다음 목표 섹션에는 데이터 요구사항, 입력/출력 스키마 파일, 스키마에서 정의한 데이터 가져오기 파일 형식(JSON Lines 및 CSV)에 대한 정보가 포함되어 있습니다.
객체 감지
데이터 요구사항
| 일반 이미지 요구사항 | |
|---|---|
| 지원되는 파일 형식 |
|
| 이미지 유형 | AutoML 모델은 현실의 물체를 찍은 사진에 최적화되어 있습니다. |
| 학습 이미지 파일 크기(MB) | 최대 크기는 30MB입니다. |
| 예측 이미지 파일* 크기(MB) | 최대 크기는 1.5MB입니다. |
| 이미지 크기(픽셀) | 권장 최대 크기는 1024x1024 픽셀입니다. 1024x1024 픽셀보다 훨씬 큰 이미지의 경우 Vertex AI의 이미지 정규화 과정 중에 일부 이미지 품질이 손실될 수 있습니다. |
| 라벨 및 경계 상자 요구사항 | |
|---|---|
| 다음 요구사항은 AutoML 모델을 학습시키는 데 사용되는 데이터 세트에 적용됩니다. | |
| 학습용 라벨 인스턴스 | 최소 10개 주석(인스턴스) |
| 주석 요구사항 | 각 레벨에 대해 최소 10개 이상의 이미지가 있어야 하고, 각 이미지에는 최소 1개 이상의 주석이 있어야 합니다(경계 상자 및 라벨). 하지만 모델 학습을 위해서는 라벨당 약 1,000개의 주석을 사용하는 것이 좋습니다. 일반적으로 라벨당 이미지 수가 많을수록 모델 성능이 향상됩니다. |
| 라벨 비율(가장 흔한 라벨부터 가장 흔하지 않은 라벨 순서): | 가장 흔한 라벨의 이미지가 가장 흔하지 않은 라벨의 이미지보다 최대 100배 많을 때 모델의 성능이 가장 좋습니다. 모델 성능을 위해서는 빈도가 매우 낮은 라벨을 삭제하는 것이 좋습니다. |
| 경계 상자 가장자리 길이 | 최소한 이미지 측면 길이에 0.01을 곱한 것 이상입니다. 예를 들어 1000 * 900 픽셀 이미지는 최소한 10 * 9 픽셀 이상의 경계 상자가 필요합니다. 경계 상자 최소 크기: 8픽셀 * 8픽셀 |
| 다음 요구사항은 AutoML 또는 커스텀 학습 모델을 학습시키는 데 사용되는 데이터 세트에 적용됩니다. | |
| 고유 이미지당 경계 상자 | 최대 500입니다. |
| 예측 요청에서 반환된 경계 상자 | 100(기본값), 최대 500입니다. |
| 학습 데이터 및 데이터 세트 요구사항 | |
|---|---|
| 다음 요구사항은 AutoML 모델을 학습시키는 데 사용되는 데이터 세트에 적용됩니다. | |
| 학습 이미지 특성 | 학습 데이터는 예측을 수행할 데이터와 최대한 유사해야 합니다. 예를 들어 사용 사례에 보안 카메라 영상처럼 흐릿한 저해상도 이미지가 포함된다면, 학습 데이터는 흐릿한 저해상도 이미지로 구성해야 합니다. 또한 일반적으로 다양한 각도, 해상도, 배경으로 촬영한 학습 이미지를 제공하면 도움이 됩니다. 인간이 지정할 수 없는 라벨은 Vertex AI 모델도 일반적으로 예측할 수 없습니다. 따라서 사람이 1~2초 동안 주시하여 라벨을 붙이도록 훈련시킬 수 없는 이미지라면 모델도 그러한 작업을 수행하도록 학습시키기 어렵습니다. |
| 내부 이미지 사전 처리 | 이미지를 가져오면 Vertex AI가 데이터에 대한 사전 처리를 수행합니다. 사전 처리된 이미지는 모델 학습을 위해 사용되는 실제 데이터입니다. 이미지의 가장 작은 가장자리가 1024픽셀보다 큰 경우에 이미지 사전 처리(크기 조정)이 수행됩니다. 이미지의 작은 면이 1024픽셀보다 크면 작은 면이 1024픽셀로 축소됩니다. 큰 면및 지정된 경계 상자가 모두 작은 면과 동일한 크기로 축소됩니다. 따라서 모든 축소된 주석(경계 상자 및 라벨)이 8픽셀 * 8픽셀보다 작으면 삭제됩니다. 작은 면이 1024픽셀보다 작거나 같은 이미지는 사전 처리 크기 조정이 수행되지 않습니다. |
| 다음 요구사항은 AutoML 또는 커스텀 학습 모델을 학습시키는 데 사용되는 데이터 세트에 적용됩니다. | |
| 각 데이터 세트의 이미지 | 최대 150,000 |
| 각 데이터 세트에서 주석이 추가된 경계 상자 합계 | 최대 1,000,000 |
| 각 데이터 세트의 라벨 수 | 최소 1, 최대 1,000 |
YAML 스키마 파일
공개적으로 액세스할 수 있는 다음 스키마 파일을 사용하여 이미지 객체 감지 주석(경계 상자 및 라벨)을 가져옵니다. 이 스키마 파일은 데이터 입력 파일의 형식을 지정합니다. 이 파일의 구조는 OpenAPI 스키마를 따릅니다.
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml
전체 스키마 파일
title: ImageBoundingBox description: > Import and export format for importing/exporting images together with bounding box annotations. Can be used in Dataset.import_schema_uri field. type: object required: - imageGcsUri properties: imageGcsUri: type: string description: > A Cloud Storage URI pointing to an image. Up to 30MB in size. Supported file mime types: `image/jpeg`, `image/gif`, `image/png`, `image/webp`, `image/bmp`, `image/tiff`, `image/vnd.microsoft.icon`. boundingBoxAnnotations: type: array description: Multiple bounding box Annotations on the image. items: type: object description: > Bounding box anntoation. `xMin`, `xMax`, `yMin`, and `yMax` are relative to the image size, and the point 0,0 is in the top left of the image. properties: displayName: type: string description: > It will be imported as/exported from AnnotationSpec's display name, i.e. the name of the label/class. xMin: description: The leftmost coordinate of the bounding box. type: number format: double xMax: description: The rightmost coordinate of the bounding box. type: number format: double yMin: description: The topmost coordinate of the bounding box. type: number format: double yMax: description: The bottommost coordinate of the bounding box. type: number format: double annotationResourceLabels: description: Resource labels on the Annotation. type: object additionalProperties: type: string dataItemResourceLabels: description: Resource labels on the DataItem. type: object additionalProperties: type: string
입력 파일
JSON Lines
각 행의 JSON:
{
"imageGcsUri": "gs://bucket/filename.ext",
"boundingBoxAnnotations": [
{
"displayName": "OBJECT1_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX",
"annotationResourceLabels": {
"aiplatform.googleapis.com/annotation_set_name": "displayName",
"env": "prod"
}
},
{
"displayName": "OBJECT2_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX"
}
],
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "test/train/validation"
}
}필드 참고사항:
imageGcsUri- 유일한 필수 필드입니다.annotationResourceLabels- 키-값 문자열 쌍을 포함할 수 있습니다. 시스템에 예약된 유일한 키-값 쌍은 다음과 같습니다.- 'aiplatform.googleapis.com/annotation_set_name': 'value'
여기서 value는 데이터 세트에 있는 기존 주석 집합의 표시 이름 중 하나입니다.
dataItemResourceLabels- 키-값 문자열 쌍을 포함할 수 있습니다. 시스템에서 예약할 수 있는 유일한 키-값 쌍은 다음과 같이 데이터 항목의 머신러닝 사용 세트를 지정합니다.- 'aiplatform.googleapis.com/ml_use': 'training/test/validation'
JSON Lines 예시 - object_detection.jsonl:
{"imageGcsUri": "gs://bucket/filename1.jpeg", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.3", "yMin": "0.3", "xMax": "0.7", "yMax": "0.6"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "test"}}
{"imageGcsUri": "gs://bucket/filename2.gif", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.8", "yMin": "0.2", "xMax": "1.0", "yMax": "0.4"},{"displayName": "Salad", "xMin": "0.0", "yMin": "0.0", "xMax": "1.0", "yMax": "1.0"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename3.png", "boundingBoxAnnotations": [{"displayName": "Baked goods", "xMin": "0.5", "yMin": "0.7", "xMax": "0.8", "yMax": "0.8"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename4.tiff", "boundingBoxAnnotations": [{"displayName": "Salad", "xMin": "0.1", "yMin": "0.2", "xMax": "0.8", "yMax": "0.9"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "validation"}}
...CSV
CSV 형식:
[ML_USE],GCS_FILE_PATH,[LABEL],[BOUNDING_BOX]*
ML_USE(선택 사항). 모델을 학습시킬 때 데이터 분할 목적으로 사용됩니다. TRAINING, TEST, VALIDATION이 사용됩니다. 수동 데이터 분할에 대한 자세한 내용은 AutoML 모델에 대한 데이터 분할 정보를 참조하세요.GCS_FILE_PATH. 이 필드에는 이미지의 Cloud Storage URI가 포함됩니다. Cloud Storage URI는 대소문자를 구분합니다.LABEL. 라벨은 문자로 시작해야 하며 문자, 숫자, 밑줄만 포함할 수 있습니다.BOUNDING_BOX. 이미지에 있는 객체의 경계 상자입니다. 경계 상자 지정에는 2개 이상의 열이 사용됩니다.
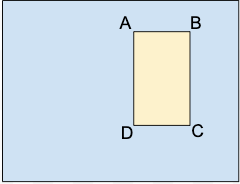
A.X_MIN,Y_MIN
B.X_MAX,Y_MIN
C.X_MAX,Y_MAX
D.X_MIN,Y_MAX
각 꼭짓점은 x, y 좌표 값으로 지정됩니다. 좌표는 정규화된 float 값 [0,1]입니다. 0.0은 X_MIN 또는 Y_MIN이고 1.0은 X_MAX 또는 Y_MAX입니다.
예를 들어 전체 이미지의 경계 상자는 (0.0,0.0,,,1.0,1.0,,) 또는 (0.0,0.0,1.0,0.0,1.0,1.0,0.0,1.0)으로 표현됩니다.
객체의 경계 상자는 두 가지 방법 중 하나로 지정될 수 있습니다.
- 직사각형의 대각선 반대 지점에 위치한 2개의 꼭짓점(2개의 x,y 좌표 집합):
A.X_MIN,Y_MIN
C.X_MAX,Y_MAX
다음 예시 참조:
A,,C,
X_MIN,Y_MIN,,,X_MAX,Y_MAX,, - 다음과 같이 4개의 꼭짓점이 모두 지정됨:
X_MIN,Y_MIN,X_MAX,Y_MIN, X_MAX,Y_MAX,X_MIN,Y_MAX,
4개의 지정 꼭짓점이 이미지의 변과 평행을 이루는 직사각형을 형성하지 않는 경우 Vertex AI는 이러한 직사각형을 형성하는 꼭짓점을 지정합니다.
- 직사각형의 대각선 반대 지점에 위치한 2개의 꼭짓점(2개의 x,y 좌표 집합):
CSV 예시 - object_detection.csv:
test,gs://bucket/filename1.jpeg,Tomato,0.3,0.3,,,0.7,0.6,,
training,gs://bucket/filename2.gif,Tomato,0.8,0.2,,,1.0,0.4,,
gs://bucket/filename2.gif
gs://bucket/filename3.png,Baked goods,0.5,0.7,0.8,0.7,0.8,0.8,0.5,0.8
validation,gs://bucket/filename4.tiff,Salad,0.1,0.2,,,0.8,0.9,,
...