Abgeleitete Tabellen bieten eine Vielzahl von erweiterten Analysemöglichkeiten, können aber schwierig zu implementieren und zu beheben sein. Dieses Kochbuch enthält die beliebtesten Anwendungsfälle für abgeleitete Tabellen in Looker.
Auf dieser Seite finden Sie die folgenden Beispiele:
- Tabelle täglich um 3:00 Uhr erstellen
- Neue Daten an eine große Tabelle anhängen
- SQL-Fensterfunktionen verwenden
- Abgeleitete Spalten für berechnete Werte erstellen
- Optimierungsstrategien
- PATs zum Testen von Optimierungen verwenden
UNIONzwei Tabellen- Summe einer Summe bilden (Messwert dimensionalisieren)
- Rollup-Tabellen mit aggregierter Bekanntheit
Ressourcen für abgeleitete Tabellen
In diesen Anleitungen wird davon ausgegangen, dass Sie ein grundlegendes Verständnis von LookML und abgeleiteten Tabellen haben. Sie sollten Ansichten erstellen und die Modelldatei bearbeiten können. Wenn Sie Ihr Wissen zu einem dieser Themen auffrischen möchten, sehen Sie sich die folgenden Ressourcen an:
- Abgeleitete Tabellen
- LookML – Begriffe und Konzepte
- Native abgeleitete Tabellen erstellen
derived_table-Parameterreferenz- Abfragen im Cache speichern und PDTs mit Datengruppen neu erstellen
Täglich um 3 Uhr eine Tabelle erstellen
In diesem Beispiel werden die Daten jeden Tag um 2:00 Uhr empfangen. Die Ergebnisse einer Abfrage für diese Daten sind unabhängig davon, ob sie um 3 Uhr oder um 21 Uhr ausgeführt wird. Daher ist es sinnvoll, die Tabelle einmal täglich zu erstellen und Nutzern zu erlauben, Ergebnisse aus einem Cache abzurufen.
Wenn Sie Ihre Datengruppe in die Modelldatei einfügen, können Sie sie für mehrere Tabellen und Explores wiederverwenden. Diese Datengruppe enthält einen sql_trigger_value-Parameter, der angibt, wann die Datengruppe ausgelöst und die abgeleitete Tabelle neu erstellt werden soll.
Weitere Beispiele für Triggerausdrücke finden Sie in der Dokumentation zu sql_trigger_value.
## in the model file
datagroup: standard_data_load {
sql_trigger_value: SELECT FLOOR(((TIMESTAMP_DIFF(CURRENT_TIMESTAMP(),'1970-01-01 00:00:00',SECOND)) - 60*60*3)/(60*60*24)) ;;
max_cache_age: "24 hours"
}
explore: orders {
…
Fügen Sie der derived_table-Definition in der Ansichtsdatei den Parameter datagroup_trigger hinzu und geben Sie den Namen der Datengruppe an, die Sie verwenden möchten. In diesem Beispiel ist die Datengruppe standard_data_load.
view: orders {
derived_table: {
indexes: ["id"]
datagroup_trigger: standard_data_load
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
…
}
Neue Daten an eine große Tabelle anhängen
Eine inkrementelle PDT ist eine persistente abgeleitete Tabelle, die von Looker aufgebaut wird. Dabei werden neue Daten an die Tabelle angehängt, anstatt dass die ganze Tabelle neu erstellt wird.
Das nächste Beispiel baut auf dem Beispiel für die Tabelle orders auf und zeigt, wie die Tabelle inkrementell erstellt wird. Täglich werden neue Bestelldaten empfangen, die an die vorhandene Tabelle angehängt werden können, wenn Sie einen increment_key-Parameter und einen increment_offset-Parameter hinzufügen.
view: orders {
derived_table: {
indexes: ["id"]
increment_key: "created_at"
increment_offset: 3
datagroup_trigger: standard_data_load
distribution_style: all
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;; }
…
}
Der Wert increment_key ist auf created_at festgelegt. Das ist das Zeitinkrement, für das in diesem Beispiel neue Daten abgefragt und an die PDT angehängt werden sollen.
Der Wert increment_offset wird auf 3 festgelegt, um die Anzahl der vorherigen Zeiträume (in der Granularität des Inkrementschlüssels) anzugeben, die neu erstellt werden, um spät eintreffende Daten zu berücksichtigen.
SQL-Fensterfunktionen verwenden
Einige Datenbankdialekte unterstützen Fensterfunktionen, insbesondere zum Erstellen von Sequenznummern, Primärschlüsseln, laufenden und kumulativen Summen sowie anderen nützlichen Berechnungen über mehrere Zeilen hinweg. Nach Ausführung der primären Abfrage werden alle derived_column-Deklarationen gesondert ausgeführt.
Sofern Ihr Datenbankdialekt Fensterfunktionen unterstützt, können Sie diese in Ihrer nativen abgeleiteten Tabelle nutzen. Erstellen Sie einen derived_column-Parameter mit einem sql-Parameter, der Ihre Fensterfunktion enthält. Beim Verweisen auf Werte sollten Sie den Spaltennamen verwenden, der in Ihrer nativen abgeleiteten Tabelle definiert wurde.
Im folgenden Beispiel wird gezeigt, wie Sie eine native abgeleitete Tabelle erstellen, die die Spalten user_id, order_id und created_time enthält. Anschließend würden Sie anhand einer abgeleiteten Spalte mit einer SQL ROW_NUMBER()-Fensterfunktion eine Spalte berechnen, die die Sequenznummer eines Kundenauftrags enthält.
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
Abgeleitete Spalten für berechnete Werte erstellen
Sie können derived_column-Parameter hinzufügen, um Spalten anzugeben, die nicht im Explore des Parameters explore_source vorhanden sind. Jeder derived_column-Parameter hat einen sql-Parameter, der angibt, wie der Wert erstellt wird.
Für die Berechnung von sql können alle Spalten verwendet werden, die Sie mit column-Parametern angegeben haben. Abgeleitete Spalten können zwar keine Summenfunktionen enthalten, aber Berechnungen, die an einer einzelnen Tabellenzeile durchgeführt werden können.
In diesem Beispiel wird die Spalte average_customer_order erstellt, die aus den Spalten lifetime_customer_value und lifetime_number_of_orders in der nativen abgeleiteten Tabelle berechnet wird.
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: users.id
}
column: lifetime_number_of_orders {
field: order_items.count
}
column: lifetime_customer_value {
field: order_items.total_profit
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
Optimierungsstrategien
Da PDTs in Ihrer Datenbank gespeichert werden, sollten Sie die PDTs mit den folgenden Strategien optimieren, je nach Unterstützung durch Ihren Dialekt:
Wenn Sie beispielsweise Persistenz hinzufügen möchten, können Sie die PDT so einstellen, dass sie neu erstellt wird, wenn die Datengruppe orders_datagroup ausgelöst wird. Anschließend können Sie sowohl für customer_id als auch für first_order Indexe hinzufügen, wie unten dargestellt:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
Wenn Sie keinen Index (oder eine Entsprechung für Ihren Dialekt) hinzufügen, werden Sie von Looker gewarnt, dass Sie dies zur Steigerung der Abfrageleistung nachholen sollten.
PDTs zum Testen von Optimierungen verwenden
Mit temporären abgeleiteten Tabellen können Sie verschiedene Indexierungs-, Verteilungs- und andere Optimierungsoptionen testen, ohne dass Sie viel Unterstützung von Ihrem Datenbankadministrator oder ETL-Entwicklern benötigen.
Angenommen, Sie haben eine Tabelle, möchten aber verschiedene Indexe testen. Ihr ursprüngliches LookML für die Ansicht könnte so aussehen:
view: customer {
sql_table_name: warehouse.customer ;;
}
Wenn Sie Optimierungsstrategien testen möchten, können Sie mit dem Parameter indexes der LookML Indexe hinzufügen, wie im Folgenden gezeigt:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Fragen Sie die Ansicht einmal ab, um die PDT zu generieren. Führen Sie dann Ihre Testabfragen aus und vergleichen Sie die Ergebnisse. Wenn die Ergebnisse positiv sind, können Sie Ihr DBA- oder ETL-Team bitten, die Indexe der Originaltabelle hinzuzufügen.
UNION zwei Tabellen
Sie können in beiden abgeleiteten Tabellen einen SQL-UNION- oder UNION ALL-Operator ausführen, sofern Ihr SQL-Dialekt dies unterstützt. Die Operatoren UNION und UNION ALL kombinieren die Ergebnismengen von zwei Abfragen.
In diesem Beispiel sehen Sie, wie eine SQL-basierte abgeleitete Tabelle mit einem UNION aussieht:
view: first_and_second_quarter_sales {
derived_table: {
sql:
SELECT * AS sales_records
FROM sales_records_first_quarter
UNION
SELECT * AS sales_records
FROM sales_records_second_quarter ;;
}
}
Mit der Anweisung UNION im Parameter sql wird eine abgeleitete Tabelle erstellt, in der die Ergebnisse beider Abfragen kombiniert werden.
Der Unterschied zwischen UNION und UNION ALL besteht darin, dass bei UNION ALL keine doppelten Zeilen entfernt werden. Bei der Verwendung von UNION im Vergleich zu UNION ALL sind Leistungsaspekte zu berücksichtigen, da der Datenbankserver zusätzliche Arbeit leisten muss, um die doppelten Zeilen zu entfernen.
Summe einer Summe bilden (Messwert dimensionalisieren)
In SQL und damit auch in Looker gilt die allgemeine Regel, dass Sie eine Abfrage nicht nach den Ergebnissen einer Aggregatfunktion (in Looker als Messwerte dargestellt) gruppieren können. Sie können nur nach nicht aggregierten Feldern gruppieren, die in Looker als Dimensionen dargestellt werden.
Wenn Sie nach einem Aggregat gruppieren möchten, z. B. um die Summe einer Summe zu berechnen, müssen Sie einen Messwert „dimensionalisieren“. Eine Möglichkeit dafür ist die Verwendung einer abgeleiteten Tabelle, mit der effektiv eine Unterabfrage der Aggregation erstellt wird.
Ausgehend von einem Explore kann Looker LookML für die gesamte abgeleitete Tabelle oder einen großen Teil davon generieren. Erstellen Sie einfach ein Explore und wählen Sie alle Felder aus, die in der abgeleiteten Tabelle enthalten sein sollen. So generieren Sie den LookML-Code für die native (oder SQL-basierte) abgeleitete Tabelle:
Klicken Sie auf das Zahnradmenü des Explores und wählen Sie LookML abrufen aus.
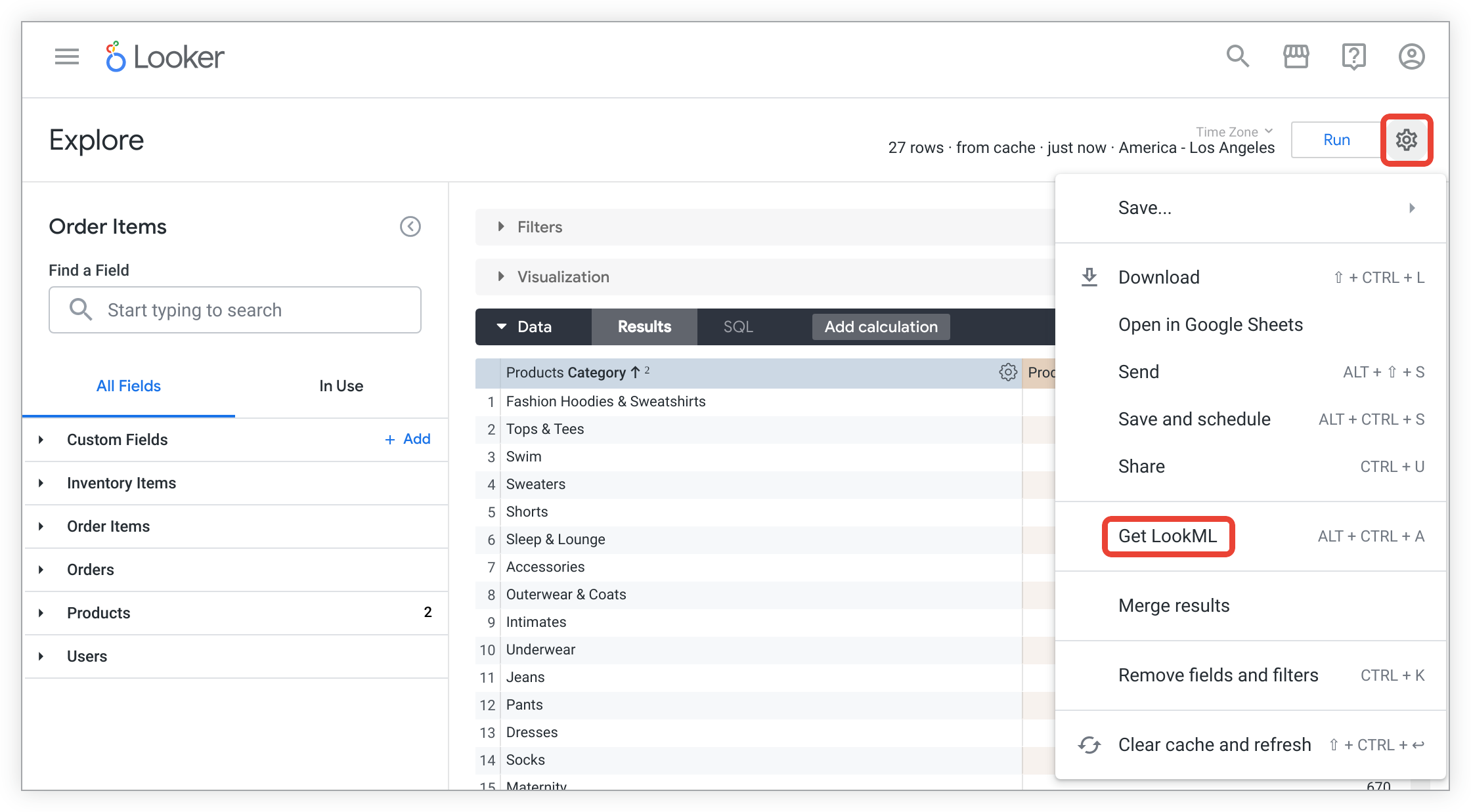
Klicken Sie auf den Tab Abgeleitete Tabelle, um die LookML zum Erstellen einer nativen abgeleiteten Tabelle für das Explore aufzurufen.
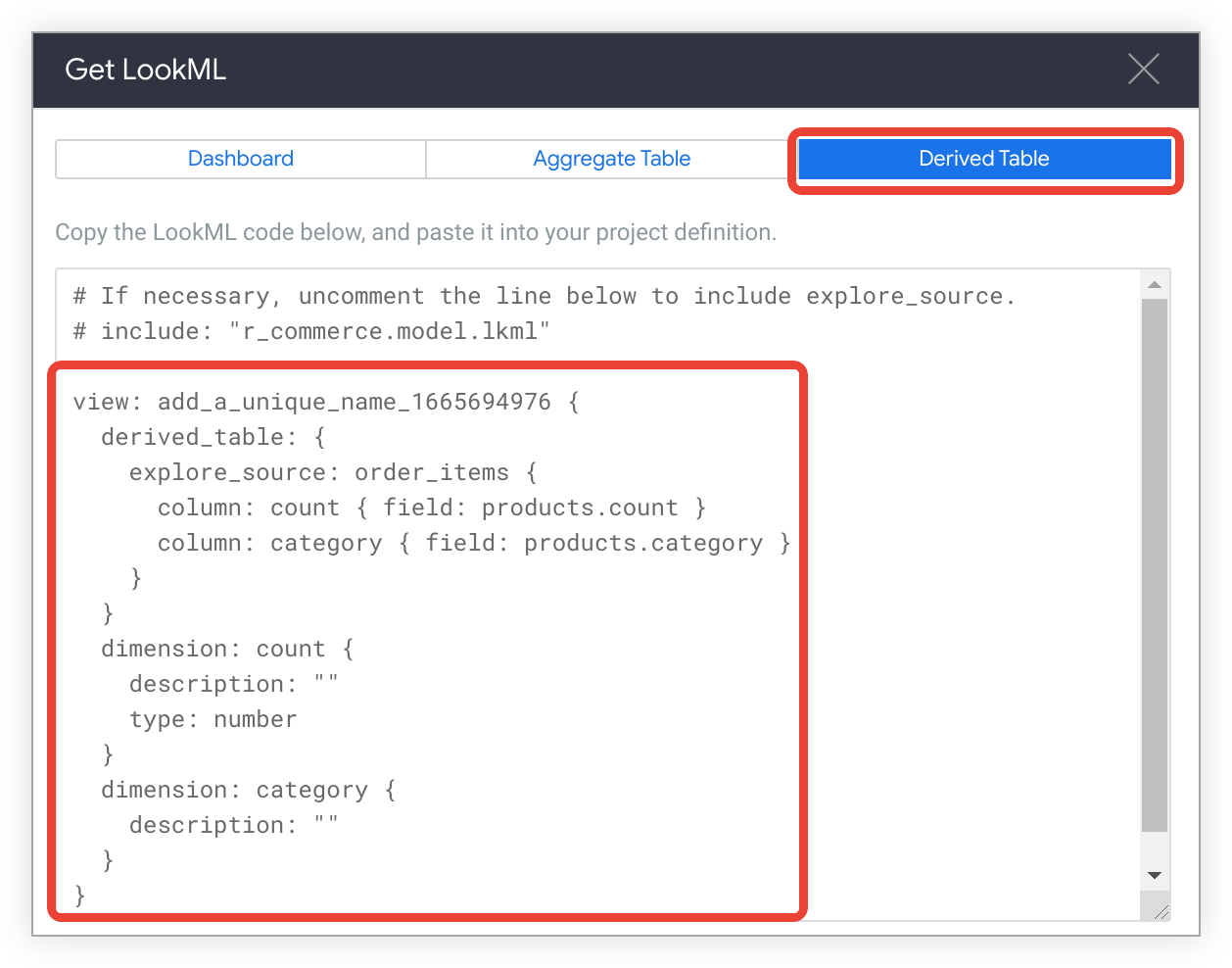
Kopieren Sie den LookML-Code.
Fügen Sie den kopierten LookML-Code in eine Ansichtsdatei ein:
Rufen Sie im Entwicklungsmodus Ihre Projektdateien auf.
Klicken Sie oben in der Projektdateiliste in der Looker-IDE auf das Pluszeichen + und wählen Sie Ansicht erstellen aus. Alternativ können Sie die Datei im Ordner erstellen, indem Sie auf das Menü eines Ordners klicken und Ansicht erstellen auswählen.
Geben Sie der Ansicht einen aussagekräftigen Namen.
Optional können Sie Spaltennamen ändern, abgeleitete Spalten festlegen und Filter hinzufügen.
Rollup-Tabellen mit Aggregatfunktion
In Looker werden Sie häufig auf sehr große Datasets oder Tabellen stoßen, für die zur Leistungssteigerung Aggregationstabellen oder Roll-ups erforderlich sind.
Mit der Funktion „Aggregate Awareness“ von Looker können Sie aggregierte Tabellen mit verschiedenen Granularitäts-, Dimensionalitäts- und Aggregationsstufen vorab erstellen und Looker mitteilen, wie sie in vorhandenen Explores verwendet werden sollen. Abfragen verwenden diese Rollup-Tabellen dann, wenn Looker dies für angemessen hält, ohne dass der Nutzer etwas tun muss. Dadurch wird die Abfragegröße verringert, die Wartezeiten werden verkürzt und die Nutzerfreundlichkeit wird verbessert.
Im Folgenden sehen Sie eine sehr einfache Implementierung in einem Looker-Modell, um zu veranschaulichen, wie einfach die Aggregat-Awareness sein kann. Angenommen, Sie haben eine hypothetische Tabelle „flights“ (Flüge) in der Datenbank mit einer Zeile für jeden Flug, der von der FAA aufgezeichnet wird. Sie können diese Tabelle in Looker mit einer eigenen Ansicht und einem eigenen Explore modellieren. Unten sehen Sie die LookML für eine aggregierte Tabelle, die Sie für den Explore definieren können:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Mit dieser Aggregat-Tabelle kann ein Nutzer das flights-Explore abfragen und Looker verwendet automatisch die Aggregat-Tabelle, um Abfragen zu beantworten. Eine detailliertere Anleitung finden Sie im Tutorial zu Aggregate Awareness.