Esta página fornece uma vista geral do Vertex AI Model Monitoring.
Vista geral da monitorização
O Vertex AI Model Monitoring permite-lhe executar tarefas de monitorização conforme necessário ou num horário regular para acompanhar a qualidade dos seus modelos tabulares. Se tiver definido alertas, o Vertex AI Model Monitoring informa quando as métricas ultrapassam um limite especificado.
Por exemplo, suponha que tem um modelo que prevê o valor do cliente. À medida que os hábitos dos clientes mudam, os fatores que preveem os gastos dos clientes também mudam. Consequentemente, as funcionalidades e os valores das funcionalidades que usou para preparar o modelo antes podem não ser relevantes para fazer inferências hoje. Este desvio nos dados é conhecido como desvio.
O Vertex AI Model Monitoring pode monitorizar e enviar-lhe alertas quando os desvios excederem um limite especificado. Em seguida, pode reavaliar ou voltar a formar o modelo para garantir que o modelo está a funcionar conforme previsto.
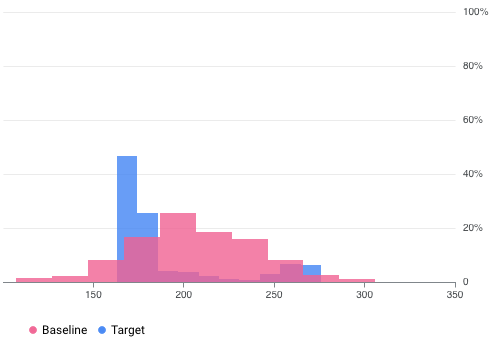
Por exemplo, o Vertex AI Model Monitoring pode fornecer visualizações como na figura seguinte, que sobrepõe dois gráficos de dois conjuntos de dados. Esta visualização permite-lhe comparar rapidamente e ver desvios entre os dois conjuntos de dados.
Versões do Vertex AI Model Monitoring
O Vertex AI Model Monitoring oferece duas opções: v2 e v1.
A monitorização de modelos v2 está em pré-visualização e é a oferta mais recente que associa todas as tarefas de monitorização a uma versão do modelo. Por outro lado, o Model Monitoring v1 está disponível de forma geral e é configurado em pontos finais da Vertex AI.
Se precisar de apoio técnico ao nível de produção e quiser monitorizar um modelo implementado num ponto final da Vertex AI, use o Model Monitoring v1. Para todos os outros exemplos de utilização, use a monitorização de modelos v2, que oferece todas as capacidades da monitorização de modelos v1 e muito mais. Para mais informações, consulte a vista geral de cada versão:
Para os utilizadores existentes da monitorização de modelos v1, a monitorização de modelos v1 é mantida tal como está. Não tem de migrar para a monitorização de modelos v2. Se quiser migrar, pode usar ambas as versões em simultâneo até ter migrado totalmente para a monitorização de modelos v2 para ajudar a evitar lacunas de monitorização durante a transição.
Vista geral do Model Monitoring v2
A monitorização de modelos v2 permite-lhe acompanhar as métricas ao longo do tempo depois de configurar uma monitorização de modelos e executar tarefas de monitorização. Pode executar tarefas de monitorização a pedido ou configurar execuções agendadas. Ao usar execuções programadas, a monitorização de modelos executa automaticamente tarefas de monitorização com base num horário que definir.
Objetivos de monitorização
As métricas e os limites que monitoriza são mapeados para objetivos de monitorização. Para cada versão do modelo, pode especificar um ou mais objetivos de monitorização. A tabela seguinte detalha cada objetivo:
| Objetivo | Descrição | Tipo de dados de funcionalidades | Métricas compatíveis |
|---|---|---|---|
| Desvio de dados de funcionalidades de entrada |
Mede a distribuição dos valores das caraterísticas de entrada em comparação com uma distribuição de dados de base. |
Categorical: booleano, string, categórico |
|
| Numérico: float, integer | Divergência de Jensen-Shannon | ||
| Desvio dos dados de inferência de saída |
Mede a distribuição de dados das inferências do modelo em comparação com uma distribuição de dados de base. |
Categorical: booleano, string, categórico |
|
| Numérico: float, integer | Divergência de Jensen-Shannon | ||
| Atribuição de funcionalidades |
Mede a alteração na contribuição das caraterísticas para a inferência de um modelo em comparação com uma base. Por exemplo, pode monitorizar se uma funcionalidade muito importante perde subitamente importância. |
Todos os tipos de dados | Valor SHAP (SHapley Additive exPlanations) |
Desvio da funcionalidade de entrada e da inferência de saída
Depois de um modelo ser implementado em produção, os dados de entrada podem desviar-se dos dados que foram usados para preparar o modelo, ou a distribuição dos dados das caraterísticas em produção pode mudar significativamente ao longo do tempo. A monitorização de modelos v2 pode monitorizar alterações na distribuição de dados de produção em comparação com os dados de preparação ou acompanhar a evolução da distribuição de dados de produção ao longo do tempo.
Da mesma forma, para os dados de inferência, a monitorização de modelos v2 pode monitorizar as alterações na distribuição dos resultados previstos em comparação com a distribuição dos dados de treino ou dos dados de produção ao longo do tempo.
Atribuição de funcionalidades
As atribuições de funcionalidades indicam a contribuição de cada funcionalidade no seu modelo para as inferências de cada instância específica. As pontuações de atribuição são proporcionais à contribuição da funcionalidade para a inferência de um modelo. Normalmente, são indicados com um sinal, o que indica se uma funcionalidade ajuda a aumentar ou diminuir a inferência. As atribuições em todas as funcionalidades têm de corresponder à pontuação de inferência do modelo.
Ao monitorizar as atribuições de funcionalidades, a monitorização de modelos v2 acompanha as alterações nas contribuições de uma funcionalidade para as inferências de um modelo ao longo do tempo. Uma alteração na pontuação de atribuição de uma funcionalidade principal indica frequentemente que a funcionalidade foi alterada de uma forma que pode afetar a precisão das inferências do modelo.
Para mais informações sobre as atribuições de funcionalidades e as métricas, consulte os artigos Explicações baseadas em funcionalidades e Método Shapley de amostragem.
Como configurar a monitorização de modelos v2
Primeiro, tem de registar os seus modelos no Registo de modelos do Vertex AI. Se estiver a publicar modelos fora do Vertex AI, não precisa de carregar o artefacto do modelo. Em seguida, cria um monitor de modelo, que associa a uma versão do modelo e define o esquema do modelo. Para alguns modelos, como os modelos do AutoML, o esquema é fornecido.
No monitor de modelos, pode especificar opcionalmente configurações predefinidas, como objetivos de monitorização, um conjunto de dados de preparação, a localização de saída da monitorização e definições de notificação. Para mais informações, consulte o artigo Configure a monitorização de modelos.
Depois de criar uma monitorização de modelos, pode executar uma tarefa de monitorização a pedido ou programar tarefas regulares para uma monitorização contínua. Quando executa uma tarefa, a Monitorização de modelos usa a configuração predefinida definida no monitor de modelos, a menos que forneça uma configuração de monitorização diferente. Por exemplo, se fornecer objetivos de monitorização diferentes ou um conjunto de dados de comparação diferente, a monitorização de modelos usa as configurações da tarefa em vez da configuração predefinida do monitor de modelos. Para mais informações, consulte o artigo Execute uma tarefa de monitorização.
Preços
Não lhe é cobrado o Model Monitoring v2 durante a pré-visualização. Continua a pagar a utilização de outros serviços, como o Cloud Storage, o BigQuery, as inferências em lote do Vertex AI, o Vertex Explainable AI e o Cloud Logging.
Tutoriais do bloco de notas
Os tutoriais seguintes demonstram como usar o SDK Vertex AI para Python para configurar a monitorização de modelos v2 para o seu modelo.
Monitorização de modelos v2: tarefa de inferência em lote de modelo personalizado
Monitorização de modelos v2: inferência online de modelos personalizados
Model Monitoring v2: modelos fora da Vertex AI
Vista geral do Model Monitoring v1
Para ajudar a manter o desempenho de um modelo, a Model Monitoring v1 monitoriza os dados de entrada de inferência do modelo quanto à distorção e à deriva de caraterísticas:
A divergência entre a preparação e o fornecimento ocorre quando a distribuição de dados de funcionalidades na produção se desvia da distribuição de dados de funcionalidades usada para preparar o modelo. Se os dados de preparação originais estiverem disponíveis, pode ativar a deteção de desequilíbrios para monitorizar os seus modelos quanto a desequilíbrios entre a preparação e a publicação.
A deriva de inferência ocorre quando a distribuição de dados de funcionalidades na produção muda significativamente ao longo do tempo. Se os dados de preparação originais não estiverem disponíveis, pode ativar a deteção de desvio para monitorizar as alterações nos dados de entrada ao longo do tempo.
Pode ativar a deteção de distorção e desvio.
A monitorização de modelos v1 suporta a deteção de desvios e deriva de funcionalidades para funcionalidades categóricas e numéricas:
As funcionalidades categóricas são dados limitados pelo número de valores possíveis, normalmente agrupados por propriedades qualitativas. Por exemplo, categorias como tipo de produto, país ou tipo de cliente.
As funcionalidades numéricas são dados que podem ser qualquer valor numérico. Por exemplo, o peso e a altura.
Quando a distorção ou a variação de uma funcionalidade de um modelo excede um limite de alerta que definiu, a monitorização de modelos v1 envia-lhe um alerta por email. Também pode ver as distribuições de cada funcionalidade ao longo do tempo para avaliar se precisa de voltar a preparar o modelo.
Calcule a deriva
Para detetar a variação para a v1, o Vertex AI Model Monitoring usa a validação de dados do TensorFlow (TFDV) para calcular as distribuições e as pontuações de distância.
Calcular a distribuição estatística da base:
Para a deteção de desvios, a base é a distribuição estatística dos valores da funcionalidade nos dados de preparação.
Para a deteção de desvio, a base é a distribuição estatística dos valores da funcionalidade observados em produção no passado.
As distribuições para caraterísticas categóricas e numéricas são calculadas da seguinte forma:
Para funcionalidades categóricas, a distribuição calculada é o número ou a percentagem de instâncias de cada valor possível da funcionalidade.
Para as caraterísticas numéricas, o Vertex AI Model Monitoring divide o intervalo de valores possíveis das caraterísticas em intervalos iguais e calcula o número ou a percentagem de valores das caraterísticas que se enquadram em cada intervalo.
A base é calculada quando cria uma tarefa do Vertex AI Model Monitoring e só é recalculada se atualizar o conjunto de dados de preparação da tarefa.
Calcular a distribuição estatística dos valores das funcionalidades mais recentes observados na produção.
Compare a distribuição dos valores das funcionalidades mais recentes em produção com a distribuição de base calculando uma pontuação de distância:
Para as caraterísticas categóricas, a pontuação de distância é calculada através da distância L-infinity.
Para as caraterísticas numéricas, a pontuação de distância é calculada através da divergência de Jensen-Shannon.
Quando a pontuação de distância entre duas distribuições estatísticas excede o limite especificado, o Vertex AI Model Monitoring identifica a anomalia como desvio ou deriva.
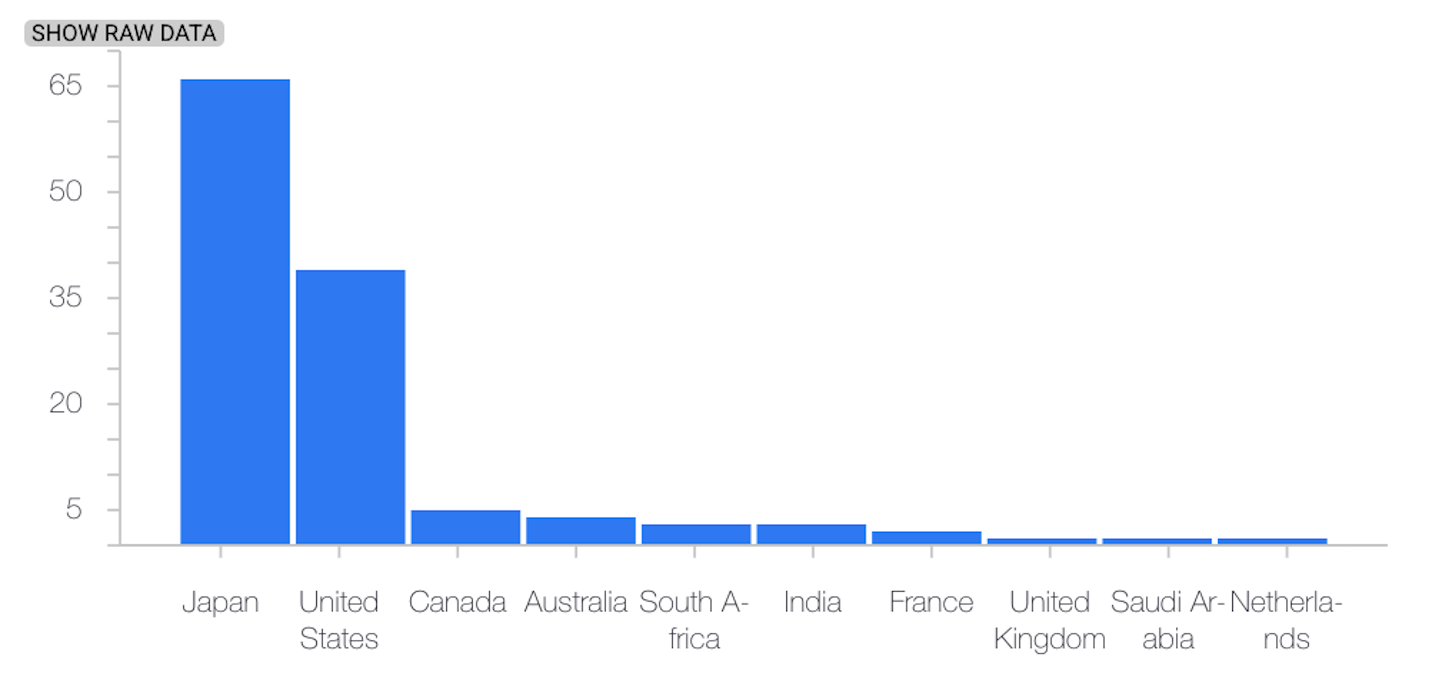
O exemplo seguinte mostra a distorção ou a deriva entre as distribuições de referência e as mais recentes de uma caraterística categorial:
Distribuição de base
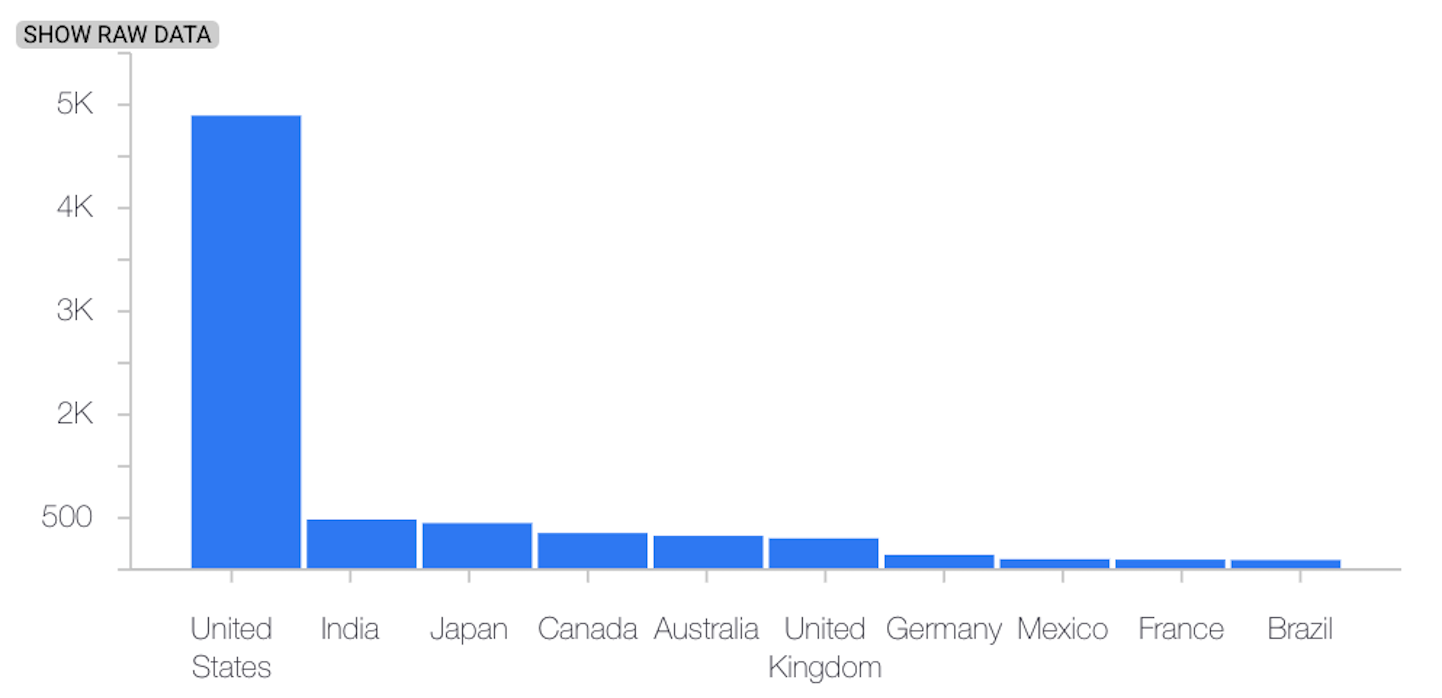
Distribuição mais recente
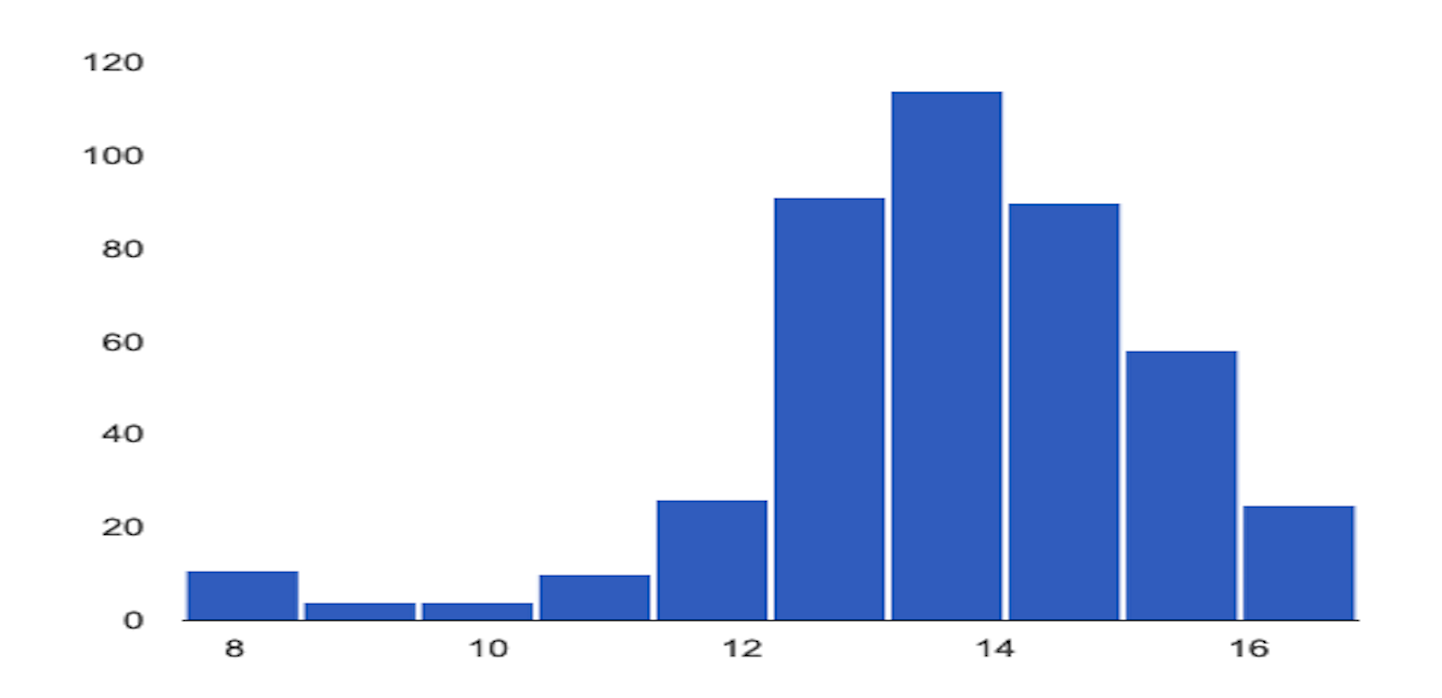
O exemplo seguinte mostra a distorção ou a deriva entre as distribuições de base e as distribuições mais recentes de uma caraterística numérica:
Distribuição de base
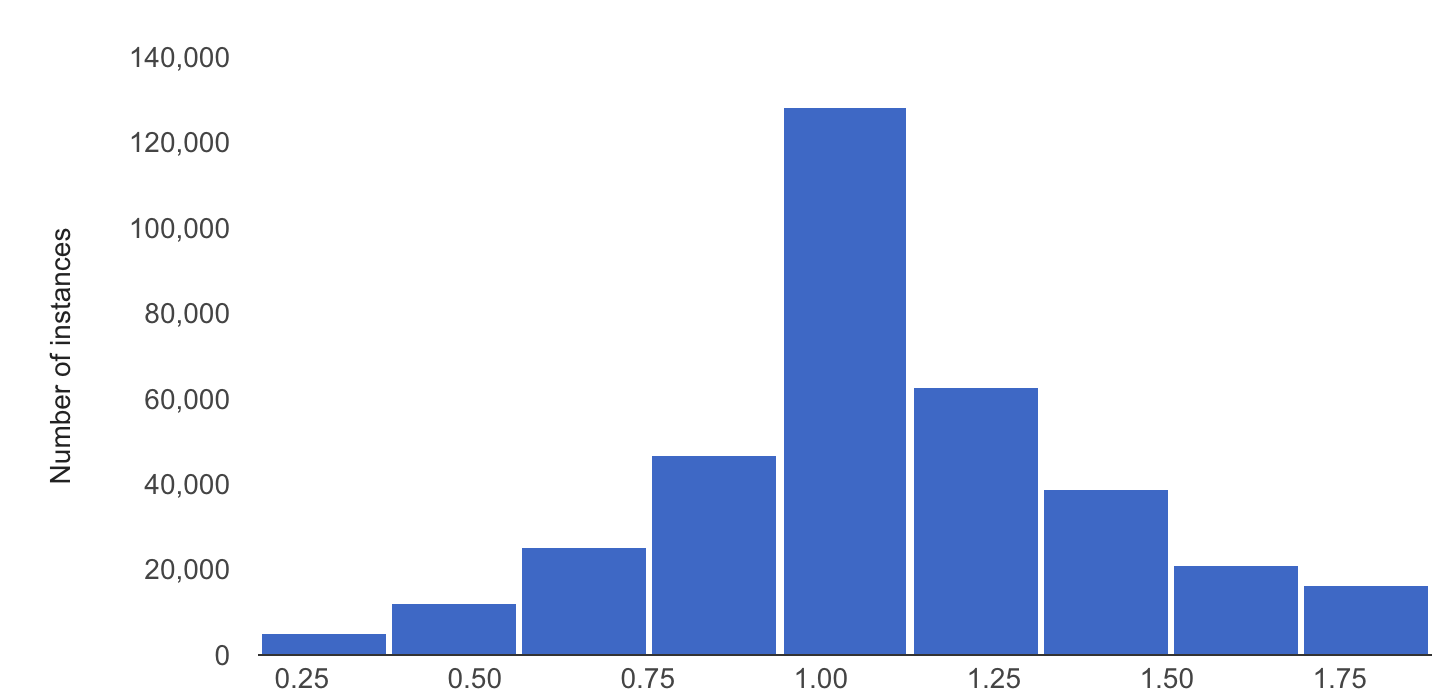
Distribuição mais recente
Considerações sobre a utilização da monitorização de modelos
Para rentabilizar os custos, pode definir uma taxa de amostragem de pedidos de inferência para monitorizar um subconjunto das entradas de produção de um modelo.
Pode definir uma frequência com a qual as entradas registadas recentemente de um modelo implementado são monitorizadas quanto a desvio ou deriva. A frequência de monitorização determina o intervalo de tempo ou a dimensão do período de monitorização dos dados registados que são analisados em cada execução de monitorização.
Pode especificar limites de alerta para cada funcionalidade que quer monitorizar. É registado um alerta quando a distância estatística entre a distribuição da funcionalidade de entrada e a respetiva referência excede o limite especificado. Por predefinição, todas as funcionalidades categóricas e numéricas são monitorizadas com valores de limite de 0, 3.
Um ponto final de inferência online pode alojar vários modelos. Quando ativa a deteção de desvio ou deriva num ponto final, os seguintes parâmetros de configuração são partilhados por todos os modelos alojados nesse ponto final:
- Tipo de deteção
- Frequência de monitorização
- Fração de pedidos de entrada monitorizados
Para os outros parâmetros de configuração, pode definir valores diferentes para cada modelo.