Untuk menggunakan penjelasan berbasis contoh, Anda harus mengonfigurasi penjelasan dengan menentukan explanationSpec saat mengimpor atau mengupload Model
ke Model Registry.
Kemudian, saat meminta penjelasan online, Anda dapat mengganti beberapa
nilai konfigurasi tersebut dengan menentukan
ExplanationSpecOverride
dalam permintaan. Anda tidak dapat meminta penjelasan batch; mereka tidak didukung.
Halaman ini menjelaskan cara mengonfigurasi dan memperbarui opsi tersebut.
Mengonfigurasi penjelasan saat mengimpor atau mengupload model
Sebelum memulai, pastikan Anda telah memiliki hal berikut:
Lokasi Cloud Storage yang berisi artefak model Anda. Model Anda tidak harus berupa model deep neural network (DNN) tempat Anda memberikan nama lapisan atau tanda tangan, yang output-nya dapat digunakan sebagai ruang laten, atau Anda dapat menyediakannya model yang secara langsung menghasilkan embedding (representasi ruang laten). Ruang laten ini menangkap contoh representasi yang digunakan untuk menghasilkan penjelasan.
Lokasi Cloud Storage yang berisi instance yang akan diindeks untuk perkiraan penelusuran tetangga terdekat. Untuk mengetahui informasi selengkapnya, lihat persyaratan data input.
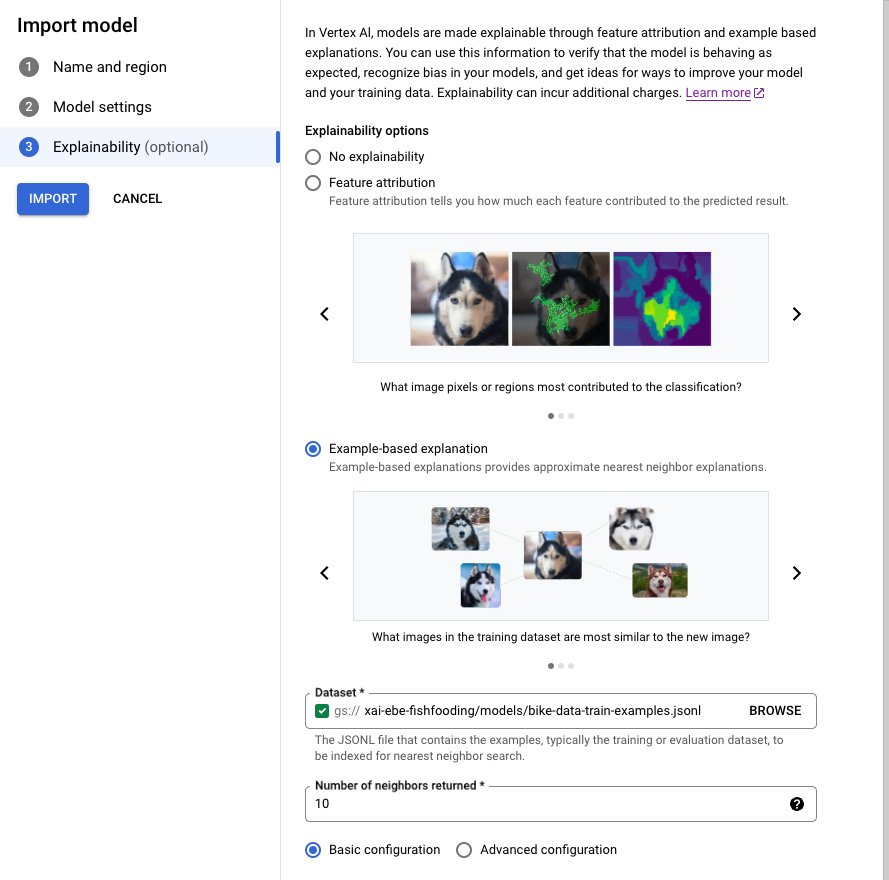
Konsol
Ikuti panduan untuk mengimpor model menggunakan konsol Google Cloud .
Di tab Penjelasan, pilih Penjelasan berbasis contoh dan isi kolom yang tersedia.
Untuk mengetahui informasi tentang setiap kolom, lihat tips di konsol Google Cloud
(ditampilkan di bawah) serta dokumentasi referensi untuk Example dan ExplanationMetadata.
gcloud CLI
- Tulis
ExplanationMetadataberikut ke file JSON di lingkungan lokal Anda. Nama file tidak penting, tetapi untuk contoh ini, panggil fileexplanation-metadata.json:
{
"inputs": {
"my_input": {
"inputTensorName": "INPUT_TENSOR_NAME",
"encoding": "IDENTITY",
},
"id": {
"inputTensorName": "id",
"encoding": "IDENTITY"
}
},
"outputs": {
"embedding": {
"outputTensorName": "OUTPUT_TENSOR_NAME"
}
}
}
- (Opsional) Jika Anda menentukan
NearestNeighborSearchConfiglengkap, tulis hal berikut ke file JSON di lingkungan lokal Anda. Nama file tidak penting, tetapi untuk contoh ini, panggil filesearch_config.json:
{
"contentsDeltaUri": "",
"config": {
"dimensions": 50,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
- Jalankan perintah berikut untuk mengupload
Model.
Jika Anda menggunakan konfigurasi penelusuran Preset, hapus flag --explanation-nearest-neighbor-search-config-file. Jika Anda
menentukan NearestNeighborSearchConfig,
hapus flag --explanation-modality dan --explanation-query.
Tanda yang paling relevan dengan penjelasan berbasis contoh dicetak tebal.
gcloud ai models upload \
--region=LOCATION \
--display-name=MODEL_NAME \
--container-image-uri=IMAGE_URI \
--artifact-uri=MODEL_ARTIFACT_URI \
--explanation-method=examples \
--uris=[URI, ...] \
--explanation-neighbor-count=NEIGHBOR_COUNT \
--explanation-metadata-file=explanation-metadata.json \
--explanation-modality=IMAGE|TEXT|TABULAR \
--explanation-query=PRECISE|FAST \
--explanation-nearest-neighbor-search-config-file=search_config.json
Lihat upload model ai gcloud untuk informasi lebih lanjut.
-
Tindakan upload akan menampilkan
OPERATION_IDyang dapat digunakan untuk memeriksa kapan operasi selesai. Anda dapat melakukan polling untuk status operasi hingga responsnya menyertakan"done": true. Gunakan perintah gcloud ai operations describe untuk mengkueri status, misalnya:gcloud ai operations describe <operation-id>Anda tidak akan dapat meminta penjelasan hingga operasi selesai. Bergantung pada ukuran set data dan arsitektur model, langkah ini dapat memerlukan waktu beberapa jam untuk mem-build indeks yang digunakan untuk membuat kueri untuk contoh.
REST
Sebelum menggunakan salah satu data permintaan, buat pengganti berikut:
- PROJECT
- LOCATION
Untuk mempelajari placeholder lainnya, lihat Model, explanationSpec, dan Examples.
Untuk mempelajari lebih lanjut cara mengupload model, lihat metode upload dan Mengimpor model.
Isi permintaan JSON di bawah menentukan konfigurasi penelusuran Preset. Atau, Anda dapat menentukan NearestNeighborSearchConfig lengkap.
Metode HTTP dan URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models:upload
Meminta isi JSON:
{
"model": {
"displayName": "my-model",
"artifactUri": "gs://your-model-artifact-folder",
"containerSpec": {
"imageUri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-11:latest",
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": ["gs://your-examples-folder"]
},
"neighborCount": 10,
"presets": {
"modality": "image"
}
}
},
"metadata": {
"outputs": {
"embedding": {
"output_tensor_name": "embedding"
}
},
"inputs": {
"my_fancy_input": {
"input_tensor_name": "input_tensor_name",
"encoding": "identity",
"modality": "image"
},
"id": {
"input_tensor_name": "id",
"encoding": "identity"
}
}
}
}
}
}
Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan menerima respons JSON yang mirip dengan berikut ini:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.UploadModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-01-08T01:21:10.147035Z",
"updateTime": "2022-01-08T01:21:10.147035Z"
}
}
}
Tindakan upload akan menampilkan OPERATION_ID yang dapat digunakan untuk memeriksa kapan operasi selesai. Anda dapat melakukan polling untuk status operasi hingga responsnya menyertakan "done": true. Gunakan perintah gcloud ai operations describe untuk mengkueri status, misalnya:
gcloud ai operations describe <operation-id>
Anda tidak akan dapat meminta penjelasan hingga operasi selesai. Bergantung pada ukuran set data dan arsitektur model, langkah ini dapat memerlukan waktu beberapa jam untuk mem-build indeks yang digunakan untuk membuat kueri untuk contoh.
Python
Lihat bagian Mengupload model di notebook penjelasan berbasis contoh klasifikasi gambar.
NearestNeighborSearchConfig
Isi permintaan JSON berikut menunjukkan cara menentukan NearestNeighborSearchConfig lengkap (bukan preset) dalam permintaan upload singkat ini.
{
"model": {
"displayName": displayname,
"artifactUri": model_path_to_deploy,
"containerSpec": {
"imageUri": DEPLOY_IMAGE,
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": [DATASET_PATH]
},
"neighborCount": 5,
"nearest_neighbor_search_config": {
"contentsDeltaUri": "",
"config": {
"dimensions": dimensions,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
}
},
"metadata": { ... }
}
}
}
Tabel ini mencantumkan kolom untuk NearestNeighborSearchConfig.
| Kolom | |
|---|---|
dimensions |
Wajib. Jumlah dimensi vektor input. Hanya digunakan untuk sematan padat. |
approximateNeighborsCount |
Wajib jika algoritma tree-AH digunakan. Jumlah default tetangga yang harus ditemukan melalui perkiraan penelusuran sebelum pengurutan ulang yang sama persis dilakukan. Pengurutan ulang yang sama persis adalah prosedur ketika hasil yang ditampilkan oleh algoritma perkiraan penelusuran diurutkan ulang menggunakan komputasi jarak yang lebih mahal. |
ShardSize |
ShardSize
Ukuran setiap shard. Jika indeks berukuran besar, indeks akan di-shard berdasarkan ukuran shard yang ditentukan. Selama penayangan, setiap shard ditayangkan di node terpisah dan diskalakan secara independen. |
distanceMeasureType |
Ukuran jarak yang digunakan dalam penelusuran tetangga terdekat. |
featureNormType |
Jenis normalisasi yang akan dilakukan pada setiap vektor. |
algorithmConfig |
oneOf:
Konfigurasi untuk algoritma yang digunakan Vector Search untuk penelusuran yang efisien. Hanya digunakan untuk sematan padat.
|
DistanceMeasureType
| Enum | |
|---|---|
SQUARED_L2_DISTANCE |
Jarak Euclidean (L2) |
L1_DISTANCE |
Jarak Manhattan (L1) |
DOT_PRODUCT_DISTANCE |
Nilai default. Didefinisikan sebagai negatif dari perkalian titik. |
COSINE_DISTANCE |
Jarak Kosinus. Sebaiknya gunakan DOT_PRODUCT_DISTANCE + UNIT_L2_NORM, bukan jarak COSINE. Algoritma kami lebih dioptimalkan untuk jarak DOT_PRODUCT, dan saat dikombinasikan dengan UNIT_L2_NORM, algoritma ini menawarkan rank dan kesetaraan matematika yang sama dengan jarak COSINE. |
FeatureNormType
| Enum | |
|---|---|
UNIT_L2_NORM |
Jenis normalisasi unit L2. |
NONE |
Nilai default. Tidak ada jenis normalisasi yang ditetapkan. |
TreeAhConfig
Ini adalah kolom yang harus dipilih untuk algoritme tree-AH (Pohon Shallow + Hashing Asimetris).
| Kolom | |
|---|---|
fractionLeafNodesToSearch |
double |
| Fraksi default node daun tempat kueri apa pun dapat dicari. Harus dalam rentang 0,0 - 1,0, eksklusif. Nilai defaultnya adalah 0,05 jika tidak ditetapkan. | |
leafNodeEmbeddingCount |
int32 |
| Jumlah embedding pada setiap node daun. Nilai defaultnya adalah 1000 jika tidak ditetapkan. | |
leafNodesToSearchPercent |
int32 |
Tidak digunakan lagi, gunakan fractionLeafNodesToSearch.Persentase default node daun tempat kueri apa pun dapat dicari. Harus dalam rentang 1-100, inklusif. Nilai defaultnya adalah 10 (berarti 10%) jika tidak ditetapkan. |
|
BruteForceConfig
Opsi ini mengimplementasikan penelusuran linear standar dalam database untuk
setiap kueri. Tidak ada kolom yang harus dikonfigurasi untuk penelusuran brute force. Untuk memilih algoritma ini, teruskan objek kosong untuk BruteForceConfig ke algorithmConfig.
Persyaratan data input
Upload set data Anda ke lokasi Cloud Storage. Pastikan file dalam format JSON Lines.
File harus dalam format JSON Lines. Contoh berikut berasal dari notebook penjelasan berbasis contoh klasifikasi gambar:
{"id": "0", "bytes_inputs": {"b64": "..."}}
{"id": "1", "bytes_inputs": {"b64": "..."}}
{"id": "2", "bytes_inputs": {"b64": "..."}}
Memperbarui indeks atau konfigurasi
Vertex AI memungkinkan Anda memperbarui indeks tetangga terdekat atau
konfigurasi Example. Ini berguna jika Anda ingin memperbarui model tanpa mengindeks ulang set data-nya. Misalnya, jika indeks model Anda berisi 1.000 instance, dan Anda ingin menambahkan 500 instance lagi, Anda dapat memanggil UpdateExplanationDataset untuk ditambahkan ke indeks tanpa perlu memproses ulang 1.000 instance yang asli.
Untuk memperbarui set data penjelasan:
Python
def update_explanation_dataset(model_id, new_examples):
response = clients["model"].update_explanation_dataset(model=model_id, examples=new_examples)
update_dataset_response = response.result()
return update_dataset_response
PRESET_CONFIG = {
"modality": "TEXT",
"query": "FAST"
}
NEW_DATASET_FILE_PATH = "new_dataset_path"
NUM_NEIGHBORS_TO_RETURN = 10
EXAMPLES = aiplatform.Examples(presets=PRESET_CONFIG,
gcs_source=aiplatform.types.io.GcsSource(uris=[NEW_DATASET_FILE_PATH]),
neighbor_count=NUM_NEIGHBORS_TO_RETURN)
MODEL_ID = 'model_id'
update_dataset_response = update_explanation_dataset(MODEL_ID, EXAMPLES)
Catatan penggunaan:
model_idtidak berubah setelah operasiUpdateExplanationDataset.Operasi
UpdateExplanationDatasethanya memengaruhi resourceModel;DeployedModelyang terkait tidak akan diperbarui. Ini berarti indeksdeployedModelberisi set data pada saat di-deploy. Untuk memperbarui indeksdeployedModel, Anda harus men-deploy ulang model yang telah diupdate ke endpoint.
Mengabaikan konfigurasi saat mendapatkan penjelasan online
Saat meminta penjelasan, Anda dapat mengganti beberapa parameter dengan cepat
dengan menentukan
kolom
ExplanationSpecOverride.
Bergantung pada aplikasinya, beberapa batasan mungkin diinginkan pada jenis penjelasan yang ditampilkan. Misalnya, untuk memastikan keragaman penjelasan, pengguna dapat menentukan parameter crowding yang menyatakan bahwa tidak ada satu jenis contoh pun yang terlalu terwakili dalam penjelasan. Konkritnya, jika pengguna mencoba memahami mengapa seekor burung diberi label sebagai pesawat berdasarkan modelnya, mereka mungkin tidak tertarik untuk melihat terlalu banyak contoh burung sebagai penjelasan untuk menyelidiki akar permasalahannya dengan lebih baik.
Tabel berikut merangkum parameter yang dapat diganti untuk permintaan penjelasan berbasis contoh:
| Nama Properti | Nilai Properti | Deskripsi |
|---|---|---|
| neighborCount | int32 |
Jumlah contoh yang akan ditampilkan sebagai penjelasan |
| crowdingCount | int32 |
Jumlah maksimum contoh untuk ditampilkan dengan crowding tag yang sama |
| izinkan | String Array |
Tag yang diizinkan untuk penjelasan |
| tolak | String Array |
Tag yang tidak diizinkan untuk memiliki penjelasan |
Pemfilteran Penelusuran Vektor menjelaskan parameter ini secara lebih mendetail.
Berikut adalah contoh isi permintaan JSON dengan pengabaian:
{
"instances":[
{
"id": data[0]["id"],
"bytes_inputs": {"b64": bytes},
"restricts": "",
"crowding_tag": ""
}
],
"explanation_spec_override": {
"examples_override": {
"neighbor_count": 5,
"crowding_count": 2,
"restrictions": [
{
"namespace_name": "label",
"allow": ["Papilloma", "Rift_Valley", "TBE", "Influenza", "Ebol"]
}
]
}
}
}
Langkah berikutnya
Berikut adalah contoh respons dari permintaan explain berbasis contoh:
[
{
"neighbors":[
{
"neighborId":"311",
"neighborDistance":383.8
},
{
"neighborId":"286",
"neighborDistance":431.4
}
],
"input":"0"
},
{
"neighbors":[
{
"neighborId":"223",
"neighborDistance":471.6
},
{
"neighborId":"55",
"neighborDistance":392.7
}
],
"input":"1"
}
]
Harga
Lihat bagian penjelasan berbasis contoh di halaman harga.