Diese Seite bietet eine Übersicht über Vertex AI-Modellmonitoring.
Monitoring-Übersicht
Mit Vertex AI Model Monitoring können Sie Monitoringjobs nach Bedarf oder auf einem regelmäßiger Zeitplan ausführen, um die Qualität Ihrer tabellarischen Modelle zu verfolgen. Wenn Sie Benachrichtigungen festgelegt haben, informiert das Vertex AI Model Monitoring Sie, wenn Messwerte eine festgelegten Schwellenwert überschreiten.
Angenommen, Sie haben ein Modell, das den Customer Lifetime Value prognostiziert. Mit dem sich ändernden Kundenverhalten ändern sich auch die Faktoren, die die Ausgaben der Kundschaft vorhersagen. Daher sind die Features und Featurewerte, die Sie zum Trainieren Ihres Modells verwendet haben, derzeit möglicherweise nicht für Vorhersagen relevant. Diese Abweichung in den Daten wird als Drift bezeichnet.
Mit Vertex AI Model Monitoring kann nachverfolgen und Sie benachrichtigen, wenn Abweichungen einen bestimmten Schwellenwert überschreiten. Sie können Ihr Modell dann neu bewerten oder neu trainieren, damit sich das Modell wie vorgesehen verhält.
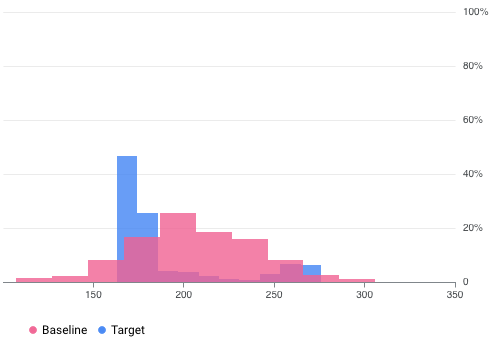
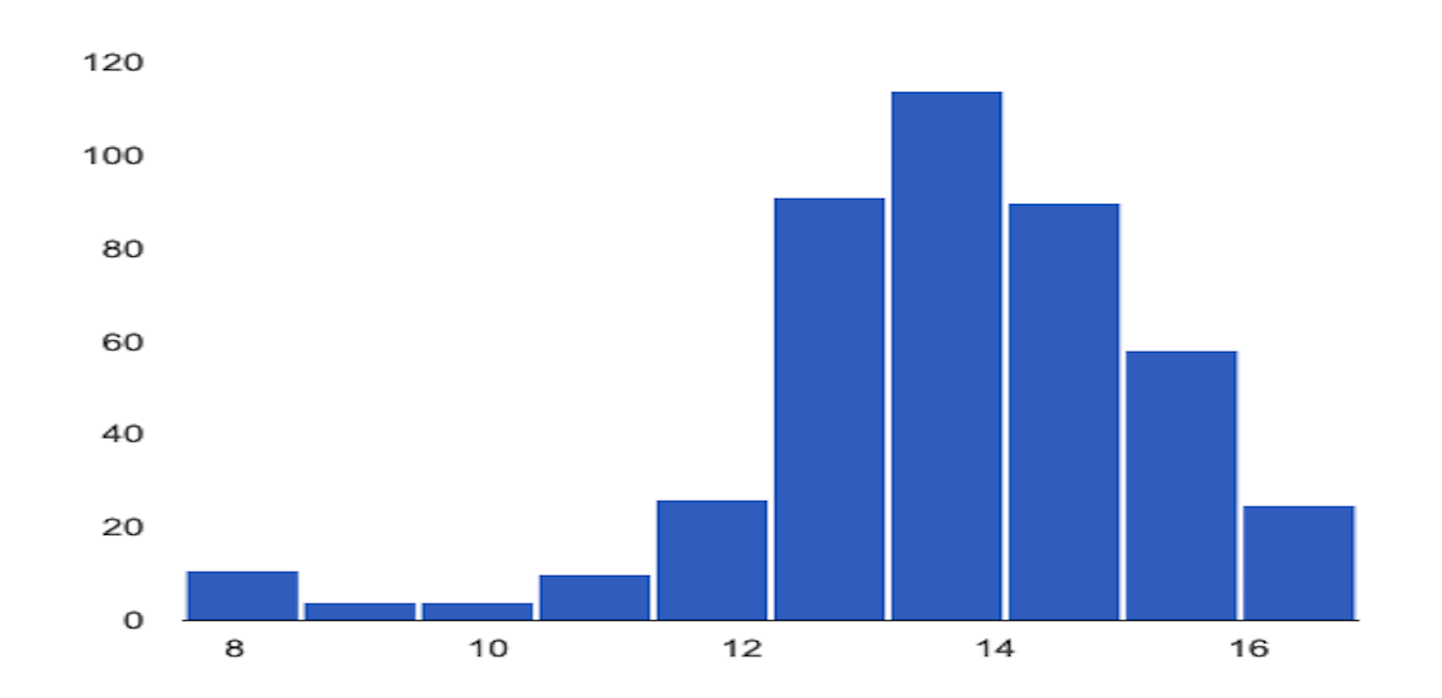
Vertex AI Model Monitoring kann beispielsweise Visualisierungen wie in folgende Abbildung bereitstellen, die zwei Diagramme aus zwei Datasets überlagert. Diese Visualisierung ermöglicht Ihnen einen schnellen Vergleich und die Darstellung von Abweichungen zwischen den beiden Mengen von Daten.
Vertex AI Model Monitoring-Versionen
Vertex AI Model Monitoring bietet zwei Angebote: v2 und v1.
Model Monitoring v2 befindet sich in der Vorschau und ist das neueste Angebot, das alle Monitoring-Aufgaben mit einer Modellversion verknüpft. Im Gegensatz dazu ist Model Monitoring v1 allgemein verfügbar und auf Vertex AI-Endpunkten konfiguriert.
Wenn Sie Support auf Produktionsebene benötigen und ein auf einem Vertex AI-Endpunkt bereitgestelltes Modell überwachen möchten, verwenden Sie Model Monitoring v1. Verwenden Sie für alle anderen Anwendungsfälle Model Monitoring v2, die alle Funktionen von Model Monitoring v1 und mehr bietet. Weitere Informationen finden Sie in der Übersicht der einzelnen Versionen:
Für bestehende Nutzer von Model Monitoring v1 wird Model Monitoring v1 unverändert beibehalten. Sie müssen nicht zu Model Monitoring v2 migrieren. Wenn Sie migrieren möchten, können Sie beide Versionen verwenden bis Sie vollständig zu Model Monitoring v2 migriert sind. So vermeiden Sie Überwachungslücken während des Übergangs.
Model Monitoring v2 – Übersicht
Mit Model Monitoring v2 können Sie Messwerte im Zeitverlauf verfolgen, nachdem Sie ein Modellmonitoring konfiguriert haben und Monitoringjobs ausführen. Sie können On-Demand-Monitoringjobs ausführen oder geplante Ausführungen einrichten. Mit geplanten Ausführungen kann das Modellmonitoring automatisch Monitoringjobs nach einem von Ihnen definierten Zeitplan ausführen.
Monitoringziele
Die von Ihnen beobachteten Messwerte und Schwellenwerte werden Monitoringzielen zugeordnet. Sie können für jede Modellversion ein oder mehrere Monitoringziele angeben. In der folgenden Tabelle sind die einzelnen Ziele aufgeführt:
| Ziel | Beschreibung | Feature-Datentyp | Unterstützte Messwerte |
|---|---|---|---|
| Datendrift bei Eingabefeatures |
Misst die Verteilung der Eingabefeaturewerte im Vergleich zu einer Referenz-Datenverteilung. |
Kategorial: boolescher Wert, String, kategorial |
|
| Numerisch: Gleitkommazahl, Ganzzahl | Jensen Shannon Divergence | ||
| Drift von Ausgabevorhersagedaten |
Misst die Datenverteilung der Vorhersagen des Modells im Vergleich zur Referenz-Datenverteilung. |
Kategorial: boolescher Wert, String, kategorial |
|
| Numerisch: Gleitkommazahl, Ganzzahl | Jensen Shannon Divergence | ||
| Featureattribution |
Misst die Änderung des Beitrags von Features zur Vorhersage eines Modells im Vergleich zur Baseline. So können Sie z. B. feststellen, ob ein wichtiges Feature plötzlich an Bedeutung verliert. |
Alle Datentypen | SHAP-Wert (SHapley additive exPlanations) |
Eingabefeature- und Ausgabevorhersage-Drift
Nachdem ein Modell in der Produktion bereitgestellt wurde, können die Eingabedaten von den Daten abweichen, die zum Trainieren des Modells verwendet wurden, oder die Verteilung von Featuredaten in der Produktion kann sich im Laufe der Zeit erheblich verändern. Model Monitoring v2 kann Änderungen die Verteilung von Produktionsdaten im Vergleich zu den Trainingsdaten überwachen oder die Entwicklung der Verteilung von Produktionsdaten im Zeitverlauf verfolgen.
Ebenso kann Model Monitoring v2 für Vorhersagedaten Änderungen in der Verteilung der vorhergesagten Ergebnisse im Vergleich zur Trainingsdaten- oder Produktionsdaten-Verteilung im Zeitverlauf überwachen.
Featureattribution
Feature-Attributionen geben an, wie viel jedes Feature in Ihrem Modell zu den Vorhersagen für die jeweilige Instanz beigetragen hat. Die Attributionswerte sind proportional zum Beitrag des Features zur Vorhersage eines Modells. Sie sind normalerweise signiert und geben an, ob ein Feature die Vorhersage nach oben oder unten verschiebt. Attributionen für alle Features müssen insgesamt den Vorhersagewert des Modells ergeben.
Durch das Monitoring der Feature-Attributionen verfolgt das Model Monitoring v2 Änderungen in den Beiträgen eines Features zu den Vorhersagen eines Modells im Laufe der Zeit. Eine Änderung des Attributionswerts in einem Schlüsselfeature weist häufig darauf hin, dass sich das Feature so geändert hat, dass sich dies auf die Genauigkeit der Vorhersagen des Modells auswirken kann.
Weitere Informationen zu Featureattributionen und Messwerten finden Sie unter Featurebasierte Erläuterungen und Sampled Shapley-Methode.
Anleitung zum Einrichten von Model Monitoring v2
Sie müssen Ihre Modelle zuerst in der Vertex AI Model Registry registrieren. Wenn Sie Modelle außerhalb von Vertex AI bereitstellen, müssen Sie das Modellartefakt nicht hochladen. Anschließend erstellen Sie einen Modellmonitor, den Sie mit einer Modellversion verknüpfen, und definieren Ihr Modellschema. Bei einigen Modellen, z. B. AutoML-Modellen, wird das Schema für Sie bereitgestellt.
Im Modellmonitor können Sie optional Standardkonfigurationen wie folgende angeben: Monitoring-Ziele, ein Trainings-Dataset, das Ort der Monitoring-Ausgabe und Benachrichtigungseinstellungen. Weitere Informationen finden Sie unter Modell-Monitoring einrichten.
Nachdem Sie einen Modellmonitor erstellt haben, können Sie bei Bedarf einen Monitoringjob ausführen oder regelmäßige Jobs für ein kontinuierliches Monitoring planen. Wenn Sie einen Job ausführen, verwendet Model Monitoring die im Modellmonitor festgelegte Standardkonfiguration, wenn Sie keine andere Monitoringkonfiguration bereitstellen. Wenn Sie z. B. unterschiedliche Monitoringziele oder ein anderes Vergleichs-Dataset bereitstellen, verwendet das Modellmonitoring die Konfigurationen des Jobs anstelle der Standardkonfiguration aus dem Modellmonitor. Weitere Informationen finden Sie unter Monitoringjob ausführen.
Preise
Für Model Monitoring v2 fallen in der Vorabversion keine Gebühren an. Ihnen wird immer noch die Nutzung anderer Dienste wie Cloud Storage, BigQuery, Batchvorhersagen von Vertex AI, Vertex Explainable AI und Cloud Logging berechnet.
Notebook-Anleitungen
In den folgenden Anleitungen wird gezeigt, wie Sie das Vertex AI SDK für Python zum Einrichten von Model Monitoring v2 für Ihr Modell verwenden.
Model Monitoring v2: Batchvorhersagejob mit benutzerdefiniertem Modell
Model Monitoring v2: Onlinevorhersage mit benutzerdefiniertem Modell
Model Monitoring v2: Modelle außerhalb von Vertex AI
Model Monitoring v1 – Übersicht
Um die Leistung eines Modells aufrechtzuerhalten, überwacht Model Monitoring v1 die Vorhersageeingabedaten des Modells für Feature-Verzerrung und -Drift:
Abweichungen zwischen Training und Bereitstellung treten auf, wenn die Verteilung der Featuredaten in der Produktion von der Verteilung der Featuredaten abweicht, die zum Trainieren des Modells verwendet wurden. Wenn die ursprünglichen Trainingsdaten verfügbar sind, können Sie die Abweichungserkennung aktivieren, um Ihre Modelle auf Abweichungen zwischen Training und Bereitstellung zu überwachen.
Vorhersage-Drift tritt auf, wenn sich die Featuredatenverteilung in der Produktion im Laufe der Zeit erheblich ändert. Wenn die ursprünglichen Trainingsdaten nicht verfügbar sind, können Sie die Drifterkennung aktivieren, um die Eingabedaten auf Änderungen im Laufe der Zeit zu überwachen.
Sie können sowohl die Verzerrungs- als auch die Drifterkennung aktivieren.
Model Monitoring v1 unterstützt die Erkennung von Abweichung und Drift von Features für kategoriale und numerische Features.
Kategoriale Merkmale sind Daten, die durch die Anzahl möglicher Werte begrenzt sind, die in der Regel nach qualitativen Attributen gruppiert sind. Kategorien wie Produktkategorie, Land oder Kundentyp.
Numerische Merkmale sind Daten, die beliebige numerische Werte sein können. Beispiel: Gewicht und Höhe.
Sobald die Verzerrung oder der Drift für das Feature eines Modells einen von Ihnen bestimmten Schwellenwert für Benachrichtigungen überschreitet, sendet Ihnen Model Monitoring v1 eine E-Mail-Benachrichtigung. Sie können auch die Verteilungen für jedes Feature im Zeitverlauf anzeigen, um festzustellen, ob Sie Ihr Modell neu trainieren müssen.
Drift berechnen
Zum Erkennen von Drift für v1 verwendet Vertex AI Model Monitoring TensorFlow Datenvalidierung (TFDV) zur Berechnung der Verteilungen und Entfernungswerte.
Berechnen Sie die grundlegende statistische Verteilung:
Bei der Abweichungserkennung ist die Baseline die statistische Verteilung der Featurewerte in den Trainingsdaten.
Bei der Drifterkennung ist die Baseline die statistische Verteilung der zuletzt in der Produktion festgestellten Featurewerte.
Die Verteilungen für kategoriale und numerische Features werden so berechnet:
Bei kategorialen Features ist die berechnete Verteilung die Anzahl oder der Prozentsatz der Instanzen jedes möglichen Werts des Features.
Bei numerischen Features teilt Vertex AI Model Monitoring den Bereich möglicher Featurewerte in gleiche Intervalle auf und berechnet die Anzahl oder den Prozentsatz der Featurewerte, die in jedes Intervall fallen.
Die Referenz wird beim Erstellen eines Vertex AI Model Monitoring-Jobs berechnet und nur neu berechnet, wenn Sie das Trainings-Dataset für den Job aktualisieren.
Berechnen der statistischen Verteilung der neuesten in der Produktion verwendeten Featurewerte.
Vergleichen Sie die Verteilung der neuesten Featurewerte in der Produktion mit der Referenzverteilung. Dazu berechnen Sie einen Entfernungswert:
Bei kategorialen Merkmalen wird die Entfernungspunktzahl anhand der L-Infinity-Entfernung berechnet.
Für numerische Features wird die Entfernungspunktzahl mithilfe der Jensen-Shannon-Abweichung berechnet.
Wenn der Entfernungswert zwischen zwei statistischen Verteilungen den Grenzwert überschreitet, den Sie angeben, wird die Anomalie von Vertex AI Model Monitoring als Verzerrung oder Drift identifiziert.
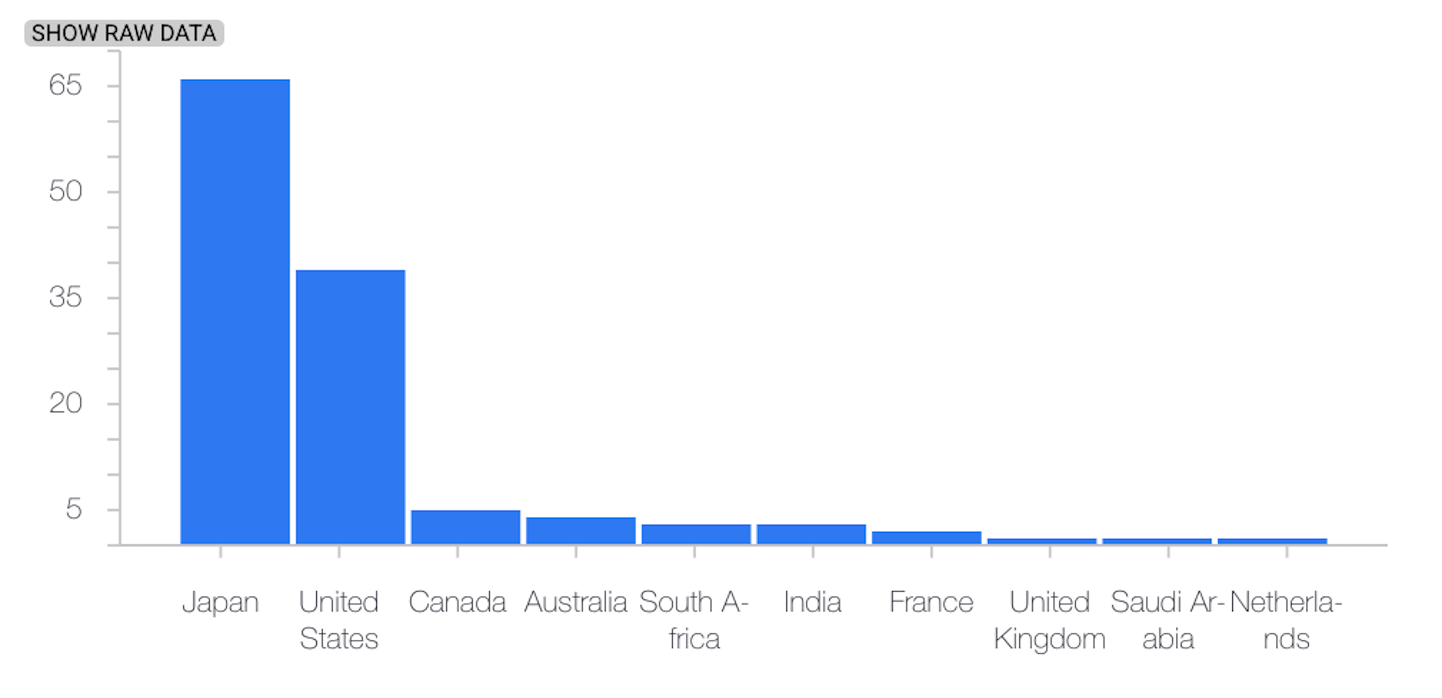
Das folgende Beispiel zeigt eine Verzerrung oder Abweichung zwischen der Referenzversion und den letzten Verteilungen eines kategorialen Merkmals:
Baseline-Verteilung
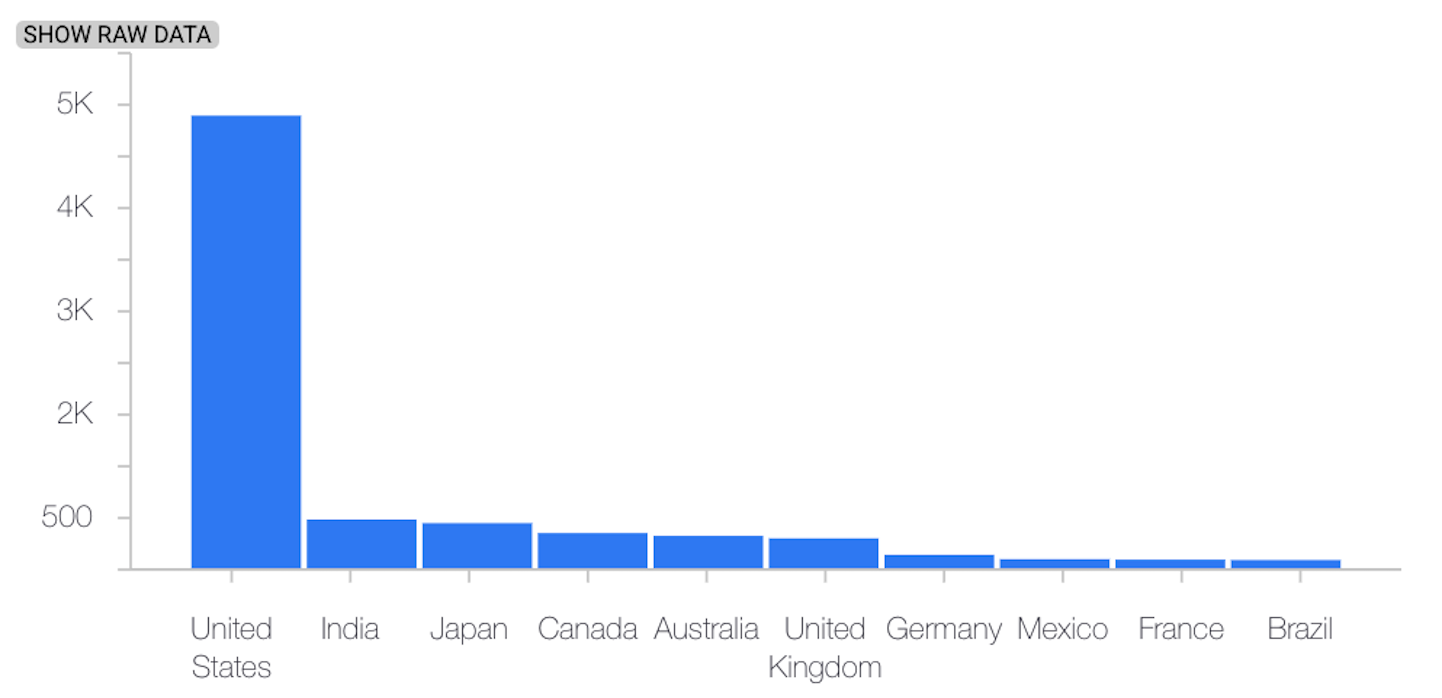
Letzte Verteilung
Das folgende Beispiel zeigt eine Verzerrung oder Abweichung zwischen der Referenzversion und den letzten Verteilungen eines numerischen Merkmals:
Baseline-Verteilung
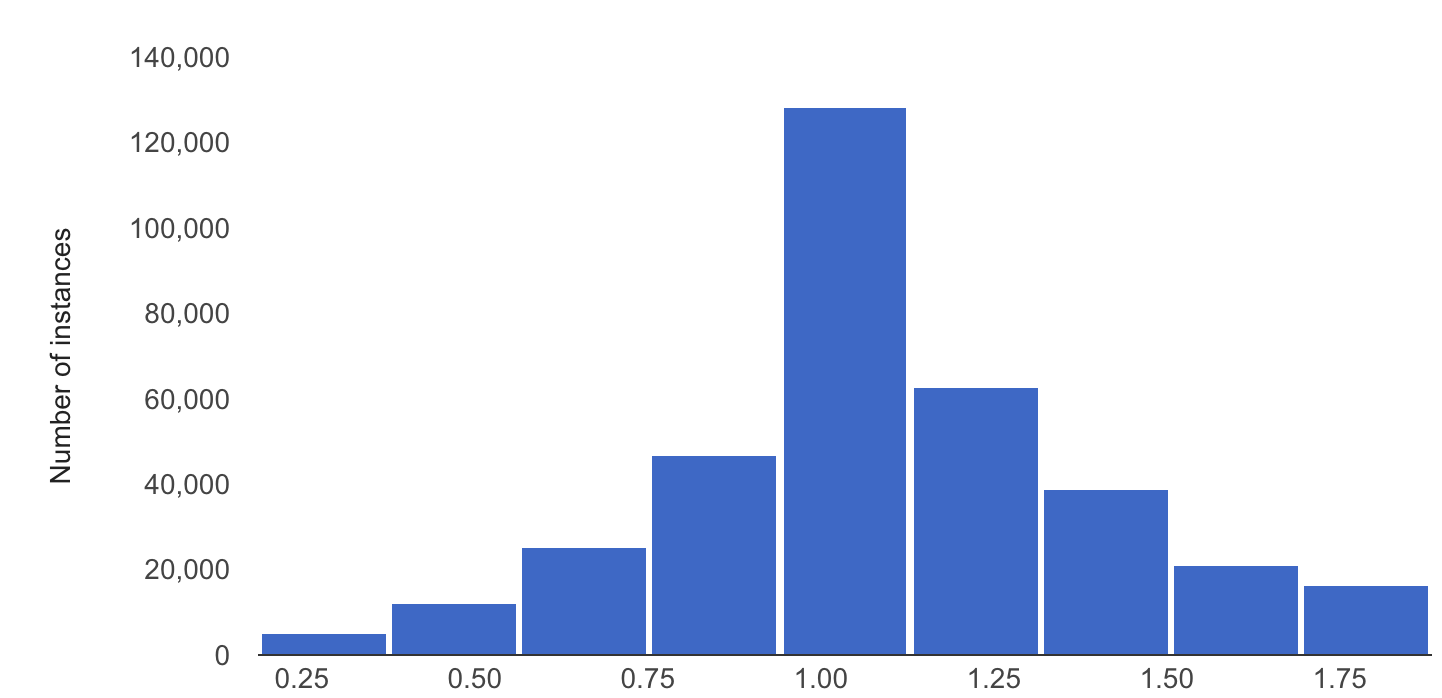
Letzte Verteilung
Überlegungen bei der Verwendung von Model Monitoring
Zur Kosteneffizienz können Sie eine Abtastrate für Vorhersageanfragen festlegen, um einen Teil der Produktionseingaben in einem Modell zu überwachen.
Sie können eine Häufigkeit festlegen, mit der die kürzlich protokollierten Eingaben eines bereitgestellten Modells auf Abweichungen oder Drift überwacht werden. Die Monitoringhäufigkeit legt die Zeitspanne (die Größe des Monitoringfensters) der protokollierten Daten fest, die bei jeder Monitoringausführung analysiert werden.
Sie können Grenzwerte für Benachrichtigungen für jedes Feature festlegen, das Sie überwachen möchten. Eine Benachrichtigung wird protokolliert, wenn die statistische Entfernung zwischen der Eingabefeatureverteilung und der entsprechenden Baseline den angegebenen Grenzwert überschreitet. Standardmäßig wird jedes kategoriale und numerische Feature mit Grenzwerten von 0,3 überwacht.
Ein Endpunkt für eine Onlinevorhersage kann mehrere Modelle hosten. Wenn Sie die Verzerrungs- oder Erkennungserkennung für einen Endpunkt aktivieren, werden die folgenden Konfigurationsparameter für alle Modelle freigegeben, die an diesem Endpunkt gehostet werden:
- Art der Erkennung
- Monitoring-Häufigkeit
- Anteil der überwachten Eingabeanfragen
Bei den anderen Konfigurationsparametern können Sie für jedes Modell unterschiedliche Werte festlegen.