Pour utiliser des explications basées sur des exemples, vous devez configurer les explications en spécifiant explanationSpec lorsque vous importez la ressource Model dans le registre de modèles.
Ensuite, lorsque vous demandez des explications en ligne, vous pouvez remplacer certaines de ces valeurs de configuration en spécifiant ExplanationSpecOverride dans la requête. Vous ne pouvez pas demander d'explications par lot. Elles ne sont pas compatibles.
Cette page explique comment configurer et mettre à jour ces options.
Configurer les explications lors de l'importation du modèle
Avant de commencer, vérifiez que vous disposez des éléments suivants :
Un emplacement Cloud Storage contenant les artefacts de votre modèle. Votre modèle doit être un modèle de réseau de neurones profond (DNN, Deep Neural Network) dans lequel vous fournissez le nom d'une couche, ou signature, dont vous pouvez utiliser la sortie comme espace latent, ou vous pouvez fournir un modèle qui génère directement des embeddings (représentations d'espace latent). Cet espace latent capture les exemples de représentations qui sont utilisés pour générer les explications.
Un emplacement Cloud Storage contenant les instances à indexer pour la recherche de type plus proches voisins approximatifs. Pour en savoir plus, consultez la section Exigences concernant les données d'entrée.
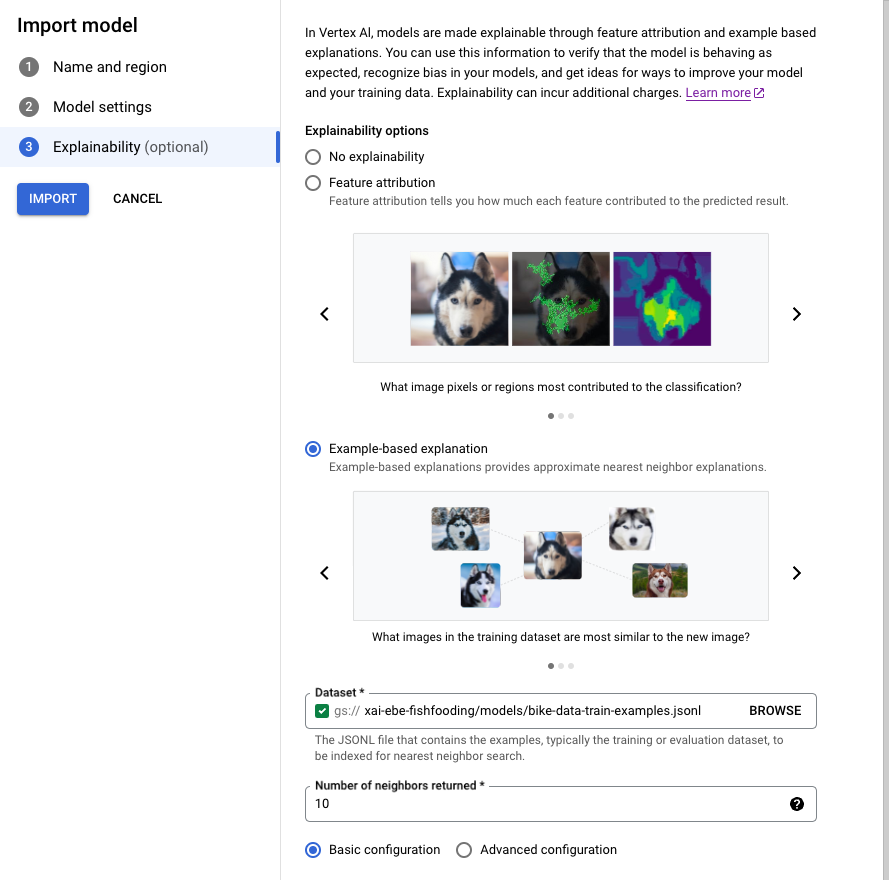
Console
Suivez le guide pour importer un modèle à l'aide de la console Google Cloud.
Dans l'onglet Explainability (Explicabilité), sélectionnez Example-based explanation (Explication basée sur des exemples) et renseignez les champs.
Pour obtenir des informations sur chaque champ, consultez les conseils dans la console Google Cloud (voir ci-dessous), ainsi que la documentation de référence sur Example et ExplanationMetadata.
gcloud CLI
- Écrivez les métadonnées
ExplanationMetadatasuivantes dans un fichier JSON de votre environnement local. Le nom de fichier n'a pas d'importance, mais pour cet exemple, nommez le fichierexplanation-metadata.json.
{
"inputs": {
"my_input": {
"inputTensorName": "INPUT_TENSOR_NAME",
"encoding": "IDENTITY",
},
"id": {
"inputTensorName": "id",
"encoding": "IDENTITY"
}
},
"outputs": {
"embedding": {
"outputTensorName": "OUTPUT_TENSOR_NAME"
}
}
}
- (Facultatif) Si vous spécifiez l'intégralité de
NearestNeighborSearchConfig, écrivez les éléments suivants dans un fichier JSON dans votre environnement local. Le nom de fichier n'a pas d'importance, mais, pour cet exemple, nommez le fichiersearch_config.json:
{
"contentsDeltaUri": "",
"config": {
"dimensions": 50,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
- Exécutez la commande suivante pour importer votre
Model.
Si vous utilisez une configuration de recherche Preset, supprimez l'option --explanation-nearest-neighbor-search-config-file. Si vous spécifiez NearestNeighborSearchConfig, supprimez les options --explanation-modality et --explanation-query.
Les options les plus pertinentes pour les explications basées sur des exemples sont en gras.
gcloud ai models upload \
--region=LOCATION \
--display-name=MODEL_NAME \
--container-image-uri=IMAGE_URI \
--artifact-uri=MODEL_ARTIFACT_URI \
--explanation-method=examples \
--uris=[URI, ...] \
--explanation-neighbor-count=NEIGHBOR_COUNT \
--explanation-metadata-file=explanation-metadata.json \
--explanation-modality=IMAGE|TEXT|TABULAR \
--explanation-query=PRECISE|FAST \
--explanation-nearest-neighbor-search-config-file=search_config.json
Pour plus d'informations, consultez la page gcloud ai models upload.
-
L'action d'importation renvoie un
OPERATION_IDqui permet de vérifier la fin de l'opération. Vous pouvez interroger l'état de l'opération jusqu'à ce que la réponse indique"done": true. Interrogez l'état à l'aide de la commande gcloud ai operations describe, par exemple:gcloud ai operations describe <operation-id>Vous ne pourrez pas demander d'explications tant que l'opération n'est pas terminée. Selon la taille de l'ensemble de données et de l'architecture du modèle, cette étape peut prendre plusieurs heures pour créer l'index utilisé permettant d'interroger des exemples.
REST
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- PROJECT
- LOCATION
Pour en savoir plus sur les autres espaces réservés, consultez les sections Model, explanationSpec et Examples.
Pour en savoir plus sur l'importation de modèles, consultez la méthode upload et la page Importer des modèles.
Le corps de la requête JSON ci-dessous spécifie une configuration de recherche Preset. Vous pouvez également spécifier l'intégralité de NearestNeighborSearchConfig.
Méthode HTTP et URL :
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models:upload
Corps JSON de la requête :
{
"model": {
"displayName": "my-model",
"artifactUri": "gs://your-model-artifact-folder",
"containerSpec": {
"imageUri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-11:latest",
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": ["gs://your-examples-folder"]
},
"neighborCount": 10,
"presets": {
"modality": "image"
}
}
},
"metadata": {
"outputs": {
"embedding": {
"output_tensor_name": "embedding"
}
},
"inputs": {
"my_fancy_input": {
"input_tensor_name": "input_tensor_name",
"encoding": "identity",
"modality": "image"
},
"id": {
"input_tensor_name": "id",
"encoding": "identity"
}
}
}
}
}
}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.UploadModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-01-08T01:21:10.147035Z",
"updateTime": "2022-01-08T01:21:10.147035Z"
}
}
}
L'action d'importation renvoie un OPERATION_ID qui permet de vérifier la fin de l'opération. Vous pouvez interroger l'état de l'opération jusqu'à ce que la réponse indique "done": true. Interrogez l'état à l'aide de la commande gcloud ai operations describe, par exemple:
gcloud ai operations describe <operation-id>
Vous ne pourrez pas demander d'explications tant que l'opération n'est pas terminée. Selon la taille de l'ensemble de données et de l'architecture du modèle, cette étape peut prendre plusieurs heures pour créer l'index utilisé permettant d'interroger des exemples.
Python
Consultez la section Importer le modèle dans le notebook d'explications basées sur des exemples de classification d'images.
NearestNeighborSearchConfig
Le corps de requête JSON suivant montre comment spécifier l'intégralité de NearestNeighborSearchConfig (au lieu de préréglages) dans une requête upload.
{
"model": {
"displayName": displayname,
"artifactUri": model_path_to_deploy,
"containerSpec": {
"imageUri": DEPLOY_IMAGE,
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": [DATASET_PATH]
},
"neighborCount": 5,
"nearest_neighbor_search_config": {
"contentsDeltaUri": "",
"config": {
"dimensions": dimensions,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
}
},
"metadata": { ... }
}
}
}
Les tableaux ci-dessous répertorient les champs pour NearestNeighborSearchConfig.
| Champs | |
|---|---|
dimensions |
Obligatoire. Nombre de dimensions des vecteurs d'entrée. Utilisé uniquement pour les embeddings denses. |
approximateNeighborsCount |
Obligatoire si l'algorithme "tree-AH" est utilisé. Nombre de voisins par défaut à rechercher via la recherche approximative avant la réorganisation exacte. La réorganisation exacte est une procédure dans laquelle les résultats renvoyés par un algorithme de recherche approximatif sont réorganisés à l'aide d'un calcul de distance plus coûteux. |
ShardSize |
ShardSize
Taille de chaque segment. Lorsqu'un index est volumineux, il est segmenté en fonction de la taille de segment spécifiée. Pendant la diffusion, chaque segment est diffusé sur un nœud distinct et évolue indépendamment. |
distanceMeasureType |
Mesure de distance utilisée par la recherche de voisin le plus proche. |
featureNormType |
Type de normalisation à exécuter sur chaque vecteur. |
algorithmConfig |
oneOf:
Configuration des algorithmes utilisés par Vector Search pour une recherche efficace. Utilisés uniquement pour les embeddings denses.
|
DistanceMeasureType
| Enums | |
|---|---|
SQUARED_L2_DISTANCE |
Distance euclidienne (L2) |
L1_DISTANCE |
Distance de Manhattan (L1) |
DOT_PRODUCT_DISTANCE |
Valeur par défaut. Définie comme le négatif du produit scalaire. |
COSINE_DISTANCE |
Distance de cosinus. Nous vous recommandons vivement d'utiliser DOT_PRODUCT_DISTANCE + UNIT_L2_NORM au lieu de la distance COSINE. Nos algorithmes ont été plus optimisés pour la distance DOT_Product et, lorsqu'ils sont associés à UNIT_L2_NORM, offrent le même classement et l'équivalence mathématique que la distance COSINE. |
FeatureNormType
| Enums | |
|---|---|
UNIT_L2_NORM |
Type de normalisation de l'unité L2. |
NONE |
Valeur par défaut. Aucun type de normalisation n'est spécifié. |
TreeAhConfig
Il s'agit des champs à sélectionner pour l'algorithme "tree-AH" (arbre superficiel et hachage asymétrique).
| Champs | |
|---|---|
fractionLeafNodesToSearch |
double |
| Fraction par défaut de nœuds feuilles pouvant être recherchés par n'importe quelle requête. Doit être compris entre 0 et 1 (exclus). Si ce nombre n'est pas défini, la valeur par défaut est 0.05. | |
leafNodeEmbeddingCount |
int32 |
| Nombre de représentations vectorielles continues sur chaque nœud feuille. Si ce nombre n'est pas défini, la valeur par défaut est 1 000. | |
leafNodesToSearchPercent |
int32 |
Obsolète : utilisez fractionLeafNodesToSearch.Pourcentage par défaut de nœuds feuilles pouvant être recherchés par n'importe quelle requête. Doit être compris entre 1 et 100 (inclus). La valeur par défaut est 10 (soit 10 %) si elle n'est pas définie. |
|
BruteForceConfig
Cette option met en œuvre la recherche linéaire standard dans la base de données pour chaque requête. Il n'y a aucun champ à configurer pour une recherche par force brute. Pour sélectionner cet algorithme, transmettez un objet vide pour BruteForceConfig à algorithmConfig.
Exigences concernant les données d'entrée
Importez votre ensemble de données dans un emplacement Cloud Storage. Assurez-vous que les fichiers sont au format JSON Lines.
Les fichiers doivent être au format JSON Lines. L'exemple suivant provient du notebook d'explications basées sur des exemples de classification d'images :
{"id": "0", "bytes_inputs": {"b64": "..."}}
{"id": "1", "bytes_inputs": {"b64": "..."}}
{"id": "2", "bytes_inputs": {"b64": "..."}}
Mettre à jour l'index ou la configuration
Vertex AI vous permet de mettre à jour l'index des plus proches voisins d'un modèle ou la configuration Example. Cette méthode est utile si vous souhaitez mettre à jour votre modèle sans réindexer son ensemble de données. Par exemple, si l'index de votre modèle contient 1 000 instances et que vous souhaitez ajouter 500 instances supplémentaires, vous pouvez appeler UpdateExplanationDataset pour ajouter des instances à l'index sans retraiter les 1 000 instances d'origine.
Pour mettre à jour l'ensemble de données d'explications, procédez comme suit :
Python
def update_explanation_dataset(model_id, new_examples):
response = clients["model"].update_explanation_dataset(model=model_id, examples=new_examples)
update_dataset_response = response.result()
return update_dataset_response
PRESET_CONFIG = {
"modality": "TEXT",
"query": "FAST"
}
NEW_DATASET_FILE_PATH = "new_dataset_path"
NUM_NEIGHBORS_TO_RETURN = 10
EXAMPLES = aiplatform.Examples(presets=PRESET_CONFIG,
gcs_source=aiplatform.types.io.GcsSource(uris=[NEW_DATASET_FILE_PATH]),
neighbor_count=NUM_NEIGHBORS_TO_RETURN)
MODEL_ID = 'model_id'
update_dataset_response = update_explanation_dataset(MODEL_ID, EXAMPLES)
Remarques sur l'utilisation :
model_idreste inchangé après l'opérationUpdateExplanationDataset.L'opération
UpdateExplanationDatasetn'affecte que la ressourceModel. Elle ne met pas à jour lesDeployedModelassociés. Cela signifie que l'index d'undeployedModelcontient l'ensemble de données au moment où il a été déployé. Pour mettre à jour l'index d'undeployedModel, vous devez redéployer sur un point de terminaison le modèle mis à jour.
Remplacer la configuration lors de l'obtention d'explications en ligne
Lorsque vous demandez une explication, vous pouvez remplacer certains paramètres à la volée en spécifiant le champ ExplanationSpecOverride.
Selon l'application, certaines contraintes peuvent être souhaitables quant au type d'explications qui sont renvoyées. Par exemple, pour garantir la diversité des explications, l'utilisateur peut spécifier un paramètre de regroupement, qui indique qu'aucun type d'exemple n'est surreprésenté dans les explications. Concrètement, si un utilisateur tente de comprendre pourquoi un oiseau a été étiqueté en tant qu'avion par son modèle, il pourrait vouloir ne pas consulter trop d'exemples d'oiseaux comme explications pour mieux étudier la cause première.
Le tableau suivant récapitule les paramètres pouvant être remplacés pour une requête d'explications basée sur des exemples :
| Nom de la propriété | Valeur de la propriété | Description |
|---|---|---|
| neighborCount | int32 |
Nombre d'exemples à renvoyer en tant qu'explications |
| crowdingCount | int32 |
Nombre maximal d'exemples à renvoyer avec le même tag de regroupement |
| allow | String Array |
Tags autorisés pour les explications |
| deny | String Array |
Tags non autorisés pour les explications |
La section Filtres de Vector Search décrit ces paramètres plus en détail.
Voici un exemple de corps de requête JSON avec des remplacements :
{
"instances":[
{
"id": data[0]["id"],
"bytes_inputs": {"b64": bytes},
"restricts": "",
"crowding_tag": ""
}
],
"explanation_spec_override": {
"examples_override": {
"neighbor_count": 5,
"crowding_count": 2,
"restrictions": [
{
"namespace_name": "label",
"allow": ["Papilloma", "Rift_Valley", "TBE", "Influenza", "Ebol"]
}
]
}
}
}
Étapes suivantes
Voici un exemple de réponse issue d'une requête explain basée sur un exemple :
[
{
"neighbors":[
{
"neighborId":"311",
"neighborDistance":383.8
},
{
"neighborId":"286",
"neighborDistance":431.4
}
],
"input":"0"
},
{
"neighbors":[
{
"neighborId":"223",
"neighborDistance":471.6
},
{
"neighborId":"55",
"neighborDistance":392.7
}
],
"input":"1"
}
]
Tarifs
Consultez la section sur les explications basées sur des exemples dans la page des tarifs.