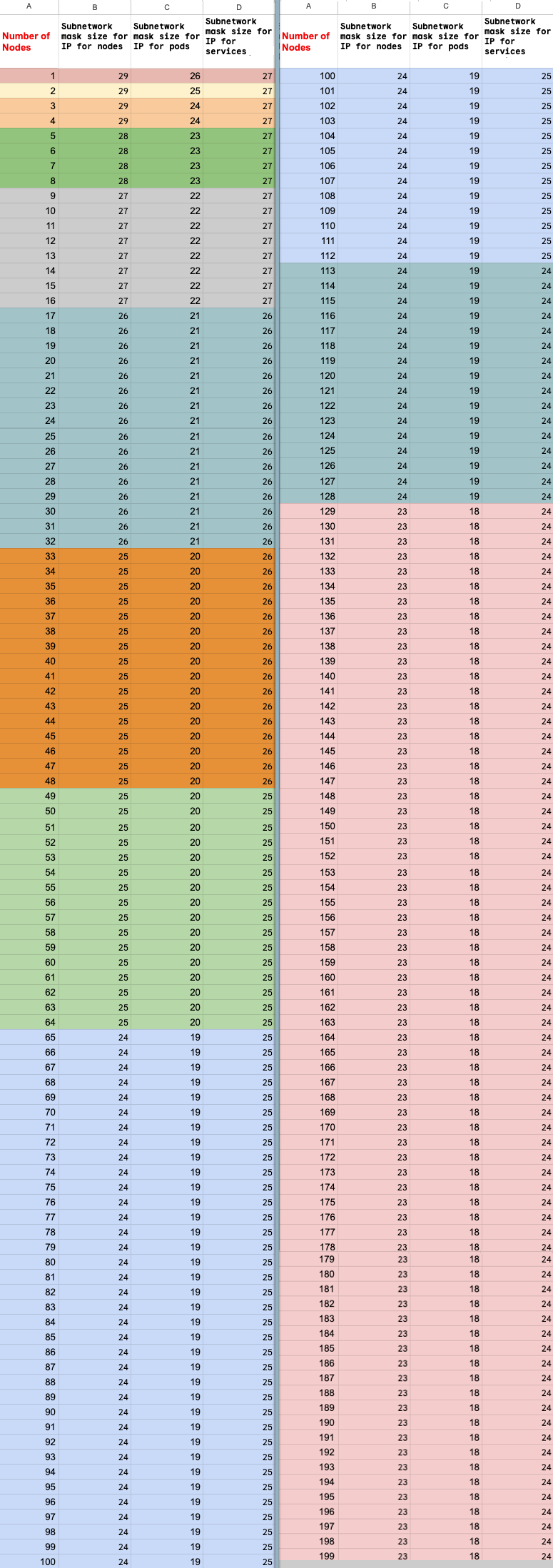
Cálculo do número máximo de nós
Se você usa o Acesso a serviços particulares (peering de VPC) para se conectar
aos nós, use as fórmulas a seguir para verificar se não excedeu o
número máximo de nós (M), supondo que f(x) = min(29, (32 -
ceiling(log2(x))):
f(2 * M) = f(2 * N)f(64 * M) = f(64 * N)f(max(32, 16 + M)) = f(max(32, 16 + N))
O número total máximo de nós no cluster do Ray na Vertex AI que pode ser escalonado verticalmente (M) depende do número total inicial de nós que você configurou (N). Depois de criar o cluster do Ray na Vertex AI, é possível escalonar o número total de nós para qualquer valor entre P e M, em que P é o número de pools do cluster.
O número total inicial de nós no cluster e a meta de escalonamento vertical deve estar no mesmo bloco de cor.
Atualizar contagem de réplicas
Use o console Google Cloud ou o SDK da Vertex AI para Python para atualizar a contagem de réplicas do pool de workers. Se o cluster inclui vários pools de workers, é possível mudar individualmente cada uma das contagens de réplica em uma única solicitação.
SDK do Ray na Vertex AI
import vertexai import vertex_ray vertexai.init() cluster = vertex_ray.get_ray_cluster("CLUSTER_NAME") # Get the resource name. cluster_resource_name = cluster.cluster_resource_name # Create the new worker pools new_worker_node_types = [] for worker_node_type in cluster.worker_node_types: worker_node_type.node_count = REPLICA_COUNT # new worker pool size new_worker_node_types.append(worker_node_type) # Make update call updated_cluster_resource_name = vertex_ray.update_ray_cluster( cluster_resource_name=cluster_resource_name, worker_node_types=new_worker_node_types, )
Console
No console Google Cloud , acesse a página do Ray na Vertex AI.
Na lista de clusters, clique naquele que você quer modificar.
Na página Detalhes do cluster, clique em Editar cluster.
No painel Editar cluster, selecione o pool de workers a ser atualizado e modifique a contagem de réplicas.
Clique em Atualizar.
Aguarde alguns minutos para que o cluster seja atualizado. Quando a atualização for concluída, você poderá ver a contagem de réplicas atualizada na página Detalhes do cluster.
Clique em Criar.