En esta página se ofrece una guía sobre los aspectos principales de las redes de Google Kubernetes Engine (GKE).
En esta página no se tratan temas generales sobre Kubernetes ni GKE. En esta página se da por hecho que conoces los siguientes conceptos:
- Conceptos de gestión de redes Linux
- Utilidades, como las reglas de enrutamiento y
iptables
Además, en esta página se da por supuesto que conoces la terminología básica relacionada con lo siguiente:
- Capa de transporte
- Capa de Internet
- Capas de aplicación
- Conjunto de protocolos de Internet (IP), incluidos HTTP y DNS
Esta página y el resto de la documentación están dirigidos a arquitectos de Cloud y especialistas en redes que diseñan y desarrollan la red de su organización. Para obtener una descripción general de todos los conjuntos de documentación de GKE, consulta Explorar la documentación de GKE. Para obtener más información sobre los roles habituales y las tareas de ejemplo a las que hacemos referencia en el Google Cloud contenido, consulta Roles y tareas habituales de los usuarios de GKE.
Kubernetes te permite definir de forma declarativa cómo se despliegan tus aplicaciones, cómo se comunican entre sí y con el plano de control de Kubernetes, y cómo pueden acceder a ellas los clientes. En esta página también se proporciona información sobre cómo configura GKE los servicios de Google Cloud, cuando es relevante para las redes.
Por qué es diferente la red de Kubernetes
Cuando usas Kubernetes para orquestar tus aplicaciones, es importante que cambies tu forma de pensar sobre el diseño de red de tus aplicaciones y sus hosts. Con Kubernetes, te centras en cómo se comunican los pods, los servicios y los clientes externos, en lugar de pensar en cómo se conectan tus hosts o máquinas virtuales.
La red definida por software (SDN) avanzada de Kubernetes permite el enrutamiento y el reenvío de paquetes para pods, servicios y nodos en diferentes zonas del mismo clúster regional. Kubernetes también configura de forma dinámica las reglas de filtrado de IP, las tablas de enrutamiento y las reglas de cortafuegos en cada nodo, en función del modelo declarativo de tus implementaciones de Kubernetes y de la configuración de tu clúster en Google Cloud. Google Cloud
Terminología relacionada con las redes de Kubernetes
El modelo de redes de Kubernetes se basa en gran medida en las direcciones IP. Los servicios, los pods, los contenedores y los nodos se comunican mediante direcciones IP y puertos. Kubernetes ofrece diferentes tipos de balanceo de carga para dirigir el tráfico a los pods correctos. Todos estos mecanismos se describen con más detalle más adelante. Ten en cuenta los siguientes términos relacionados con las direcciones IP:
- ClusterIP: la dirección IP asignada a un servicio. En otros documentos, puede denominarse "IP de clúster". Esta dirección es estable durante la vida útil del Servicio, tal como se indica en Servicios.
- Dirección IP del pod: la dirección IP asignada a un pod concreto. Es efímero, como se explica en Pods.
- Dirección IP del nodo: la dirección IP asignada a un nodo concreto.
Requisitos de conectividad de clústeres
Todos los clústeres requieren conectividad con *.googleapis.com, *.gcr.io, *.pkg.dev y la dirección IP del plano de control. Este requisito se cumple con las reglas de salida implícitas y las reglas de cortafuegos creadas automáticamente que crea GKE.
Redes dentro del clúster
En esta sección se describe la red de un clúster de Kubernetes en relación con la asignación de IPs, los pods, los servicios, el DNS y el plano de control.
Asignación de direcciones IP
Kubernetes usa varios intervalos de IP para asignar direcciones IP a nodos, pods y servicios.
- Cada nodo tiene asignada una dirección IP de la red de nube privada virtual (VPC) del clúster. Esta IP de nodo proporciona conectividad desde componentes de control como
kube-proxyykubeletal servidor de la API de Kubernetes. Esta dirección IP es la conexión del nodo con el resto del clúster. Cada nodo tiene un grupo de direcciones IP que GKE asigna a los pods que se ejecutan en ese nodo (un bloque CIDR/24 de forma predeterminada). También puedes especificar el intervalo de IPs al crear el clúster. La función de intervalo CIDR de pods flexible te permite reducir el tamaño del intervalo de direcciones IP de los pods de los nodos de un grupo de nodos.
Cada pod tiene una sola dirección IP asignada del intervalo CIDR de pods de su nodo. Todos los contenedores que se ejecutan en el pod comparten esta dirección IP, que los conecta con otros pods que se ejecutan en el clúster.
Cada servicio tiene una dirección IP, denominada ClusterIP, asignada desde la red VPC del clúster. Puedes personalizar la red VPC al crear el clúster.
Cada plano de control tiene una dirección IP pública o interna en función del tipo de clúster, la versión y la fecha de creación. Para obtener más información, consulta la descripción del plano de control.
El modelo de red de GKE no permite reutilizar direcciones IP en la red. Cuando migres a GKE, debes planificar la asignación de direcciones IP para reducir el uso de direcciones IP internas en GKE.
Unidad máxima de transmisión (MTU)
El valor de MTU seleccionado para una interfaz de Pod depende de la interfaz de red de contenedores (CNI) que usen los nodos del clúster y del valor de MTU de la VPC subyacente. Para obtener más información, consulta Pods.
El valor de MTU de la interfaz de Pod es 1460 o se hereda de la interfaz principal del nodo.
| CNI | MTU | GKE Standard |
|---|---|---|
| kubenet | 1460 | Predeterminado |
|
kubenet (versión 1.26.1 de GKE y posteriores) |
Heredada | Predeterminado |
| Calico | 1460 |
Se habilita mediante Para obtener más información, consulta el artículo Controlar la comunicación entre pods y servicios mediante políticas de red. |
| netd | Heredada | Se habilita de una de las siguientes formas: |
| GKE Dataplane V2 | Heredada |
Se habilita mediante Para obtener más información, consulta Usar GKE Dataplane V2. |
Para obtener más información, consulta Clústeres nativos de VPC.
Complementos de red admitidos
- Para usar un complemento de red, debes instalarlo tú mismo. GKE ofrece los siguientes complementos de red compatibles de forma nativa:
- Calico (en Dataplane V1)
- Cilium (en Dataplane V2)
- Istio-CNI (en el controlador de plano de datos gestionado de GKE Enterprise)
Pods
En Kubernetes, un pod es la unidad desplegable más básica de un clúster de Kubernetes. Un pod ejecuta uno o varios contenedores. Cero o más pods se ejecutan en un nodo. Cada nodo del clúster forma parte de un grupo de nodos.
En GKE, estos nodos son máquinas virtuales, cada una de las cuales se ejecuta como una instancia en Compute Engine.
Los pods también pueden conectarse a volúmenes de almacenamiento externo y a otros recursos personalizados. En este diagrama se muestra un solo nodo que ejecuta dos pods, cada uno de ellos conectado a dos volúmenes.
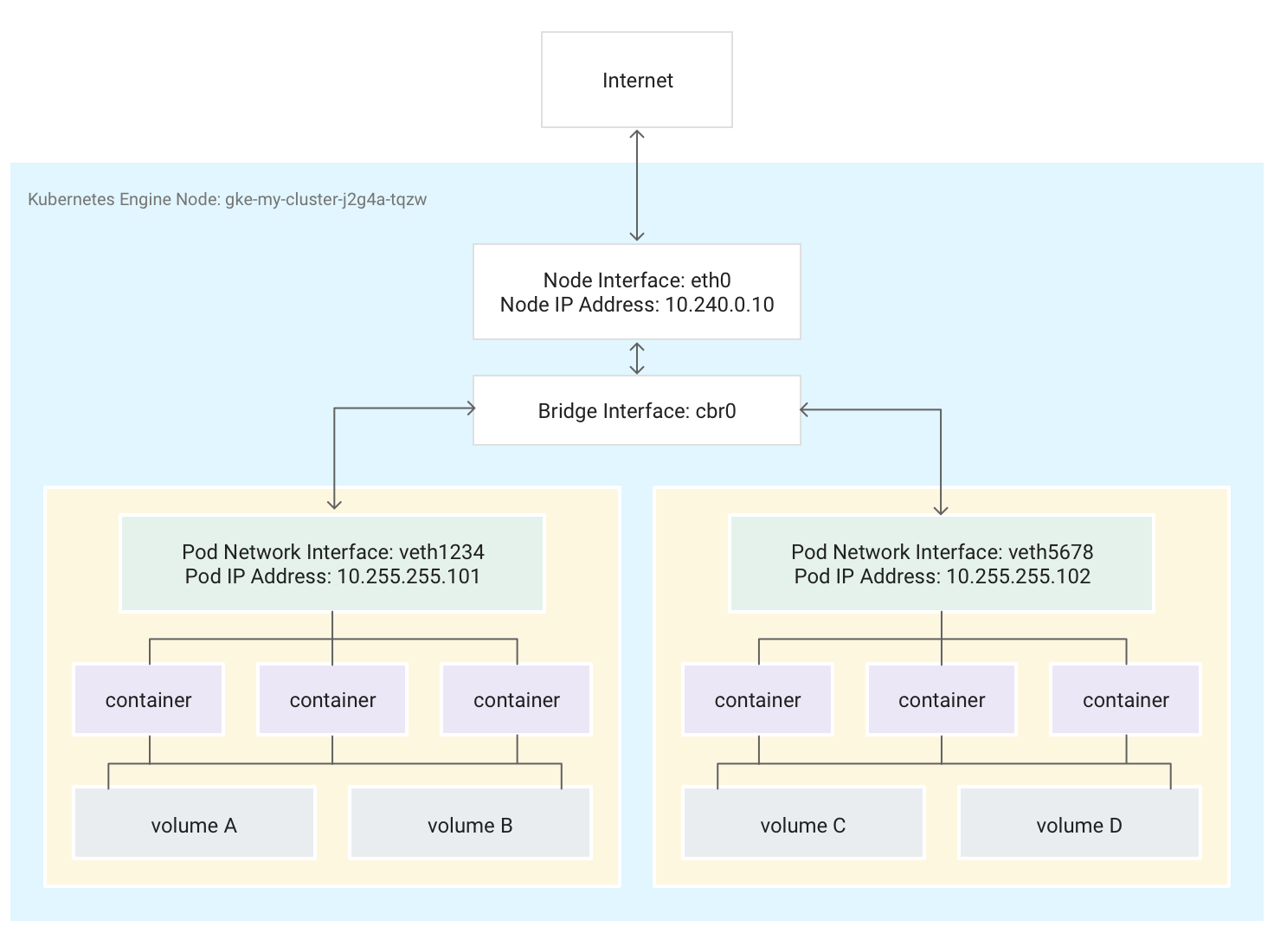
Cuando Kubernetes programa un pod para que se ejecute en un nodo, crea un espacio de nombres de red para el pod en el kernel de Linux del nodo. Este espacio de nombres de red conecta la interfaz de red física del nodo, como eth0, con el pod mediante una interfaz de red virtual, de forma que los paquetes puedan fluir hacia el pod y desde él. La interfaz de red virtual asociada en el espacio de nombres de red raíz del nodo se conecta a un puente de Linux que permite la comunicación entre los pods del mismo nodo. Un pod también puede enviar paquetes fuera del nodo mediante la misma interfaz virtual.
Kubernetes asigna una dirección IP (la dirección IP del pod) a la interfaz de red virtual en el espacio de nombres de red del pod a partir de un intervalo de direcciones reservado para los pods del nodo. Este intervalo de direcciones es un subconjunto del intervalo de direcciones IP asignado al clúster para los pods, que puedes configurar al crear un clúster.
Un contenedor que se ejecuta en un pod usa el espacio de nombres de red del pod. Desde el punto de vista del contenedor, el pod parece una máquina física con una interfaz de red. Todos los contenedores del Pod ven la misma interfaz de red.
El localhost de cada contenedor está conectado, a través del pod, a la interfaz de red física del nodo, como eth0.
Ten en cuenta que esta conectividad varía drásticamente en función de si usas la interfaz de red de contenedores (CNI) de GKE o si eliges usar la implementación de Calico habilitando la política de red al crear el clúster.
Si usas el CNI de GKE, un extremo del par de dispositivos Ethernet virtual (veth) se adjunta al pod en su espacio de nombres y el otro se conecta al dispositivo de puente de Linux
cbr0.1 En este caso, el siguiente comando muestra las distintas direcciones MAC de los pods adjuntos acbr0:arp -nSi ejecutas el siguiente comando en el contenedor de la caja de herramientas, se muestra el extremo del espacio de nombres raíz de cada par veth conectado a
cbr0:brctl show cbr0Si la política de red está habilitada, un extremo del par veth se adjunta al pod y el otro a
eth0. En este caso, el siguiente comando muestra las diferentes direcciones MAC de los pods asociados a diferentes dispositivos veth:arp -nAl ejecutar el siguiente comando en el contenedor de la caja de herramientas, se muestra que no hay ningún dispositivo de puente de Linux llamado
cbr0:brctl show
Las reglas de iptables que facilitan el reenvío dentro del clúster varían de un caso a otro. Es importante tener en cuenta esta distinción al solucionar problemas de conectividad.
De forma predeterminada, cada pod tiene acceso sin filtros a todos los demás pods que se ejecutan en todos los nodos del clúster, pero puedes limitar el acceso entre pods. Kubernetes elimina y vuelve a crear pods periódicamente. Esto ocurre cuando se actualiza un grupo de nodos, cuando se cambia la configuración declarativa de un pod o la imagen de un contenedor, o cuando un nodo deja de estar disponible. Por lo tanto, la dirección IP de un pod es un detalle de implementación y no debes depender de ella. Kubernetes proporciona direcciones IP estables mediante servicios.
-
El puente de red virtual
cbr0solo se crea si hay pods que definenhostNetwork: false.↩.
Servicios
En Kubernetes, puedes asignar pares clave-valor arbitrarios llamados etiquetas a cualquier recurso de Kubernetes. Kubernetes usa etiquetas para agrupar varios pods relacionados en una unidad lógica llamada "servicio". Un servicio tiene una dirección IP y puertos estables, y proporciona balanceo de carga entre el conjunto de pods cuyas etiquetas coinciden con todas las etiquetas que definas en el selector de etiquetas al crear el servicio.
de Kubernetes.En el siguiente diagrama se muestran dos servicios independientes, cada uno de los cuales se compone de varios pods. Cada uno de los pods del diagrama tiene la etiqueta app=demo, pero sus otras etiquetas son diferentes. El servicio "frontend" coincide con todos los pods que tienen app=demo y component=frontend, mientras que el servicio "users" coincide con todos los pods que tienen app=demo y component=users. El pod del cliente no coincide exactamente con el selector de ninguno de los dos servicios, por lo que no forma parte de ninguno de ellos. Sin embargo, el pod de cliente puede comunicarse con cualquiera de los servicios porque se ejecuta en el mismo clúster.
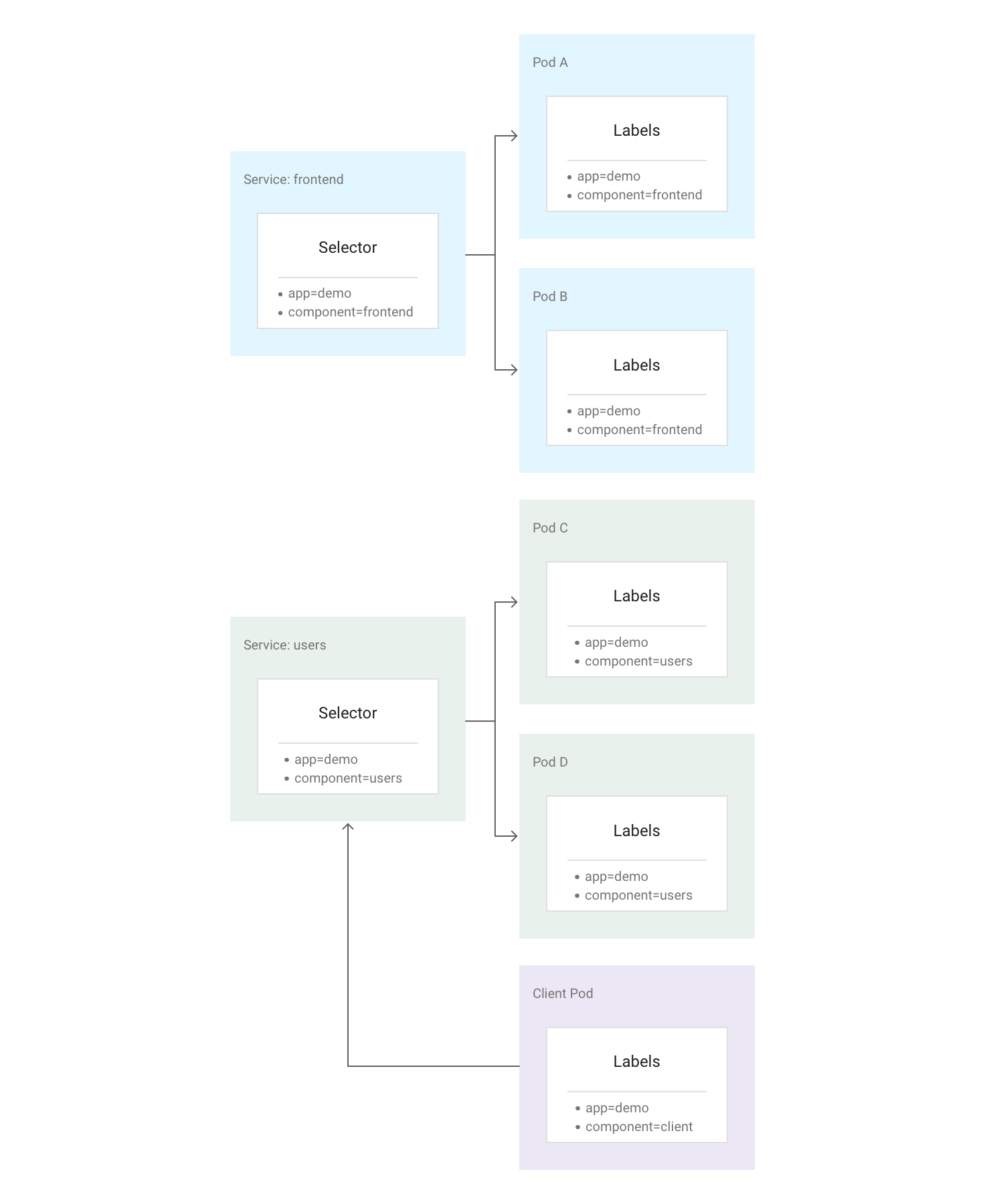
Kubernetes asigna una dirección IP estable y fiable a cada servicio recién creado (la ClusterIP) del grupo de direcciones IP de servicio disponibles del clúster. Kubernetes también asigna un nombre de host a ClusterIP añadiendo una entrada de DNS. ClusterIP y el nombre de host son únicos en el clúster y no cambian durante el ciclo de vida del servicio. Kubernetes solo libera la ClusterIP y el nombre de host si el servicio se elimina de la configuración del clúster. Puedes acceder a un pod en buen estado que ejecute tu aplicación mediante ClusterIP o el nombre de host del servicio.
A primera vista, un servicio puede parecer un punto único de fallo para tus aplicaciones. Sin embargo, Kubernetes distribuye el tráfico de la forma más uniforme posible entre el conjunto completo de pods que se ejecutan en muchos nodos, por lo que un clúster puede resistir una interrupción que afecte a uno o varios nodos (pero no a todos).
Kube-Proxy
Kubernetes gestiona la conectividad entre pods y servicios mediante el componente kube-proxy, que tradicionalmente se ejecuta como un pod estático en cada nodo.
kube-proxy, que no es un proxy insertado, sino un controlador de balanceo de carga basado en el tráfico de salida, monitoriza el servidor de la API de Kubernetes y asigna continuamente la ClusterIP a los pods en buen estado añadiendo y eliminando reglas de NAT de destino (DNAT) al subsistema iptables del nodo. Cuando un contenedor que se ejecuta en un pod envía tráfico a la ClusterIP de un servicio, el nodo selecciona un pod aleatoriamente y dirige el tráfico a ese pod.
Cuando configuras un servicio, puedes reasignar su puerto de escucha definiendo valores para port y targetPort.
- El
portes el lugar donde los clientes acceden a la aplicación. - El
targetPortes el puerto en el que la aplicación está escuchando el tráfico dentro del pod.
kube-proxy gestiona esta reasignación de puertos añadiendo y quitando reglas iptables en el nodo.
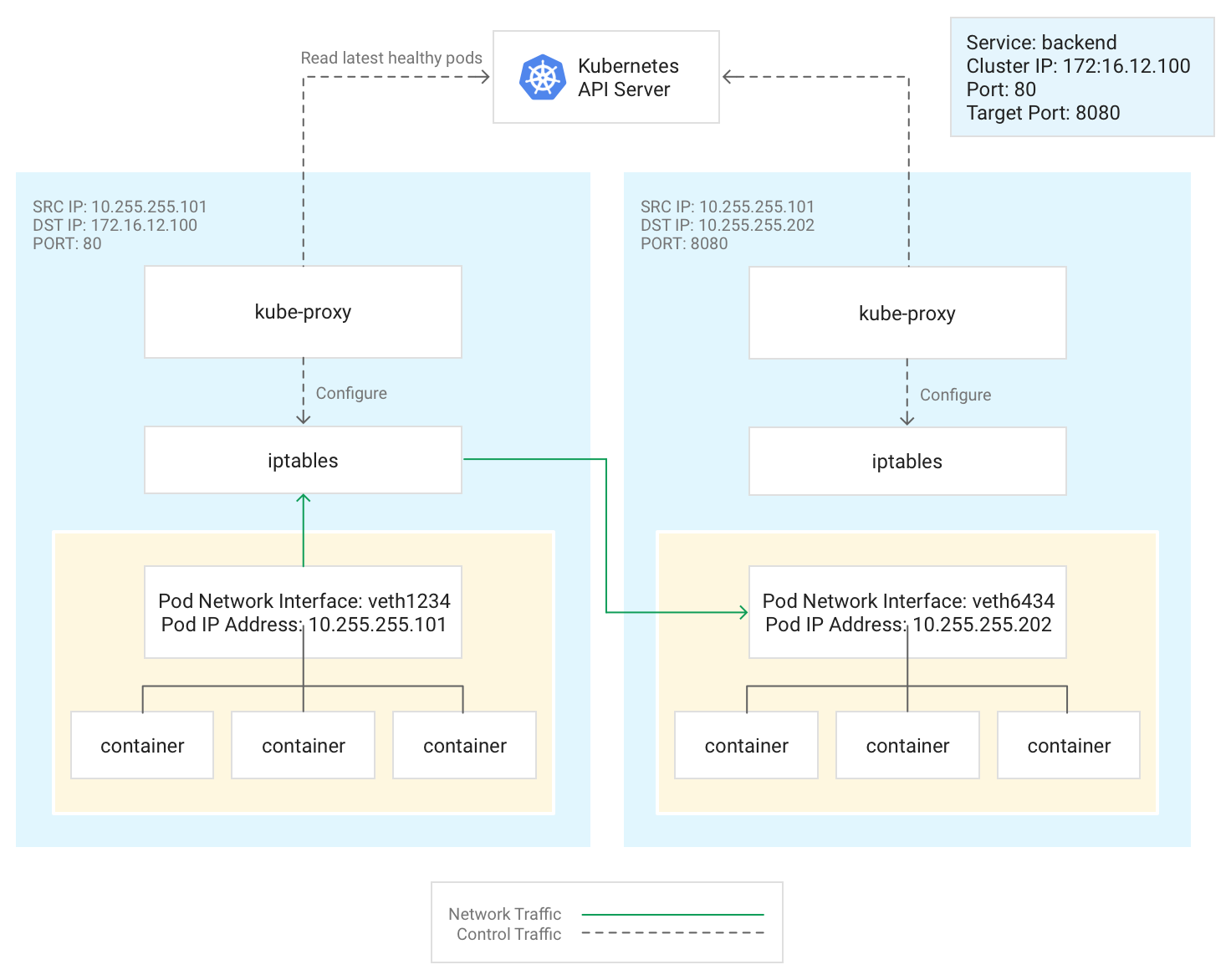
En este diagrama se muestra el flujo de tráfico de un pod de cliente a un pod de servidor en un nodo diferente. El cliente se conecta al Servicio en 172.16.12.100:80.
El servidor de la API de Kubernetes mantiene una lista de pods que ejecutan la aplicación. El proceso de kube-proxy en cada nodo usa esta lista para crear una regla de iptables que dirija el tráfico al pod adecuado (como 10.255.255.202:8080). El pod del cliente no tiene por qué conocer la topología del clúster ni ningún detalle sobre los pods o contenedores individuales que contiene.
La forma en que se despliega kube-proxy depende de la versión de GKE del clúster:
- En las versiones 1.16.0 y 1.16.8-gke.13 de GKE,
kube-proxyse implementa como un DaemonSet. - En las versiones de GKE posteriores a la 1.16.8-gke.13,
kube-proxyse despliega como un pod estático para los nodos.
DNS
GKE ofrece las siguientes opciones de DNS de clúster gestionado para resolver nombres de servicio y nombres externos:
kube-dns: un complemento de clúster que se implementa de forma predeterminada en todos los clústeres de GKE. Para obtener más información, consulta el artículo sobre cómo usar kube-dns.
Cloud DNS: una infraestructura de DNS de clúster gestionada en la nube que sustituye a kube-dns en el clúster. Para obtener más información, consulta Usar Cloud DNS para GKE.
GKE también proporciona NodeLocal DNSCache como complemento opcional con kube-dns o Cloud DNS para mejorar el rendimiento del DNS del clúster.
Para obtener más información sobre cómo proporciona GKE el DNS, consulta Descubrimiento de servicios y DNS.
Plano de control
En Kubernetes, el plano de control gestiona los procesos del plano de control, incluido el servidor de la API de Kubernetes. La forma de acceder al plano de control depende de cómo hayas configurado el aislamiento de red del plano de control.
Redes fuera del clúster
En esta sección se explica cómo llega el tráfico desde fuera del clúster a las aplicaciones que se ejecutan en un clúster de Kubernetes. Esta información es importante a la hora de diseñar las aplicaciones y las cargas de trabajo de tu clúster.
Ya has leído cómo usa Kubernetes los servicios para proporcionar direcciones IP estables a las aplicaciones que se ejecutan en pods. De forma predeterminada, los pods no exponen una dirección IP externa, ya que kube-proxy gestiona todo el tráfico de cada nodo. Los pods y sus contenedores pueden comunicarse libremente, pero las conexiones fuera del clúster no pueden acceder al servicio. Por ejemplo, en la ilustración anterior, los clientes que no están en el clúster no pueden acceder al servicio frontend mediante su ClusterIP.
GKE ofrece tres tipos diferentes de balanceadores de carga para controlar el acceso y distribuir el tráfico entrante en tu clúster de la forma más uniforme posible. Puede configurar un servicio para que use varios tipos de balanceadores de carga simultáneamente.
- Los balanceadores de carga externos gestionan el tráfico procedente de fuera del clúster y de fuera de tu Google Cloudred de VPC. Usan reglas de reenvío asociadas a laGoogle Cloud red para enrutar el tráfico a un nodo de Kubernetes.
- Los balanceadores de carga internos gestionan el tráfico procedente de la misma red de VPC. Al igual que los balanceadores de carga externos, utilizan reglas de reenvío asociadas a la Google Cloud red para enrutar el tráfico a un nodo de Kubernetes.
- Los balanceadores de carga de aplicaciones son balanceadores de carga externos especializados que se usan para el tráfico HTTP(S). Usan un recurso de pasarela (recomendado) o de entrada en lugar de una regla de reenvío para enrutar el tráfico a un nodo de Kubernetes.
Cuando el tráfico llega a un nodo de Kubernetes, se gestiona de la misma forma, independientemente del tipo de balanceador de carga. El balanceador de carga no sabe qué nodos del clúster están ejecutando pods para su servicio. En su lugar, equilibra el tráfico entre todos los nodos del clúster, incluso entre aquellos que no ejecutan un pod relevante. En un clúster regional, la carga se distribuye entre todos los nodos de todas las zonas de la región del clúster. Cuando el tráfico se dirige a un nodo, este lo envía a un pod, que puede estar ejecutándose en el mismo nodo o en otro. El nodo reenvía el tráfico a un pod elegido aleatoriamente mediante las reglas iptables que kube-proxy gestiona en el nodo.
En el siguiente diagrama, el balanceador de carga de red de paso a través externo dirige el tráfico al nodo central y el tráfico se redirige a un pod del primer nodo.

Cuando un balanceador de carga envía tráfico a un nodo, el tráfico se puede reenviar a un pod de otro nodo. Esto requiere saltos de red adicionales. Si quieres evitar los saltos adicionales, puedes especificar que el tráfico debe ir a un pod que esté en el mismo nodo que recibe el tráfico inicialmente.
Para especificar que el tráfico debe dirigirse a un pod del mismo nodo, defina externalTrafficPolicy como Local en el manifiesto de su servicio:
apiVersion: v1
kind: Service
metadata:
name: my-lb-service
spec:
type: LoadBalancer
externalTrafficPolicy: Local
selector:
app: demo
component: users
ports:
- protocol: TCP
port: 80
targetPort: 8080
Si asignas el valor Local a externalTrafficPolicy, el balanceador de carga solo envía tráfico a los nodos que tengan un pod en buen estado que pertenezca al servicio.
El balanceador de carga usa una comprobación del estado para determinar qué nodos tienen los pods adecuados.
Balanceador de carga externo
Si tu servicio debe ser accesible desde fuera del clúster y de tu red de VPC, puedes configurarlo como LoadBalancer. Para ello, define el campo type del servicio como Loadbalancer al definir el servicio. A continuación, GKE aprovisiona un balanceador de carga de red de paso a través externo delante del servicio.
El balanceador de carga de red de pases externo conoce todos los nodos de tu clúster y configura las reglas de cortafuegos de tu red VPC para permitir conexiones al servicio desde fuera de la red VPC mediante la dirección IP externa del servicio. Puedes asignar una dirección IP externa estática al servicio.
Para obtener más información, consulta Configurar nombres de dominio con direcciones IP estáticas.
Para obtener más información sobre las reglas de cortafuegos, consulta Reglas de cortafuegos creadas automáticamente.
Información técnica
Cuando se usa el balanceador de carga externo, el tráfico entrante se dirige inicialmente a un nodo mediante una regla de reenvío asociada a la Google Cloud red.
Cuando el tráfico llega al nodo, este usa su tabla NAT iptables para elegir un pod. kube-proxy gestiona las reglas de iptables en el nodo.
Balanceador de carga interno
Para el tráfico que debe llegar a tu clúster desde la red VPC del clúster o desde redes conectadas a la red VPC del clúster, puedes configurar tu servicio para aprovisionar un balanceador de carga de red de transferencia interno. El balanceador de carga de red de paso a través interno elige una dirección IP de la subred de VPC de tu clúster en lugar de una dirección IP externa. Las aplicaciones o los servicios, tanto si están en la red VPC del clúster como en redes conectadas, pueden usar esta dirección IP para comunicarse con los servicios del clúster.
Información técnica
El balanceo de carga interno se proporciona mediante Google Cloud. Cuando el tráfico llega a un nodo determinado, este usa su tabla NAT iptables para elegir un pod, aunque el pod esté en otro nodo.
kube-proxy gestiona las reglas de iptables en el nodo.
Para obtener más información sobre los balanceadores de carga internos, consulta el artículo Usar un balanceador de carga de red de paso a través interno.
Balanceador de carga de aplicación
Muchas aplicaciones, como las APIs de servicios web RESTful, se comunican mediante HTTP(S). Puedes permitir que los clientes externos a tu red VPC accedan a este tipo de aplicación mediante la API Gateway de Kubernetes.
El controlador de GKE Gateway es la implementación de Google de la API Gateway de Kubernetes para el balanceo de carga en Cloud. Gateway API es un proyecto de código abierto cuyo objetivo es estandarizar la forma en que los service meshes y los controladores de entrada exponen las aplicaciones en Kubernetes. Está diseñado para ser un sucesor más expresivo, flexible y extensible del recurso Ingress.
El controlador de Gateway de GKE se usa para configurar balanceadores de carga de aplicaciones de capa 7 que exponen el tráfico HTTP(S) a las aplicaciones que se ejecutan en el clúster.
Usa la API Gateway para implementar tu balanceador de carga.
Gateway API usa los siguientes recursos:
- Clase de Gateway: este recurso define el tipo de balanceador de carga que implementa GKE. GKE proporciona GatewayClasses que se pueden usar en clústeres.
- Pasarela: un recurso de pasarela define configuraciones de escucha, como puertos, protocolos y nombres de host, y actúa como punto de entrada del tráfico en tu clúster.
- HTTPRoute un HTTPRoute especifica cómo se enruta el tráfico recibido por una Gateway a los Servicios. Las HTTPRoutes pueden incluir funciones avanzadas, como el enrutamiento basado en rutas, la coincidencia de encabezados, la división del tráfico para pruebas A/B y un control más preciso de los tiempos de espera y los reintentos.
- Política: puedes asociar una política a una pasarela, una ruta o un servicio de Kubernetes para definir cómo debe funcionar la infraestructura subyacente. Google Cloud
Para obtener más información, consulta el artículo Acerca de la API Gateway.
Información técnica
Cuando creas un objeto Gateway, el controlador Gateway de GKE configura un balanceador de carga de aplicaciones según las reglas de los manifiestos Gateway, HTTPRoute y Service. El cliente envía una solicitud al Application Load Balancer. El balanceador de carga es un proxy real. Elige un nodo y reenvía la solicitud a la combinación NodeIP:NodePort de ese nodo. El nodo usa su iptables tabla NAT para elegir un Pod.
kube-proxy gestiona las reglas de iptables en el nodo.
Seguridad de redes
Para mejorar la seguridad de tu clúster, puedes limitar la conectividad entre nodos, entre pods y con los balanceadores de carga.
Limitar la conectividad entre nodos
Crear reglas de cortafuegos de entrada o salida dirigidas a los nodos de tu clúster puede tener efectos adversos. Por ejemplo, si aplicas reglas de denegación de salida a los nodos de tu clúster, podrían dejar de funcionar funciones como NodePort y kubectl exec.
Limitar la conectividad a pods y servicios
De forma predeterminada, todos los pods que se ejecutan en el mismo clúster pueden comunicarse libremente. Sin embargo, puedes limitar la conectividad dentro de un clúster de diferentes formas, según tus necesidades.
Limitar el acceso entre pods
Puedes limitar el acceso entre pods mediante una política de red. Las definiciones de políticas de red te permiten restringir el ingreso y la salida de los pods en función de una combinación arbitraria de etiquetas, intervalos de direcciones IP y números de puerto.
De forma predeterminada, no hay ninguna política de red, por lo que se permite todo el tráfico entre los pods del clúster. En cuanto creas la primera política de red en un espacio de nombres, se deniega todo el tráfico restante.
Después de crear una política de red, debe habilitarla explícitamente en el clúster. Para obtener más información, consulta Configurar políticas de red para aplicaciones.
Limitar el acceso a un balanceador de carga externo
Si tu servicio usa un balanceador de carga externo, el tráfico de cualquier dirección IP externa puede acceder a tu servicio de forma predeterminada. Puede restringir los intervalos de direcciones IP que pueden acceder a los endpoints de su clúster configurando la opción loadBalancerSourceRanges al configurar el servicio. Puedes especificar varios intervalos y actualizar la configuración de un servicio en ejecución en cualquier momento. La instancia kube-proxy que se ejecuta en cada nodo configura las reglas iptables de ese nodo para denegar todo el tráfico que no coincida con el loadBalancerSourceRanges especificado. Además, cuando creas un servicio LoadBalancer, GKE crea una regla de cortafuegos de VPC correspondiente para aplicar estas restricciones a nivel de red.
Limitar el acceso a un balanceador de carga de aplicaciones
Si tu servicio usa un balanceador de carga de aplicaciones, puedes usar una política de seguridad de Google Cloud Armor para limitar las direcciones IP externas que pueden acceder a tu servicio y las respuestas que se deben devolver cuando se deniega el acceso debido a la política de seguridad. Puedes configurar Cloud Logging para registrar información sobre estas interacciones.
Si una política de seguridad de Cloud Armor no es lo suficientemente detallada, puedes habilitar Identity-Aware Proxy en tus endpoints para implementar la autenticación y la autorización basadas en usuarios en tu aplicación. Consulta más información en el tutorial detallado para configurar las compras en la aplicación.
Problemas conocidos
En esta sección se describen los problemas conocidos.
El nodo habilitado para contenedores no puede conectarse al intervalo 172.17/16
Una VM de nodo con containerd habilitado no puede conectarse a un host que tenga una IP dentro de 172.17/16. Para obtener más información, consulta Conflicto con el intervalo de direcciones IP 172.17/16.
Recursos restantes de clústeres de GKE eliminados con Private Service Connect
Si has creado y eliminado clústeres de GKE con Private Service Connect antes del 7 de mayo del 2024 y has eliminado el proyecto que contenía el clúster antes que el propio clúster, es posible que se hayan filtrado recursos de Private Service Connect asociados. Estos recursos permanecen ocultos y no te permiten eliminar las subredes asociadas. Si tienes este problema, ponte en contacto con el equipo de Asistencia deGoogle Cloud .
Siguientes pasos
- Consulta información sobre los servicios.
- Consulta información sobre los pods.
- Configura un clúster con VPC compartida.