機器學習模型通常是「黑箱」,就連設計人員也無法解釋模型如何或為何產生特定推論。Vertex Explainable AI 提供特徵式和範例式解釋,助您深入瞭解模型如何做出決定。
瞭解模型的行為方式,以及訓練資料集對模型的影響,可讓機器學習的建構者或使用者具備新能力,進而改善模型、對推論結果更有信心,並瞭解何時及為何會出錯。
範例式解釋
採用範例式解釋時,Vertex AI 會透過最鄰近搜尋,傳回與輸入內容最相似的樣本清單 (通常來自訓練集)。一般來說,我們預期類似的輸入內容會產生類似的推論,因此可以使用這些說明來探索及說明模型的行為。
範例式解釋適用於下列幾種情況:
改善資料或模型:以範例為基礎的說明主要用途之一,是協助您瞭解模型在推論時為何會犯下某些錯誤,並運用這些洞察資料改善資料或模型。如要這麼做,請先選取您感興趣的測試資料。這可能是由業務需求或啟發式方法 (例如模型發生最嚴重錯誤的資料) 所驅動。
舉例來說,假設我們有一個模型會將圖片分類為鳥類或飛機,但模型以高信賴度將下列鳥類誤分類為飛機。使用範例式解釋,從訓練集中擷取類似圖片,找出問題所在。

由於所有說明都是飛機類別的深色輪廓,因此這是取得更多鳥類輪廓的信號。
不過,如果說明主要來自鳥類,這表示即使資料豐富,模型也無法學習關係,因此我們應考慮增加模型複雜度 (例如新增更多層)。
解讀新穎資料:假設您的模型經過訓練,可分類鳥類和飛機,但在現實世界中,模型也會遇到風箏、無人機和直升機的圖片。如果最鄰近項目資料集包含一些風箏、無人機和直升機的標記圖片,您可以套用最鄰近項目最常出現的標籤,透過範例式解釋分類新圖片。這是因為我們預期風箏的潛在表示法與鳥類或飛機不同,但與最鄰近資料集中的標記風箏相似。
偵測異常狀況:直覺上,如果執行個體與訓練集中的所有資料相距甚遠,則很可能是離群值。類神經網路在出錯時往往過於自信,因此會掩蓋錯誤。使用範例式說明監控模型,有助於找出最嚴重的離群值。
主動學習:以範例為基礎的說明可協助您找出可能需要人工標籤的執行個體。如果標籤作業緩慢或成本高昂,這項功能就特別實用,可確保您從有限的標籤資源中取得最豐富的資料集。
舉例來說,假設我們有一個模型,可將醫療病患分類為感冒或流感。如果系統將病患歸類為流感,且所有以範例為準的說明都來自流感類別,醫生就能對模型的推論結果更有信心,不必仔細檢查。不過,如果部分說明來自流感類別,其他說明來自感冒類別,建議您尋求醫生的意見。這樣一來,資料集中就會有更多難以辨識的執行個體標籤,方便後續模型學習複雜關係。
如要建立支援以範例為基礎的說明的模型,請參閱「設定以範例為基礎的說明」。
支援的模型類型
系統支援任何可針對輸入內容提供嵌入 (潛在表示) 的 TensorFlow 模型。系統不支援樹狀結構模型,例如決策樹。目前尚不支援其他架構的模型,例如 PyTorch 或 XGBoost。
對於深層類神經網路,我們通常會假設較高層 (靠近輸出層) 已學到「有意義」的內容,因此通常會選擇倒數第二層做為嵌入。嘗試使用幾種不同的層,研究您取得的範例,並根據一些量化 (類別相符) 或質化 (看起來合理) 的指標選擇一種。
如要瞭解如何從 TensorFlow 模型擷取嵌入,並執行最鄰近搜尋,請參閱以範例為基礎的說明筆記本。
特徵式解釋
Vertex Explainable AI 會將特徵重要性整合至 Vertex AI。本節提供概念的簡短總覽,瞭解 Vertex AI 支援的特徵歸因方法。
特徵歸因會指出模型中的各項特徵對每個指定執行個體推論結果的影響程度。要求推論時,系統會根據模型提供適當的值。要求說明時,您會收到推論結果和特徵歸因資訊。
特徵重要性適用於表格資料,並內建圖像資料的視覺化功能。請見以下範例:
系統會根據天氣資料和先前的共乘資料,訓練深層類神經網路預測騎乘時間。如果您只要求從這個模型進行推論,系統會以分鐘數為單位,提供預測的騎乘時間。如果您要求說明,系統會提供預測的單車行程時間,以及說明要求中每個特徵的歸因分數。相較於您指定的基準值,歸因分數會顯示這項功能對推論值變化的影響程度。選擇對模型有意義的基準,在此案例中為單車騎乘時間中位數。您可以繪製特徵屬性分數,瞭解哪些特徵對推論結果的影響最大:

圖片分類模型經過訓練後,可預測指定圖片是否含有狗或貓。如果您對一組新圖片要求此模型進行推論,則會收到每張圖片的推論結果 (「狗」或「貓」)。如果您要求說明,系統會提供預測類別,以及圖片的疊加層,顯示圖片中哪些像素對推論結果的影響最大:

貓咪相片,上方疊加特徵歸因 
狗狗相片,上方疊加特徵歸因 圖片分類模型經過訓練後,可預測圖片中的花卉品種。如果您對一組新圖片要求從這個模型進行推論,則會收到每張圖片的推論結果 (「雛菊」或「蒲公英」)。如果您要求說明,系統會提供預測類別和圖片的疊加層,顯示圖片中對推論結果影響最大的區域:

雛菊相片,並疊加特徵屬性
支援的模型類型
特徵歸因適用於所有類型的模型 (包括 AutoML 和自訂訓練模型)、架構 (TensorFlow、scikit、XGBoost)、BigQuery ML 模型和模態 (圖片、文字、表格、影片)。
如要使用特徵歸因,請在將模型上傳或註冊至 Vertex AI Model Registry 時,設定模型的特徵歸因。
此外,對於下列類型的 AutoML 模型,特徵歸因會整合至 Google Cloud 控制台:
- AutoML 圖片模型 (僅限分類模型)
- AutoML 表格模型 (僅限分類和迴歸模型)
對於整合的 AutoML 模型類型,您可以在訓練期間透過 Google Cloud 控制台啟用特徵歸因,並查看模型的特徵重要性,以及線上和批次推論的局部特徵重要性。
對於未整合的 AutoML 模型類型,您仍可匯出模型構件,並在將模型構件上傳至 Vertex AI Model Registry 時設定特徵歸因,藉此啟用特徵歸因。
優點
檢查特定執行個體,並彙整訓練資料集中的特徵歸因,有助於深入瞭解模型的運作方式。優點如下:
偵錯模型:特徵歸因可協助偵測資料中的問題,而標準模型評估技術通常會遺漏這些問題。
舉例來說,某個影像病理模型在胸部 X 光影像的測試資料集上,獲得了可疑的優異結果。特徵歸因顯示,模型的高準確度取決於放射科醫師在圖片中的筆跡。如要進一步瞭解這個範例,請參閱 AI 解釋白皮書。
最佳化模型:您可以找出並移除較不重要的特徵,進而提高模型效率。
特徵歸因方法
每種特徵歸因方法都以 Shapley 值為基礎,這是一種合作賽局理論演算法,可為遊戲中的每位玩家指派特定結果的功勞。套用至機器學習模型時,這表示每個模型特徵都會被視為遊戲中的「玩家」。Vertex Explainable AI 會根據特定推論的結果,為每項特徵指派相應的額度。
Sampled Shapley 方法
Sampled Shapley 方法可提供確切 Shapley 值的近似取樣。AutoML 表格模型會使用抽樣 Shapley 方法來判斷特徵重要性。這些模型是樹狀結構和類神經網路的元集合,因此很適合使用 Shapley 取樣。
如要深入瞭解取樣夏普利值方法的運作方式,請參閱「Bounding the Estimation Error of Sampling-based Shapley Value Approximation」論文。
積分梯度法
在積分梯度方法中,系統會沿著積分路徑,計算推論輸出內容相對於輸入特徵的梯度。
- 系統會以不同的間隔計算資源調度參數的梯度。 每個間隔的大小是根據高斯求積規則決定。(如果是圖片資料,請將這個縮放參數想像成「滑桿」,可將圖片的所有像素縮放為黑色)。
- 梯度整合方式如下:
- 積分是使用加權平均值估算而得。
- 計算平均梯度與原始輸入的元素乘積。
如要瞭解如何將這項程序套用至圖片,請參閱「Attributing a deep network's inference to its input features」(將深層網路的推論歸因於輸入特徵) 這篇網誌文章。在先前的網誌文章中,整合梯度原始論文 (Axiomatic Attribution for Deep Networks) 的作者,說明瞭在每個步驟中,圖片看起來會如何。
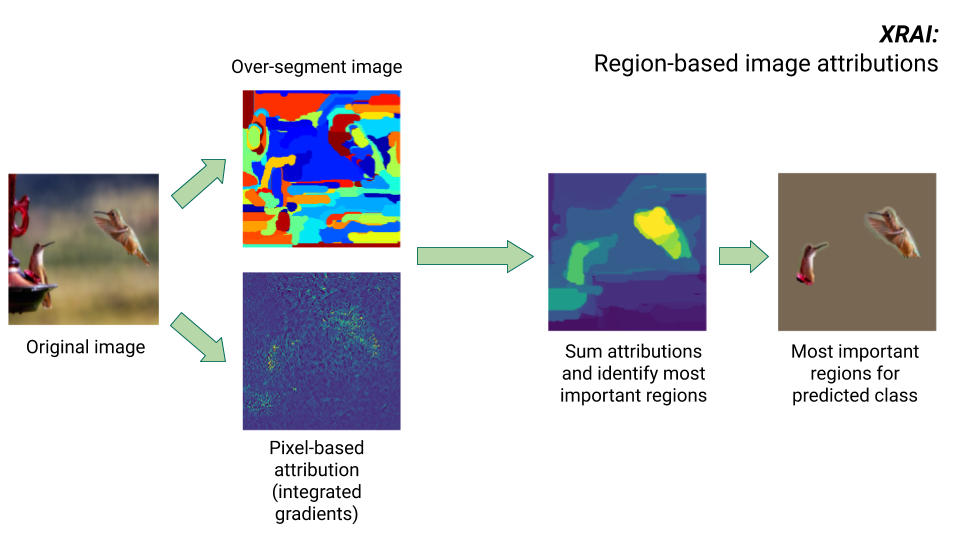
XRAI 方法
XRAI 方法結合了積分梯度法和其他步驟,可判斷圖片中哪些區域對特定類別的推論影響最大。
- 像素層級歸因:XRAI 會對輸入圖片執行像素層級歸因。在這個步驟中,XRAI 會使用積分梯度法,並以黑色和白色做為基準。
- 過度區隔:XRAI 會獨立於像素層級的歸因,過度區隔圖片,建立由小區域組成的拼布。XRAI 會使用 Felzenswalb 的圖表式方法建立圖片區隔。
- 區域選取:XRAI 會彙整每個區隔內的像素層級歸因,以判斷歸因密度。XRAI 會根據這些值為每個區隔排序,然後依正向程度排序區隔。這項資訊會決定圖片中哪些區域最顯眼,或對特定類別推論的影響程度最大。
比較特徵歸因方法
Vertex Explainable AI 提供三種特徵歸因方法:取樣 Shapley、積分梯度和 XRAI。
| 方法 | 基本說明 | 建議模型類型 | 應用實例 | 相容的 Vertex AI Model 資源 |
|---|---|---|---|---|
| Sampled Shapley | 為每項特徵指派結果額度,並考慮不同特徵的排列組合。這個方法會提供確切 Shapley 值的近似取樣。 | 不可微分模型,例如樹狀結構和類神經網路的集合 |
|
|
| 積分梯度 | 以梯度為基礎的方法,可有效計算特徵歸因,並具備與 Shapley 值相同的公理屬性。 | 可微模型,例如類神經網路。特別建議用於特徵空間較大的模型。 建議用於低對比圖片,例如 X 光片。 |
|
|
| XRAI (以排序區域積分解釋) | XRAI 會根據積分梯度法評估影像中重疊的區域,建立顯著性地圖,醒目顯示影像中的相關區域,而非像素。 | 接受圖像輸入內容的模型。特別建議用於自然圖片,也就是含有多個物件的任何現實場景。 |
|
|
如要更全面地比較歸因方法,請參閱 AI 說明白皮書。
可微模型和不可微模型
在可微分模型中,您可以計算 TensorFlow 圖形中所有運算的導數。這個屬性有助於在這些模型中進行反向傳播。舉例來說,類神經網路是可微分的。如要取得可微分模型的特徵歸因,請使用整合梯度法。
積分梯度方法不適用於不可微分模型。 進一步瞭解如何編碼不可微分的輸入內容,以便搭配使用積分梯度法。
不可微分模型在 TensorFlow 圖形中包含不可微分的作業,例如執行解碼和捨入作業的作業。舉例來說,以樹狀結構和類神經網路組合建構的模型不可微分。如要取得不可微分模型的特徵歸因,請使用 Shapley 值取樣方法。取樣夏普利值也適用於可微分模型,但這種情況下,運算成本會高於必要成本。
概念限制
請注意功能歸因的下列限制:
特徵歸因 (包括 AutoML 的本機特徵重要性) 適用於個別推論。檢查個別推論的特徵歸因可提供實用洞察,但這些洞察可能無法套用至該個別例項的整個類別,或整個模型。
如要取得 AutoML 模型更具一般性的洞察資料,請參閱模型特徵重要性。如要取得其他模型的更一般化洞察資料,請匯總資料集子集或整個資料集的歸因。
雖然特徵歸因有助於模型偵錯,但無法清楚指出問題是源自模型,還是模型訓練所用的資料。請運用您的判斷力,診斷常見的資料問題,縮小可能原因的範圍。
特徵歸因與複雜模型中的推論一樣,容易受到類似的對抗性攻擊。
如要進一步瞭解限制,請參閱高階限制清單和 AI 說明白皮書。
參考資料
如為特徵歸因,Sampled Shapley、積分梯度和 XRAI 的實作方式分別依據下列參考資料:
- Bounding the Estimation Error of Sampling-based Shapley Value Approximation
- 深層網路的公理式歸因
- XRAI:透過區域取得更準確的歸因
如要進一步瞭解如何導入 Vertex Explainable AI,請參閱 AI 解釋白皮書。
筆記本
如要開始使用 Vertex Explainable AI,請使用下列筆記本:
| 筆記本 | 可解釋性方法 | ML 架構 | 模態 | 工作 |
|---|---|---|---|---|
| GitHub 連結 | 範例式解釋 | TensorFlow | 圖片 | 訓練分類模型,預測提供的輸入圖片類別,並取得線上說明 |
| GitHub 連結 | 以特徵為準 | AutoML | 表格 | 訓練二元分類模型,預測銀行客戶是否購買定期存款,並取得批次說明 |
| GitHub 連結 | 以特徵為準 | AutoML | 表格 | 訓練分類模型來預測鳶尾花種類,並取得線上說明 |
| GitHub 連結 | 特徵式 (取樣 Shapley) | scikit-learn | 表格 | 訓練線性迴歸模型來預測計程車車資,並取得線上說明 |
| GitHub 連結 | 特徵式 (積分梯度) | TensorFlow | 圖片 | 訓練分類模型,預測提供的輸入圖片類別,並取得批次說明 |
| GitHub 連結 | 特徵式 (積分梯度) | TensorFlow | 圖片 | 訓練分類模型,預測提供的輸入圖片類別,並取得線上說明 |
| GitHub 連結 | 特徵式 (積分梯度) | TensorFlow | 表格 | 訓練迴歸模型來預測房屋中位數價格,並取得批次說明 |
| GitHub 連結 | 特徵式 (積分梯度) | TensorFlow | 表格 | 訓練迴歸模型來預測房屋中位數價格,並取得線上說明 |
| GitHub 連結 | 特徵式 (取樣 Shapley) | TensorFlow | 文字 | 使用評論文字訓練 LSTM 模型,將電影評論分類為正面或負面,並取得線上說明 |
教育資源
下列資源提供更多實用教育資料:
- 適用於從業人員的 Explainable AI
- 可解讀的機器學習:Shapley 值
- Ankur Taly 的 Integrated Gradients GitHub 存放區。
- Shapley 值簡介