La seguente sezione Obiettivo include informazioni sui requisiti dei dati, sul file di schema di input/output e sul formato dei file di importazione dei dati (JSON Lines & CSV) definiti dallo schema.
Autorizzazioni
Per utilizzare le immagini di un bucket Cloud Storage, devi concedere all'agente di servizio Vertex AI il ruolo Storage Object Viewer per il bucket. L'agente di servizio è un account di servizio gestito da Google che Vertex AI utilizza per accedere ai tuoi dati per tuo conto. Per una spiegazione più dettagliata, vedi Agenti di servizio.
Rilevamento di oggetti
Requisiti dei dati
| Requisiti generali per le immagini | |
|---|---|
| Tipi di file supportati |
|
| Tipi di immagini | I modelli AutoML sono ottimizzati per fotografie di oggetti nel mondo reale. |
| Dimensioni del file immagine di addestramento (MB) | Dimensione massima: 30 MB. |
| Dimensioni del file immagine di previsione* (MB) | Dimensione massima: 1,5 MB. |
| Dimensioni dell'immagine (pixel) | Massimo 1024 x 1024 pixel consigliato. Per le immagini molto più grandi di 1024 pixel per 1024 pixel, la qualità dell'immagine potrebbe peggiorare durante il processo di normalizzazione delle immagini di Vertex AI. |
| Requisiti per le etichette e riquadro di delimitazione di selezione | |
|---|---|
| I seguenti requisiti si applicano ai set di dati utilizzati per addestrare i modelli AutoML. | |
| Etichettare le istanze per l'addestramento | Almeno 10 annotazioni (istanze). |
| Requisiti per le annotazioni | Per ogni etichetta devi avere almeno 10 immagini, ognuna con almeno un'annotazione (riquadro di delimitazione ed etichetta). Tuttavia, ai fini dell'addestramento del modello, è consigliabile utilizzare circa 1000 annotazioni per etichetta. In generale, più immagini per etichetta hai, migliore sarà il rendimento del modello. |
| Rapporto tra le etichette (etichetta più comune ed etichetta meno comune): | Il modello funziona meglio quando ci sono al massimo 100 volte più immagini per l'etichetta più comune che per l'etichetta meno comune. Per migliorare le prestazioni del modello, si consiglia di rimuovere le etichette con frequenza molto bassa. |
| Lunghezza del bordo del riquadro di delimitazione | Almeno 0,01 * lunghezza di un lato di un'immagine. Ad esempio, un'immagine di 1000 x 900 pixel richiederebbe bounding box di almeno 10 x 9 pixel. Dimensioni minime del riquadro di delimitazione: 8 x 8 pixel. |
| I seguenti requisiti si applicano ai set di dati utilizzati per addestrare modelli AutoML o con addestramento personalizzato. | |
| Riquadri di delimitazione per immagine distinta | Massimo 500. |
| Riquadri di delimitazione restituiti da una richiesta di previsione | 100 (valore predefinito), 500 massimo. |
| Requisiti dei dati di addestramento e del set di dati | |
|---|---|
| I seguenti requisiti si applicano ai set di dati utilizzati per addestrare i modelli AutoML. | |
| Caratteristiche delle immagini di addestramento | I dati di addestramento devono essere il più possibile simili ai dati su cui devono essere effettuate le previsioni. Ad esempio, se il tuo caso d'uso riguarda immagini sfocate e a bassa risoluzione (ad esempio quelle di una videocamera di sicurezza), i dati di addestramento devono essere composti da immagini sfocate e a bassa risoluzione. In generale, dovresti anche prendere in considerazione la possibilità di fornire più angolazioni, risoluzioni e sfondi per le immagini di addestramento. I modelli Vertex AI in genere non possono prevedere etichette che gli esseri umani non possono assegnare. Pertanto, se una persona non può essere addestrata ad assegnare etichette guardando l'immagine per 1-2 secondi, è probabile che non sia possibile addestrare il modello a farlo. |
| Pre-elaborazione interna delle immagini | Dopo l'importazione delle immagini, Vertex AI esegue la pre-elaborazione dei dati. Le immagini preelaborate sono i dati effettivi utilizzati per addestrare il modello. Il pre-elaborazione (ridimensionamento) dell'immagine si verifica quando il lato più piccolo dell'immagine è maggiore di 1024 pixel. Nel caso in cui il lato più corto dell'immagine sia maggiore di 1024 pixel, questo lato viene ridimensionato a 1024 pixel. Il lato più grande e le caselle di selezione specificate vengono ridimensionati della stessa quantità del lato più piccolo. Di conseguenza, le annotazioni ridimensionate (riquadri di delimitazione ed etichette) vengono rimosse se sono inferiori a 8 pixel x 8 pixel. Le immagini con un lato più piccolo inferiore o uguale a 1024 pixel non sono soggette a ridimensionamento di pre-elaborazione. |
| I seguenti requisiti si applicano ai set di dati utilizzati per addestrare modelli AutoML o con addestramento personalizzato. | |
| Immagini in ogni set di dati | Massimo 150.000 |
| Totale dei riquadri di delimitazione annotati in ogni set di dati | Massimo 1.000.000 |
| Numero di etichette in ogni set di dati | Minimo 1, massimo 1000 |
File di schema YAML
Utilizza il seguente file di schema accessibile pubblicamente per importare le annotazioni di rilevamento degli oggetti immagine (riquadri di delimitazione ed etichette). Questo file di schema determina il formato dei file di input dei dati. La struttura di questo file segue lo schema OpenAPI.
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml
File schema completo
title: ImageBoundingBox description: > Import and export format for importing/exporting images together with bounding box annotations. Can be used in Dataset.import_schema_uri field. type: object required: - imageGcsUri properties: imageGcsUri: type: string description: > A Cloud Storage URI pointing to an image. Up to 30MB in size. Supported file mime types: `image/jpeg`, `image/gif`, `image/png`, `image/webp`, `image/bmp`, `image/tiff`, `image/vnd.microsoft.icon`. boundingBoxAnnotations: type: array description: Multiple bounding box Annotations on the image. items: type: object description: > Bounding box anntoation. `xMin`, `xMax`, `yMin`, and `yMax` are relative to the image size, and the point 0,0 is in the top left of the image. properties: displayName: type: string description: > It will be imported as/exported from AnnotationSpec's display name, i.e. the name of the label/class. xMin: description: The leftmost coordinate of the bounding box. type: number format: double xMax: description: The rightmost coordinate of the bounding box. type: number format: double yMin: description: The topmost coordinate of the bounding box. type: number format: double yMax: description: The bottommost coordinate of the bounding box. type: number format: double annotationResourceLabels: description: Resource labels on the Annotation. type: object additionalProperties: type: string dataItemResourceLabels: description: Resource labels on the DataItem. type: object additionalProperties: type: string
File di input
JSON Lines
JSON su ogni riga:
{
"imageGcsUri": "gs://bucket/filename.ext",
"boundingBoxAnnotations": [
{
"displayName": "OBJECT1_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX",
"annotationResourceLabels": {
"aiplatform.googleapis.com/annotation_set_name": "displayName",
"env": "prod"
}
},
{
"displayName": "OBJECT2_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX"
}
],
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "test/train/validation"
}
}Note sul campo:
imageGcsUri: l'unico campo obbligatorio.annotationResourceLabels- Può contenere un numero qualsiasi di coppie di stringhe chiave-valore. L'unica coppia chiave-valore riservata al sistema è la seguente:- "aiplatform.googleapis.com/annotation_set_name" : "value"
Dove value è uno dei nomi visualizzati dei set di annotazioni esistenti nel set di dati.
dataItemResourceLabels- Può contenere un numero qualsiasi di coppie di stringhe chiave-valore. L'unica coppia chiave-valore riservata al sistema è la seguente, che specifica l'insieme di utilizzo del machine learning dell'elemento di dati:- "aiplatform.googleapis.com/ml_use" : "training/test/validation"
Esempio di JSON Lines - object_detection.jsonl:
{"imageGcsUri": "gs://bucket/filename1.jpeg", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.3", "yMin": "0.3", "xMax": "0.7", "yMax": "0.6"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "test"}}
{"imageGcsUri": "gs://bucket/filename2.gif", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.8", "yMin": "0.2", "xMax": "1.0", "yMax": "0.4"},{"displayName": "Salad", "xMin": "0.0", "yMin": "0.0", "xMax": "1.0", "yMax": "1.0"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename3.png", "boundingBoxAnnotations": [{"displayName": "Baked goods", "xMin": "0.5", "yMin": "0.7", "xMax": "0.8", "yMax": "0.8"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename4.tiff", "boundingBoxAnnotations": [{"displayName": "Salad", "xMin": "0.1", "yMin": "0.2", "xMax": "0.8", "yMax": "0.9"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "validation"}}
...CSV
Formato CSV:
[ML_USE],GCS_FILE_PATH,[LABEL],[BOUNDING_BOX]*
ML_USE(facoltativo). Per la suddivisione dei dati durante l'addestramento di un modello. Utilizza TRAINING, TEST o VALIDATION. Per ulteriori informazioni sulla suddivisione manuale dei dati, consulta Informazioni sulle suddivisioni di dati per i modelli AutoML.GCS_FILE_PATH. Questo campo contiene l'URI Cloud Storage dell'immagine. Gli URI Cloud Storage distinguono tra maiuscole e minuscole.LABEL. Le etichette devono iniziare con una lettera e contenere solo lettere, numeri e trattini bassi.BOUNDING_BOX. Un riquadro di delimitazione per un oggetto nell'immagine. La specifica di un riquadro di delimitazione coinvolge più di una colonna.
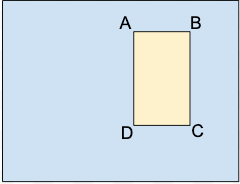
A.X_MIN,Y_MIN
B.X_MAX,Y_MIN
C.X_MAX,Y_MAX
D.X_MIN,Y_MAX
Ogni vertice è specificato dai valori delle coordinate x e y. Le coordinate sono valori float normalizzati [0,1]; 0.0 è X_MIN o Y_MIN, 1.0 è X_MAX o Y_MAX.
Ad esempio, un riquadro di delimitazione per l'intera immagine è espresso come (0.0,0.0,,,1.0,1.0,,) o (0.0,0.0,1.0,0.0,1.0,1.0,0.0,1.0).
Il riquadro di delimitazione per un oggetto può essere specificato in uno dei due modi seguenti:
- Due vertici (due coppie di coordinate x,y) che sono punti diagonalmente opposti del
rettangolo:
A.X_MIN,Y_MIN
C.X_MAX,Y_MAX
come mostrato in questo esempio:
A,,C,
X_MIN,Y_MIN,,,X_MAX,Y_MAX,, - Tutti e quattro i vertici specificati come mostrato in:
X_MIN,Y_MIN,X_MAX,Y_MIN, X_MAX,Y_MAX,X_MIN,Y_MAX,
Se i quattro vertici specificati non formano un rettangolo parallelo ai bordi dell'immagine, Vertex AI specifica i vertici che formano un rettangolo di questo tipo.
- Due vertici (due coppie di coordinate x,y) che sono punti diagonalmente opposti del
rettangolo:
CSV di esempio - object_detection.csv:
test,gs://bucket/filename1.jpeg,Tomato,0.3,0.3,,,0.7,0.6,,
training,gs://bucket/filename2.gif,Tomato,0.8,0.2,,,1.0,0.4,,
gs://bucket/filename2.gif
gs://bucket/filename3.png,Baked goods,0.5,0.7,0.8,0.7,0.8,0.8,0.5,0.8
validation,gs://bucket/filename4.tiff,Salad,0.1,0.2,,,0.8,0.9,,
...