Os clusters do Ray na Vertex AI oferecem duas opções de escalabilidade: escalabilidade automática e escalabilidade manual. O redimensionamento automático permite que o cluster ajuste automaticamente o número de nós de trabalho com base nos recursos que as tarefas e os atores do Ray requerem. Se executar uma carga de trabalho pesada e não tiver a certeza dos recursos necessários, recomendamos a escala automática. O ajuste de escala manual dá aos utilizadores um controlo mais detalhado dos nós.
O dimensionamento automático pode reduzir os custos da carga de trabalho, mas adiciona custos gerais de lançamento de nós e pode ser difícil de configurar. Se está a usar o Ray pela primeira vez, comece por usar clusters sem escalamento automático e use a funcionalidade de escalamento manual.
Escala automática
Ative a funcionalidade de escala automática de um cluster do Ray especificando o número mínimo de réplicas (min_replica_count) e o número máximo de réplicas (max_replica_count) de um grupo de trabalhadores.
Tenha em conta o seguinte:
- Configure a especificação do escalamento automático de todos os conjuntos de trabalhadores.
- A velocidade de aumento e redução personalizados não é suportada. Para os valores predefinidos, consulte Velocidade de aumento e redução da escala na documentação do Ray.
Defina a especificação de dimensionamento automático do grupo de trabalhadores
Use a Google Cloud consola ou o SDK Vertex AI para Python para ativar a funcionalidade de escalabilidade automática de um cluster Ray.
SDK Ray on Vertex AI
from google.cloud import aiplatform import vertex_ray from vertex_ray import AutoscalingSpec autoscaling_spec = AutoscalingSpec( min_replica_count=1, max_replica_count=3, ) head_node_type = Resources( machine_type="n1-standard-16", node_count=1, ) worker_node_types = [Resources( machine_type="n1-standard-16", accelerator_type="NVIDIA_TESLA_T4", accelerator_count=1, autoscaling_spec=autoscaling_spec, )] # Create the Ray cluster on Vertex AI CLUSTER_RESOURCE_NAME = vertex_ray.create_ray_cluster( head_node_type=head_node_type, worker_node_types=worker_node_types, ... )
Consola
De acordo com a recomendação da prática recomendada da OSS Ray, a definição da contagem de CPUs lógicas para 0 no nó principal do Ray é aplicada para evitar a execução de qualquer carga de trabalho no nó principal.
Na Google Cloud consola, aceda à página Ray no Vertex AI.
Clique em Criar cluster para abrir o painel Criar cluster.
Para cada passo no painel Criar cluster, reveja ou substitua as informações do cluster predefinidas. Clique em Continuar para concluir cada passo:
- Em Nome e região, especifique um Nome e escolha uma localização para o seu cluster.
Para Definições de computação, especifique a configuração do cluster Ray no nó principal, incluindo o respetivo tipo de máquina, tipo e quantidade de acelerador, tipo e tamanho do disco, e quantidade de réplicas. Opcionalmente, adicione um URI de imagem personalizado para especificar uma imagem de contentor personalizada para adicionar dependências do Python não fornecidas pela imagem de contentor predefinida. Consulte Imagem personalizada.
Em Opções avançadas, pode:
- Especifique a sua própria chave de encriptação.
- Especifique uma conta de serviço personalizada.
- Se não precisar de monitorizar as estatísticas de recursos da sua carga de trabalho durante a preparação, desative a recolha de métricas.
Para criar um cluster com um grupo de trabalhadores de escalamento automático, indique um valor para o número máximo de réplicas do grupo de trabalhadores.
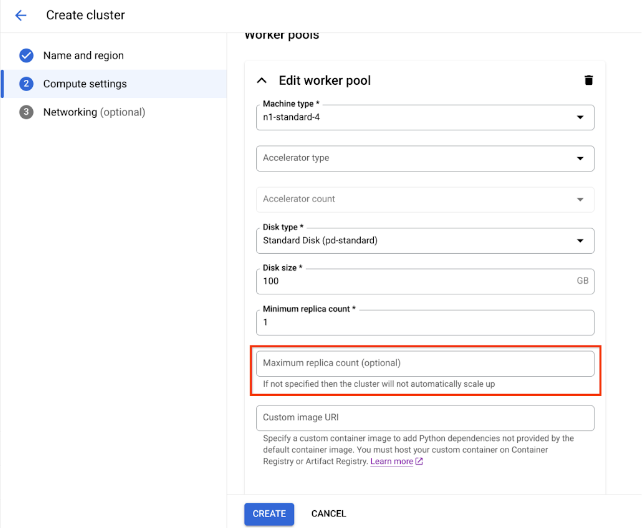
Clique em Criar.
Escala manual
À medida que as cargas de trabalho aumentam ou diminuem nos seus clusters do Ray no Vertex AI, dimensione manualmente o número de réplicas para corresponder à procura. Por exemplo, se tiver capacidade excessiva, reduza as suas pools de trabalhadores para poupar custos.
Limitações com o intercâmbio da VPC
Quando dimensiona clusters, só pode alterar o número de réplicas nos pools de trabalhadores existentes. Por exemplo, não pode adicionar nem remover grupos de trabalhadores do cluster, nem alterar o tipo de máquina dos grupos de trabalhadores. Além disso, o número de réplicas dos grupos de trabalhadores não pode ser inferior a um.
Se usar uma ligação de peering de VPC para se ligar aos seus clusters, existe uma limitação no número máximo de nós. O número máximo de nós depende do número de nós que o cluster tinha quando o criou. Para mais informações, consulte o artigo Cálculo do número máximo de nós. Este número máximo inclui não só os seus conjuntos de trabalhadores, mas também o nó principal. Se usar a configuração de rede predefinida, o número de nós não pode exceder os limites superiores, conforme descrito na documentação criar clusters.
Práticas recomendadas para a atribuição de sub-redes
Quando implementa o Ray no Vertex AI através do acesso a serviços privados (PSA), é fundamental garantir que o intervalo de endereços IP atribuído é suficientemente grande e contíguo para acomodar o número máximo de nós para o qual o cluster pode ser dimensionado. O esgotamento de IPs pode ocorrer se o intervalo de IPs reservado para a sua ligação de PSA for demasiado pequeno ou fragmentado, o que leva a falhas na implementação.
Em alternativa, recomendamos a implementação do Ray na Vertex AI com uma interface do Private Service Connect, que reduz o consumo de IP para uma sub-rede /28.
Monitorização do acesso privado ao serviço
Como prática recomendada, use o analisador de rede uma ferramenta de diagnóstico no Network Intelligence Center do Google Cloud que monitoriza automaticamente as configurações da sua rede de nuvem virtual privada (VPC) para detetar configurações incorretas e definições abaixo do ideal. O Network Analyzer funciona continuamente, o que executa proativamente testes e gera estatísticas para ajudar a identificar, diagnosticar e resolver problemas de rede antes de afetarem a disponibilidade do serviço.
O Analisador de rede tem a capacidade de monitorizar sub-redes usadas para o acesso privado ao serviço (PSA) e fornece estatísticas específicas relacionadas com as mesmas. Esta é uma função essencial para gerir serviços como o Cloud SQL, o Memorystore e o Vertex AI, que usam o PSA.
A principal forma como o analisador de rede monitoriza as sub-redes de PSA é através da disponibilização de estatísticas de utilização de endereços IP para os intervalos atribuídos.
Utilização do intervalo de ASP: o analisador de rede monitoriza ativamente a percentagem de atribuição de endereços IP nos blocos CIDR dedicados que atribuiu para ASP. Isto é importante porque, quando cria um serviço gerido (como o Vertex AI), a Google cria uma VPC do produtor de serviços e uma sub-rede na mesma, retirando um intervalo de IP do seu bloco atribuído.
Alertas proativos: se a utilização de endereços IP para um intervalo atribuído de PSA exceder um determinado limite (por exemplo, 75%), o Network Analyzer gera uma estatística de aviso. Isto alerta-o proativamente para potenciais problemas de capacidade, dando-lhe tempo para expandir o intervalo de IP atribuído antes de ficar sem endereços disponíveis para novos recursos de serviço.
Atualizações da sub-rede do acesso privado ao serviço
Para implementações do Ray na Vertex AI, a Google recomenda a atribuição de um bloco CIDR /16 ou /17 para a sua ligação PSA. Isto fornece um bloco contíguo de endereços IP suficientemente grande para suportar uma escalabilidade significativa, acomodando até 65 536 ou 32 768 endereços IP únicos, respetivamente. Isto ajuda a evitar o esgotamento de IPs, mesmo com grandes clusters do Ray.
Se esgotar o espaço de endereços IP atribuído, Google Cloud é devolvido este erro:
Não foi possível criar a sub-rede. Não foi possível encontrar blocos livres nos intervalos de IP atribuídos.
Recomendamos que expanda o intervalo de sub-rede atual ou atribua um intervalo que acomode o crescimento futuro.
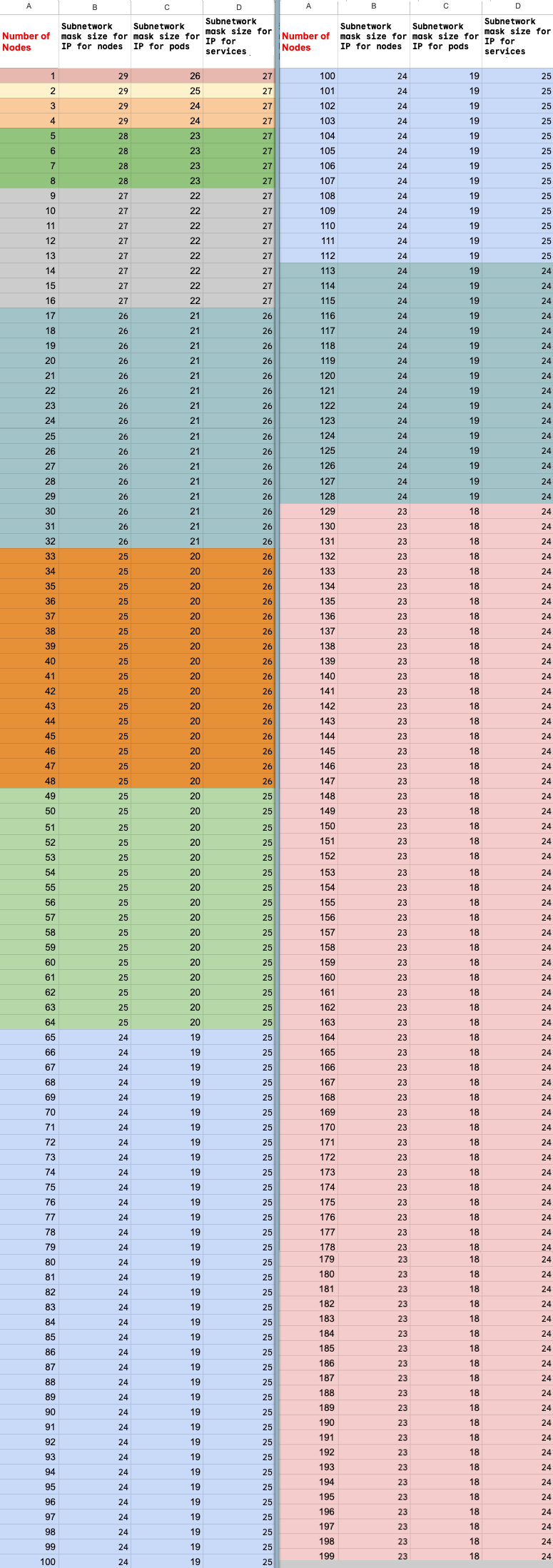
Cálculo do número máximo de nós
Se usar o acesso a serviços privados (interligação de VPCs) para se ligar aos seus nós, use as seguintes fórmulas para verificar se não excede o número máximo de nós (M), partindo do princípio de que f(x) = min(29, (32 -
ceiling(log2(x))):
f(2 * M) = f(2 * N)f(64 * M) = f(64 * N)f(max(32, 16 + M)) = f(max(32, 16 + N))
O número total máximo de nós no cluster do Ray na Vertex AI para o qual pode aumentar a escala (M) depende do número total inicial de nós que configurou (N). Depois de criar o cluster do Ray na Vertex AI, pode aumentar a escala do número total de nós para qualquer valor entre P e M, inclusive, em que P é o número de pools no seu cluster.
O número total inicial de nós no cluster e o número de destino de expansão têm de estar no mesmo bloco de cores.
Atualize a contagem de réplicas
Use a Google Cloud consola ou o Vertex AI SDK para Python para atualizar a quantidade de réplicas do seu grupo de trabalhadores. Se o seu cluster incluir vários conjuntos de trabalhadores, pode alterar individualmente a quantidade de réplicas de cada um deles num único pedido.
SDK Ray on Vertex AI
import vertexai import vertex_ray vertexai.init() cluster = vertex_ray.get_ray_cluster("CLUSTER_NAME") # Get the resource name. cluster_resource_name = cluster.cluster_resource_name # Create the new worker pools new_worker_node_types = [] for worker_node_type in cluster.worker_node_types: worker_node_type.node_count = REPLICA_COUNT # new worker pool size new_worker_node_types.append(worker_node_type) # Make update call updated_cluster_resource_name = vertex_ray.update_ray_cluster( cluster_resource_name=cluster_resource_name, worker_node_types=new_worker_node_types, )
Consola
Na Google Cloud consola, aceda à página Ray no Vertex AI.
Na lista de clusters, clique no cluster que quer modificar.
Na página Detalhes do cluster, clique em Editar cluster.
No painel Editar cluster, selecione o conjunto de trabalhadores a atualizar e, de seguida, modifique a quantidade de réplicas.
Clique em Atualizar.
Aguarde alguns minutos para que o cluster seja atualizado. Quando a atualização estiver concluída, pode ver a contagem de réplicas atualizada na página Detalhes do cluster.
Clique em Criar.