Vertex AI Pipelines adalah layanan terkelola yang membantu Anda membangun, men-deploy, dan mengelola alur kerja machine learning (ML) end-to-end di platform Google Cloud. Cloud Dataflow menyediakan lingkungan serverless untuk menjalankan pipeline Anda sehingga Anda tidak perlu mengelola infrastruktur.
Dalam tutorial ini, Anda akan menggunakan Vertex AI Pipelines untuk menjalankan tugas pelatihan kustom dan men-deploy model terlatih di Vertex AI, dalam lingkungan jaringan hybrid.
Seluruh proses ini membutuhkan waktu dua hingga tiga jam, termasuk sekitar 50 menit untuk menjalankan pipeline.
Tutorial ini ditujukan bagi administrator jaringan perusahaan, ilmuwan data, dan peneliti yang sudah memahami Vertex AI, Virtual Private Cloud (VPC), konsol Google Cloud , dan Cloud Shell. Pemahaman tentang Vertex AI Workbench akan membantu, tetapi tidak wajib.
Tujuan
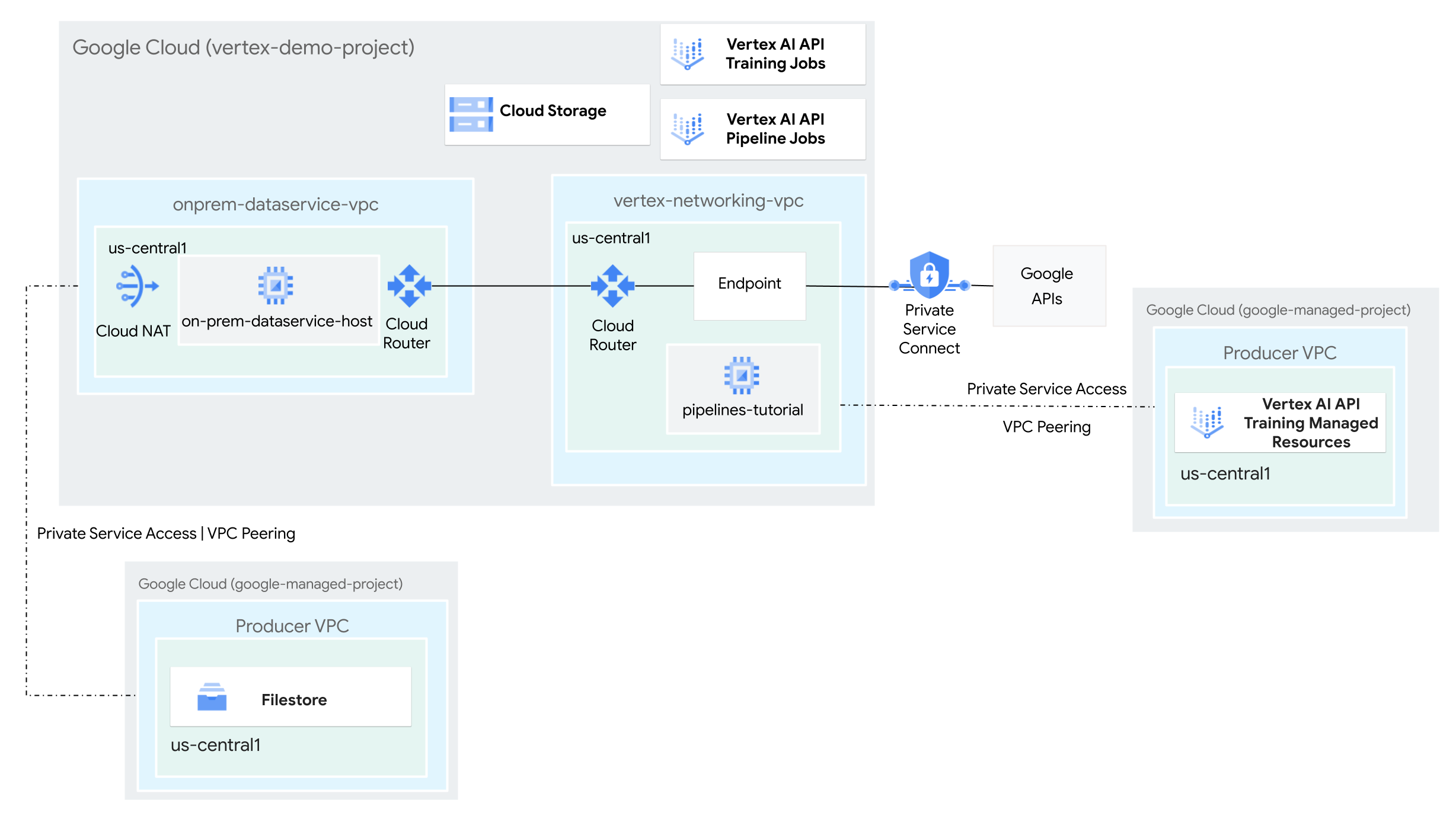
- Buat dua jaringan Virtual Private Cloud (VPC):
- Satu (
vertex-networking-vpc) untuk menggunakan Vertex AI Pipelines API guna membuat dan menghosting template pipeline untuk melatih model machine learning dan men-deploy-nya ke endpoint. - Lainnya (
onprem-dataservice-vpc) mewakili jaringan lokal.
- Satu (
- Hubungkan kedua jaringan VPC sebagai berikut:
- Deploy gateway VPN dengan ketersediaan tinggi (HA), tunnel Cloud VPN, dan
Cloud Router untuk menghubungkan
vertex-networking-vpcdanonprem-dataservice-vpc. - Buat endpoint Private Service Connect (PSC) untuk meneruskan permintaan pribadi ke Vertex AI Pipelines REST API.
- Konfigurasi pemberitahuan rute kustom Cloud Router di
vertex-networking-vpcuntuk mengumumkan rute untuk endpoint Private Service Connect keonprem-dataservice-vpc.
- Deploy gateway VPN dengan ketersediaan tinggi (HA), tunnel Cloud VPN, dan
Cloud Router untuk menghubungkan
- Buat instance Filestore di jaringan
onprem-dataservice-vpcVPC dan tambahkan data pelatihan ke instance tersebut di berbagi NFS. - Buat aplikasi paket Python untuk tugas pelatihan.
- Buat template tugas Vertex AI Pipelines untuk melakukan hal berikut:
- Buat dan jalankan tugas pelatihan pada data dari berbagi NFS.
- Impor model terlatih dan upload ke Vertex AI Model Registry.
- Buat endpoint Vertex AI untuk prediksi online.
- Deploy model ke endpoint.
- Upload template pipeline ke repositori Artifact Registry.
- Gunakan Vertex AI Pipelines REST API untuk memicu eksekusi pipeline dari
host layanan data lokal (
on-prem-dataservice-host).
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Setelah menyelesaikan tugas yang dijelaskan dalam dokumen ini, Anda dapat menghindari penagihan berkelanjutan dengan menghapus resource yang Anda buat. Untuk mengetahui informasi selengkapnya, lihat Pembersihan.
Sebelum memulai
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- Buka Cloud Shell untuk menjalankan perintah yang tercantum dalam tutorial ini. Cloud Shell adalah lingkungan shell interaktif untuk Google Cloud yang dapat Anda gunakan untuk mengelola project dan resource dari browser web.
- Di Cloud Shell, tetapkan project saat ini ke project ID Google Cloud Anda dan simpan project ID yang sama ke dalam variabel shell
projectid:projectid="PROJECT_ID" gcloud config set project ${projectid} - Jika Anda bukan pemilik project, minta pemilik project untuk memberi Anda peran
Admin IAM Project (
roles/resourcemanager.projectIamAdmin). Anda harus memiliki peran ini untuk memberikan peran IAM pada langkah berikutnya. -
Make sure that you have the following role or roles on the project: roles/artifactregistry.admin, roles/artifactregistry.repoAdmin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/file.editor, roles/logging.viewer, roles/logging.admin, roles/notebooks.admin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/servicemanagement.quotaAdmin, roles/serviceusage.serviceUsageAdmin, roles/storage.admin, roles/storage.objectAdmin, roles/aiplatform.admin, roles/aiplatform.user, roles/aiplatform.viewer, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/resourcemanager.projectIamAdmin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Buka IAM - Pilih project.
- Klik Grant access.
-
Di kolom New principals, masukkan ID pengguna Anda. Biasanya berupa alamat email untuk Akun Google.
- Di daftar Select a role, pilih peran.
- Untuk memberikan peran tambahan, klik Tambahkan peran lain, lalu tambahkan setiap peran tambahan.
- Klik Simpan.
Enable the DNS, Artifact Registry, IAM, Compute Engine, Cloud Logging, Network Connectivity, Notebooks, Cloud Filestore, Service Networking, Service Usage, and Vertex AI APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Membuat jaringan VPC
Di bagian ini, Anda akan membuat dua jaringan VPC: satu untuk mengakses Google API untuk Vertex AI Pipelines, dan yang lainnya untuk menyimulasikan jaringan lokal. Di setiap dari dua jaringan VPC, Anda akan membuat gateway Cloud Router dan Cloud NAT. Gateway Cloud NAT menyediakan konektivitas keluar untuk instance virtual machine (VM) Compute Engine tanpa alamat IP eksternal.
Di Cloud Shell, jalankan perintah berikut, ganti PROJECT_ID dengan project ID Anda:
projectid=PROJECT_ID gcloud config set project ${projectid}Buat jaringan VPC
vertex-networking-vpc:gcloud compute networks create vertex-networking-vpc \ --subnet-mode customDi jaringan
vertex-networking-vpc, buat subnet bernamapipeline-networking-subnet1, dengan rentang IPv4 utama10.0.0.0/24:gcloud compute networks subnets create pipeline-networking-subnet1 \ --range=10.0.0.0/24 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessBuat jaringan VPC untuk menyimulasikan jaringan lokal (
onprem-dataservice-vpc):gcloud compute networks create onprem-dataservice-vpc \ --subnet-mode customDi jaringan
onprem-dataservice-vpc, buat subnet bernamaonprem-dataservice-vpc-subnet1, dengan rentang IPv4 utama172.16.10.0/24:gcloud compute networks subnets create onprem-dataservice-vpc-subnet1 \ --network onprem-dataservice-vpc \ --range 172.16.10.0/24 \ --region us-central1 \ --enable-private-ip-google-access
Pastikan jaringan VPC dikonfigurasi dengan benar
Di konsol Google Cloud , buka tab Networks in current project di halaman VPC networks.
Dalam daftar jaringan VPC, pastikan kedua jaringan telah dibuat:
vertex-networking-vpcdanonprem-dataservice-vpc.Klik tab Subnets in current project.
Dalam daftar subnet VPC, pastikan subnet
pipeline-networking-subnet1danonprem-dataservice-vpc-subnet1telah dibuat.
Mengonfigurasi konektivitas hybrid
Di bagian ini, Anda akan membuat dua gateway VPN dengan ketersediaan tinggi (HA) yang terhubung satu sama lain. Salah satunya berada di jaringan VPC
vertex-networking-vpc. Yang lainnya berada di jaringan VPC onprem-dataservice-vpc. Setiap gateway berisi
Cloud Router dan sepasang tunnel VPN.
Membuat gateway VPN dengan ketersediaan tinggi (HA)
Di Cloud Shell, buat gateway VPN dengan ketersediaan tinggi (HA) untuk jaringan VPC
vertex-networking-vpc:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1Buat gateway VPN dengan ketersediaan tinggi (HA) untuk jaringan VPC
onprem-dataservice-vpcVPC:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-dataservice-vpc \ --region us-central1Di konsol Google Cloud , buka tab Cloud VPN Gateways di halaman VPN.
Pastikan kedua gateway (
vertex-networking-vpn-gw1danonprem-vpn-gw1) telah dibuat dan setiap gateway memiliki dua alamat IP antarmuka.
Buat Cloud Router dan gateway Cloud NAT
Di setiap dari dua jaringan VPC, Anda membuat dua Cloud Router: satu untuk digunakan dengan Cloud NAT dan satu untuk mengelola sesi BGP untuk VPN dengan ketersediaan tinggi (HA).
Di Cloud Shell, buat Cloud Router untuk jaringan VPC
vertex-networking-vpcyang akan digunakan untuk VPN:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1 \ --network vertex-networking-vpc \ --asn 65001Buat Cloud Router untuk jaringan VPC
onprem-dataservice-vpcyang akan digunakan untuk VPN:gcloud compute routers create onprem-dataservice-vpc-router1 \ --region us-central1 \ --network onprem-dataservice-vpc \ --asn 65002Buat Cloud Router untuk jaringan VPC
vertex-networking-vpcyang akan digunakan untuk Cloud NAT:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Konfigurasi gateway Cloud NAT di Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Buat Cloud Router untuk jaringan VPC
onprem-dataservice-vpcyang akan digunakan untuk Cloud NAT:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-dataservice-vpc \ --region us-central1Konfigurasi gateway Cloud NAT di Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Di konsol Google Cloud , buka halaman Cloud Router.
Di daftar Cloud Router, verifikasi bahwa router berikut telah dibuat:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-dataservice-vpc-router1vertex-networking-vpc-router1
Anda mungkin perlu memuat ulang tab browser konsol untuk melihat nilai baru. Google Cloud
Di daftar Cloud Router, klik
cloud-router-us-central1-vertex-nat.Di halaman Router details, pastikan
cloud-nat-us-central1gateway Cloud NAT telah dibuat.Klik panah kembali untuk kembali ke halaman Cloud Router.
Di daftar Cloud Router, klik
cloud-router-us-central1-onprem-nat.Di halaman Router details, pastikan gateway Cloud NAT telah dibuat.
cloud-nat-us-central1-on-prem
Buat tunnel VPN
Di Cloud Shell, di jaringan
vertex-networking-vpc, buat tunnel VPN bernamavertex-networking-vpc-tunnel0:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0Di jaringan
vertex-networking-vpc, buat tunnel VPN yang disebutvertex-networking-vpc-tunnel1:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1Di jaringan
onprem-dataservice-vpc, buat tunnel VPN yang disebutonprem-dataservice-vpc-tunnel0:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0Di jaringan
onprem-dataservice-vpc, buat tunnel VPN yang disebutonprem-dataservice-vpc-tunnel1:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1Di konsol Google Cloud , buka halaman VPN.
Dalam daftar tunnel VPN, verifikasi bahwa empat tunnel VPN telah dibuat.
Membuat sesi BGP
Cloud Router menggunakan Border Gateway Protocol (BGP) untuk bertukar rute antara
jaringan VPC Anda (dalam hal ini, vertex-networking-vpc)
dan jaringan lokal Anda (diwakili oleh onprem-dataservice-vpc). Di Cloud Router,
Anda mengonfigurasi antarmuka dan peer BGP untuk router lokal Anda.
Konfigurasi antarmuka dan peer BGP bersama-sama membentuk sesi BGP.
Di bagian ini, Anda akan membuat dua sesi BGP untuk vertex-networking-vpc dan
dua sesi untuk onprem-dataservice-vpc.
Setelah Anda mengonfigurasi antarmuka dan peer BGP di antara router, router tersebut akan otomatis mulai menukar rute.
Membuat sesi BGP untuk vertex-networking-vpc
Di Cloud Shell, di jaringan
vertex-networking-vpc, buat antarmuka BGP untukvertex-networking-vpc-tunnel0:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1Di jaringan
vertex-networking-vpc, buat peer BGP untukbgp-onprem-tunnel0:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1Di jaringan
vertex-networking-vpc, buat antarmuka BGP untukvertex-networking-vpc-tunnel1:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1Di jaringan
vertex-networking-vpc, buat peer BGP untukbgp-onprem-tunnel1:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
Membuat sesi BGP untuk onprem-dataservice-vpc
Di jaringan
onprem-dataservice-vpc, buat antarmuka BGP untukonprem-dataservice-vpc-tunnel0:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel0 \ --region us-central1Di jaringan
onprem-dataservice-vpc, buat peer BGP untukbgp-vertex-networking-vpc-tunnel0:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1Di jaringan
onprem-dataservice-vpc, buat antarmuka BGP untukonprem-dataservice-vpc-tunnel1:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel1 \ --region us-central1Di jaringan
onprem-dataservice-vpc, buat peer BGP untukbgp-vertex-networking-vpc-tunnel1:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
Memvalidasi pembuatan sesi BGP
Di konsol Google Cloud , buka halaman VPN.
Dalam daftar tunnel VPN, pastikan nilai di kolom Status sesi BGP untuk setiap tunnel telah berubah dari Konfigurasi sesi BGP menjadi BGP dibuat. Anda mungkin perlu memuat ulang tab browser konsol untuk melihat nilai baru. Google Cloud
Memvalidasi rute yang dipelajari onprem-dataservice-vpc
Di Google Cloud konsol, buka halaman VPC networks.
Dalam daftar jaringan VPC, klik
onprem-dataservice-vpc.Klik tab Routes.
Pilih us-central1 (Iowa) dalam daftar Region, lalu klik Lihat.
Di kolom Destination IP range, pastikan rentang IP subnet
pipeline-networking-subnet1(10.0.0.0/24) muncul dua kali.Anda mungkin perlu memuat ulang tab browser konsol untuk melihat kedua entri. Google Cloud
Memvalidasi rute yang dipelajari vertex-networking-vpc
Klik panah kembali untuk kembali ke halaman VPC networks.
Dalam daftar jaringan VPC, klik
vertex-networking-vpc.Klik tab Routes.
Pilih us-central1 (Iowa) dalam daftar Region, lalu klik Lihat.
Di kolom Rentang IP tujuan, pastikan rentang IP subnet
onprem-dataservice-vpc-subnet1(172.16.10.0/24) muncul dua kali.
Membuat endpoint Private Service Connect untuk Google API
Di bagian ini, Anda akan membuat endpoint Private Service Connect untuk Google API yang akan Anda gunakan untuk mengakses Vertex AI Pipelines REST API dari jaringan lokal Anda.
Di Cloud Shell, cadangkan alamat IP endpoint konsumen yang akan digunakan untuk mengakses Google API:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcBuat aturan penerusan untuk menghubungkan endpoint ke Google API dan layanan Google.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc \ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
Buat pemberitahuan rute kustom untuk vertex-networking-vpc
Di bagian ini, Anda akan membuat
pemberitahuan rute kustom
untuk vertex-networking-vpc-router1 (Cloud Router untuk
vertex-networking-vpc) guna mengiklankan alamat IP endpoint PSC
ke jaringan VPC onprem-dataservice-vpc.
Di konsol Google Cloud , buka halaman Cloud Router.
Di daftar Cloud Router, klik
vertex-networking-vpc-router1.Di halaman detail Router, klik Edit.
Di bagian Advertised routes untuk Routes, pilih Create custom routes.
Centang kotak Beriklan semua subnet yang terlihat oleh Cloud Router untuk terus mengiklankan subnet yang tersedia untuk Cloud Router. Mengaktifkan opsi ini meniru perilaku Cloud Router dalam mode iklan default.
Klik Tambahkan rute kustom.
Untuk Sumber, pilih Rentang IP kustom.
Untuk Rentang alamat IP, masukkan alamat IP berikut:
192.168.0.1Untuk Deskripsi, masukkan teks berikut:
Custom route to advertise Private Service Connect endpoint IP addressKlik Selesai, lalu klik Simpan.
Validasi bahwa onprem-dataservice-vpc telah mempelajari rute yang diiklankan
Di konsol Google Cloud , buka halaman Routes.
Pada tab Effective routes, lakukan hal berikut:
- Untuk Network, pilih
onprem-dataservice-vpc. - Untuk Region, pilih
us-central1 (Iowa). - Klik View.
Dalam daftar rute, pastikan ada dua entri yang namanya diawali dengan
onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel0dan dua entri yang diawali denganonprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel1.Jika entri ini tidak langsung muncul, tunggu beberapa menit, lalu muat ulang tab browser konsol Google Cloud .
Pastikan dua entri memiliki Destination IP range
192.168.0.1/32dan dua entri memiliki Destination IP range10.0.0.0/24.
- Untuk Network, pilih
Buat instance VM di onprem-dataservice-vpc
Di bagian ini, Anda akan membuat instance VM yang menyimulasikan host layanan data lokal. Dengan mengikuti praktik terbaik Compute Engine dan IAM, VM ini menggunakan akun layanan yang dikelola pengguna, bukan akun layanan default Compute Engine.
Buat akun layanan yang dikelola pengguna untuk instance VM
Di Cloud Shell, jalankan perintah berikut, ganti PROJECT_ID dengan project ID Anda:
projectid=PROJECT_ID gcloud config set project ${projectid}Buat akun layanan bernama
onprem-user-managed-sa:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa"Tetapkan peran Vertex AI User (
roles/aiplatform.user) ke akun layanan:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid." \ --role="roles/aiplatform.user"Tetapkan peran Vertex AI Viewer (
roles/aiplatform.viewer):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid." \ --role="roles/aiplatform.viewer"Tetapkan peran Filestore Editor (
roles/file.editor):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid." \ --role="roles/file.editor"Tetapkan peran Service Account Admin (
roles/iam.serviceAccountAdmin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid." \ --role="roles/iam.serviceAccountAdmin"Tetapkan peran Service Account User (
roles/iam.serviceAccountUser):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid." \ --role="roles/iam.serviceAccountUser"Tetapkan peran Pembaca Artifact Registry (
roles/artifactregistry.reader):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid." \ --role="roles/artifactregistry.reader"Tetapkan peran Storage Object Admin (
roles/storage.objectAdmin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid." \ --role="roles/storage.objectAdmin"Tetapkan peran Logging Admin (
roles/logging.admin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid." \ --role="roles/logging.admin"
Buat instance VM on-prem-dataservice-host
Instance VM yang Anda buat tidak memiliki alamat IP eksternal dan tidak mengizinkan akses langsung melalui internet. Untuk mengaktifkan akses administratif ke VM, Anda menggunakan penerusan TCP Identity-Aware Proxy (IAP).
Di Cloud Shell, buat instance VM
on-prem-dataservice-host:gcloud compute instances create on-prem-dataservice-host \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-dataservice-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid. \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Buat aturan firewall untuk mengizinkan IAP terhubung ke instance VM Anda:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-dataservice-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Perbarui file /etc/hosts agar mengarah ke endpoint PSC
Di bagian ini, Anda akan menambahkan baris ke file /etc/hosts yang menyebabkan permintaan
yang dikirim ke endpoint layanan publik (us-central1-aiplatform.googleapis.com)
dialihkan ke endpoint PSC (192.168.0.1).
Di Cloud Shell, login ke instance VM
on-prem-dataservice-hostmenggunakan IAP:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapDi instance VM
on-prem-dataservice-host, gunakan editor teks sepertivimataunanountuk membuka file/etc/hosts, misalnya:sudo vim /etc/hostsTambahkan baris berikut ke file:
192.168.0.1 us-central1-aiplatform.googleapis.comBaris ini menetapkan alamat IP endpoint PSC (
192.168.0.1) ke nama domain yang sepenuhnya memenuhi syarat untuk Vertex AI Google API (us-central1-aiplatform.googleapis.com).File yang diedit akan terlihat seperti ini:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-dataservice-host.us-central1-a.c.PROJECT_ID.internal on-prem-dataservice-host # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleSimpan file sebagai berikut:
- Jika Anda menggunakan
vim, tekan tombolEsc, lalu ketik:wquntuk menyimpan file dan keluar. - Jika Anda menggunakan
nano, ketikControl+Odan tekanEnteruntuk menyimpan file, lalu ketikControl+Xuntuk keluar.
- Jika Anda menggunakan
Ping endpoint Vertex AI API sebagai berikut:
ping us-central1-aiplatform.googleapis.comPerintah
pingakan menampilkan output berikut.192.168.0.1adalah alamat IP endpoint PSC:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.Ketik
Control+Cuntuk keluar dariping.Ketik
exituntuk keluar dari instance VMon-prem-dataservice-hostdan kembali ke prompt Cloud Shell.
Mengonfigurasi jaringan untuk instance Filestore
Di bagian ini, Anda akan mengaktifkan akses layanan pribadi untuk jaringan VPC, sebagai persiapan untuk membuat instance Filestore dan memasangnya sebagai berbagi Network File System (NFS). Untuk memahami apa yang Anda lakukan di bagian ini dan bagian berikutnya, lihat Memasang berbagi NFS untuk pelatihan kustom dan Menyiapkan Peering Jaringan VPC.
Mengaktifkan akses layanan pribadi di jaringan VPC
Di bagian ini, Anda akan membuat koneksi Jaringan Layanan dan menggunakannya
untuk mengaktifkan akses layanan pribadi ke jaringan VPC onprem-dataservice-vpc
melalui Peering Jaringan VPC.
Di Cloud Shell, tetapkan rentang alamat IP yang dicadangkan menggunakan
gcloud compute addresses create:gcloud compute addresses create filestore-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=10.243.208.0 \ --prefix-length=24 \ --description="filestore subnet" \ --network=onprem-dataservice-vpcBuat koneksi peering antara jaringan VPC
onprem-dataservice-vpcdan Jaringan Layanan Google, menggunakangcloud services vpc-peerings connect:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=filestore-subnet \ --network=onprem-dataservice-vpcPerbarui Peering Jaringan VPC untuk mengaktifkan impor dan ekspor rute kustom yang dipelajari:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=onprem-dataservice-vpc \ --import-custom-routes \ --export-custom-routesDi konsol Google Cloud , buka halaman VPC network peering.
Dalam daftar peering VPC, pastikan ada entri untuk peering antara
servicenetworking.googleapis.comdan jaringan VPConprem-dataservice-vpc.
Buat pemberitahuan rute kustom untuk filestore-subnet
Di konsol Google Cloud , buka halaman Cloud Router.
Di daftar Cloud Router, klik
onprem-dataservice-vpc-router1.Di halaman detail Router, klik Edit.
Di bagian Advertised routes untuk Routes, pilih Create custom routes.
Centang kotak Beriklan semua subnet yang terlihat oleh Cloud Router untuk terus mengiklankan subnet yang tersedia untuk Cloud Router. Mengaktifkan opsi ini meniru perilaku Cloud Router dalam mode iklan default.
Klik Tambahkan rute kustom.
Untuk Sumber, pilih Rentang IP kustom.
Untuk IP address range, masukkan rentang alamat IP berikut:
10.243.208.0/24Untuk Deskripsi, masukkan teks berikut:
Filestore reserved IP address rangeKlik Selesai, lalu klik Simpan.
Buat instance Filestore di jaringan onprem-dataservice-vpc
Setelah mengaktifkan akses layanan pribadi untuk jaringan VPC, Anda dapat membuat instance Filestore dan memasang instance sebagai berbagi NFS untuk tugas pelatihan kustom. Hal ini memungkinkan tugas pelatihan Anda mengakses file jarak jauh seolah-olah file tersebut bersifat lokal, sehingga memungkinkan throughput tinggi dan latensi rendah.
Buat instance Filestore
Di konsol Google Cloud , buka halaman Filestore Instances.
Klik Create instance dan konfigurasikan instance sebagai berikut:
Setel Instance ID ke berikut ini:
image-data-instanceSetel Instance type ke Basic.
Tetapkan Storage type ke HDD.
Tetapkan Allocate capacity ke 1
TiB.Tetapkan Region ke us-central1 dan Zone ke us-central1-c.
Tetapkan VPC network ke
onprem-dataservice-vpc.Tetapkan Allocated IP range ke Use an existing allocated IP range, lalu pilih
filestore-subnet.Tetapkan File share name ke berikut ini:
vol1Setel Kontrol akses ke Beri akses ke semua klien di jaringan VPC.
Klik Buat.
Catat alamat IP untuk instance Filestore baru Anda. Anda mungkin perlu memuat ulang tab browser konsol untuk melihat instance baru. Google Cloud
Pasang berbagi file Filestore
Di Cloud Shell, jalankan perintah berikut, ganti PROJECT_ID dengan project ID Anda:
projectid=PROJECT_ID gcloud config set project ${projectid}Login ke instance VM
on-prem-dataservice-host:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapInstal paket NFS di instance VM:
sudo apt-get update -y sudo apt-get -y install nfs-commonBuat direktori pemasangan untuk berbagi file Filestore:
sudo mkdir -p /mnt/nfsPasang berbagi file, ganti FILESTORE_INSTANCE_IP dengan alamat IP untuk instance Filestore Anda:
sudo mount FILESTORE_INSTANCE_IP:/vol1 /mnt/nfsJika waktu tunggu koneksi habis, periksa dan pastikan Anda memberikan alamat IP yang benar untuk instance Filestore.
Validasi bahwa pemasangan NFS berhasil dengan menjalankan perintah berikut:
df -hPastikan berbagi file
/mnt/nfsmuncul di hasil:Filesystem Size Used Avail Use% Mounted on udev 1.8G 0 1.8G 0% /dev tmpfs 368M 396K 368M 1% /run /dev/sda1 9.7G 1.9G 7.3G 21% / tmpfs 1.8G 0 1.8G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/sda15 124M 11M 114M 9% /boot/efi tmpfs 368M 0 368M 0% /run/user 10.243.208.2:/vol1 1007G 0 956G 0% /mnt/nfsBuat berbagi file dapat diakses dengan mengubah izin:
sudo chmod go+rw /mnt/nfs
Mendownload set data ke berbagi file
Di instance VM
on-prem-dataservice-host, download set data ke file yang dibagikan:gcloud storage cp gs://cloud-samples-data/vertex-ai/dataset-management/datasets/fungi_dataset /mnt/nfs/ --recursiveProses download memerlukan waktu beberapa menit.
Pastikan set data berhasil disalin dengan menjalankan perintah berikut:
sudo du -sh /mnt/nfsBerikut adalah output yang diinginkan:
104M /mnt/nfsKetik
exituntuk keluar dari instance VMon-prem-dataservice-hostdan kembali ke prompt Cloud Shell.
Membuat bucket staging untuk pipeline
Vertex AI Pipelines menyimpan artefak operasi pipeline Anda menggunakan Cloud Storage. Sebelum menjalankan pipeline, Anda harus membuat bucket Cloud Storage untuk staging operasi pipeline.
Di Cloud Shell, buat bucket Cloud Storage:
gcloud storage buckets create gs://pipelines-staging-bucket-$projectid --location=us-central1
Membuat akun layanan yang dikelola pengguna untuk Vertex AI Workbench
Di Cloud Shell, buat akun layanan:
gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Tetapkan peran Vertex AI User (
roles/aiplatform.user) ke akun layanan:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid." \ --role="roles/aiplatform.user"Tetapkan peran Administrator Artifact Registry (
artifactregistry.admin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid." \ --role="roles/artifactregistry.admin"Tetapkan peran Storage Admin (
storage.admin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid." \ --role="roles/storage.admin"
Buat aplikasi pelatihan Python
Di bagian ini, Anda akan membuat instance Vertex AI Workbench dan menggunakannya untuk membuat paket aplikasi pelatihan kustom Python.
Membuat instance Vertex AI Workbench
Di konsol Google Cloud , buka tab Instances di halaman Vertex AI Workbench.
Klik Buat baru, lalu klik Opsi lanjutan.
Halaman New instance akan terbuka.
Di halaman New instance, di bagian Details, berikan informasi berikut untuk instance baru Anda, lalu klik Continue:
Nama: Masukkan berikut ini, dengan mengganti PROJECT_ID dengan project ID:
pipeline-tutorial-PROJECT_IDRegion: Pilih us-central1.
Zona: Pilih us-central1-a.
Hapus centang pada kotak Aktifkan Sesi Interaktif Dataproc Serverless.
Di bagian Lingkungan, klik Lanjutkan.
Di bagian Jenis mesin, berikan informasi berikut, lalu klik Lanjutkan:
- Jenis mesin: Pilih N1, lalu pilih
n1-standard-4dari menu Jenis mesin. Shielded VM: Pilih kotak centang berikut:
- Secure Boot
- Virtual Trusted Platform Module (vTPM)
- Integrity monitoring
- Jenis mesin: Pilih N1, lalu pilih
Di bagian Disk, pastikan Google-managed encryption key dipilih, lalu klik Lanjutkan:
Di bagian Networking, berikan hal berikut, lalu klik Lanjutkan:
Networking: Pilih Network dalam project ini dan selesaikan langkah-langkah berikut:
Di kolom Network, pilih vertex-networking-vpc.
Di kolom Subnetwork, pilih pipeline-networking-subnet1.
Hapus centang pada kotak Tetapkan alamat IP eksternal. Dengan tidak menetapkan alamat IP eksternal, Anda dapat mencegah instance menerima komunikasi yang tidak diminta dari internet atau jaringan VPC lainnya.
Centang kotak Izinkan akses proxy.
Di bagian IAM dan keamanan, berikan hal berikut, lalu klik Lanjutkan:
IAM dan keamanan: Untuk memberikan akses kepada satu pengguna ke antarmuka JupyterLab instance, selesaikan langkah-langkah berikut:
- Pilih Service account.
- Hapus centang pada kotak Gunakan akun layanan default Compute Engine.
Langkah ini penting, karena akun layanan default Compute Engine (dan dengan demikian satu pengguna yang baru saja Anda tentukan) dapat memiliki peran Editor (
roles/editor) pada project Anda. Di kolom Service account email, masukkan berikut ini, dengan mengganti PROJECT_ID dengan project ID:
workbench-sa@PROJECT_ID.(Ini adalah alamat email akun layanan khusus yang Anda buat sebelumnya.) Akun layanan ini memiliki izin terbatas.
Untuk mempelajari lebih lanjut cara memberikan akses, lihat Mengelola akses ke antarmuka JupyterLab instance Vertex AI Workbench.
Opsi keamanan: Hapus centang pada kotak berikut:
- Akses root ke instance
Centang kotak berikut:
- nbconvert:
nbconvertmemungkinkan pengguna mengekspor dan mendownload file notebook sebagai jenis file berbeda, seperti HTML, PDF, atau LaTeX. Setelan ini diperlukan oleh beberapa notebook di repositori GitHub Google Cloud Generative AI.
Hapus centang pada kotak berikut:
- Mendownload file
Pilih kotak centang berikut, kecuali jika Anda berada di lingkungan produksi:
- Akses terminal: Ini memungkinkan akses terminal ke instance Anda dari dalam antarmuka pengguna JupyterLab.
Di bagian Kondisi sistem, hapus centang pada Upgrade otomatis lingkungan dan berikan hal berikut:
Di Pelaporan, centang kotak berikut:
- Melaporkan kondisi sistem
- Melaporkan metrik kustom ke Cloud Monitoring
- Menginstal Cloud Monitoring
- Melaporkan status DNS untuk domain Google yang diperlukan
Klik Create dan tunggu beberapa menit hingga instance Vertex AI Workbench dibuat.
Jalankan aplikasi pelatihan di instance Vertex AI Workbench
Di konsol Google Cloud , buka tab Instances di halaman Vertex AI Workbench.
Di samping nama instance Vertex AI Workbench (
pipeline-tutorial-PROJECT_ID), dengan PROJECT_ID adalah ID project, klik Open JupyterLab.Instance Vertex AI Workbench Anda akan terbuka di JupyterLab.
Pilih File > New > Terminal.
Di terminal JupyterLab (bukan Cloud Shell), tentukan variabel lingkungan untuk project Anda. Ganti PROJECT_ID dengan project ID Anda:
projectid=PROJECT_IDBuat direktori induk untuk aplikasi pelatihan (masih di terminal JupyterLab):
mkdir fungi_training_package mkdir fungi_training_package/trainerDi File Browser, klik dua kali folder
fungi_training_package, lalu klik dua kali foldertrainer.Di File Browser, klik kanan daftar file kosong (di bagian judul Name), lalu pilih New file.
Klik kanan file baru, lalu pilih Ganti nama file.
Ganti nama file dari
untitled.txtmenjaditask.py.Klik dua kali file
task.pyuntuk membukanya.Salin kode berikut ke
task.py:# Import the libraries import tensorflow as tf from tensorflow.python.client import device_lib import argparse import os import sys # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--data-dir', dest='dataset_dir', type=str, help='Dir to access dataset.') parser.add_argument('--model-dir', dest='model_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the model.') parser.add_argument('--epochs', dest='epochs', default=10, type=int, help='Number of epochs.') parser.add_argument('--batch-size', dest='batch_size', default=32, type=int, help='Number of images per batch.') parser.add_argument('--distribute', dest='distribute', default='single', type=str, help='distributed training strategy.') args = parser.parse_args() # print the tf version and config print('Python Version = {}'.format(sys.version)) print('TensorFlow Version = {}'.format(tf.__version__)) print('TF_CONFIG = {}'.format(os.environ.get('TF_CONFIG', 'Not found'))) print('DEVICES', device_lib.list_local_devices()) # Single Machine, single compute device if args.distribute == 'single': if tf.test.is_gpu_available(): strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0") else: strategy = tf.distribute.OneDeviceStrategy(device="/cpu:0") # Single Machine, multiple compute device elif args.distribute == 'mirror': strategy = tf.distribute.MirroredStrategy() # Multiple Machine, multiple compute device elif args.distribute == 'multi': strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy() # Multi-worker configuration print('num_replicas_in_sync = {}'.format(strategy.num_replicas_in_sync)) # Preparing dataset BUFFER_SIZE = 1000 IMG_HEIGHT = 224 IMG_WIDTH = 224 def make_datasets_batched(dataset_path, global_batch_size): # Configure the training data generator train_data_dir = os.path.join(dataset_path,"train/") train_ds = tf.keras.utils.image_dataset_from_directory( train_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # Configure the validation data generator val_data_dir = os.path.join(dataset_path,"valid/") val_ds = tf.keras.utils.image_dataset_from_directory( val_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # get the number of classes in the data num_classes = len(train_ds.class_names) # Configure the dataset for performance AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(BUFFER_SIZE).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE) return train_ds, val_ds, num_classes # Build the Keras model def build_and_compile_cnn_model(num_classes): # build a CNN model model = tf.keras.models.Sequential([ tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)), tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(num_classes) ]) # compile the CNN model model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) return model # Get the strategy data NUM_WORKERS = strategy.num_replicas_in_sync # Here the batch size scales up by number of workers GLOBAL_BATCH_SIZE = args.batch_size * NUM_WORKERS # Create dataset generator objects train_ds, val_ds, num_classes = make_datasets_batched(args.dataset_dir, GLOBAL_BATCH_SIZE) # Compile the model with strategy.scope(): # Creation of dataset, and model building/compiling need to be within # `strategy.scope()`. model = build_and_compile_cnn_model(num_classes) # fit the model on the data history = model.fit(train_ds, validation_data=val_ds, epochs=args.epochs) # save the model to the output dir model.save(args.model_dir)Pilih File > Save Python file.
Di terminal JupyterLab, buat file
__init__.pydi setiap subdirektori untuk menjadikannya sebuah paket:touch fungi_training_package/__init__.py touch fungi_training_package/trainer/__init__.pyDi File Browser, klik dua kali folder
fungi_training_package.Pilih File > New > Python file.
Klik kanan file baru, lalu pilih Ganti nama file.
Ganti nama file dari
untitled.pymenjadisetup.py.Klik dua kali file
setup.pyuntuk membukanya.Salin kode berikut ke
setup.py:from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for fungi-classification.' )Pilih File > Save Python file.
Di terminal, buka direktori
fungi_training_package:cd fungi_training_packageGunakan perintah
sdistuntuk membuat distribusi sumber aplikasi pelatihan:python setup.py sdist --formats=gztarBuka direktori induk:
cd ..Verifikasi bahwa Anda berada di direktori yang benar:
pwdOutputnya akan terlihat seperti ini:
/home/jupyterSalin paket Python ke bucket penyiapan:
gcloud storage cp fungi_training_package/dist/trainer-0.1.tar.gz gs://pipelines-staging-bucket-$projectid/training_package/Pastikan bucket penyiapan berisi paket:
gcloud storage ls gs://pipelines-staging-bucket-$projectid/training_packageOutputnya adalah:
gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz
Buat koneksi Service Networking untuk Vertex AI Pipelines
Di bagian ini, Anda membuat koneksi Service Networking yang digunakan untuk membuat layanan produsen yang terhubung ke jaringan VPC vertex-networking-vpc melalui Peering Jaringan VPC. Untuk mengetahui informasi selengkapnya, lihat
Peering Jaringan VPC.
Di Cloud Shell, jalankan perintah berikut, ganti PROJECT_ID dengan project ID Anda:
projectid=PROJECT_ID gcloud config set project ${projectid}Tetapkan rentang alamat IP yang dicadangkan menggunakan
gcloud compute addresses create:gcloud compute addresses create vertex-pipeline-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=192.168.10.0 \ --prefix-length=24 \ --description="pipeline subnet" \ --network=vertex-networking-vpcBuat koneksi peering antara jaringan VPC
vertex-networking-vpcdan Jaringan Layanan Google, menggunakangcloud services vpc-peerings connect:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=vertex-pipeline-subnet \ --network=vertex-networking-vpcPerbarui koneksi peering VPC untuk mengaktifkan impor dan ekspor rute kustom yang dipelajari:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=vertex-networking-vpc \ --import-custom-routes \ --export-custom-routes
Mengiklankan subnet pipeline dari Cloud Router pipeline-networking
Di konsol Google Cloud , buka halaman Cloud Router.
Di daftar Cloud Router, klik
vertex-networking-vpc-router1.Di halaman detail Router, klik Edit.
Klik Tambahkan rute kustom.
Untuk Sumber, pilih Rentang IP kustom.
Untuk IP address range, masukkan rentang alamat IP berikut:
192.168.10.0/24Untuk Deskripsi, masukkan teks berikut:
Vertex AI Pipelines reserved subnetKlik Selesai, lalu klik Simpan.
Membuat template pipeline dan menguploadnya ke Artifact Registry
Di bagian ini, Anda akan membuat dan mengupload template pipeline Kubeflow Pipelines (KFP). Template ini berisi definisi alur kerja yang dapat digunakan kembali beberapa kali, oleh satu pengguna atau beberapa pengguna.
Menentukan dan mengompilasi pipeline
Di JupyterLab, di File Browser, klik dua kali folder tingkat teratas.
Pilih File > New > Notebook.
Dari menu Select Kernel, pilih
Python 3 (ipykernel), lalu klik Select.Di sel notebook baru, jalankan perintah berikut untuk memastikan Anda memiliki
pipversi terbaru:!python -m pip install --upgrade pipJalankan perintah berikut untuk menginstal SDK Komponen Pipeline Google Cloud dari Python Package Index (PyPI):
!pip install --upgrade google-cloud-pipeline-componentsSetelah penginstalan selesai, pilih Kernel > Restart kernel untuk memulai ulang kernel dan memastikan bahwa library tersedia untuk diimpor.
Jalankan kode berikut di sel notebook baru untuk menentukan pipeline:
from kfp import dsl # define the train-deploy pipeline @dsl.pipeline(name="custom-image-classification-pipeline") def custom_image_classification_pipeline( project: str, training_job_display_name: str, worker_pool_specs: list, base_output_dir: str, model_artifact_uri: str, prediction_container_uri: str, model_display_name: str, endpoint_display_name: str, network: str = '', location: str="us-central1", serving_machine_type: str="n1-standard-4", serving_min_replica_count: int=1, serving_max_replica_count: int=1 ): from google_cloud_pipeline_components.types import artifact_types from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp from google_cloud_pipeline_components.v1.model import ModelUploadOp from google_cloud_pipeline_components.v1.endpoint import (EndpointCreateOp, ModelDeployOp) from kfp.dsl import importer # Train the model task custom_job_task = CustomTrainingJobOp( project=project, display_name=training_job_display_name, worker_pool_specs=worker_pool_specs, base_output_directory=base_output_dir, location=location, network=network ) # Import the model task import_unmanaged_model_task = importer( artifact_uri=model_artifact_uri, artifact_class=artifact_types.UnmanagedContainerModel, metadata={ "containerSpec": { "imageUri": prediction_container_uri, }, }, ).after(custom_job_task) # Model upload task model_upload_op = ModelUploadOp( project=project, display_name=model_display_name, unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"], ) model_upload_op.after(import_unmanaged_model_task) # Create Endpoint task endpoint_create_op = EndpointCreateOp( project=project, display_name=endpoint_display_name, ) # Deploy the model to the endpoint ModelDeployOp( endpoint=endpoint_create_op.outputs["endpoint"], model=model_upload_op.outputs["model"], dedicated_resources_machine_type=serving_machine_type, dedicated_resources_min_replica_count=serving_min_replica_count, dedicated_resources_max_replica_count=serving_max_replica_count, )Jalankan kode berikut di sel notebook baru untuk mengompilasi definisi pipeline:
from kfp import compiler PIPELINE_FILE = "pipeline_config.yaml" compiler.Compiler().compile( pipeline_func=custom_image_classification_pipeline, package_path=PIPELINE_FILE, )Di File Browser, file bernama
pipeline_config.yamlakan muncul dalam daftar file.
Membuat repositori Artifact Registry
Jalankan kode berikut di sel notebook baru untuk membuat repositori artefak jenis KFP:
REPO_NAME="fungi-repo" REGION="us-central1" !gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFP
Mengupload template pipeline ke Artifact Registry
Di bagian ini, Anda akan mengonfigurasi klien registry Kubeflow Pipelines SDK dan mengupload template pipeline yang dikompilasi ke Artifact Registry dari notebook JupyterLab.
Di notebook JupyterLab, jalankan kode berikut untuk mengupload template pipeline, dengan mengganti PROJECT_ID dengan project ID Anda:
PROJECT_ID = "PROJECT_ID" from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."})Di konsol Google Cloud , untuk memverifikasi bahwa template Anda telah diupload, buka Vertex AI Pipelines templates.
Untuk membuka panel Pilih repositori, klik Pilih repositori.
Di daftar repositori, klik repositori yang Anda buat (
fungi-repo), lalu klik Pilih.Pastikan pipeline Anda (
custom-image-classification-pipeline) muncul dalam daftar.
Memicu eksekusi pipeline dari lokal
Di bagian ini, setelah template pipeline dan paket pelatihan siap, Anda akan menggunakan cURL untuk memicu eksekusi pipeline dari aplikasi lokal.
Berikan parameter pipeline
Di notebook JupyterLab, jalankan perintah berikut untuk memverifikasi nama template pipeline:
print (TEMPLATE_NAME)Nama template yang ditampilkan adalah:
custom-image-classification-pipelineJalankan perintah berikut untuk mendapatkan versi template pipeline:
print (VERSION_NAME)Nama versi template pipeline yang ditampilkan akan terlihat seperti ini:
sha256:41eea21e0d890460b6e6333c8070d7d23d314afd9c7314c165efd41cddff86c7Catat seluruh string nama versi.
Di Cloud Shell, jalankan perintah berikut, ganti PROJECT_ID dengan project ID Anda:
projectid=PROJECT_ID gcloud config set project ${projectid}Login ke instance VM
on-prem-dataservice-host:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapDi instance VM
on-prem-dataservice-host, gunakan editor teks sepertivimataunanountuk membuat filerequest_body.json, misalnya:sudo vim request_body.jsonTambahkan teks berikut ke file
request_body.json:{ "displayName": "fungi-image-pipeline-job", "serviceAccount": "onprem-user-managed-sa@PROJECT_ID.", "runtimeConfig":{ "gcsOutputDirectory":"gs://pipelines-staging-bucket-PROJECT_ID/pipeline_root/", "parameterValues": { "project": "PROJECT_ID", "training_job_display_name": "fungi-image-training-job", "worker_pool_specs": [{ "machine_spec": { "machine_type": "n1-standard-4" }, "replica_count": 1, "python_package_spec":{ "executor_image_uri":"us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8.py310:latest", "package_uris": ["gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args": ["--data-dir","/mnt/nfs/fungi_dataset/", "--epochs", "10"], "env": [{"name": "AIP_MODEL_DIR", "value": "gs://pipelines-staging-bucket-PROJECT_ID/model/"}] }, "nfs_mounts": [{ "server": "FILESTORE_INSTANCE_IP", "path": "/vol1", "mount_point": "/mnt/nfs/" }] }], "base_output_dir":"gs://pipelines-staging-bucket-PROJECT_ID", "model_artifact_uri":"gs://pipelines-staging-bucket-PROJECT_ID/model/", "prediction_container_uri":"us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest", "model_display_name":"fungi-image-model", "endpoint_display_name":"fungi-image-endpoint", "location": "us-central1", "serving_machine_type":"n1-standard-4", "network":"projects/PROJECT_NUMBER/global/networks/vertex-networking-vpc" } }, "templateUri": "https://us-central1-kfp.pkg.dev/PROJECT_ID/fungi-repo/custom-image-classification-pipeline/latest", "templateMetadata": { "version":"VERSION_NAME" } }Ganti nilai berikut:
- PROJECT_ID: project ID Anda
- PROJECT_NUMBER: nomor project. ID ini berbeda dengan ID project. Anda dapat menemukan nomor project di halaman Project Settings untuk project di konsol Google Cloud .
- FILESTORE_INSTANCE_IP: alamat IP instance Filestore, misalnya,
10.243.208.2. Anda dapat menemukannya di halaman Filestore Instances untuk instance Anda. - VERSION_NAME: nama versi template pipeline (
sha256:...) yang Anda catat di langkah 2.
Simpan file sebagai berikut:
- Jika Anda menggunakan
vim, tekan tombolEsc, lalu ketik:wquntuk menyimpan file dan keluar. - Jika Anda menggunakan
nano, ketikControl+Odan tekanEnteruntuk menyimpan file, lalu ketikControl+Xuntuk keluar.
- Jika Anda menggunakan
Mengirimkan operasi pipeline dari template Anda
Di instance VM
on-prem-dataservice-host, jalankan perintah berikut, dengan mengganti PROJECT_ID dengan project ID Anda:curl -v -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request_body.json \ https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/pipelineJobsOutput yang Anda lihat cukup panjang, tetapi hal utama yang perlu Anda cari adalah baris berikut, yang menunjukkan bahwa layanan sedang bersiap untuk menjalankan pipeline:
"state": "PIPELINE_STATE_PENDING"Seluruh proses pipeline memerlukan waktu sekitar 45 hingga 50 menit.
Di konsol Google Cloud , di bagian Vertex AI, buka tab Runs di halaman Pipelines.
Klik nama proses pipeline Anda (
custom-image-classification-pipeline).Halaman pipeline akan muncul dan menampilkan grafik runtime pipeline. Ringkasan pipeline muncul di panel Analisis proses pipeline.
Untuk mendapatkan bantuan dalam memahami informasi yang ditampilkan dalam grafik runtime, termasuk cara melihat log dan menggunakan Vertex ML Metadata untuk mempelajari lebih lanjut artefak pipeline Anda, lihat Memvisualisasikan dan menganalisis hasil pipeline.
Pembersihan
Agar tidak menimbulkan biaya pada Google Cloud akun Anda untuk resource yang digunakan dalam tutorial ini, Anda dapat menghapus project yang berisi resource tersebut, atau menyimpan project dan menghapus setiap resource.
Anda dapat menghapus setiap resource dalam project dengan cara berikut:
Hapus semua proses pipeline sebagai berikut:
Di konsol Google Cloud , di bagian Vertex AI, buka tab Runs di halaman Pipelines.
Pilih proses pipeline yang akan dihapus, lalu klik Hapus.
Hapus template pipeline sebagai berikut:
Di bagian Vertex AI, buka tab Your templates di halaman Pipelines.
Di samping template pipeline
custom-image-classification-pipeline, klik Tindakan, lalu pilih Hapus.
Hapus repositori dari Artifact Registry sebagai berikut:
Di halaman Artifact Registry, buka tab Repositories.
Pilih repositori
fungi-repo, lalu klik Hapus.
Batalkan deployment model dari endpoint sebagai berikut:
Di bagian Vertex AI, buka tab Endpoints di halaman Online predictions.
Klik
fungi-image-endpointuntuk membuka halaman detail endpoint.Di baris untuk model Anda,
fungi-image-model, klik Tindakan, lalu pilih Batalkan deployment model dari endpoint.Pada dialog Batalkan deployment model dari endpoint, klik Batalkan deployment.
Hapus endpoint sebagai berikut:
Di bagian Vertex AI, buka tab Endpoints di halaman Online predictions.
Pilih
fungi-image-endpoint, lalu klik Hapus.
Hapus model sebagai berikut:
Buka halaman Model Registry.
Di baris untuk model Anda,
fungi-image-model, klik Tindakan, lalu pilih Hapus model.
Hapus bucket penyiapan sebagai berikut:
Buka halaman Cloud Storage.
Pilih
pipelines-staging-bucket-PROJECT_ID, dengan PROJECT_ID adalah project ID, lalu klik Hapus.
Hapus instance Vertex AI Workbench sebagai berikut:
Di bagian Vertex AI, buka tab Instances di halaman Workbench.
Pilih instance Vertex AI Workbench
pipeline-tutorial-PROJECT_IDdengan PROJECT_ID adalah ID project, lalu klik Delete.
Hapus instance VM Compute Engine sebagai berikut:
Buka halaman Compute Engine.
Pilih instance VM
on-prem-dataservice-host, lalu klik Hapus.
Hapus tunnel VPN sebagai berikut:
Buka halaman VPN.
Di halaman VPN, klik tab Cloud VPN Tunnels.
Dalam daftar tunnel VPN, pilih empat tunnel VPN yang Anda buat dalam tutorial ini, lalu klik Hapus.
Hapus gateway VPN dengan ketersediaan tinggi (HA) sebagai berikut:
Di halaman VPN, klik tab Cloud VPN Gateways.
Dalam daftar gateway VPN, klik
onprem-vpn-gw1.Di halaman Detail gateway Cloud VPN, klik Hapus Gateway VPN.
Klik panah kembali jika perlu untuk kembali ke daftar gateway VPN, lalu klik
vertex-networking-vpn-gw1.Di halaman Detail gateway Cloud VPN, klik Hapus Gateway VPN.
Hapus Cloud Router sebagai berikut:
Buka halaman Cloud Router.
Dalam daftar Cloud Router, pilih empat router yang Anda buat dalam tutorial ini.
Untuk menghapus router, klik Hapus.
Tindakan ini juga akan menghapus dua gateway Cloud NAT yang terhubung ke Cloud Router.
Hapus koneksi Service Networking ke jaringan VPC
vertex-networking-vpcdanonprem-dataservice-vpcsebagai berikut:Buka halaman VPC Network Peering.
Pilih
servicenetworking-googleapis-com.Untuk menghapus koneksi, klik Hapus.
Hapus aturan penerusan
pscvertexuntuk jaringan VPCvertex-networking-vpcsebagai berikut:Buka tab Frontend di halaman Load balancing.
Dalam daftar aturan penerusan, klik
pscvertex.Di halaman Global forwarding rule details, klik Delete.
Hapus instance Filestore sebagai berikut:
Buka halaman Filestore.
Pilih instance
image-data-instance.Untuk menghapus instance, klik Tindakan, lalu klik Hapus instance.
Hapus jaringan VPC sebagai berikut:
Buka halaman VPC networks.
Dalam daftar jaringan VPC, klik
onprem-dataservice-vpc.Di halaman VPC network details, klik Delete VPC Network.
Menghapus setiap jaringan juga akan menghapus subnetwork, rute, dan aturan firewall-nya.
Dalam daftar jaringan VPC, klik
vertex-networking-vpc.Di halaman VPC network details, klik Delete VPC Network.
Hapus akun layanan
workbench-sadanonprem-user-managed-sasebagai berikut:Buka halaman Akun layanan.
Pilih akun layanan
onprem-user-managed-sadanworkbench-sa, lalu klik Hapus.
Langkah berikutnya
Pelajari cara menggunakan Vertex AI Pipelines untuk mengatur proses pembuatan dan deployment model machine learning Anda.
Pelajari set data deFungi.