이 페이지에서는 Google Kubernetes Engine(GKE) 워크로드 및 기본 클러스터 노드의 시작 지연 시간을 모니터링하는 데 사용할 수 있는 측정항목과 대시보드를 설명합니다. 측정항목을 사용하여 시작 지연 시간을 추적하고, 문제를 해결하고 줄일 수 있습니다.
이 페이지는 워크로드의 시작 지연 시간을 모니터링하고 최적화해야 하는 플랫폼 관리자 및 운영자를 대상으로 합니다. Google Cloud 콘텐츠에서 참조하는 일반적인 역할에 대한 자세한 내용은 일반 GKE 사용자 역할 및 태스크를 참조하세요.
개요
시작 지연 시간은 애플리케이션이 트래픽 급증에 응답하는 방식, 복제본이 중단에서 복구되는 속도, 클러스터 및 워크로드의 운영 비용 효율성에 큰 영향을 미칩니다. 워크로드의 시작 지연 시간을 모니터링하면 지연 시간 악화를 감지하고 워크로드 및 인프라 업데이트가 시작 지연 시간에 미치는 영향을 추적할 수 있습니다.
워크로드 시작 지연 시간을 최적화하면 다음과 같은 이점이 있습니다.
- 트래픽 급증 시 사용자에게 서비스의 응답 지연 시간을 줄입니다.
- 새 복제본이 생성되는 동안 수요 급증을 흡수하는 데 필요한 추가 제공 용량을 줄입니다.
- 일괄 컴퓨팅 중에 이미 배포되었고 나머지 리소스가 시작되기를 기다리는 리소스의 유휴 시간을 줄입니다.
시작하기 전에
시작하기 전에 다음 태스크를 수행했는지 확인합니다.
- Google Kubernetes Engine API를 사용 설정합니다. Google Kubernetes Engine API 사용 설정
- 이 태스크에 Google Cloud CLI를 사용하려면 gcloud CLI를 설치한 후 초기화합니다. 이전에 gcloud CLI를 설치한 경우
gcloud components update명령어를 실행하여 최신 버전을 가져옵니다. 이전 gcloud CLI 버전에서는 이 문서의 명령어를 실행하지 못할 수 있습니다.
Cloud Logging 및 Cloud Monitoring API를 사용 설정합니다.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
요구사항
워크로드의 시작 지연 시간 측정항목과 대시보드를 보려면 GKE 클러스터가 다음 요구사항을 충족해야 합니다.
- GKE 버전 1.31.1-gke.1678000 이상이 있어야 합니다.
- 시스템 측정항목 수집을 구성해야 합니다.
- 시스템 로그 수집을 구성해야 합니다.
- 클러스터에서
POD구성요소로 Kubernetes 상태 측정항목을 사용 설정하여 포드 및 컨테이너 측정항목을 확인합니다.
필수 역할 및 권한
로그 생성을 사용 설정하고 로그에 액세스하여 처리하는 데 필요한 권한을 얻으려면 관리자에게 다음 IAM 역할을 부여해 달라고 요청하세요.
-
GKE 클러스터, 노드, 워크로드 보기:
프로젝트에 대한 Kubernetes Engine 뷰어(
roles/container.viewer) -
시작 지연 시간 측정항목에 액세스하고 대시보드 보기: 프로젝트에 대한 모니터링 뷰어(
roles/monitoring.viewer) -
지연 시간 정보가 포함된 로그(예: Kubelet 이미지 가져오기 이벤트)에 액세스하고 로그 탐색기 및 로그 애널리틱스에서 보기: 프로젝트에 대한 로그 뷰어(
roles/logging.viewer)
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
커스텀 역할이나 다른 사전 정의된 역할을 통해 필요한 권한을 얻을 수도 있습니다.
시작 지연 시간 측정항목
시작 지연 시간 측정항목은 GKE 시스템 측정항목에 포함되며 GKE 클러스터와 동일한 프로젝트의 Cloud Monitoring으로 내보내집니다.
이 테이블의 Cloud Monitoring 측정항목 이름에는 kubernetes.io/ 프리픽스를 붙여야 합니다. 테이블의 항목에서는 이 프리픽스가 생략되었습니다.
| 측정항목 유형(리소스 계층 구조 수준) 표시 이름 |
|
|---|---|
|
종류, 유형, 단위 모니터링 리소스 |
설명 라벨 |
pod/latencies/pod_first_ready
(프로젝트)
포드 첫 준비 지연 시간 |
|
GAUGE, Double, s
k8s_pod |
이미지 가져오기를 포함한 포드의 엔드 투 엔드 시작 지연 시간입니다(포드 Created~Ready). 60초마다 샘플링됩니다. |
node/latencies/startup
(프로젝트)
노드 시작 지연 시간 |
|
GAUGE, INT64, s
k8s_node |
GCE 인스턴스의 CreationTimestamp부터 처음 Kubernetes node ready까지의 노드 총 시작 지연 시간입니다. 60초마다 샘플링됩니다.accelerator_family: 하드웨어 가속기(gpu, tpu, cpu)에 기반한 노드 분류입니다.
kube_control_plane_available: KCP(kube 컨트롤 플레인)를 사용할 수 있을 때 노드 생성 요청이 수신되었는지 여부입니다.
|
autoscaler/latencies/per_hpa_recommendation_scale_latency_seconds
(프로젝트)
HPA 추천별 확장 지연 시간 |
|
GAUGE, DOUBLE, s
k8s_scale |
HPA 타겟의 수평형 포드 자동 확장 처리(HPA) 확장 추천 지연 시간(측정항목이 생성되는 시점과 해당 확장 추천이 apiserver에 적용되는 시점 사이의 시간)입니다. 60초마다 샘플링됩니다. 샘플링되면 데이터는 최대 20초 동안 표시되지 않습니다.metric_type: 측정항목 소스의 유형입니다. "ContainerResource", "External", "Object", "Pods", "Resource" 중 하나여야 합니다.
|
워크로드의 시작 지연 시간 대시보드 보기
워크로드의 시작 지연 시간 대시보드는 배포에만 사용할 수 있습니다. 배포의 시작 지연 시간 측정항목을 보려면 Google Cloud 콘솔에서 다음 단계를 수행하세요.
워크로드 페이지로 이동합니다.
배포 세부정보 뷰를 열려면 검사할 워크로드의 이름을 클릭합니다.
관측 가능성 탭을 클릭합니다.
왼쪽 메뉴에서 시작 지연 시간을 선택합니다.
포드의 시작 지연 시간 분포 보기
포드의 시작 지연 시간은 이미지 가져오기를 포함한 총 시작 지연 시간을 나타내며, 포드의 Created 상태부터 Ready 상태까지의 시간을 측정합니다. 다음 두 차트를 사용하여 포드의 시작 지연 시간을 평가할 수 있습니다.
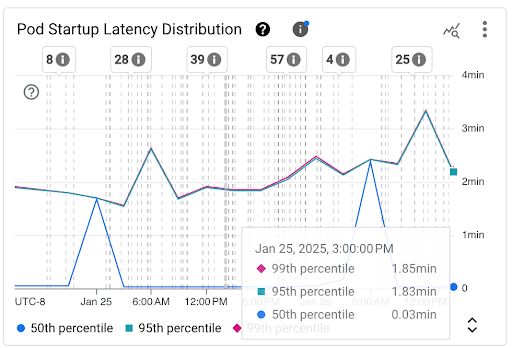
포드 시작 지연 시간 분포 차트: 이 차트는 고정된 3시간 간격(예: 오전 12시~오전 3시, 오전 3시~오전 6시) 동안 포드 시작 이벤트 관찰을 기반으로 계산된 포드의 시작 지연 시간 백분위수(50번째 백분위수, 95번째 백분위수, 99번째 백분위수)를 보여줍니다. 이 차트는 다음 용도로 사용할 수 있습니다.
- 기준 포드 시작 지연 시간을 파악합니다.
- 시간 경과에 따른 포드 시작 지연 시간의 변동을 식별합니다.
- 포드 시작 지연 시간의 변화를 워크로드 배포 또는 클러스터 자동 확장 처리 이벤트와 같은 최근 이벤트와 연관시킵니다. 대시보드 상단의 주석 목록에서 이벤트를 선택할 수 있습니다.
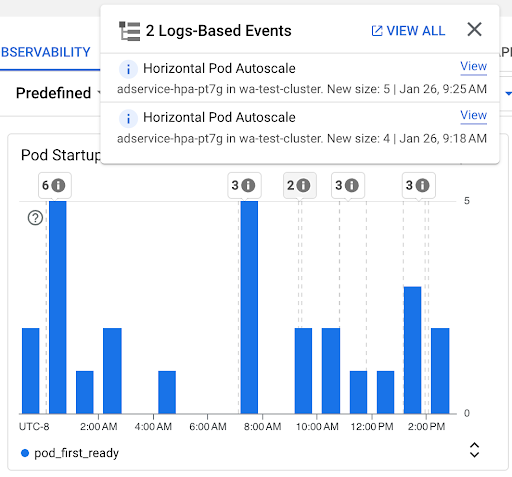
포드 시작 수 차트: 이 차트는 선택한 시간 간격 동안 시작된 포드의 수를 보여줍니다. 이 차트는 다음 용도로 사용할 수 있습니다.
- 특정 시간 간격의 포드 시작 지연 시간 분포 백분위수를 계산하는 데 사용되는 포드 샘플 크기를 이해합니다.
- 워크로드 배포 또는 수평형 포드 자동 확장 처리 이벤트와 같은 포드 시작의 원인을 파악합니다. 대시보드 상단의 주석 목록에서 이벤트를 선택할 수 있습니다.
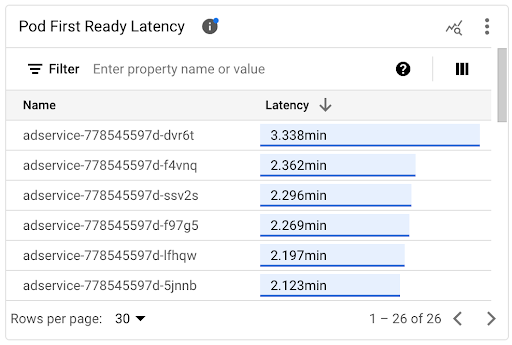
개별 포드의 시작 지연 시간 보기
포드 첫 번째 준비 지연 시간 타임라인 차트와 연결된 목록에서 개별 포드의 시작 지연 시간을 확인할 수 있습니다.
- 포드 첫 번째 준비 지연 시간 타임라인 차트를 사용하여 개별 포드 시작을 수평형 포드 자동 확장 처리 또는 클러스터 자동 확장 처리 이벤트와 같은 최근 이벤트와 연관시킵니다. 대시보드 상단의 주석 목록에서 이러한 이벤트를 선택할 수 있습니다. 이 차트는 다른 포드와 비교하여 시작 지연 시간의 변경사항에 대한 잠재적 원인을 파악하는 데 도움이 됩니다.
- 포드 첫 번째 준비 지연 시간 목록을 사용하여 시작하는 데 걸린 시간이 가장 길거나 짧은 개별 포드를 식별합니다. 지연 시간 열을 기준으로 목록을 정렬할 수 있습니다. 시작 지연 시간이 가장 긴 포드를 식별하면 포드 시작 이벤트를 다른 최근 이벤트와 연관시켜 지연 시간 악화 문제를 해결할 수 있습니다.
개별 포드가 생성된 시점은 해당 포드 생성 이벤트의 timestamp 필드 값을 확인하면 알 수 있습니다. timestamp 필드를 확인하려면 로그 탐색기에서 다음 쿼리를 실행하세요.
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.pods.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.namespace=NAMESPACE AND
protoPayload.response.metadata.name=POD_NAME
워크로드의 모든 포드 생성 이벤트를 나열하려면 이전 쿼리에서 다음 필터를 사용하세요.
protoPayload.response.metadata.name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
개별 포드의 지연 시간을 비교하면 다양한 구성이 포드 시작 지연 시간에 미치는 영향을 테스트하고 요구사항에 따라 최적의 구성을 식별할 수 있습니다.
포드 예약 지연 시간 확인
포드 예약 지연 시간은 포드가 생성된 시점과 포드가 노드에 예약된 시점 사이의 시간입니다. 포드 예약 지연 시간은 포드의 엔드 투 엔드 시작 시간에 영향을 미치며, 포드 예약 이벤트와 포드 생성 요청의 타임스탬프를 빼서 계산됩니다.
해당 포드 예약 이벤트의 jsonPayload.eventTime 필드에서 개별 포드 예약 이벤트의 타임스탬프를 확인할 수 있습니다. jsonPayload.eventTime 필드를 확인하려면 로그 탐색기에서 다음 쿼리를 실행하세요.
log_id("events")
jsonPayload.reason="Scheduled"
resource.type="k8s_pod"
resource.labels.project_id=PROJECT_ID
resource.labels.location=CLUSTER_LOCATION
resource.labels.cluster_name=CLUSTER_NAME
resource.labels.namespace_name=NAMESPACE
resource.labels.pod_name=POD_NAME
워크로드의 모든 포드 예약 이벤트를 나열하려면 이전 쿼리에서 다음 필터를 사용하세요.
resource.labels.pod_name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
이미지 가져오기 지연 시간 보기
컨테이너 이미지 가져오기 지연 시간은 이미지가 아직 노드에서 제공되지 않거나 이미지를 새로고침해야 하는 시나리오에서 포드 시작 지연 시간에 영향을 미칩니다. 이미지 가져오기 지연 시간을 최적화하면 클러스터 수평 확장 이벤트 중에 워크로드 시작 지연 시간이 줄어듭니다.
Kubelet 이미지 가져오기 이벤트 테이블을 확인하여 워크로드 컨테이너 이미지가 가져온 시간과 프로세스에 걸린 시간을 확인할 수 있습니다.
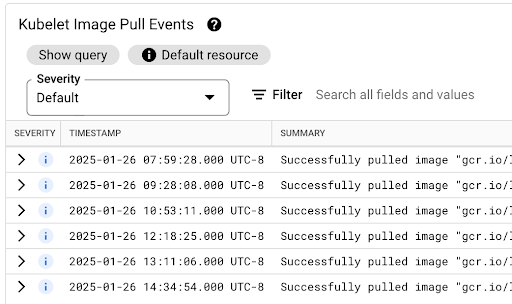
이미지 가져오기 지연 시간은 다음과 같은 메시지가 포함된 jsonPayload.message 필드에서 확인할 수 있습니다.
"Successfully pulled image "gcr.io/example-project/image-name" in 17.093s (33.051s including waiting). Image size: 206980012 bytes."
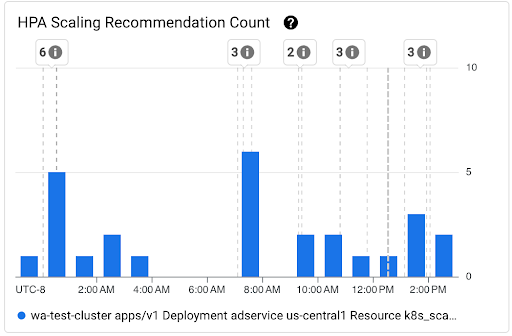
HPA 확장 추천의 지연 시간 분포 보기
HPA 타겟의 수평형 포드 자동 확장 처리(HPA) 확장 추천의 지연 시간은 측정항목이 생성되는 시점과 해당 확장 추천이 API 서버에 적용되는 시점 사이의 시간입니다. HPA 확장 추천 지연 시간을 최적화하면 수평 확장 이벤트 중에 워크로드 시작 지연 시간이 줄어듭니다.
HPA 확장은 다음 두 차트에서 확인할 수 있습니다.
HPA 확장 추천 지연 시간 분포 차트: 이 차트는 지난 3시간 동안의 HPA 확장 추천 관찰을 기반으로 계산된 HPA 확장 추천 지연 시간의 백분위수(50번째 백분위수, 95번째 백분위수, 99번째 백분위수)를 보여줍니다. 이 차트는 다음 용도로 사용할 수 있습니다.
- 기준 HPA 확장 추천 지연 시간을 파악합니다.
- 시간 경과에 따른 HPA 확장 추천 지연 시간의 변동을 식별합니다.
- HPA 확장 추천 지연 시간의 변화와 최근 이벤트를 연관시킵니다. 대시보드 상단의 주석 목록에서 이벤트를 선택할 수 있습니다.

HPA 확장 추천 수 차트: 이 차트는 선택한 시간 간격 동안 관찰된 HPA 확장 추천 수를 보여줍니다. 다음 태스크에 차트를 사용하세요.
- HPA 확장 추천 샘플 크기를 이해합니다. 샘플은 특정 시간 간격의 HPA 확장 추천 지연 시간 분포에서 백분위수를 계산하는 데 사용됩니다.
- HPA 확장 추천을 새 포드 시작 이벤트 및 수평형 포드 자동 확장 처리 이벤트와 연관시킵니다. 대시보드 상단의 주석 목록에서 이벤트를 선택할 수 있습니다.
포드의 예약 문제 보기
포드 예약 문제는 워크로드의 엔드 투 엔드 시작 지연 시간에 영향을 미칠 수 있습니다. 워크로드의 엔드 투 엔드 시작 지연 시간을 줄이려면 이러한 문제의 수를 해결하고 줄이세요.
이러한 문제를 추적하는 데 사용할 수 있는 두 가지 차트는 다음과 같습니다.
- 예약할 수 없음/대기 중/실패한 포드 차트에는 시간 경과에 따른 예약할 수 없음, 대기 중, 실패한 포드의 수가 표시됩니다.
- 백오프/대기 중/준비 실패 컨테이너 차트에는 시간 경과에 따른 해당 상태의 컨테이너 수가 표시됩니다.
노드의 시작 지연 시간 대시보드 보기
노드의 시작 지연 시간 측정항목을 보려면Google Cloud 콘솔에서 다음 단계를 수행합니다.
Kubernetes 클러스터 페이지로 이동합니다.
클러스터 세부정보 뷰를 열려면 검사할 클러스터의 이름을 클릭합니다.
관측 가능성 탭을 클릭합니다.
왼쪽 메뉴에서 시작 지연 시간을 선택합니다.
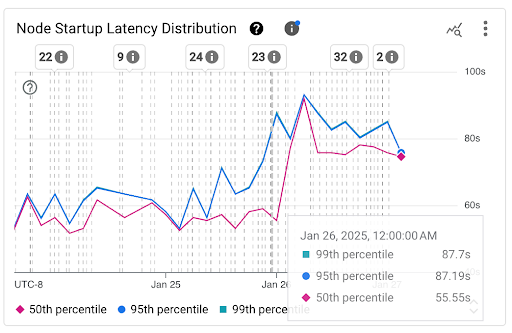
노드 시작 지연 시간 분포 보기
노드의 시작 지연 시간은 총 시작 지연 시간을 나타내며, 노드의 CreationTimestamp부터 Kubernetes node ready 상태까지의 시간을 측정합니다. 노드 시작 지연 시간은 다음 두 차트에서 확인할 수 있습니다.
노드 시작 지연 시간 분포 차트: 이 차트는 고정된 3시간 간격(예: 오전 12시~오전 3시, 오전 3시~오전 6시) 동안의 노드 시작 이벤트 관찰을 기반으로 계산된 노드 시작 지연 시간의 백분위수(50번째 백분위수, 95번째 백분위수, 99번째 백분위수)를 보여줍니다. 이 차트는 다음 용도로 사용할 수 있습니다.
- 기준 노드 시작 지연 시간을 파악합니다.
- 시간 경과에 따른 노드 시작 지연 시간의 변동을 식별합니다.
- 노드 시작 지연 시간의 변경사항을 클러스터 업데이트 또는 노드 풀 업데이트와 같은 최근 이벤트와 연관시킵니다. 대시보드 상단의 주석 목록에서 이벤트를 선택할 수 있습니다.
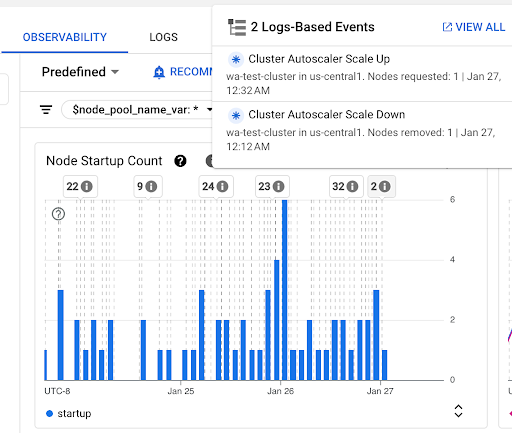
노드 시작 수 차트: 이 차트는 선택한 시간 간격 동안 시작된 노드 수를 보여줍니다. 이 차트는 다음 용도로 사용할 수 있습니다.
- 특정 시간 간격의 노드 시작 지연 시간 분포 백분위수를 계산하는 데 사용되는 노드 샘플 크기를 이해합니다.
- 노드 풀 업데이트 또는 클러스터 자동 확장 처리 이벤트와 같은 노드 시작 원인을 파악합니다. 대시보드 상단의 주석 목록에서 이벤트를 선택할 수 있습니다.
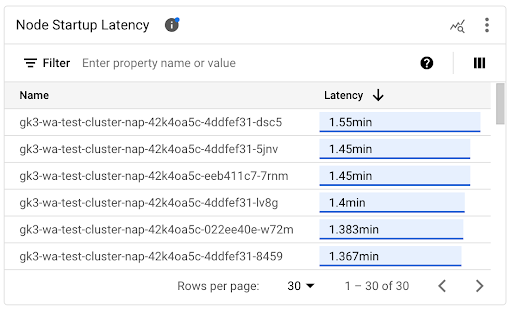
개별 노드의 시작 지연 시간 보기
개별 노드의 지연 시간을 비교하면 다양한 노드 구성이 노드 시작 지연 시간에 미치는 영향을 테스트하고 요구사항에 따라 최적의 구성을 식별할 수 있습니다. 노드 시작 지연 시간 타임라인 차트와 연결된 목록에서 개별 노드의 시작 지연 시간을 확인할 수 있습니다.
노드 시작 지연 시간 타임라인 차트를 사용하여 개별 노드 시작을 클러스터 업데이트 또는 노드 풀 업데이트와 같은 최근 이벤트와 연관시킵니다. 다른 노드와 비교하여 시작 지연 시간의 변경사항에 대한 잠재적 원인을 파악할 수 있습니다. 대시보드 상단의 주석 목록에서 이벤트를 선택할 수 있습니다.
노드 시작 지연 시간 목록을 사용하여 시작하는 데 걸린 시간이 가장 길거나 짧은 개별 노드를 식별합니다. 지연 시간 열을 기준으로 목록을 정렬할 수 있습니다. 시작 지연 시간이 가장 긴 노드를 식별하면 노드 시작 이벤트를 다른 최근 이벤트와 연관시켜 지연 시간 악화 문제를 해결할 수 있습니다.
개별 노드가 생성된 시점은 해당 노드 생성 이벤트의 protoPayload.metadata.creationTimestamp 필드 값을 확인하면 알 수 있습니다. protoPayload.metadata.creationTimestamp 필드를 확인하려면 로그 탐색기에서 다음 쿼리를 실행하세요.
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.nodes.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.name=NODE_NAME
노드 풀의 시작 지연 시간 보기
노드 풀의 구성이 다른 경우(예: 다른 워크로드를 실행하는 경우) 노드 풀별로 노드 시작 지연 시간을 별도로 모니터링해야 할 수 있습니다. 노드 풀 간의 노드 시작 지연 시간을 비교하면 노드 구성이 노드 시작 지연 시간에 미치는 영향을 파악하고 결과적으로 지연 시간을 최적화할 수 있습니다.
기본적으로 노드 시작 지연 시간 대시보드에는 클러스터의 모든 노드 풀에 걸쳐 집계된 시작 지연 시간 분포와 개별 노드 시작 지연 시간이 표시됩니다. 특정 노드 풀의 노드 시작 지연 시간을 보려면 대시보드 상단에 있는 $node_pool_name_var 필터를 사용하여 노드 풀의 이름을 선택합니다.
다음 단계
- 측정항목을 기반으로 포드 자동 확장을 최적화하는 방법을 알아봅니다.
- GKE에서 콜드 스타트 지연 시간을 줄이는 방법에 대해 자세히 알아봅니다.
- 이미지 스트리밍으로 이미지 가져오기 지연 시간을 줄이는 방법을 알아봅니다.
- 수평형 포드 자동 확장 조정의 놀라운 경제성에 대해 알아봅니다.
- 자동 애플리케이션 모니터링으로 워크로드를 모니터링합니다.