I modelli di machine learning sono spesso "scatole nere"; anche i loro progettisti non possono spiegare come o perché un modello ha prodotto un'inferenza specifica. Vertex Explainable AI offre spiegazioni basate su caratteristiche ed esempi per comprendere meglio le decisioni prese dal modello.
Sapere come si comporta un modello e come il suo set di dati di addestramento lo influenza offre a chiunque crei o utilizzi il machine learning nuove capacità per migliorare i modelli, aumentare la fiducia nelle loro inferenze e capire quando e perché le cose vanno male.
Le spiegazioni basate su esempi
Nel caso delle spiegazioni basate su esempi, Vertex AI utilizza la ricerca del vicino più prossimo per restituire un elenco degli esempi (di solito dal set di addestramento) più simili all'input. Poiché in genere ci aspettiamo che input simili producano inferenze simili, possiamo utilizzare queste spiegazioni per esplorare e spiegare il comportamento del nostro modello.
Le spiegazioni basate su esempi possono essere utili in diversi scenari:
Migliora i tuoi dati o il tuo modello: uno dei casi d'uso principali delle spiegazioni basate su esempi è aiutarti a capire perché il tuo modello ha commesso determinati errori nelle sue inferenze e utilizzare queste informazioni per migliorare i tuoi dati o il tuo modello. Per farlo, seleziona innanzitutto i dati di test che ti interessano. Ciò potrebbe essere determinato dalle esigenze aziendali o da euristiche come i dati in cui il modello ha commesso gli errori più gravi.
Ad esempio, supponiamo di avere un modello che classifica le immagini come uccelli o aerei e che classifica in modo errato l'uccello seguente come aereo con un'alta confidenza. Utilizza le spiegazioni basate su esempi per recuperare immagini simili dal set di addestramento e capire cosa sta succedendo.

Poiché tutte le spiegazioni sono sagome scure della classe di aerei, è un segnale per ottenere più sagome di uccelli.
Tuttavia, se le spiegazioni provenivano principalmente dalla classe degli uccelli, è un segnale che il nostro modello non riesce ad apprendere le relazioni anche quando i dati sono ricchi e dovremmo prendere in considerazione l'aumento della complessità del modello (ad esempio, l'aggiunta di più livelli).
Interpretare nuovi dati: supponi, per il momento, che il tuo modello sia stato addestrato per classificare uccelli e aerei, ma nel mondo reale il modello incontra anche immagini di aquiloni, droni ed elicotteri. Se il tuo set di dati dei vicini più prossimi include alcune immagini etichettate di aquiloni, droni ed elicotteri, puoi utilizzare spiegazioni basate su esempi per classificare nuove immagini applicando l'etichetta che si verifica più frequentemente dei suoi vicini più prossimi. Ciò è possibile perché prevediamo che la rappresentazione latente degli aquiloni sia diversa da quella degli uccelli o degli aerei e più simile agli aquiloni etichettati nel set di dati dei vicini più prossimi.
Rileva le anomalie: intuitivamente, se un'istanza è lontana da tutti i dati nel set di addestramento, è probabile che sia un outlier. È noto che le reti neurali sono eccessivamente sicure dei propri errori, mascherandoli. Il monitoraggio dei modelli utilizzando le spiegazioni basate su esempi aiuta a identificare gli outlier più gravi.
Apprendimento attivo: le spiegazioni basate su esempi possono aiutarti a identificare le istanze che potrebbero trarre vantaggio dall'etichettatura umana. Ciò è particolarmente utile se l'etichettatura è lenta o costosa, in quanto ti consente di ottenere il set di dati più ricco possibile da risorse di etichettatura limitate.
Ad esempio, supponiamo di avere un modello che classifica un paziente come affetto da raffreddore o influenza. Se un paziente viene classificato come affetto da influenza e tutte le spiegazioni basate su esempi provengono dalla classe dell'influenza, il medico può avere maggiore fiducia nell'inferenza del modello senza dover esaminare più da vicino la situazione. Tuttavia, se alcune spiegazioni provengono dalla classe dell'influenza e altre da quella del raffreddore, vale la pena consultare un medico. In questo modo, si otterrà un set di dati in cui le istanze difficili hanno più etichette, il che rende più facile per i modelli downstream apprendere relazioni complesse.
Per creare un modello che supporti le spiegazioni basate su esempi, consulta Configurazione delle spiegazioni basate su esempi.
Tipi di modelli supportati
È supportato qualsiasi modello TensorFlow in grado di fornire un incorporamento (rappresentazione latente) per gli input. I modelli basati su alberi, come gli alberi decisionali, non sono supportati. I modelli di altri framework, come PyTorch o XGBoost, non sono ancora supportati.
Per le reti neurali profonde, in genere si presume che i livelli superiori (più vicini al livello di output) abbiano appreso qualcosa di "significativo" e, pertanto, il penultimo livello viene spesso scelto per gli incorporamenti. Sperimenta con alcuni livelli diversi, esamina gli esempi che ricevi e scegli quello che preferisci in base a misure quantitative (corrispondenza di classe) o qualitative (aspetto sensato).
Per una dimostrazione su come estrarre gli incorporamenti da un modello TensorFlow ed eseguire la ricerca del vicino più prossimo, consulta il notebook di spiegazione basata sugli esempi.
Spiegazioni basate sulle caratteristiche
Vertex Explainable AI integra le attribuzioni delle caratteristiche in Vertex AI. Questa sezione fornisce una breve panoramica concettuale dei metodi di attribuzione delle caratteristiche disponibili con Vertex AI.
L'attribuzione delle caratteristiche indica in che misura ciascuna caratteristica del modello ha contribuito alle inferenze per ogni istanza specificata. Quando richiedi inferenze, ottieni valori appropriati per il tuo modello. Quando richiedi le spiegazioni, ottieni le inferenze insieme alle informazioni sull'attribuzione delle funzionalità.
Le attribuzioni delle funzionalità funzionano con i dati tabulari e includono funzionalità di visualizzazione integrate per i dati delle immagini. Considera i seguenti esempi:
Una rete neurale profonda viene addestrata per prevedere la durata di una corsa in bicicletta, in base ai dati meteo e ai dati precedenti di ride sharing. Se richiedi solo inferenze da questo modello, ottieni le durate previste delle corse in bicicletta in numero di minuti. Se richiedi le spiegazioni, ricevi la durata prevista del viaggio in bicicletta, insieme a un punteggio di attribuzione per ogni caratteristica nella richiesta di spiegazioni. I punteggi di attribuzione mostrano in che misura la funzionalità ha influito sulla variazione del valore di inferenza rispetto al valore di base che specifichi. Scegli una base di riferimento significativa e adatta al tuo modello. In questo caso, la durata mediana della corsa in bicicletta. Puoi tracciare i punteggi di attribuzione delle caratteristiche per vedere quali hanno contribuito maggiormente all'inferenza risultante:
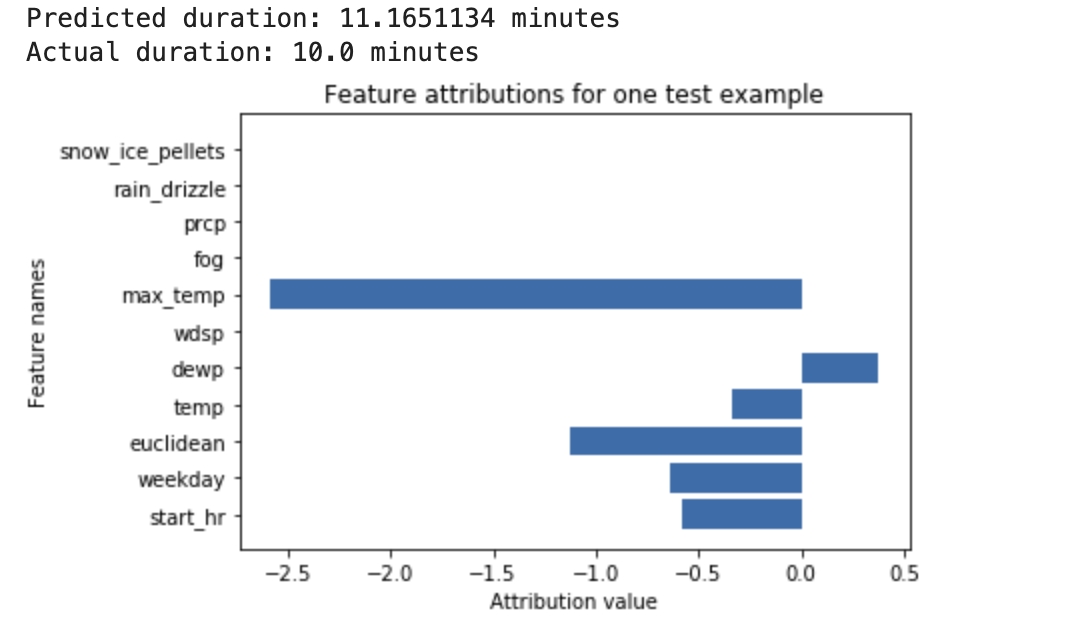
Un modello di classificazione delle immagini viene addestrato per prevedere se una determinata immagine contiene un cane o un gatto. Se richiedi inferenze da questo modello su un nuovo set di immagini, ricevi un'inferenza per ogni immagine ("cane" o "gatto"). Se richiedi le spiegazioni, ricevi la classe prevista insieme a un overlay per l'immagine, che mostra i pixel dell'immagine che hanno contribuito maggiormente all'inferenza risultante:

Foto di un gatto con overlay di attribuzione delle funzionalità 
Foto di un cane con overlay di attribuzione delle funzionalità Un modello di classificazione delle immagini è addestrato a prevedere la specie di un fiore nell'immagine. Se richiedi inferenze da questo modello su un nuovo insieme di immagini, ricevi un'inferenza per ogni immagine ("margherita" o "tarassaco"). Se richiedi le spiegazioni, ottieni la classe prevista insieme a un overlay per l'immagine, che mostra le aree dell'immagine che hanno contribuito maggiormente all'inferenza risultante:

Una foto di una margherita con overlay di attribuzione della funzionalità
Tipi di modelli supportati
L'attribuzione delle funzionalità è supportata per tutti i tipi di modelli (sia AutoML che con addestramento personalizzato), framework (TensorFlow, scikit, XGBoost), modelli BigQuery ML e modalità (immagini, testo, tabellare, video).
Per utilizzare l'attribuzione delle funzionalità, configura il modello per l'attribuzione delle funzionalità quando carichi o registri il modello in Vertex AI Model Registry.
Inoltre, per i seguenti tipi di modelli AutoML, l'attribuzione delle funzionalità è integrata nella console Google Cloud :
- Modelli di immagini AutoML (solo modelli di classificazione)
- Modelli tabulari AutoML (solo modelli di classificazione e regressione)
Per i tipi di modelli AutoML integrati, puoi attivare l'attribuzione delle funzionalità nella console Google Cloud durante l'addestramento e visualizzare l'importanza delle funzionalità del modello per il modello nel complesso e l'importanza delle funzionalità locali per le inferenze online e batch.
Per i tipi di modelli AutoML non integrati, puoi comunque attivare l'attribuzione delle funzionalità esportando gli artefatti del modello e configurando l'attribuzione delle funzionalità quando carichi gli artefatti del modello in Vertex AI Model Registry.
Vantaggi
Se esamini istanze specifiche e aggreghi anche le attribuzioni delle caratteristiche nel set di dati di addestramento, puoi ottenere informazioni più approfondite sul funzionamento del modello. Considera i seguenti vantaggi:
Debug dei modelli: le attribuzioni delle caratteristiche possono aiutare a rilevare problemi nei dati che le tecniche standard di valutazione dei modelli di solito non rilevano.
Ad esempio, un modello di patologia delle immagini ha ottenuto risultati sospettosamente buoni su un set di dati di test di radiografie del torace. L'attribuzione delle caratteristiche ha rivelato che l'elevata precisione del modello dipendeva dai segni della penna del radiologo nell'immagine. Per ulteriori dettagli su questo esempio, consulta il white paper su AI Explanations.
Ottimizzazione dei modelli: puoi identificare e rimuovere le funzionalità meno importanti, il che può portare a modelli più efficienti.
Metodi di attribuzione delle caratteristiche
Ogni metodo di attribuzione delle caratteristiche si basa sui valori di Shapley, un algoritmo di teoria dei giochi cooperativi che assegna il merito a ogni giocatore di una partita per un risultato particolare. Applicato ai modelli di machine learning, ciò significa che ogni caratteristica del modello viene trattata come un "giocatore" nel gioco. Vertex Explainable AI assegna un credito proporzionale a ogni caratteristica per il risultato di una particolare inferenza.
Metodo del valore di Shapley campionato
Il metodo Shapley campionato fornisce un'approssimazione di campionamento dei valori di Shapley esatti. I modelli AutoML tabulari utilizzano il metodo del valore di Shapley campionato per l'importanza delle funzionalità. Il valore di Shapley campione funziona bene per questi modelli, che sono meta-ensemble di alberi e reti neurali.
Per informazioni dettagliate sul funzionamento del metodo di Shapley basato sul campionamento, leggi l'articolo Bounding the Estimation Error of Sampling-based Shapley Value Approximation.
Metodo dei gradienti integrati
Nel metodo gradienti integrati, il gradiente dell'output di inferenza viene calcolato rispetto alle caratteristiche dell'input, lungo un percorso integrale.
- I gradienti vengono calcolati a intervalli diversi di un parametro di scalabilità. La dimensione di ogni intervallo è determinata utilizzando la regola di quadratura gaussiana. (Per i dati delle immagini, immagina questo parametro di scala come un "cursore" che ridimensiona tutti i pixel dell'immagine in nero.)
- I gradienti vengono integrati nel seguente modo:
- L'integrale viene approssimato utilizzando una media ponderata.
- Viene calcolato il prodotto elemento per elemento dei gradienti mediati e dell'input originale.
Per una spiegazione intuitiva di questo processo applicato alle immagini, consulta il post del blog "Attributing a deep network's inference to its input features". Gli autori dell'articolo originale sui gradienti integrati (Axiomatic Attribution for Deep Networks) mostrano nel post del blog precedente l'aspetto delle immagini in ogni fase del processo.
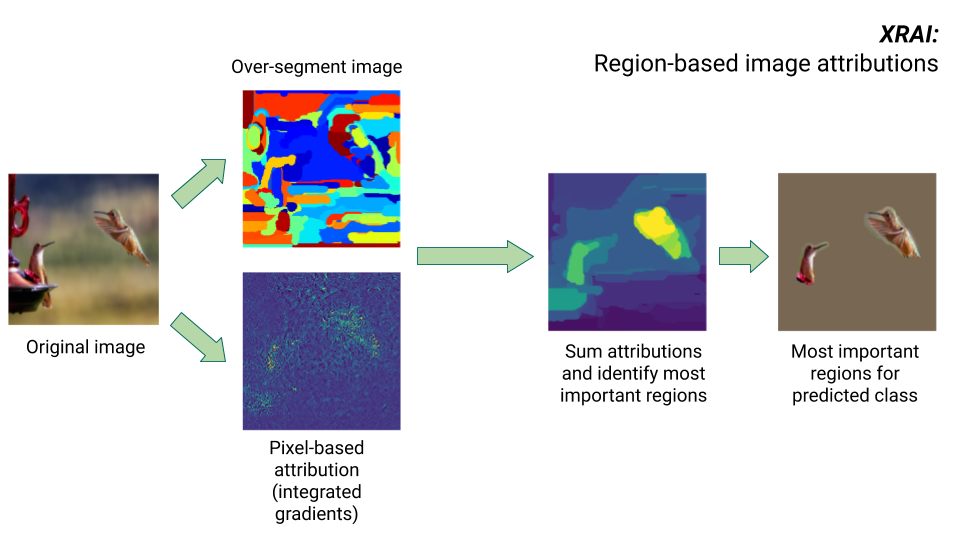
Metodo XRAI
Il metodo XRAI combina il metodo dei gradienti integrati con passaggi aggiuntivi per determinare quali regioni dell'immagine contribuiscono maggiormente all'inferenza di una determinata classe.
- Attribuzione a livello di pixel: XRAI esegue l'attribuzione a livello di pixel per l'immagine di input. In questo passaggio, XRAI utilizza il metodo dei gradienti integrati con un'immagine di riferimento nera e una bianca.
- Sovrasegmentazione: indipendentemente dall'attribuzione a livello di pixel, XRAI sovrasegmenta l'immagine per creare un patchwork di piccole regioni. XRAI utilizza il metodo basato su grafi di Felzenswalb per creare i segmenti dell'immagine.
- Selezione della regione: XRAI aggrega l'attribuzione a livello di pixel all'interno di ogni segmento per determinare la densità di attribuzione. Utilizzando questi valori, XRAI classifica ogni segmento e poi li ordina dal più positivo al meno positivo. Questo determina quali aree dell'immagine sono più salienti o contribuiscono maggiormente a una determinata inferenza di classe.
Confrontare i metodi di attribuzione delle caratteristiche
Vertex Explainable AI offre tre metodi da utilizzare per le attribuzioni delle caratteristiche: valori di Shapley campionati, gradienti integrati e XRAI.
| Metodo | Spiegazione di base | Tipi di modello consigliati | Esempi di casi d'uso | Risorse Model Vertex AI compatibili |
|---|---|---|---|---|
| Valore di Shapley campionato | Assegna il credito per il risultato a ciascuna caratteristica e considera diverse permutazioni delle caratteristiche. Questo metodo fornisce un'approssimazione di campionamento dei valori di Shapley esatti. | Modelli non differenziabili, come insiemi di alberi e reti neurali |
|
|
| Gradienti integrati | Un metodo basato sui gradienti per calcolare in modo efficiente le attribuzioni delle caratteristiche con le stesse proprietà assiomatiche del valore di Shapley. | Modelli differenziabili, come le reti neurali. Consigliato soprattutto
per i modelli con spazi delle funzionalità di grandi dimensioni. Consigliato per immagini a basso contrasto, come le radiografie. |
|
|
| XRAI (eXplanation with Ranked Area Integrals) | In base al metodo dei gradienti integrati, XRAI valuta le regioni sovrapposte dell'immagine per creare una mappa di salienza, che evidenzia le regioni pertinenti dell'immagine anziché i pixel. | Modelli che accettano input immagine. Consigliato soprattutto per le immagini naturali, ovvero qualsiasi scena del mondo reale che contenga più oggetti. |
|
|
Per un confronto più approfondito dei metodi di attribuzione, consulta il white paper AI Explanations.
Modelli differenziabili e non differenziabili
Nei modelli differenziabili, puoi calcolare la derivata di tutte le operazioni nel grafico TensorFlow. Questa proprietà contribuisce a rendere possibile la backpropagation in questi modelli. Ad esempio, le reti neurali sono differenziabili. Per ottenere attribuzioni delle funzionalità per i modelli differenziabili, utilizza il metodo dei gradienti integrati.
Il metodo dei gradienti integrati non funziona per i modelli non differenziabili. Scopri di più sulla codifica degli input non differenziabili per utilizzare il metodo dei gradienti integrati.
I modelli non differenziabili includono operazioni non differenziabili nel grafico TensorFlow, ad esempio operazioni che eseguono attività di decodifica e arrotondamento. Ad esempio, un modello creato come insieme di alberi e reti neurali non è differenziabile. Per ottenere le attribuzioni delle caratteristiche per i modelli non differenziabili, utilizza il metodo Shapley campionato. Sampled Shapley funziona anche su modelli differenziabili, ma in questo caso è più costoso dal punto di vista computazionale del necessario.
Limitazioni concettuali
Tieni presenti le seguenti limitazioni delle attribuzioni delle funzionalità:
Le attribuzioni delle funzionalità, inclusa l'importanza delle funzionalità locali per AutoML, sono specifiche per le singole inferenze. L'ispezione delle attribuzioni delle caratteristiche per una singola inferenza può fornire informazioni utili, ma queste potrebbero non essere generalizzabili all'intera classe per quella singola istanza o all'intero modello.
Per ottenere informazioni più generalizzabili per i modelli AutoML, consulta l'importanza delle funzionalità del modello. Per ottenere informazioni più generalizzabili per altri modelli, aggregare le attribuzioni in sottoinsiemi del set di dati o nell'intero set di dati.
Sebbene le attribuzioni delle caratteristiche possano essere utili per il debug del modello, non indicano sempre chiaramente se un problema deriva dal modello o dai dati su cui viene addestrato il modello. Usa il buonsenso e diagnostica i problemi comuni relativi ai dati per restringere lo spazio delle potenziali cause.
Le attribuzioni delle caratteristiche sono soggette ad attacchi avversariali simili a quelli delle inferenze nei modelli complessi.
Per ulteriori informazioni sulle limitazioni, consulta l'elenco delle limitazioni di alto livello e il white paper sulle spiegazioni dell'AI.
Riferimenti
Per l'attribuzione delle funzionalità, le implementazioni di valori di Shapley campionati, gradienti integrati e XRAI si basano rispettivamente sui seguenti riferimenti:
- Bounding the Estimation Error of Sampling-based Shapley Value Approximation
- Attribuzione assiomatica per reti profonde
- XRAI: attribuzioni migliori tramite le regioni
Scopri di più sull'implementazione di Vertex Explainable AI leggendo il white paper sulle spiegazioni dell'AI.
Notebook
Per iniziare a utilizzare Vertex Explainable AI, utilizza questi blocchi note:
| Notebook | Metodo di spiegabilità | Framework ML | Modalità | Attività |
|---|---|---|---|---|
| Link GitHub | spiegazioni basate su esempi | TensorFlow | immagine | Addestra un modello di classificazione che preveda la classe dell'immagine di input fornita e ottieni spiegazioni online. |
| Link GitHub | basato sulle funzionalità | AutoML | tabulare | Addestra un modello di classificazione binaria che prevede se un cliente bancario ha acquistato un deposito a termine e ottieni spiegazioni batch |
| Link GitHub | basato sulle funzionalità | AutoML | tabulare | Addestra un modello di classificazione che preveda il tipo di specie di fiore di Iris e ottieni spiegazioni online |
| Link GitHub | basato sulle caratteristiche (valore di Shapley campionato) | scikit-learn | tabulare | Addestrare un modello di regressione lineare che preveda le tariffe dei taxi e ottenere spiegazioni online |
| Link GitHub | basate sulle caratteristiche (gradienti integrati) | TensorFlow | immagine | Addestra un modello di classificazione che preveda la classe dell'immagine di input fornita e ottieni spiegazioni batch |
| Link GitHub | basate sulle caratteristiche (gradienti integrati) | TensorFlow | immagine | Addestra un modello di classificazione che preveda la classe dell'immagine di input fornita e ottieni spiegazioni online. |
| Link GitHub | basate sulle caratteristiche (gradienti integrati) | TensorFlow | tabulare | Addestra un modello di regressione che preveda il prezzo mediano di una casa e ottieni spiegazioni batch |
| Link GitHub | basate sulle caratteristiche (gradienti integrati) | TensorFlow | tabulare | Addestra un modello di regressione che preveda il prezzo mediano di una casa e ricevi spiegazioni online |
| Link GitHub | basato sulle caratteristiche (valore di Shapley campionato) | TensorFlow | testo | Addestra un modello LSTM che classifichi le recensioni dei film come positive o negative utilizzando il testo della recensione e ottieni spiegazioni online |
Risorse didattiche
Le seguenti risorse forniscono ulteriore materiale didattico utile:
- Explainable AI for Practitioners
- Interpretable Machine Learning: Shapley values
- Repository GitHub di Integrated Gradients di Ankur Taly.
- Introduzione ai valori di Shapley
Passaggi successivi
- Configurare il modello per le spiegazioni basate sulle caratteristiche
- Configurare il modello per le spiegazioni basate su esempi
- Visualizza l'importanza delle funzionalità per i modelli AutoML tabulari.