In diesem Leitfaden wird der konzeptionelle Kontext beschrieben, der erforderlich ist, um eine auf einer virtuellen Maschine (VM) basierende Arbeitslast in einem Air-Gap-Cluster von Google Distributed Cloud (GDC) auf Bare Metal mit einer VM-Laufzeit bereitzustellen. Die Arbeitslast in diesem Leitfaden ist eine Beispielplattform für ein Ticketsystem, die auf lokaler Hardware verfügbar ist.
Architektur
Ressourcenhierarchie
In GDC stellen Sie die Komponenten des Ticketsystems in einer dedizierten Mandantenorganisation für das Operations-Team bereit, die mit einer Kundenorganisation identisch ist. Eine Organisation ist eine Sammlung von Clustern, Infrastrukturressourcen und Anwendungsarbeitslasten, die gemeinsam verwaltet werden. Jede Organisation in einer GDC-Instanz verwendet einen dedizierten Satz von Servern, was eine starke Isolation zwischen Mandanten ermöglicht. Weitere Informationen zur Infrastruktur finden Sie unter Zugriffsgrenzen entwerfen.
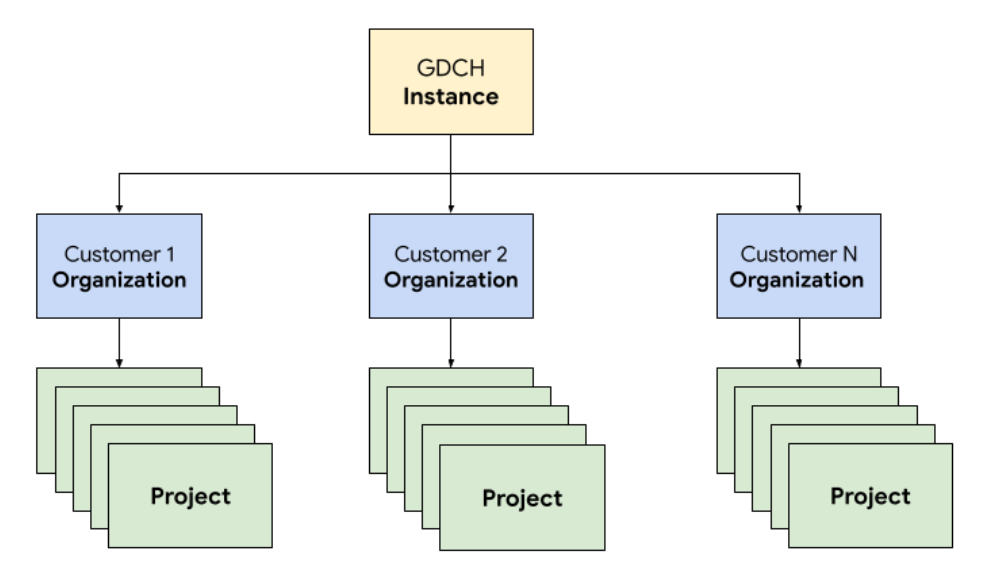
Außerdem stellen Sie die Ressourcen des Ticketsystems zusammen in einem Projekt bereit und verwalten sie dort. Dies bietet eine logische Isolation innerhalb einer Organisation durch Software-Richtlinien und die Durchsetzung von Richtlinien. Ressourcen in einem Projekt sind dazu gedacht, Komponenten zu koppeln, die während ihres Lebenszyklus zusammenbleiben müssen.
Das Ticketsystem folgt einer dreistufigen Architektur, die auf einem Load-Balancer basiert, um den Traffic über Anwendungsserver zu leiten, die eine Verbindung zu einem Datenbankserver herstellen, auf dem persistente Daten gespeichert werden.
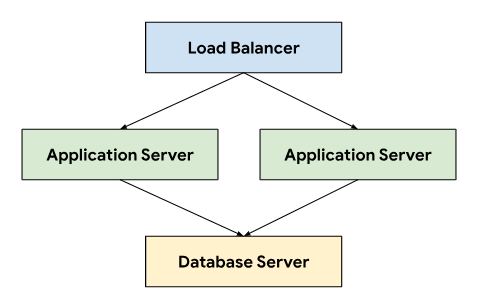
Diese Architektur ermöglicht Skalierbarkeit und Wartungsfreundlichkeit, da jede Ebene unabhängig entwickelt und gewartet werden kann. Außerdem wird eine klare Trennung der Anliegen erreicht, was die Fehlersuche und ‑behebung vereinfacht. Wenn Sie diese Ebenen in einem GDC-Projekt kapseln, können Sie Komponenten wie Ihre Anwendungs- und Datenbankserver gemeinsam bereitstellen und verwalten.
Netzwerk
Wenn Sie das Ticketsystem in einer Produktionsumgebung ausführen, müssen Sie mindestens zwei Anwendungsserver bereitstellen, um im Falle eines Knotenausfalls eine hohe Verfügbarkeit zu erreichen. In Kombination mit einem Load Balancer ermöglicht diese Topologie auch die Verteilung der Last auf mehrere Maschinen, um die Anwendung horizontal zu skalieren. Die Kubernetes-native Plattform von GDC nutzt Cloud Service Mesh, um Traffic sicher an die Anwendungsserver weiterzuleiten, aus denen das Ticketsystem besteht.
Cloud Service Mesh ist eine Implementierung von Google, die auf dem Open-Source-Projekt basiert, mit dem Dienste verwaltet, beobachtet und geschützt werden. Die folgenden Funktionen von Cloud Service Mesh werden genutzt, um das Ticketsystem auf GDC zu hosten:
- Lastenausgleich: In Cloud Service Mesh wird der Trafficfluss von der Infrastrukturskalierung entkoppelt. Dadurch werden viele Funktionen zur Trafficverwaltung möglich, darunter dynamisches Anfragerouting. Das Ticketsystem erfordert persistente Clientverbindungen. Daher aktivieren wir die Sitzungstreue mit
DestinationRules, um das Traffic-Routingverhalten zu konfigurieren.
TLS-Terminierung: Cloud Service Mesh stellt Ingress-Gateways mit TLS-Zertifikaten bereit und bietet Transportauthentifizierung im Cluster über mTLS (Mutual Transport Layer Security), ohne dass Anwendungscode geändert werden muss.
Wiederherstellung nach Fehlern: Cloud Service Mesh bietet eine Reihe wichtiger Funktionen zur Wiederherstellung nach Fehlern, darunter Zeitüberschreitungen, Unterbrechungen der Netzwerkverbindung, aktive Systemdiagnosen und begrenzte Wiederholungsversuche.
Im Kubernetes-Cluster verwenden wir standardmäßige Service-Objekte, um die Anwendungs- und Datenbankserver auf abstrakte Weise für das Netzwerk verfügbar zu machen. Dienste bieten eine praktische Möglichkeit, Instanzen mithilfe eines Selektors anzusprechen und die Namensauflösung im Cluster mithilfe eines clusterfähigen DNS-Servers zu ermöglichen.
apiVersion: v1
kind: Service
metadata:
name: http-ingress
spec:
selector:
app.kubernetes.io/component: application-server
ports:
- name: http
port: 80
---
apiVersion: v1
kind: Service
metadata:
name: database-ingress
spec:
selector:
app.kubernetes.io/component: database-server
ports:
- name: mysql
port: 3306
Compute
Das Ticketsystem empfiehlt die Verwendung von Bare-Metal- oder virtuellen Maschinen für das Hosting von On-Premise-Installationen. Wir haben die GDC-VM-Verwaltung (Virtual Machine) verwendet, um sowohl die Anwendungs- als auch die Datenbankserver als VM-Arbeitslasten bereitzustellen. Durch das Definieren von Kubernetes-Ressourcen konnten wir sowohl VirtualMachine als auch VirtualMachineDisk angeben, um Ressourcen an unsere Anforderungen für die verschiedenen Arten von Servern anzupassen. Mit VirtualMachineExternalAccess können wir die Datenübertragung in und aus der VM konfigurieren.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineDisk
metadata:
name: vm1-boot-disk
spec:
size: 100G
source:
image:
name: ts-ticketing-system-app-server-2023-08-18-203258
namespace: vm-system
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachine
metadata:
labels:
app.kubernetes.io/component: application-server
name: vm1
namespace: support
spec:
compute:
vcpus: 8
memory: 12G
disks:
- boot: true
virtualMachineDiskRef:
name: vm1-boot-disk
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineExternalAccess
metadata:
name: vm1
namespace: support
spec:
enabled: true
ports:
- name: ssh
protocol: TCP
port: 22
Für das Gastbetriebssystem-Image haben wir ein benutzerdefiniertes Image erstellt, das unseren Anforderungen an Compliance und Sicherheit entspricht. Die Verbindung zu laufenden VM-Instanzen ist über SSH mit VirtualMachineAccessRequest möglich. So können wir die Möglichkeit, eine Verbindung zu VMs herzustellen, durch Kubernetes RBAC einschränken und müssen keine lokalen Nutzerkonten in den benutzerdefinierten Images erstellen. In der Zugriffsanfrage wird auch eine Gültigkeitsdauer (Time-to-Live, TTL) definiert, mit der zeitbasierte Zugriffsanfragen für die Verwaltung von VMs möglich sind, die automatisch ablaufen.
Automatisierung
Als wichtiges Ergebnis dieses Projekts haben wir ein Verfahren zum wiederholbaren Installieren von Instanzen des Ticketsystems entwickelt, das eine umfassende Automatisierung ermöglicht und Konfigurationsabweichungen zwischen Bereitstellungen reduziert.
Release-Pipeline
Die Anpassung der Anwendungs- und Datenbankserver-Images beginnt mit einem Basis-Betriebssystem-Image. Das Basis-Image wird nach Bedarf geändert, um die für jedes Server-Image erforderlichen Abhängigkeiten zu installieren. Wir haben ein Basis-Betriebssystemimage ausgewählt, weil es häufig für das Hosten von Ticketsystemen in lokalen Installationen verwendet wird. Dieses Basis-Betriebssystem-Image bietet auch die erforderlichen Sicherheitsfunktionen, um die Security Technical Implementation Guides (STIGs) zu erfüllen, die für die Bereitstellung eines konformen Images erforderlich sind, das den NIST-800-53-Kontrollen entspricht.
In unserer CI-Pipeline (Continuous Integration) wurde der folgende Workflow verwendet, um Anwendungs- und Datenbankserver-Images anzupassen:
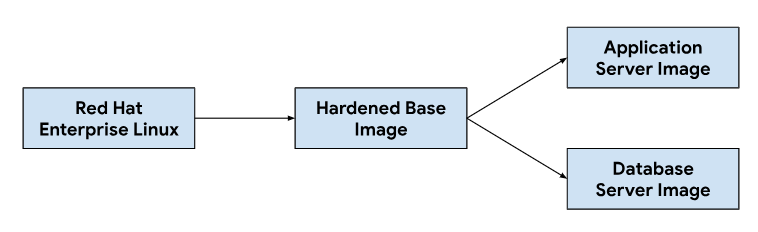
Wenn Entwickler Änderungen an den Anpassungsskripts oder Bildabhängigkeiten vornehmen, wird in unseren CI-Tools ein automatisierter Workflow ausgelöst, um einen neuen Satz von Bildern zu generieren, die in GDC-Releases enthalten sind. Im Rahmen der Image-Erstellung aktualisieren wir auch die Betriebssystemabhängigkeiten (yum update) und komprimieren das Image, um die für die Übertragung von Images in Kundenumgebungen erforderliche Image-Größe zu reduzieren.
Softwareentwicklungszyklus
Der Software-Entwicklungslebenszyklus (Software Development Life Cycle, SDLC) ist ein Prozess, der Organisationen bei der Planung, Erstellung, dem Testen und der Bereitstellung von Software unterstützt. Durch die Einhaltung eines klar definierten SDLC stellen Unternehmen sicher, dass Software auf konsistente und wiederholbare Weise entwickelt wird, und können potenzielle Probleme frühzeitig erkennen. Neben der Erstellung von Images in unserer Continuous Integration-Pipeline (CI) haben wir auch Umgebungen für die Entwicklung und das Staging von Vorabversionen des Ticketsystems für Tests und Qualitätssicherung definiert.
Durch die Bereitstellung einer separaten Instanz des Ticketsystems für jedes GDC-Projekt konnten wir Änderungen isoliert testen, ohne bestehende Instanzen in derselben GDC-Instanz zu beeinträchtigen. Wir haben die ResourceManager API verwendet, um Projekte deklarativ mit Kubernetes-Ressourcen zu erstellen und zu löschen.
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-dev
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-qa
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-staging
In Kombination mit der Paketierung von Diagrammen und der Verwaltung von Infrastruktur wie virtuellen Maschinen als Code können Entwickler schnell Änderungen vornehmen und neue Funktionen neben Produktionsinstanzen testen. Die deklarative API ermöglicht es auch, dass automatisierte Testausführungs-Frameworks regelmäßige Regressionstests durchführen und vorhandene Funktionen überprüfen.
Bedienbarkeit
Die Bedienbarkeit beschreibt, wie einfach ein System bedient und gewartet werden kann. Sie ist ein wichtiger Aspekt beim Design jeder Softwareanwendung. Ein effektives Monitoring trägt zur Betriebsfähigkeit bei, da Probleme erkannt und behoben werden können, bevor sie sich erheblich auf das System auswirken. Mit dem Monitoring lassen sich auch Verbesserungsmöglichkeiten ermitteln und eine Baseline für Service Level Objectives (SLO) festlegen.
Monitoring
Wir haben das Ticketsystem in die bestehende GDC-Infrastruktur für die Beobachtbarkeit integriert, einschließlich Protokollierung und Messwerten. Für Messwerte stellen wir HTTP-Endpunkte von jeder VM zur Verfügung, über die die Anwendung Datenpunkte abrufen kann, die von den Anwendungs- und Datenbankservern generiert werden. Diese Endpunkte umfassen Systemmesswerte, die mit dem Application Node Exporter erfasst werden, und anwendungsspezifische Messwerte.
Da in jeder VM Endpunkte verfügbar sind, haben wir das Abrufverhalten der Anwendung mit der benutzerdefinierten Ressource MonitoringTarget konfiguriert, um das Scraping-Intervall zu definieren und die Messwerte zu annotieren.
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringTarget
metadata:
name: database-monitor
spec:
podMetricsEndpoints:
path:
value: /metrics
port:
annotation: application.io/dbMetrics
scrapeInterval: 60s
Für das Logging haben wir in jeder VM einen Logging- und Messwertprozessor installiert und konfiguriert, um relevante Logs zu erfassen und Logdaten an das Logging-Tool zu senden. Dort werden die Daten indexiert und über die Monitoring-Instanz abgefragt. Audit-Logs werden an einen speziellen Endpunkt weitergeleitet, der für die Compliance mit einer verlängerten Aufbewahrungsdauer konfiguriert ist. Containerbasierte Anwendungen können die benutzerdefinierten Ressourcen LoggingTarget und AuditLoggingTarget verwenden, um die Logging-Pipeline anzuweisen, Logs von bestimmten Diensten in Ihrem Projekt zu erfassen.
Anhand der Daten, die in den Logging- und Monitoring-Prozessoren verfügbar sind, haben wir mit der benutzerdefinierten Ressource MonitoringRule Benachrichtigungen erstellt. So können wir diese Konfiguration als Code in unserem Chart-Paket verwalten. Durch die Verwendung einer deklarativen API zum Definieren von Benachrichtigungen und Dashboards können wir diese Konfiguration auch in unserem Code-Repository speichern und dieselben Code-Review- und Continuous Integration-Prozesse durchlaufen, die wir für alle anderen Codeänderungen verwenden.
Fehlermodi
Bei den ersten Tests wurden mehrere ressourcenbezogene Fehlermodi erkannt, die uns geholfen haben, zu priorisieren, welche Messwerte und Benachrichtigungen zuerst hinzugefügt werden sollten. Wir haben zuerst die hohe Arbeitsspeicher- und Festplattennutzung überwacht, da eine Fehlkonfiguration der Datenbank anfangs dazu führte, dass Puffertabellen den gesamten verfügbaren Arbeitsspeicher belegten und durch zu viel Logging die angehängte nichtflüchtige Speicherfestplatte gefüllt wurde. Nachdem wir die Größe des Speicherpuffers angepasst und eine Strategie für die Logrotation implementiert hatten, haben wir Benachrichtigungen eingeführt, die ausgelöst werden, wenn die VMs eine hohe Arbeitsspeicher- oder Festplattennutzung erreichen.
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringRule
metadata:
name: monitoring-rule
spec:
interval: 60s
limit: 0
alertRules:
- alert: vm1_disk_usage
expr:
(node_filesystem_size_bytes{container_name="compute"} -
node_filesystem_avail_bytes{container_name="compute"}) * 100 /
node_filesystem_size_bytes{container_name="compute"} > 90
labels:
severity: error
code: <a href="/distributed-cloud/hosted/docs/latest/gdch/gdch-io/service-manual/ts/runbooks/ts-r0001">TS-R0001</a>
resource: vm1
annotations:
message: "vm1 disk usage above 90% utilization"
Nachdem wir die Systemstabilität überprüft hatten, konzentrierten wir uns auf Anwendungsfehlermodi im Ticketsystem. Da wir zum Beheben von Problemen in der Anwendung oft eine Secure Shell-Verbindung (SSH) zu jeder Anwendungsserver-VM herstellen mussten, um die Protokolle des Ticketsystems zu prüfen, haben wir eine Anwendung konfiguriert, um diese Protokolle an das Logging-Tool weiterzuleiten. So konnten wir den GDC-Observability-Stack nutzen und alle Betriebslogs des Ticketsystems in der Monitoring-Instanz abfragen.
Das zentrale Logging ermöglichte es uns auch, Logs von mehreren VMs gleichzeitig abzufragen, wodurch wir einen besseren Überblick über die einzelnen Komponenten des Systems erhielten.
Sicherungen
Sicherungen sind für die Funktionsfähigkeit eines Softwaresystems wichtig, da das System im Falle eines Fehlers wiederhergestellt werden kann.
GDC bietet VM-Sicherung und ‑Wiederherstellung über Kubernetes-Ressourcen. Durch das Erstellen einer benutzerdefinierten VirtualMachineBackupRequest-Ressource mit einer benutzerdefinierten VirtualMachineBackupPlanTemplate-Ressource können wir das nichtflüchtige Volume, das an jede VM angehängt ist, in einem Objektspeicher sichern, in dem die Sicherungen gemäß einer festgelegten Aufbewahrungsrichtlinie aufbewahrt werden können.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupPlanTemplate
metadata:
name: vm-backup-plan
spec:
backupRepository: "backup-repository"
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupRequest
metadata:
name: "db-vm-backup"
spec:
virtualMachineBackupPlanTemplate: vm-backup-plan
virtualMachine: db1
virtualMachineBackupName: db-vm-backup
Ebenso wird beim Wiederherstellen eines VM-Status aus einem Backup eine benutzerdefinierte Ressource vom Typ VirtualMachineRestoreRequest erstellt, um sowohl Anwendungs- als auch Datenbankserver wiederherzustellen, ohne den Code oder die Konfiguration für einen der beiden Dienste zu ändern.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineRestoreRequest
metadata:
name: vm-restore-1
spec:
virtualMachineBackup: db-vm-backup
restoreName: restore1
restoredResourceName: db1
Upgrades
Um den Softwarelebenszyklus des Ticketsystems und seiner Abhängigkeiten zu unterstützen, haben wir drei Arten von Software-Upgrades identifiziert, die jeweils einzeln behandelt werden, um Ausfallzeiten und Dienstunterbrechungen zu minimieren:
- Betriebssystem-Upgrades.
- Plattform-Upgrades wie Patch- und Hauptversionen.
- Konfigurationsupdates.
Für Betriebssystem-Upgrades erstellen und veröffentlichen wir kontinuierlich neue VM-Images für Anwendungs- und Datenbankserver, die mit jedem GDC-Release verteilt werden. Diese Images enthalten Korrekturen für Sicherheitslücken und Updates für das zugrunde liegende Betriebssystem.
Für die Plattform-Upgrades des Ticketsystems müssen Updates auf die vorhandenen VM-Images angewendet werden. Daher können wir uns nicht auf eine unveränderliche Infrastruktur verlassen, um Patches und Updates für Hauptversionen durchzuführen. Bei Plattform-Upgrades testen und überprüfen wir die Patch- oder Hauptversion in unseren Entwicklungs- und Stagingumgebungen, bevor wir ein eigenständiges Upgrade-Paket zusammen mit dem GDC-Release veröffentlichen.
Schließlich werden Konfigurationsupdates ohne Ausfallzeiten über die APIs des Ticketsystems für Updatesets und andere Nutzerdaten angewendet. Wir entwickeln und testen Konfigurationsupdates in unseren Entwicklungs- und Stagingumgebungen, bevor wir während des GDC-Releaseprozesses mehrere Updatesets zusammenfassen.
Integrationen
Identitätsanbieter
Um Kunden einen nahtlosen Ablauf zu bieten und Organisationen die Möglichkeit zu geben, ihre Nutzer zu registrieren, haben wir das Ticketsystem in mehrere Identitätsanbieter integriert, die in GDC verfügbar sind. In der Regel haben Unternehmens- und öffentliche Kunden eigene gut verwaltete Identitätsanbieter, mit denen sie ihren Mitarbeitern Berechtigungen erteilen und entziehen können. Aufgrund von Compliance-Anforderungen und der einfachen Verwaltung von Identitäten und Zugriffen möchten diese Kunden ihre vorhandenen Identitätsanbieter als „Source of Truth“ verwenden, um den Zugriff ihrer Mitarbeiter auf das Ticketsystem zu verwalten.
Das Ticketsystem unterstützt sowohl SAML 2.0- als auch OIDC-Anbieter über sein Modul für mehrere Identitätsanbieter, das wir im VM-Image unseres Anwendungsservers vorab aktiviert haben. Kunden authentifizieren sich über den Identitätsanbieter ihrer Organisation, wodurch automatisch Nutzer erstellt und Rollen im Ticketsystem zugewiesen werden.
Der Zugriff auf Identitätsanbieterserver ist über die benutzerdefinierte Ressource ProjectNetworkPolicy zulässig. Dadurch wird eingeschränkt, ob externe Dienste von einer Organisation in GDC aus erreichbar sind. Mit diesen Richtlinien können wir deklarativ steuern, auf welche Endpunkte das Ticketsystem im Netzwerk zugreifen kann.
Aufnahme von Benachrichtigungen
Nutzer können sich nicht nur anmelden, um manuell Supportanfragen zu erstellen, sondern wir erstellen auch Vorfälle im Ticketsystem als Reaktion auf Systembenachrichtigungen.
Für diese Integration haben wir einen Open-Source-Kubernetes-Webhook angepasst, um Benachrichtigungen von der Anwendung zu empfangen und den Lebenszyklus von Vorfällen über den API-Endpunkt des Ticketsystems zu verwalten, der über Cloud Service Mesh bereitgestellt wird.
API-Schlüssel werden im GDC-Geheimnisspeicher gespeichert, der durch Kubernetes-Secrets gesichert wird, die über die rollenbasierte Zugriffssteuerung (Role-Based Access Control, RBAC) verwaltet werden. Andere Konfigurationen wie API-Endpunkte und Felder zur Anpassung von Vorfällen werden über den Kubernetes ConfigMap-Schlüssel/Wert-Speicher verwaltet.
Das Ticketsystem bietet Mailserverintegrationen, damit Kunden E-Mail-basierten Support erhalten können. Automatisierte Workflows wandeln eingehende Kunden-E‑Mails in Supportanfragen um und senden automatische Antworten mit Links zu Anfragen an Kunden. So kann unser Supportteam seinen Posteingang besser verwalten, E‑Mail-Anfragen systematisch verfolgen und beantworten und einen besseren Kundenservice bieten.
apiVersion: networking.gdc.goog/v1
kind: ProjectNetworkPolicy
metadata:
name: allow-ingress-traffic-from-ticketing-system
spec:
subject:
subjectType: UserWorkload
ingress:
- from:
- projects:
matchNames:
- ticketing-system
Wenn Sie E-Mail als Kubernetes-Dienst verfügbar machen, wird auch die Diensterkennung und die Auflösung von Domainnamen ermöglicht. Außerdem wird das E-Mail-Server-Backend von Clients wie dem Ticketsystem entkoppelt.
Compliance
Audit-Logging
Audit-Logs tragen zur Compliance bei, da sie eine Möglichkeit bieten, die Softwarenutzung zu verfolgen und zu überwachen und Systemaktivitäten aufzuzeichnen. In Audit-Logs werden Zugriffsversuche durch nicht autorisierte Nutzer aufgezeichnet, die API-Nutzung verfolgt und potenzielle Sicherheitsrisiken identifiziert. Prüfprotokolle erfüllen Compliance-Anforderungen, z. B. die des Health Insurance Portability and Accountability Act (HIPAA), des Payment Card Industry Data Security Standard (PCI DSS) und des Sarbanes-Oxley Act (SOX).
GDC bietet ein System zum Aufzeichnen von Administratoraktivitäten und Zugriffen innerhalb der Plattform und zum Aufbewahren dieser Logs für einen konfigurierbaren Zeitraum. Durch die Bereitstellung der benutzerdefinierten Ressource AuditLoggingTarget wird die Logging-Pipeline so konfiguriert, dass Audit-Logs aus unserer Anwendung erfasst werden.
Für das Ticketsystem haben wir Audit-Logging-Ziele für sowohl gesammelte System-Audit-Ereignisse als auch anwendungsspezifische Ereignisse konfiguriert, die vom Sicherheits-Audit-Log des Ticketsystems generiert werden. Beide Arten von Logs werden an eine zentrale Loki-Instanz gesendet, in der wir Abfragen schreiben und Dashboards in der Monitoring-Instanz ansehen können.
Zugriffssteuerung
Bei der Zugriffssteuerung wird der Zugriff auf Ressourcen basierend auf der Identität des Nutzers oder Prozesses, der den Zugriff anfordert, gewährt oder verweigert. Das trägt zum Schutz der Daten vor unberechtigtem Zugriff bei und sorgt dafür, dass nur autorisierte Nutzer Änderungen am System vornehmen können. In GDC verwenden wir Kubernetes RBAC, um Richtlinien zu deklarieren und die Autorisierung für die Systemressourcen zu erzwingen, die aus der Anwendung des Ticketsystems bestehen.
Durch die Definition einer ProjectRole in GDC können wir mithilfe einer voreingestellten Autorisierungsrolle einen detaillierten Zugriff auf Kubernetes-Ressourcen gewähren.
apiVersion: resourcemanager.gdc.goog/v1
kind: ProjectRole
metadata:
name: ticketing-system-admin
labels:
resourcemanager.gdc.goog/rbac-selector: system
spec:
rules:
- apiGroups:
- ""
resources:
- configmaps
- events
- pods/log
- services
verbs:
- get
- list
Notfallwiederherstellung
Datenbankreplikation
Um die Anforderungen an die Notfallwiederherstellung (Disaster Recovery, DR) zu erfüllen, stellen wir das Ticketsystem in einer primär-sekundären Konfiguration in mehreren GDC-Instanzen bereit. In diesem Modus werden Anfragen an das Ticketsystem normalerweise an den primären Standort weitergeleitet, während am sekundären Standort das Binärlog der Datenbank kontinuierlich repliziert wird. Bei einem Failover wird die sekundäre Website zur neuen primären Website hochgestuft und Anfragen werden dann an die neue primäre Website weitergeleitet.
Wir nutzen die Funktionen zur Datenbankreplikation, um sowohl den primären als auch den Replikat-Datenbankserver pro GDC-Instanz basierend auf den festgelegten Parametern zu konfigurieren.
Wenn Sie die Replikation für eine vorhandene Instanz aktivieren möchten, die länger als der Aufbewahrungszeitraum für das Binärlog ausgeführt wurde, können Sie die Replikatdatenbank mithilfe einer Datenbanksicherung wiederherstellen, um die Replikation von der primären Datenbank aus zu starten.
Im primären Modus funktionieren die Anwendungsserver und die Datenbank wie bisher. Die primäre Datenbank ist jedoch für die Replikation konfiguriert. Beispiel:
Aktivieren Sie das binäre Log.
Legen Sie die Server-ID fest.
Erstellen Sie ein Nutzerkonto für die Replikation.
Eine Sicherung erstellen.
Im Replikamodus deaktivieren die Anwendungsserver den Ticketing-Webdienst, um eine direkte Verbindung zur Replikatdatenbank zu vermeiden. Die Replikatdatenbank muss so konfiguriert sein, dass die Replikation von der primären Datenbank aus gestartet wird, z. B.:
Legen Sie die Server-ID fest.
Konfigurieren Sie die Anmeldedaten des Replikationsnutzers und die primären Verbindungsdetails wie Host und Port.
Wiederherstellung aus Sicherung mit Fortsetzung der binären Logposition.
Für die Datenbankreplikation ist eine Netzwerkverbindung erforderlich, damit das Replikat eine Verbindung zur primären Datenbank herstellen und die Replikation starten kann. Um den Endpunkt der primären Datenbank für die Replikation verfügbar zu machen, verwenden wir Cloud Service Mesh, um ein Ingress-Service-Mesh zu erstellen, das die TLS-Terminierung im Service-Mesh unterstützt. Das ist ähnlich wie bei der Verarbeitung von HTTPS-Datenübertragungen für die Webanwendung des Ticketsystems.