Los modelos de aprendizaje automático suelen ser "cajas negras"; ni siquiera sus diseñadores pueden explicar cómo o por qué un modelo ha producido una inferencia específica. Vertex Explainable AI ofrece explicaciones basadas en funciones y basadas en ejemplos para comprender mejor el proceso de toma de decisiones de los modelos.
Saber cómo se comporta un modelo y cómo influye en él el conjunto de datos de entrenamiento ofrece a cualquier persona que cree o use aprendizaje automático nuevas formas de mejorar los modelos, generar confianza en sus inferencias y entender cuándo y por qué las cosas no salen bien.
Explicaciones basadas en ejemplos
Con las explicaciones basadas en ejemplos, Vertex AI usa la búsqueda de vecinos más cercanos para devolver una lista de ejemplos (normalmente del conjunto de entrenamiento) que sean los más similares a la entrada. Como solemos esperar que entradas similares produzcan inferencias similares, podemos usar estas explicaciones para explorar y explicar el comportamiento de nuestro modelo.
Las explicaciones basadas en ejemplos pueden ser útiles en varios casos:
Mejorar los datos o el modelo: uno de los principales casos prácticos de las explicaciones basadas en ejemplos es ayudarte a entender por qué tu modelo ha cometido determinados errores en sus inferencias y usar esa información valiosa para mejorar los datos o el modelo. Para ello, primero selecciona los datos de prueba que te interesen. Esto puede deberse a las necesidades de la empresa o a heurísticas, como los datos en los que el modelo ha cometido los errores más graves.
Por ejemplo, supongamos que tenemos un modelo que clasifica las imágenes como pájaro o avión y clasifica erróneamente el siguiente pájaro como avión con un alto nivel de confianza. Usa explicaciones basadas en ejemplos para obtener imágenes similares del conjunto de entrenamiento y averiguar qué está pasando.

Como todas las explicaciones son siluetas oscuras de la clase de avión, es una señal para obtener más siluetas de pájaros.
Sin embargo, si las explicaciones procedían principalmente de la clase de aves, es una señal de que nuestro modelo no puede aprender relaciones aunque los datos sean abundantes, por lo que deberíamos aumentar la complejidad del modelo (por ejemplo, añadiendo más capas).
Interpretar datos nuevos: supongamos que tu modelo se ha entrenado para clasificar pájaros y aviones, pero en el mundo real, el modelo también se encuentra con imágenes de cometas, drones y helicópteros. Si tu conjunto de datos de vecinos más cercanos incluye algunas imágenes etiquetadas de cometas, drones y helicópteros, puedes usar explicaciones basadas en ejemplos para clasificar imágenes nuevas aplicando la etiqueta que se repite con más frecuencia en sus vecinos más cercanos. Esto es posible porque esperamos que la representación latente de las cometas sea diferente de la de los pájaros o los aviones, y más similar a las cometas etiquetadas del conjunto de datos de vecinos más cercanos.
Detectar anomalías: intuitivamente, si una instancia está lejos de todos los datos del conjunto de entrenamiento, es probable que sea un valor atípico. Se sabe que las redes neuronales tienen demasiada confianza en sus errores, por lo que los ocultan. Monitorizar tus modelos con explicaciones basadas en ejemplos te ayuda a identificar los valores atípicos más graves.
Aprendizaje activo: las explicaciones basadas en ejemplos pueden ayudarte a identificar las instancias que se pueden beneficiar del etiquetado humano. Esto es especialmente útil si el etiquetado es lento o caro, ya que te permite obtener el conjunto de datos más completo posible a partir de recursos de etiquetado limitados.
Por ejemplo, supongamos que tenemos un modelo que clasifica a un paciente como si tiene un resfriado o una gripe. Si se clasifica a un paciente como si tuviera gripe y todas las explicaciones basadas en ejemplos son de la clase de gripe, el médico puede confiar más en la inferencia del modelo sin tener que examinarlo más a fondo. Sin embargo, si algunas de las explicaciones son de la clase de la gripe y otras de la clase del resfriado, merece la pena consultar a un médico. De esta forma, se obtiene un conjunto de datos en el que las instancias difíciles tienen más etiquetas, lo que facilita que los modelos posteriores aprendan relaciones complejas.
Para crear un modelo que admita explicaciones basadas en ejemplos, consulta Configurar explicaciones basadas en ejemplos.
Tipos de modelos admitidos
Se admite cualquier modelo de TensorFlow que pueda proporcionar una inserción (representación latente) para las entradas. No se admiten modelos basados en árboles, como los árboles de decisión. Aún no se admiten modelos de otros frameworks, como PyTorch o XGBoost.
En el caso de las redes neuronales profundas, generalmente se asume que las capas superiores (más cercanas a la capa de salida) han aprendido algo "significativo", por lo que a menudo se elige la penúltima capa para las inserciones. Experimenta con varias capas, analiza los ejemplos que obtienes y elige uno en función de algunas medidas cuantitativas (coincidencia de clase) o cualitativas (parece lógico).
Para ver una demostración de cómo extraer embeddings de un modelo de TensorFlow y realizar una búsqueda de vecinos más cercanos, consulta el notebook con una explicación basada en ejemplos.
Explicaciones basadas en características
Vertex Explainable AI integra las atribuciones de funciones en Vertex AI. En esta sección se ofrece una breve descripción conceptual de los métodos de atribución de funciones disponibles en Vertex AI.
Las atribuciones de características indican cuánto ha contribuido cada característica de tu modelo a las inferencias de cada instancia. Cuando solicitas inferencias, obtienes los valores adecuados para tu modelo. Cuando solicitas explicaciones, obtienes las inferencias junto con la información de atribución de funciones.
Las atribuciones de características funcionan con datos tabulares e incluyen funciones de visualización integradas para datos de imágenes. Ten en cuenta los siguientes ejemplos:
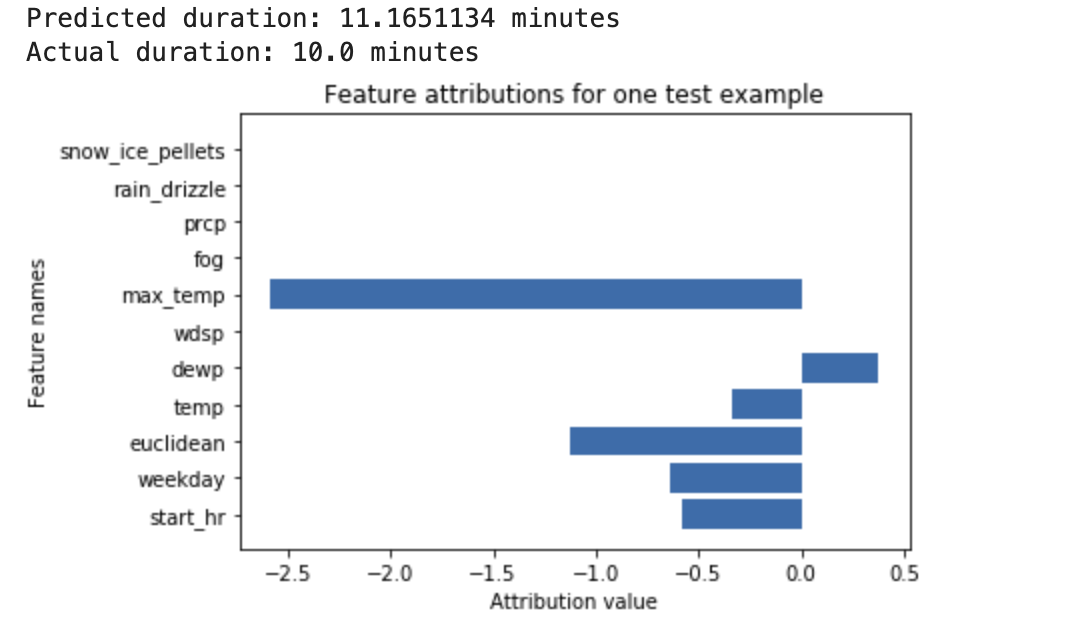
Se entrena una red neuronal profunda para predecir la duración de un trayecto en bicicleta a partir de datos meteorológicos y datos anteriores de viajes compartidos. Si solo solicitas inferencias de este modelo, obtendrás las duraciones previstas de los trayectos en bicicleta en minutos. Si solicitas explicaciones, obtendrás la duración prevista del viaje en bicicleta, así como una puntuación de atribución para cada característica de tu solicitud de explicaciones. Las puntuaciones de atribución muestran cuánto ha afectado la función al cambio en el valor de inferencia en relación con el valor de referencia que especifiques. Elige un valor de referencia significativo que tenga sentido para tu modelo. En este caso, la duración media de los trayectos en bicicleta. Puede representar gráficamente las puntuaciones de atribución de las características para ver cuáles han contribuido en mayor medida a la inferencia resultante:
Un modelo de clasificación de imágenes se entrena para predecir si una imagen determinada contiene un perro o un gato. Si solicitas inferencias de este modelo en un nuevo conjunto de imágenes, recibirás una inferencia para cada imagen ("perro" o "gato"). Si solicitas explicaciones, obtendrás la clase predicha junto con una superposición de la imagen que muestra qué píxeles de la imagen han contribuido en mayor medida a la inferencia resultante:

Foto de un gato con una superposición de atribución de funciones 
Foto de un perro con una superposición de atribución de funciones Un modelo de clasificación de imágenes se entrena para predecir la especie de una flor en la imagen. Si solicitas inferencias de este modelo en un nuevo conjunto de imágenes, recibirás una inferencia por cada imagen ("margarita" o "diente de león"). Si solicitas explicaciones, obtendrás la clase predicha junto con una superposición de la imagen que muestra las zonas de la imagen que más han contribuido a la inferencia resultante:

Foto de una margarita con una superposición de atribución de función
Tipos de modelos admitidos
La atribución de características se admite en todos los tipos de modelos (tanto AutoML como entrenados de forma personalizada), frameworks (TensorFlow, scikit y XGBoost), modelos de BigQuery ML y modalidades (imágenes, texto, datos tabulares y vídeo).
Para usar la atribución de características, configura tu modelo para la atribución de características cuando subas o registres el modelo en Vertex AI Model Registry.
Además, en los siguientes tipos de modelos de AutoML, la atribución de características está integrada en la Google Cloud consola:
- Modelos de imagen de AutoML (solo modelos de clasificación)
- Modelos tabulares de AutoML (solo modelos de clasificación y regresión)
En los tipos de modelos de AutoML que están integrados, puedes habilitar la atribución de características en la Google Cloud consola durante el entrenamiento y ver la importancia de las características del modelo en general, así como la importancia de las características locales para las inferencias online y por lotes.
En el caso de los tipos de modelos de AutoML que no estén integrados, puedes habilitar la atribución de características exportando los artefactos del modelo y configurando la atribución de características cuando subas los artefactos del modelo al registro de modelos de Vertex AI.
Ventajas
Si inspeccionas instancias específicas y agregas atribuciones de características en tu conjunto de datos de entrenamiento, puedes obtener información más detallada sobre cómo funciona tu modelo. Ten en cuenta las siguientes ventajas:
Depuración de modelos: las atribuciones de funciones pueden ayudar a detectar problemas en los datos que las técnicas de evaluación de modelos estándar suelen pasar por alto.
Por ejemplo, un modelo de patología de imágenes obtuvo resultados sospechosamente buenos en un conjunto de datos de prueba de imágenes de radiografías de tórax. Las atribuciones de las funciones revelaron que la alta precisión del modelo dependía de las marcas de bolígrafo del radiólogo en la imagen. Para obtener más información sobre este ejemplo, consulta el informe sobre explicaciones de IA.
Optimizar modelos: puede identificar y eliminar las funciones que sean menos importantes, lo que puede dar lugar a modelos más eficientes.
Métodos de atribución de funciones
Cada método de atribución de funciones se basa en los valores de Shapley, un algoritmo de teoría de juegos cooperativos que asigna crédito a cada jugador de un juego por un resultado concreto. Aplicado a los modelos de aprendizaje automático, esto significa que cada característica del modelo se trata como un "jugador" en el juego. Vertex Explainable AI asigna un crédito proporcional a cada función por el resultado de una inferencia concreta.
Método de Shapley muestreado
El método Valor de Shapley muestreado proporciona una aproximación por muestreo de los valores de Shapley exactos. Los modelos tabulares de AutoML usan el método de Shapley muestreado para determinar la importancia de las características. El muestreo de Shapley funciona bien con estos modelos, que son meta-conjuntos de árboles y redes neuronales.
Para obtener información detallada sobre cómo funciona el método de Shapley muestreado, consulta el artículo Bounding the Estimation Error of Sampling-based Shapley Value Approximation (en inglés).
Método de gradientes integrados
En el método de gradientes integrados, el gradiente de la salida de inferencia se calcula con respecto a las características de la entrada a lo largo de una ruta integral.
- Los gradientes se calculan en intervalos diferentes de un parámetro de escalado. El tamaño de cada intervalo se determina mediante la regla de cuadratura gaussiana. En el caso de los datos de imagen, imagina que este parámetro de escalado es un control deslizante que escala todos los píxeles de la imagen a negro.
- Los gradientes se integran de la siguiente manera:
- La integral se aproxima mediante una media ponderada.
- Se calcula el producto de los gradientes promediados y la entrada original elemento a elemento.
Para obtener una explicación intuitiva de este proceso aplicado a las imágenes, consulta la entrada de blog "Attributing a deep network's inference to its input features" (Atribuir la inferencia de una red profunda a sus características de entrada). Los autores del artículo original sobre gradientes integrados (Axiomatic Attribution for Deep Networks) muestran en la entrada de blog anterior cómo son las imágenes en cada paso del proceso.
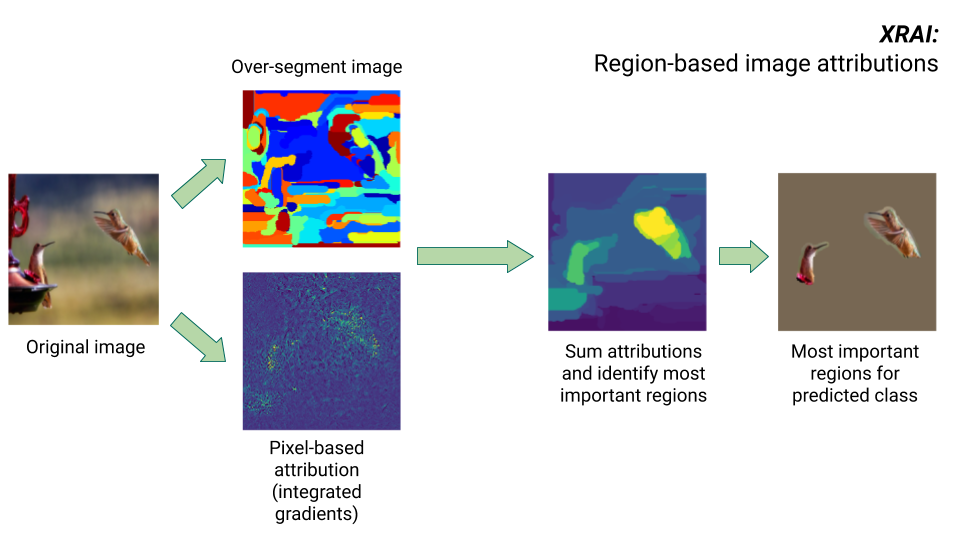
Método XRAI
El método XRAI combina el método de gradientes integrados con pasos adicionales para determinar qué regiones de la imagen contribuyen más a una inferencia de clase determinada.
- Atribución a nivel de píxel: XRAI realiza la atribución a nivel de píxel de la imagen de entrada. En este paso, XRAI usa el método de gradientes integrados con una línea de base negra y una línea de base blanca.
- Sobresegmentación: independientemente de la atribución a nivel de píxel, XRAI sobresegmenta la imagen para crear un mosaico de regiones pequeñas. XRAI usa el método basado en gráficos de Felzenswalb para crear los segmentos de imagen.
- Selección de la región: XRAI agrega la atribución a nivel de píxel de cada segmento para determinar su densidad de atribución. Con estos valores, XRAI clasifica cada segmento y, a continuación, los ordena de más a menos positivo. Esto determina qué áreas de la imagen son las más destacadas o las que más contribuyen a una inferencia de clase determinada.
Comparar métodos de atribución de funciones
Vertex Explainable AI ofrece tres métodos para usar las atribuciones de características: Shapley muestreado, degradados integrados y XRAI.
| Método | Explicación básica | Tipos de modelos recomendados | Ejemplos de casos prácticos | Recursos de Vertex AI Model compatibles |
|---|---|---|---|---|
| Shapley muestreado | Asigna la contribución al resultado a cada función y tiene en cuenta las diferentes permutaciones de las funciones. Este método proporciona una aproximación de muestreo de los valores de Shapley exactos. | Modelos no diferenciables, como conjuntos de árboles y redes neuronales |
|
|
| Degradados integrados | Un método basado en gradientes para calcular de forma eficiente las atribuciones de las funciones con las mismas propiedades axiomáticas que el valor de Shapley. | Modelos diferenciables, como las redes neuronales. Se recomienda especialmente
para modelos con espacios de características grandes. Recomendado para imágenes de bajo contraste, como radiografías. |
|
|
| XRAI (explicación con integrales de área clasificadas) | XRAI se basa en el método de gradientes integrados para evaluar las regiones superpuestas de la imagen y crear un mapa de prominencia que destaque las regiones relevantes de la imagen en lugar de los píxeles. | Modelos que aceptan entradas de imagen. Se recomienda especialmente para imágenes naturales, que son escenas del mundo real que contienen varios objetos. |
|
|
Para ver una comparación más detallada de los métodos de atribución, consulta el libro blanco sobre las explicaciones de la IA.
Modelos diferenciables y no diferenciables
En los modelos diferenciables, puedes calcular la derivada de todas las operaciones de tu gráfico de TensorFlow. Esta propiedad permite que se produzca la retropropagación en estos modelos. Por ejemplo, las redes neuronales son diferenciables. Para obtener atribuciones de características de modelos diferenciables, usa el método de gradientes integrados.
El método de gradientes integrados no funciona con modelos no diferenciables. Consulta más información sobre cómo codificar entradas no diferenciables para que funcionen con el método de gradientes integrados.
Los modelos no diferenciables incluyen operaciones no diferenciables en el gráfico de TensorFlow, como las operaciones que realizan tareas de decodificación y redondeo. Por ejemplo, un modelo creado como un conjunto de árboles y redes neuronales no es diferenciable. Para obtener atribuciones de funciones de modelos no diferenciables, usa el método de Shapley muestreado. El muestreo de Shapley también funciona en modelos diferenciables, pero en ese caso, es más costoso computacionalmente de lo necesario.
Limitaciones conceptuales
Tenga en cuenta las siguientes limitaciones de las atribuciones de funciones:
Las atribuciones de características, incluida la importancia de las características locales de AutoML, son específicas de las inferencias individuales. Inspeccionar las atribuciones de características de una inferencia individual puede proporcionar información valiosa, pero esta información puede no ser generalizable a toda la clase de esa instancia individual o a todo el modelo.
Para obtener información más generalizable sobre los modelos de AutoML, consulta la importancia de las características del modelo. Para obtener estadísticas más generalizables para otros modelos, agrega atribuciones en subconjuntos de tu conjunto de datos o en todo el conjunto de datos.
Aunque las atribuciones de las funciones pueden ayudar a depurar modelos, no siempre indican claramente si un problema surge del modelo o de los datos con los que se entrena el modelo. Usa tu buen criterio y diagnostica los problemas de datos habituales para acotar el espacio de posibles causas.
Las atribuciones de características están sujetas a ataques adversarios similares a las inferencias de modelos complejos.
Para obtener más información sobre las limitaciones, consulta la lista de limitaciones generales y el informe técnico sobre explicaciones de IA.
Referencias
En el caso de la atribución de funciones, las implementaciones de Shapley muestreado, degradados integrados y XRAI se basan en las siguientes referencias, respectivamente:
- Acotación del error de estimación del valor de Shapley basado en muestreo aproximación
- Atribución axiomática para redes profundas
- XRAI: mejores atribuciones a través de regiones
Para obtener más información sobre la implementación de Vertex Explainable AI, consulta el libro blanco sobre explicaciones de IA.
Notebooks
Para empezar a usar Vertex Explainable AI, utiliza estos cuadernos:
| Cuaderno | Método de explicabilidad | Framework de aprendizaje automático | Modalidad | Tarea |
|---|---|---|---|---|
| Enlace de GitHub | Explicaciones basadas en ejemplos | TensorFlow | imagen | Entrenar un modelo de clasificación que prediga la clase de la imagen de entrada proporcionada y obtener explicaciones online |
| Enlace de GitHub | basada en características | AutoML | tabular | Entrenar un modelo de clasificación binaria que prediga si un cliente de un banco ha comprado un depósito a plazo y obtener explicaciones por lotes |
| Enlace de GitHub | basada en características | AutoML | tabular | Entrenar un modelo de clasificación que prediga el tipo de especie de flor de iris y obtener explicaciones online |
| Enlace de GitHub | Basado en las funciones (Shapley muestreado) | scikit‑learn | tabular | Entrenar un modelo de regresión lineal que prediga las tarifas de los taxis y obtener explicaciones online |
| Enlace de GitHub | Basado en funciones (gradientes integrados) | TensorFlow | imagen | Entrenar un modelo de clasificación que prediga la clase de la imagen de entrada proporcionada y obtener explicaciones por lotes |
| Enlace de GitHub | Basado en funciones (gradientes integrados) | TensorFlow | imagen | Entrenar un modelo de clasificación que prediga la clase de la imagen de entrada proporcionada y obtener explicaciones online |
| Enlace de GitHub | Basado en funciones (gradientes integrados) | TensorFlow | tabular | Entrenar un modelo de regresión que prediga el precio medio de una casa y obtener explicaciones por lotes |
| Enlace de GitHub | Basado en funciones (gradientes integrados) | TensorFlow | tabular | Entrenar un modelo de regresión que prediga el precio medio de una casa y obtener explicaciones online |
| Enlace de GitHub | Basado en las funciones (Shapley muestreado) | TensorFlow | texto | Entrenar un modelo LSTM que clasifique las reseñas de películas como positivas o negativas usando el texto de la reseña y obtener explicaciones online |
Recursos educativos
Los siguientes recursos ofrecen más material educativo útil:
- Explainable AI para profesionales
- Aprendizaje automático interpretable: valores de Shapley
- El repositorio de GitHub de gradientes integrados de Ankur Taly.
- Introducción a los valores de Shapley
Siguientes pasos
- Configurar el modelo para obtener explicaciones basadas en características
- Configurar un modelo para que genere explicaciones basadas en ejemplos
- Consulta la importancia de las características de los modelos tabulares de AutoML.