Modelle für maschinelles Lernen werden oft als Blackboxes bezeichnet, bei denen selbst die Designer nicht erklären können, wie oder warum ein Modell eine bestimmte Inferenz erzeugt hat. Vertex Explainable AI bietet featurebasierte und beispielbasierte Erläuterungen zum besseren Verständnis der Modellentscheidung.
Wenn Sie wissen, wie sich ein Modell verhält und wie sein Trainings-Dataset das Modell beeinflusst, können alle, die ML-Modelle erstellen oder verwenden, neue Modelle verbessern, das Vertrauen in ihre Schlussfolgerungen gewinnen und verstehen, wann und warum etwas schiefgeht.
Beispielbasierte Erklärungen
Mit beispielbasierten Erläuterungen verwendet Vertex AI die Suche des nächsten Nachbarn, um eine Liste von Beispielen (in der Regel aus dem Trainings-Dataset) zurückzugeben, die der Eingabe am ähnlichsten sind. Da wir in der Regel ähnliche Eingaben erwarten, um ähnliche Vorhersagen zu liefern, können wir diese Erläuterungen nutzen, um das Verhalten unseres Modells zu untersuchen und zu erklären.
Beispielbasierte Erklärungen können in verschiedenen Szenarien nützlich sein:
Daten oder Modell verbessern: Einer der wichtigsten Anwendungsfälle für beispielbasierte Erläuterungen ist es, zu verstehen, warum Ihr Modell bestimmte Fehler bei seinen Inferenzen gemacht hat und wie Sie diese Informationen zur Verbesserung Ihrer Daten oder Ihres Modells nutzen können. Wählen Sie dazu zuerst Testdaten aus, die für Sie von Interesse sind. Diese können entweder auf Geschäftsanforderungen oder Heuristiken wie Daten zurückzuführen sein, bei denen das Modell die schwerwiegendsten Fehler gemacht hat.
Nehmen wir beispielsweise an, Sie haben ein Modell, bei dem Bilder entweder als Vogel oder als Flugzeug klassifiziert werden und der folgende Vogel fälschlicherweise als Flugzeug mit hoher Konfidenz klassifiziert wird. Verwenden Sie beispielbasierte Erläuterungen, um ähnliche Bilder aus dem Trainings-Dataset abzurufen und herauszufinden, was passiert.

Da alle Erläuterungen dunkle Silhouetten aus der Flugzeugklasse sind, ist dies ein Hinweis darauf, mehr Vogelsilhouetten zu erhalten.
Wenn die Erläuterungen jedoch hauptsächlich aus der Vogelklasse stammen, ist dies ein Hinweis darauf, dass unser Modell keine Beziehungen erlernen kann, selbst wenn die Daten umfangreich sind. Wir sollten daher eine höhere Modellkomplexität in Betracht ziehen (z. B. durch Hinzufügen weiterer Ebenen).
Neue Daten interpretieren: Nehmen wir an, Ihr Modell wurde trainiert, um Vögel und Flugzeuge zu klassifizieren, in der Praxis erkennt das Modell jedoch auch Bilder von Kites, Drohnen und Hubschraubern. Wenn das Dataset des nächsten Nachbarn einige beschriftete Bilder von Kites, Drohnen und Hubschraubern enthält, können Sie beispielbasierte Erläuterungen verwenden, um neue Bilder zu klassifizieren, indem das am häufigsten verwendete Label der nächsten Nachbarn angewendet wird. Dies ist möglich, da wir davon ausgehen, dass sich die latente Darstellung von Kites von der Vogel- und Flugzeugebene unterscheidet und ähnlich mit den mit Labels versehenen Kites im Dataset des nächsten Nachbarn ist.
Anomalien erkennen: Wenn eine Instanz weit von allen Daten im Trainings-Dataset entfernt ist, handelt es sich wahrscheinlich um einen Ausreißer. Neuronale Netzwerke sind dafür bekannt, dass sie übermäßig in ihre Fehler vertrauen und Fehler dadurch maskiert werden. Durch das Monitoring Ihrer Modelle mit beispielbasierten Erläuterungen können Sie die schwerwiegendsten Ausreißer ermitteln.
Aktives Lernen: Mit beispielbasierten Erläuterungen können Sie die Instanzen ermitteln, die vom menschlichen Labeling profitieren könnten. Dies ist besonders nützlich, wenn das Labeling langsam oder teuer ist und dafür sorgt, dass Sie ein maximal umfassendes Dataset aus begrenzten Labeling-Ressourcen erhalten.
Nehmen wir beispielsweise an, Sie haben ein Modell, das Patienten nach Erkältung oder Grippe klassifiziert. Wenn ein Patient mit Grippe klassifiziert wird und alle seine beispielbasierten Erläuterungen aus der Grippe-Klasse stammen, kann der Arzt sich besser auf die Schlussfolgerung des Modells verlassen, ohne genauer hinzuschauen. Wenn jedoch einige Erläuterungen aus der Grippe-Klasse und andere aus der Erkältungs-Klasse stammen, lohnt es sich, die Meinung eines Arztes einzuholen. So entsteht ein Dataset, in dem schwierige Instanzen mehr Labels haben. Das erleichtert es nachgelagerten Modellen, komplexe Beziehungen zu lernen.
Informationen zum Erstellen eines Modells, das beispielbasierte Erläuterungen unterstützt, finden Sie unter Beispielbasierte Erläuterungen konfigurieren.
Unterstützte Modelltypen
Es wird jedes TensorFlow-Modell unterstützt, das für Eingaben eine Einbettung (spätere Darstellung) bereitstellen kann. Baumbasierte Modelle wie Entscheidungsbäume werden nicht unterstützt. Modelle aus anderen Frameworks wie PyTorch oder XGBoost werden noch nicht unterstützt.
Bei neuronalen Deep-Learning-Netzwerken gehen wir im Allgemeinen davon aus, dass die höheren Ebenen (nahe der Ausgabeebene) etwas Sinnvolles gelernt haben. Daher wird die vorletzte Ebene häufig für Einbettungen ausgewählt. Sie können mit einigen verschiedenen Ebenen experimentieren, die erhaltenen Beispiele untersuchen und eines anhand quantitativer (Klassenübereinstimmung) oder qualitativer (erkennbarer) Maßnahmen auswählen.
Eine Demonstration dazu, wie Einbettungen aus einem TensorFlow-Modell extrahiert und die nächste Nachbarsuche durchgeführt werden, finden Sie im beispielbasierten Erläuterungsnotebook.
Featurebasierte Erläuterungen
Vertex Explainable AI bindet Feature-Attributionen in Vertex AI ein. Dieser Abschnitt bietet eine kurze konzeptionelle Übersicht über die Methoden zur Attribution von Features, die mit Vertex AI verfügbar sind.
Feature-Attributionen geben an, wie viel jedes Feature in Ihrem Modell zu den Inferenzen für die jeweilige Instanz beigetragen hat. Wenn Sie Inferenzanfragen stellen, erhalten Sie entsprechende Werte für Ihr Modell. Wenn Sie Erklärungen anfordern, erhalten Sie die Inferenz zusammen mit Informationen zur Feature-Attribution.
Feature-Attributionen arbeiten mit tabellarischen Daten und beinhalten integrierte Visualisierungsfunktionen für Bilddaten. Betrachten Sie folgende Beispiele:
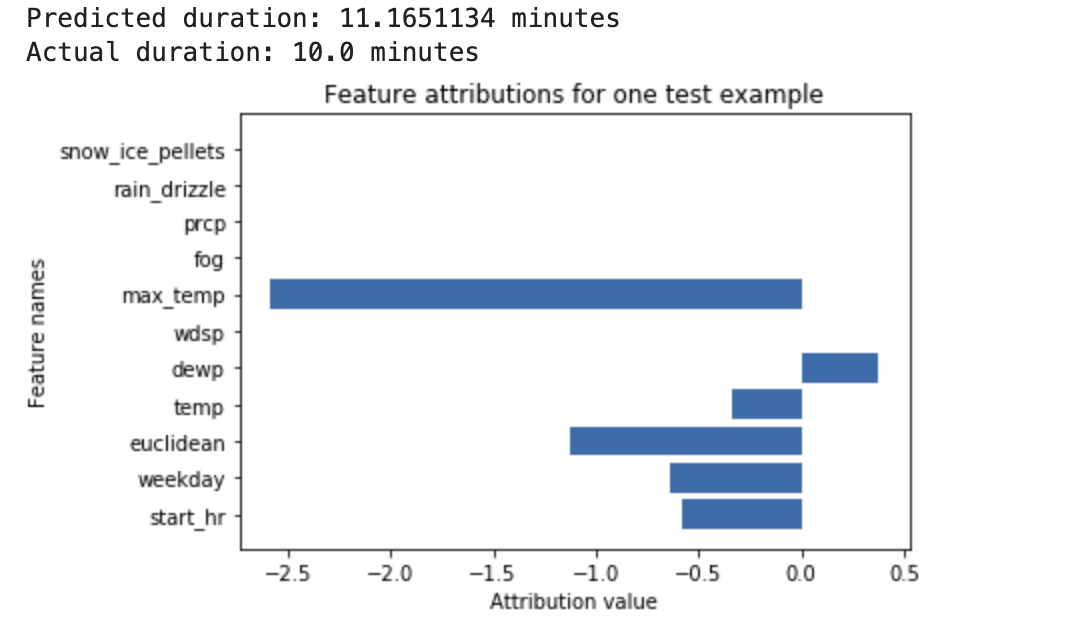
Ein neuronales Deep-Learning-Netzwerk wird trainiert, damit es die Dauer einer Fahrradtour auf Basis von Wetterdaten und früheren geteilten Daten vorhersagt. Wenn Sie nur Vorhersagen von diesem Modell anfordern, erhalten Sie die vorhergesagte Dauer von Fahrradtouren in Minuten. Wenn Sie Erläuterungen anfordern, erhalten Sie die vorhergesagte Fahrzeit sowie einen Attributionswert für jedes Feature in Ihrer Erläuterungsanfrage. Die Attributionswerte geben an, wie stark sich das Feature relativ zum von Ihnen angegebenen Referenzwert auf die Änderung des Inferenzwerts auswirkt. Wählen Sie eine aussagekräftige Referenz für Ihr Modell aus. In diesem Fall die mittlere Fahrtzeit. Sie können die Feature-Attributionswerte grafisch darstellen, um zu sehen, welche Features am stärksten zur resultierenden Inferenz beigetragen haben:
Ein Bildklassifizierungsmodell wird trainiert, um vorherzusagen, ob ein bestimmtes Bild einen Hund oder eine Katze enthält. Wenn Sie Inferenzanfragen für dieses Modell für einen neuen Satz von Bildern stellen, erhalten Sie eine Inferenz für jedes Bild („Hund“ oder „Katze“). Wenn Sie Erläuterungen anfordern, erhalten Sie die vorhergesagte Klasse zusammen mit einem Overlay für das Bild, das zeigt, welche Pixel im Bild am stärksten zur resultierenden Inferenz beigetragen haben:

Ein Foto einer Katze mit Feature-Attributionsoverlay 
Ein Foto von einem Hund mit Feature-Attributionsoverlay Ein Bildklassifizierungsmodell wird trainiert, um die Gattung einer Blume in dem Bild vorherzusagen. Wenn Sie Inferenzanfragen für dieses Modell für einen neuen Satz von Bildern stellen, erhalten Sie eine Inferenz für jedes Bild („Gänseblümchen“ oder „Löwenzahn“). Wenn Sie Erläuterungen anfordern, erhalten Sie die vorhergesagte Klasse zusammen mit einem Overlay für das Bild, das zeigt, welche Bereiche im Bild am stärksten zur resultierenden Inferenz beigetragen haben:

Foto eines Gänseblümchens mit Feature-Attributionsoverlay
Unterstützte Modelltypen
Die Feature-Attribution wird für alle Arten von Modellen (sowohl AutoML als auch benutzerdefiniert trainiert) und Frameworks (TensorFlow, scikit, XGBoost), BigQuery ML-Modelle und Modalitäten (Bilder, Text, Tabelle, Video) unterstützt.
Wenn Sie die Modellattribution verwenden möchten, konfigurieren Sie Ihr Modell für die Feature-Attribution, wenn Sie das Modell in die Vertex AI Model Registry hochladen oder registrieren.
Darüber hinaus ist für die folgenden Arten von AutoML-Modellen die Feature-Attribution in die Google Cloud Console eingebunden:
- AutoML-Bildmodelle (nur Klassifizierungsmodelle)
- Tabellarische AutoML-Modelle (nur Klassifizierungs- und Regressionsmodelle)
Bei integrierten AutoML-Modelltypen können Sie die Feature-Attribution in der Google Cloud -Konsole während des Trainings aktivieren und die Wichtigkeit des Modell-Features für das Modell insgesamt sowie die Wichtigkeit lokaler Features für Online- und Batch-Vorhersagen aufrufen.
Für nicht integrierte AutoML-Modelltypen können Sie die Feature-Attribution immer noch aktivieren. Exportieren Sie dazu die Modellartefakte und konfigurieren Sie die Feature-Attribution, wenn Sie die Modellartefakte in Vertex AI Model Registry hochladen.
Vorteile
Wenn Sie bestimmte Instanzen prüfen und darüber hinaus Feature-Attributionen in Ihrem Trainings-Dataset erzeugen, erhalten Sie genauere Einblicke in die Funktionsweise Ihres Modells. Beachten Sie die folgenden Vorteile:
Fehlerbehebungsmodelle: Mithilfe von Feature-Attributionen können Probleme in den Daten erkannt werden, die mit den Standardtechniken der Modellbewertung in der Regel nicht ermittelt werden.
So hat z. B. ein Bildpathologiemodell in einem Test-Dataset von Bruströntgenbildern erstaunlich gute Ergebnisse erzielt. Die Feature-Attributionen zeigten auf, dass sich die hohe Genauigkeit des Modells durch die Stiftmarkierungen des Radiologen im Bild ergab. Weitere Informationen zu diesem Beispiel finden Sie im Whitepaper zu AI Explanations.
Modelle optimieren: Sie können weniger wichtige Features identifizieren und entfernen, was zu effizienteren Modellen führt.
Methoden zur Featureattribution
Jede Methode der Feature-Attribution basiert auf Shapley-Werten. Dabei handelt es sich um einen Algorithmus der Spieltheorie, der jedem Spieler in einem Spiel eine Gewichtung für ein bestimmtes Ergebnis zuweist. Auf ML-Modelle angewendet bedeutet dies, dass jedes Modellmerkmal als "Spieler" im Spiel behandelt wird. Vertex Explainable AI weist jedem Feature eine proportionale Gewichtung für das Ergebnis einer bestimmten Inferenz zu.
Methode "Sampled Shapley"
Die Methode Sampled Shapley bietet eine Stichprobenapproximation für exakte Shapley-Werte. Tabellarische AutoML-Modelle verwenden die Methode "Sampled Shapley" für die Merkmalwichtigkeit. Sampled Shapley eignet sich gut für diese Modelle, die Metaensembles von Baumstrukturen und neuronalen Netzwerken darstellen.
Ausführliche Informationen zur Sampled-Shapley-Methode finden Sie im Artikel Bounding the Emulationation Error of Sampling-based Shapley Value Approximation (nur auf Englisch verfügbar).
Methode "Integrierte Gradienten"
Bei der Methode Integrierte Gradienten wird der Gradient der Inferenzausgabe in Bezug auf die Features der Eingabe entlang eines integralen Pfads berechnet.
- Die Gradienten werden in verschiedenen Intervallen eines Skalierungsparameters berechnet. Die Größe jedes Intervalls wird mithilfe der Gauß-Quadratur bestimmt. Stellen Sie sich diesen Skalierungsparameter für Bilddaten als "Schieberegler" vor, der alle Pixel des Bildes auf Schwarz skaliert.
- Die Gradienten sind folgendermaßen eingebunden:
- Das Integral wird mit einem gewichteten Durchschnitt approximiert.
- Das elementweise Produkt der gemittelten Gradienten und der ursprünglichen Eingabe wird berechnet.
Eine intuitive Erklärung dieses Prozesses für Bilder finden Sie im Blogpost Den Eingabefunktionen die Inferenz eines tiefen Netzwerks zuweisen. Die Autoren des ursprünglichen Artikels über integrierte Farbverläufe (Axiomatic Attribution for Deep Networks) zeigen im vorherigen Blogpost, wie die Bilder bei jedem Schritt des Prozesses aussehen.
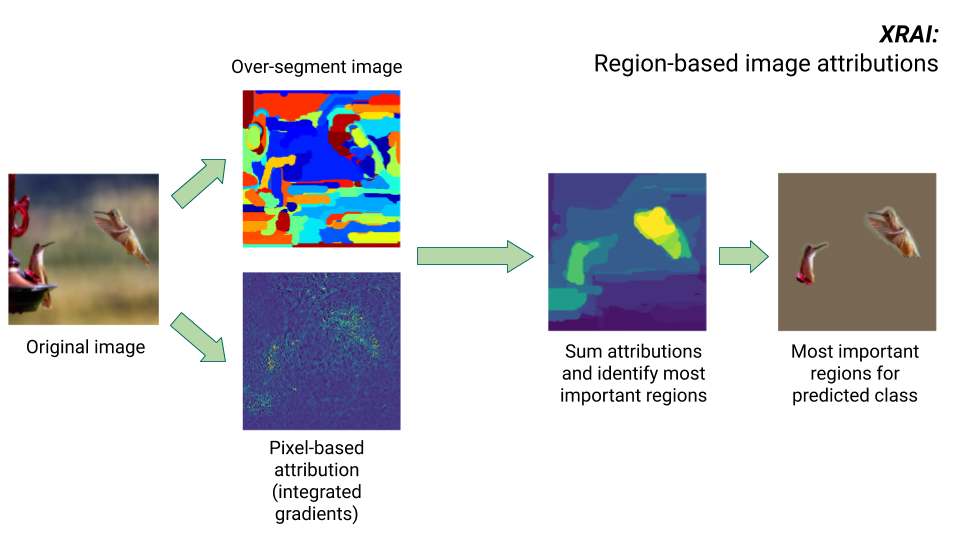
XRAI-Methode
Die Methode XRAI kombiniert die Methode „Integrierte Gradienten“ mit zusätzlichen Schritten, um zu bestimmen, welche Regionen des Bildes am meisten zu einer bestimmten Klasseninferenz beitragen.
- Attribution auf Pixelebene: XRAI führt eine Attribution auf Pixelebene für das Eingabebild durch. In diesem Schritt verwendet XRAI die Methode "Integrierte Gradienten" mit jeweils einer Referenz für Schwarz und für Weiß.
- Übersegmentierung: Unabhängig von der Attribution auf Pixelebene wird das Bild von XRAI übersegmentiert, um ein Flickwerk aus kleinen Regionen zu erstellen. XRAI verwendet zum Erstellen der Bildsegmente die auf Diagrammen beruhende Methode von Felzenszwalb.
- Regionsauswahl: XRAI aggregiert die Attribution auf Pixelebene innerhalb jedes Segments, um die Attributionsdichte zu bestimmen. Anhand dieser Werte ordnet XRAI jedem Segment einen Rang zu und ordnet dann die Segmente vom positivsten zum am wenigsten positiven Segment an. Dadurch wird bestimmt, welche Bereiche des Bildes am auffälligsten sind oder am stärksten zu einer bestimmten Klasseninferenz beitragen.
Methoden zur Featureattribution vergleichen
Vertex Explainable AI bietet drei Methoden für Feature-Attributionen: Sampled Shapley, Integrierte Gradienten und XRAI.
| Methode | Grundlegende Erläuterung | Empfohlene Modelltypen | Beispielanwendungsfälle | Kompatible Vertex-AI-Model-Ressourcen |
|---|---|---|---|---|
| Sampled Shapley | Weist jedem Feature eine Gewichtung für das Ergebnis zu und berücksichtigt verschiedene Varianten der Features. Diese Methode liefert eine Stichprobenapproximation für exakte Shapley-Werte. | Nicht unterscheidbare Modelle, z. B. Ensembles von Baumstrukturen und neuronalen Netzwerken |
|
|
| Integrierte Gradienten | Eine auf Verläufen basierende Methode zur effizienten Berechnung von Feature-Attributionen mit denselben axiomatischen Eigenschaften wie der Shapley-Wert. | Unterscheidbare Modelle, z. B. neuronale Netzwerke Besonders für Modelle mit großen Feature-Bereichen empfohlen. Empfohlen für Bilder mit geringem Kontrast, z. B. Röntgenaufnahmen. |
|
|
| XRAI (eXplanation with Ranked Area Integrals) | Auf Grundlage der Methode "Integrierte Gradienten" werden bei XRAI sich überschneidende Bereiche des Bildes bewertet, um eine Karte mit Ausprägungen zu erstellen, die relevante Regionen des Bildes statt Pixel hervorhebt. | Modelle, die Bildeingaben akzeptieren. Besonders empfohlen für natürliche Bilder, also Szenen aus der realen Welt, die mehrere Objekte enthalten. |
|
|
Einen detaillierteren Vergleich der Attributionsmethoden finden Sie im Whitepaper zu AI Explanations.
Unterscheidbare und nicht unterscheidbare Modelle
In unterscheidbaren Modellen können Sie die Ableitung aller Vorgänge in Ihrer TensorFlow-Grafik berechnen. Diese Eigenschaft ermöglicht die Rückpropagierung bei solchen Modellen. Neuronale Netzwerke sind beispielsweise unterscheidbar. Verwenden Sie die Methode "Integrierte Gradienten", um Feature-Attributionen für unterscheidbare Modelle zu erhalten.
Die Methode "Integrierte Gradienten" funktioniert nicht bei nicht unterscheidbaren Modellen. Hier finden Sie weitere Informationen zur Codierung nicht unterscheidbarer Eingaben, um die Methode "Integrierte Gradienten" nutzen zu können.
Nicht unterscheidbare Modelle enthalten nicht unterscheidbare Vorgänge in der TensorFlow-Grafik, z. B. Vorgänge, die Decodierungs- und Rundungsaufgaben ausführen. Ein Modell, das aus einer Gruppe von Bäumen und neuronalen Netzwerken besteht, ist beispielsweise nicht unterscheidbar. Verwenden Sie die Sampled Shapley-Methode, um Feature-Attributionen für nicht unterscheidbare Modelle zu erhalten. Sampled Shapley funktioniert auch bei unterscheidbaren Modellen, erfordert in diesem Fall jedoch mehr Rechenleistung als nötig.
Konzeptionelle Einschränkungen
Berücksichtigen Sie die folgenden Einschränkungen für Attributionen von Attributen:
Feature-Attributionen, einschließlich der lokalen Merkmalwichtigkeit für AutoML, gelten für einzelne Inferenzen. Die Prüfung der Feature-Attributionen für eine einzelne Inferenz bietet möglicherweise einen guten Einblick, aber die Informationen sind eventuell nicht für die gesamte Klasse dieser einzelnen Instanz oder für das gesamte Modell verallgemeinerbar.
Verallgemeinerbare Informationen zu AutoML-Modellen finden Sie in der Merkmalwichtigkeit des Modells. Für verallgemeinerbare Informationen zu anderen Modellen aggregieren Sie Attributionen für Teilmengen des Datasets oder für das gesamte Dataset.
Obwohl Feature-Attributionen bei der Fehlerbehebung für Modelle hilfreich sein können, geben sie nicht immer deutlich genug an, ob ein Problem durch das Modell oder die Daten entsteht, auf denen das Modell trainiert wird. Gehen Sie nach bestem Wissen vor und diagnostizieren Sie häufige Datenprobleme, um mögliche Ursachen zu minimieren.
Feature-Attributionen unterliegen ähnlichen kontradiktorischen Angriffen wie Inferenz in komplexen Modellen.
Weitere Informationen zu Einschränkungen finden Sie in der Liste der allgemeinen Einschränkungen und im Whitepaper zu AI Explanations.
Verweise
Für die Feature-Attribution basieren die Implementierungen von Sampled Shapley, integrierten Gradienten und XRAI auf den folgenden Referenzen:
- Bounding the Estimation Error of Sampling-based Shapley Value Approximation
- Axiomatic Attribution for Deep Networks
- XRAI: Better Attributions Through Regions
Weitere Informationen zur Implementierung von Vertex Explainable AI finden Sie im Whitepaper zu AI Explanations.
Notebooks
Verwenden Sie die folgenden Notebooks, um mit Vertex Explainable AI zu beginnen:
| Notebook | Explainable-Methode | ML-Framework | Modalität | Task |
|---|---|---|---|---|
| GitHub-Link | beispielbasierte Erklärungen | TensorFlow | Image | Klassifizierungsmodell trainieren, das die Klasse des bereitgestellten Eingabebilds vorhersagt, und Onlineerläuterungen abrufen |
| GitHub-Link | featurebasiert | AutoML | Tabellarisch | Binäres Klassifizierungsmodell trainieren, das vorhersagt, ob ein Bankkunde Termingeld angelegt hat, und Batch-Erklärungen abrufen |
| GitHub-Link | featurebasiert | AutoML | Tabellarisch | Klassifikationsmodell trainieren, das den Typ der Schwertlilienart vorhersagt, und Onlineerklärungen erhalten |
| GitHub-Link | featurebasiert (Sampled Shapley) | scikit-learn | Tabellarisch | Lineares Regressionsmodell trainieren, mit dem Taxipreise vorhergesagt werden, und Onlineerklärungen abrufen |
| GitHub-Link | featurebasiert (integrierte Gradienten) | TensorFlow | Image | Klassifizierungsmodell trainieren, das die Klasse des bereitgestellten Eingabebilds vorhersagt, und Batcherläuterungen abrufen |
| GitHub-Link | featurebasiert (integrierte Gradienten) | TensorFlow | Image | Klassifizierungsmodell trainieren, das die Klasse des bereitgestellten Eingabebilds vorhersagt, und Onlineerläuterungen abrufen |
| GitHub-Link | featurebasiert (integrierte Gradienten) | TensorFlow | Tabellarisch | Regressionsmodell trainieren, das den Medianpreis eines Hauses vorhersagt, und Batch-Erklärungen abrufen |
| GitHub-Link | featurebasiert (integrierte Gradienten) | TensorFlow | Tabellarisch | Regressionsmodell trainieren, das den Medianpreis eines Hauses vorhersagt, und Onlineerklärungen abrufen |
| GitHub-Link | featurebasiert (Sampled Shapley) | TensorFlow | text | Ein LSTM-Modell trainieren, das Filmkritiken anhand des Rezensionstextes als positiv oder negativ klassifiziert, und Online-Erläuterungen erhalten |
Bildungsressourcen
Die folgenden Ressourcen bieten weitere nützliche Lehrmaterialien:
- Explainable AI für Praktiker
- Interpretable Machine Learning: Shapley Values
- Integrated Gradients GitHub Repository von Ankur Taly
- Einführung in Shapley-Werte
Nächste Schritte
- Modell für featurebasierte Erläuterungen konfigurieren
- Modell für beispielbasierte Erläuterungen konfigurieren
- Featurewichtigkeit für tabellarische AutoML-Modelle ansehen