Os modelos de machine learning costumam ser "caixas pretas". Até os designers deles não conseguem explicar como ou por que um modelo produziu uma inferência específica. A Vertex Explainable AI oferece explicações baseadas em atributos e em exemplos para entender melhor a tomada de decisões do modelo.
Saber como um modelo se comporta e como o conjunto de dados de treinamento influencia o modelo dá a qualquer pessoa que cria ou usa ML novas habilidades para melhorar modelos, criar confiança em inferências e entender quando e por que as coisas dão errado.
Explicações baseadas em exemplos
Com explicações baseadas em exemplos, a Vertex AI usa a pesquisa vizinha mais próxima para retornar uma lista de exemplos, geralmente do conjunto de treinamento, que são mais semelhantes à entrada. Como geralmente esperamos entradas semelhantes para gerar inferências semelhantes, podemos usar essas explicações para explorar e explicar o comportamento do modelo.
As explicações com base em exemplos podem ser úteis em vários cenários:
Melhorar seus dados ou modelo: um dos principais casos de uso para explicações baseadas em exemplos é ajudar você a entender por que seu modelo cometeu determinados erros nas inferências e usar esses insights para melhorar seus dados ou modelo. Para fazer isso, primeiro selecione os dados de teste do seu interesse. Isso pode ser impulsionado por necessidades de negócios ou por heurística, como dados em que o modelo cometeu os erros mais graves.
Por exemplo, suponha que temos um modelo que classifica imagens como um pássaro ou um avião e classifica incorretamente o pássaro a seguir como um avião com alta confiança. Use explicações baseadas em exemplo para recuperar imagens semelhantes do conjunto de treinamento e descobrir o que está acontecendo.

Como todas as explicações são silhuetas escuras da classe avião, é um sinal para ver mais silhuetas de pássaros.
No entanto, se as explicações forem principalmente da classe de pássaro, é um sinal de que o modelo não consegue aprender relações mesmo quando os dados estão ricos, e devemos considerar aumentar a complexidade do modelo (por exemplo, adicionar mais camadas).
Interpretar dados novos: suponha que seu modelo tenha sido treinado para classificar aves e aviões, mas, no mundo real, também encontra imagens de pipas, drones e helicópteros. Se o conjunto de dados vizinho mais próximo incluir algumas imagens rotuladas de pipas, drones e helicópteros, será possível usar explicações baseadas em exemplos para classificar imagens novas aplicando o rótulo mais comum dos vizinhos mais próximos. Isso é possível porque esperamos que a representação latente de pipas seja diferente da representação de aves ou aviões e mais parecida com as pipas rotuladas no conjunto de dados vizinho mais próximo.
Detectar anomalias: de maneira intuitiva, se uma instância estiver longe de todos os dados do conjunto de treinamento, provavelmente ela é um outlier. As redes neurais são conhecidas por serem excessivamente confiantes sobre os erros cometidos, mascarando-os. O monitoramento dos modelos usando explicações baseadas em exemplos ajuda a identificar os outliers mais graves.
Aprendizado ativo: as explicações com base em exemplos ajudam a identificar as instâncias que podem se beneficiar da rotulagem humana. Isso é particularmente útil se a rotulagem for lenta ou cara, garantindo que você consiga o conjunto de dados mais rico possível com recursos de rotulagem limitados.
Por exemplo, suponha que temos um modelo que classifica um paciente médico como resfriado ou gripe. Se um paciente é classificado como tendo gripe e todas as explicações baseadas em exemplos são da classe da gripe, o médico pode ter mais confiança na inferência do modelo sem ter que revisar a informação. No entanto, se algumas das explicações forem da classe da gripe e outras da classe fria, vale a pena consultar a opinião de um médico. Isso levará a um conjunto de dados em que instâncias difíceis têm mais rótulos, facilitando o aprendizado de relações complexas com modelos downstream.
Para criar um modelo compatível com explicações baseadas em exemplos, consulte Como configurar explicações com base em exemplos.
Tipos de modelos compatíveis
Qualquer modelo do TensorFlow que possa fornecer uma incorporação (representação atrasada) para entradas é compatível. Modelos baseados em árvore, como árvores de decisão, não são compatíveis. Modelos de outros frameworks, como PyTorch ou XGBoost, ainda não são compatíveis.
Para redes neurais profundas, geralmente consideramos que as camadas superiores (mais próximas da camada de saída) aprenderam algo "significativo" e, portanto, a penúltima camada geralmente é escolhida para embeddings. Teste algumas camadas diferentes, investigue os exemplos que você está recebendo e escolha uma com base em algumas medidas quantitativas (correspondência de classe) ou qualitativas (parecem relevantes).
Para ver uma demonstração de como extrair embeddings de um modelo do TensorFlow e executar a pesquisa de vizinho mais próximo, consulte o notebook de explicação baseado em exemplo (link em inglês).
Explicações baseadas em atributos
O Explainable AI integra atribuições de recursos à Vertex AI. Nesta página, apresentamos uma breve visão geral conceitual dos métodos de atribuição de recursos disponíveis com a Vertex AI.
As atribuições de recursos indicam o quanto cada elemento no seu modelo contribuiu para as inferências de cada instância determinada. Ao solicitar inferências, você recebe valores adequados para seu modelo. Quando você solicita explicações, recebe as inferências junto com as informações de atribuição de recursos.
As atribuições de recursos funcionam em dados tabulares e incluem recursos de visualização integrados para dados de imagem. Veja estes exemplos:
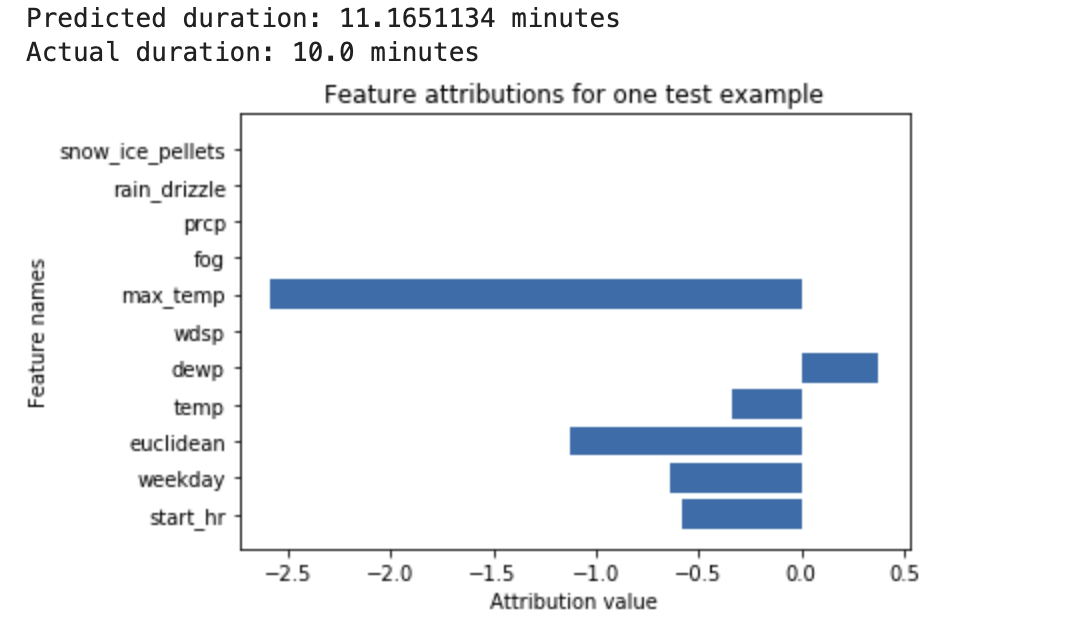
Uma rede neural profunda é treinada para prever a duração de um passeio de bicicleta, com base em dados meteorológicos e em dados anteriores de compartilhamento de carona. Se você solicitar apenas inferências desse modelo, as durações previstas de passeios de bicicleta serão calculadas em minutos. Se você solicitar explicações, receberá a previsão da duração do passeio de bicicleta, além de uma pontuação de atribuição para cada recurso na sua solicitação de explicações. As pontuações de atribuição mostram quanto o recurso afetou a mudança no valor de inferência, em relação ao valor de referência especificado. Escolha um valor de referência significativo que faça sentido para seu modelo. Nesse caso, a duração média do passeio de bicicleta. É possível traçar as pontuações de atribuição de recursos para ver quais recursos contribuíram mais para a inferência resultante:
Um modelo de classificação de imagens é treinado para prever se uma determinada imagem contém um cão ou um gato. Se você solicitar inferências desse modelo em um novo conjunto de imagens, receberá uma inferência para cada imagem ("cão" ou "gato"). Se você solicitar explicações, receberá a classe prevista junto com uma sobreposição da imagem, mostrando quais pixels na imagem contribuíram mais para a inferência resultante:

Uma foto de um gato com sobreposição de atribuição de recursos 
Uma foto de um cão com sobreposição de atribuição de recursos Um modelo de classificação de imagem é treinado para prever as espécies de uma flor na imagem. Se você solicitar inferências desse modelo em um novo conjunto de imagens, vai receber uma inferência para cada imagem ("margarida" ou "dente-de-leão"). Se você solicitar explicações, receberá a classe prevista junto com uma sobreposição para a imagem, mostrando quais áreas na imagem contribuíram mais fortemente para a inferência resultante:

Uma foto de uma margarida com sobreposição de atribuição de recursos
Tipos de modelos compatíveis
A atribuição de atributos é compatível com todos os tipos de modelos (AutoML e treinados sob medida), frameworks (TensorFlow, scikit e XGBoost), modelos do BigQuery ML e modalidades (imagens, texto, tabular e vídeo).
Para usar a atribuição de recursos, configure seu modelo para atribuição de recursos ao fazer upload ou registrar o modelo no Vertex AI Model Registry.
Além disso, para os seguintes tipos de modelos do AutoML, a atribuição de recursos é integrada ao console Google Cloud :
- Modelos de imagem do AutoML (somente modelos de classificação)
- Modelos tabulares do AutoML (somente modelos de classificação e regressão)
Para tipos de modelo do AutoML integrados, é possível ativar a atribuição de recursos no console Google Cloud durante o treinamento e ver a importância do recurso do modelo para o modelo em geral e a importância do recurso local para inferências on-line e em lote.
Para tipos de modelo do AutoML não integrados, ainda é possível ativar a aplicação de atributos exportando os artefatos de modelo e configurando a aplicação de atributos ao fazer upload dos artefatos de modelo para o Vertex AI Model Registry.
Vantagens
Se você inspecionar instâncias específicas e também agregar atribuições de recursos em todo o conjunto de dados de treinamento, poderá ter insights mais detalhados sobre o funcionamento do modelo. Considere as seguintes vantagens:
Depuração de modelos: as atribuições de recursos podem ajudar a detectar problemas nos dados que as técnicas padrão de avaliação de modelos geralmente não detectam.
Por exemplo, um modelo de patologia de imagens teve resultados suspeitos em um conjunto de dados de teste de imagens de radiografia de tórax. As atribuições de recursos revelaram que a precisão alta do modelo dependia das marcas de caneta do radiologista na imagem. Para mais detalhes sobre este exemplo, consulte o whitepaper do AI Explanations.
Otimização de modelos: é possível identificar e remover recursos que são menos importantes, o que pode resultar em modelos mais eficientes.
Métodos de atribuição de recursos
Cada método de atribuição de recurso é baseado em valores de Shapley: um algoritmo cooperativo de teoria de jogos que atribui crédito a cada jogador em um jogo para um determinado resultado. Aplicado a modelos de aprendizado de máquina, cada recurso do modelo é tratado como um "jogador" no jogo. A Vertex Explainable AI atribui crédito proporcional a cada recurso para o resultado de uma inferência específica.
Método de amostra de Shapley
O método Sampled Shapley fornece uma amostra da aproximação de valor exato do Shapley. Os modelos tabulares do AutoML usam o método Sampled Shapley para importar atributos. O Sampled Shapley funciona bem para esses modelos, que são metagentes de árvores e redes neurais.
Para informações detalhadas sobre o funcionamento do método Sampled Shapley, leia o artigo Como limitar o erro de estimativa da aproximação de valor do Sampled Shapley.
Método dos gradientes integrados
No método de gradientes integrados, o gradiente da saída de inferência é calculado em relação aos elementos da entrada, ao longo de um caminho integral.
- Os gradientes são calculados em intervalos diferentes de um parâmetro de escalonamento. O tamanho de cada intervalo é determinado usando a regra da quadratura gaussiana. Para dados de imagem, imagine esse parâmetro de escalonamento como um "controle deslizante" que está escalonando todos os pixels da imagem para preto.
- Os gradientes são integrados da seguinte maneira:
- A integral é aproximada usando uma média ponderada.
- O produto elementar dos gradientes médios e da entrada original é calculado.
Para uma explicação intuitiva desse processo aplicado às imagens, consulte a postagem do blog "Como atribuir uma inferência de rede profunda aos recursos de entrada" (em inglês). Os autores do documento original sobre gradientes integrados (Atribuição axiomática para redes profundas) mostram na postagem anterior do blog como são as imagens em cada etapa do processo.
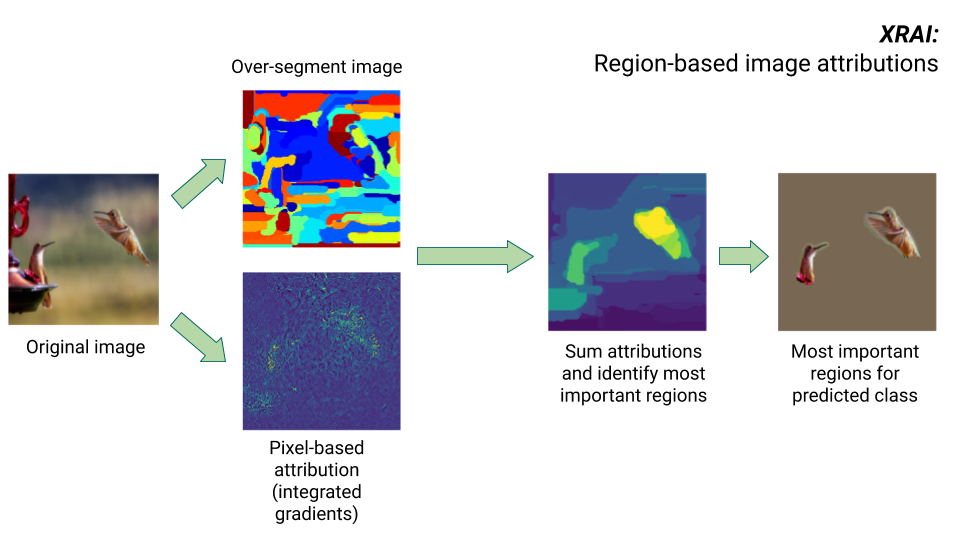
Método XRAI
O método XRAI combina o método de gradientes integrados com etapas extras para determinar quais regiões da imagem contribuem mais para uma determinada inferência de classe.
- Atribuição no nível do pixel: o XRAI executa a atribuição no nível do pixel para a imagem de entrada. Nesta etapa, o XRAI usa o método de gradientes integrados com um valor de referência preto e um valor de referência branco.
- Supersegmentação: independentemente da atribuição no nível de pixel, o XRAI supersegmenta a imagem para criar uma colcha de retalhos de pequenas regiões. A XRAI usa o método baseado em gráficos de Felzenswalb (em inglês) para criar os segmentos de imagem.
- Seleção de região: o XRAI agrega a atribuição em nível de pixel em cada segmento para determinar sua densidade de atribuição. Usando esses valores, o XRAI classifica cada segmento e depois ordena os segmentos de mais positivo ao menos positivo. Isso determina quais áreas da imagem são mais salientes ou contribuem mais fortemente para uma determinada inferência de classe.
Comparar métodos de atribuição de recursos
A Vertex Explainable AI oferece três métodos a serem usados para atribuições de recursos: Sampled Shapley, gradientes integrados e XRAI.
| Método | Explicação básica | Tipos de modelo recomendados | Casos de uso de exemplo | Recursos Model da Vertex AI compatíveis |
|---|---|---|---|---|
| Sampled Shapley | Atribui crédito para o resultado a cada recurso e considera permutações diferentes dos recursos. Esse método oferece uma aproximação de amostragem dos valores exatos de Shapley. | Modelos não diferenciais, como conjuntos de árvores e redes neurais |
|
|
| Gradientes integrados | Um método com base em gradientes para computar com eficiência as atribuições de recursos com as mesmas propriedades axiomáticas do valor de Shapley. | Modelos diferenciais, como redes neurais. Recomendado especialmente para modelos com grandes espaços de recursos. Recomendado para imagens de baixo contraste, como raio-X. |
|
|
| XRAI (eXplanation with Ranked Area Integrals) | Com base no método de gradientes integrados, o XRAI avalia regiões sobrepostas da imagem para criar um mapa de saliência, que destaca regiões relevantes da imagem em vez de pixels. | Modelos que aceitam entradas de imagem. Recomendado especialmente para imagens naturais, que são cenas reais que contêm vários objetos. |
|
|
Para uma comparação mais detalhada dos métodos de atribuição, consulte o whitepaper sobre explicações do AI.
Modelos diferenciais e não diferenciais
Em modelos diferenciais, é possível calcular a derivada de todas as operações no seu gráfico do TensorFlow. Essa propriedade ajuda a possibilitar a retropropagação nesses modelos. Por exemplo, as redes neurais são diferenciais. Para conseguir atribuições de recursos para modelos diferenciais, use o método de gradientes integrados.
O método integrado de gradientes não funciona para modelos não diferenciais. Saiba mais sobre a codificação de entradas não diferenciais para trabalhar com o método de gradientes integrados.
Os modelos não diferenciais incluem operações não diferenciais no gráfico do TensorFlow, como operações que executam tarefas de decodificação e arredondamento. Por exemplo, um modelo criado como um conjunto de árvores e redes neurais é não diferenciável. Para conseguir atribuições de recursos para modelos não diferenciais, use o método Sampled Shapley. O Sampled Shapley também funciona em modelos diferenciais, mas, nesse caso, ele é computacionalmente mais caro do que o necessário.
Limitações conceituais
Considere as seguintes limitações de atribuições de recursos:
As atribuições de recursos, incluindo a importância do recurso local do AutoML, são específicas para inferências individuais. Inspecionar as atribuições de recursos para uma inferência individual pode oferecer insights bons, mas o insight pode não ser generalizado para toda a classe dessa instância individual ou para todo o modelo.
Para conseguir insights mais gerais para modelos do AutoML, consulte a importância do recurso do modelo. Para receber insights mais gerais para outros modelos, agregue atribuições em subconjuntos ao seu conjunto de dados ou em todo o conjunto de dados.
Embora as atribuições de recursos possam ajudar com a depuração do modelo, nem sempre indicam claramente se um problema surge no modelo ou nos dados em que o modelo é treinado. Use seu bom senso e diagnostique problemas comuns de dados para reduzir o espaço de causas possíveis.
As atribuições de recursos estão sujeitas a ataques adversários semelhantes, como inferências em modelos complexos.
Para mais informações sobre limitações, consulte a lista de limitações de alto nível e o whitepaper sobre o AI Explanations.
Referências
Para a atribuição de recursos, as implementações do Sampled Shapley, gradientes integrados e XRAI são baseadas nas seguintes referências, respectivamente:
- Limitação do erro de estimativa da aproximação do valor de Shapley baseado em amostragem
- Atribuição axiomática para redes profundas
- XRAI: melhores atribuições por meio de regiões (em inglês)
Saiba mais sobre a implementação da IA explicável lendo o whitepaper sobre explicações da IA.
Notebooks
Para começar a usar a Vertex Explainable AI, use estes notebooks:
| Notebook | Método de explicação | Framework de ML | Modalidade | Tarefa |
|---|---|---|---|---|
| Link do GitHub | explicações com base em exemplos | TensorFlow | image | Treinar um modelo de classificação que prevê a classe da imagem de entrada fornecida e receber explicações on-line |
| Link do GitHub | com base em atributo | AutoML | tabular | Treinar um modelo de classificação binária que prevê se um banco personalizado adquiriu um depósito a prazo e receber explicações em lote |
| Link do GitHub | com base em atributo | AutoML | tabular | Treinar um modelo de classificação que prevê o tipo de espécie de flor de íris e receber explicações on-line |
| Link do GitHub | com base em atributos (amostra de Shapley) | scikit-learn | tabular | Treinar um modelo de regressão linear que prevê tarifas de táxi e receber explicações on-line |
| Link do GitHub | com base em atributos (gradientes integrados) | TensorFlow | image | Treinar um modelo de classificação que prevê a classe da imagem de entrada fornecida e receber explicações em lote |
| Link do GitHub | com base em atributos (gradientes integrados) | TensorFlow | image | Treinar um modelo de classificação que prevê a classe da imagem de entrada fornecida e receber explicações on-line |
| Link do GitHub | com base em atributos (gradientes integrados) | TensorFlow | tabular | Treinar um modelo de regressão que prevê o preço médio de uma casa e receber explicações em lote |
| Link do GitHub | com base em atributos (gradientes integrados) | TensorFlow | tabular | Treinar um modelo de regressão que prevê o preço médio de uma casa e receber explicações on-line |
| Link do GitHub | com base em atributos (amostra de Shapley) | TensorFlow | text | Treinar um modelo de LSTM que classifica críticas de filmes como positivas ou negativas usando o texto da crítica e receber explicações on-line |
Recursos educacionais
Os seguintes recursos oferecem materiais educacionais úteis:
- Explainable AI para profissionais (em inglês)
- Aprendizado de máquina interpretável: valores de Shapley (em inglês)
- Repositório do GitHub de gradientes integrados de Ankur Taly (em inglês).
- Introdução aos valores de Shapley (em inglês)
A seguir
- Configurar o modelo para explicações baseadas em atributos
- Configurar o modelo para explicações baseadas em exemplos
- Veja a importância de recursos para modelos tabulares do AutoML.