Présentation
Ce guide du débutant est une introduction à AutoML. Pour comprendre les principales différences entre AutoML et entraînement personnalisé, consultez la section Choisir une méthode d'entraînement.
Imaginez :
- vous soyez entraîneur d'une équipe de football ;
- vous soyez dans le service marketing d'un marchand en ligne ;
- vous travailliez sur un projet architectural identifiant des types de bâtiments ;
- Votre entreprise dispose d'un formulaire de contact sur son site Web.
Traiter des vidéos, des images, des textes et des tables manuellement est un travail long et fastidieux. Ne serait-il pas plus facile d'apprendre à un ordinateur à identifier et à signaler automatiquement les contenus ?
Image
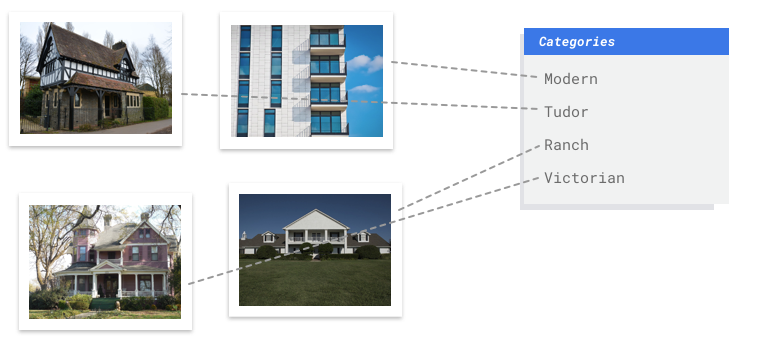
Vous travaillez avec une commission de conservation du patrimoine souhaitant identifier les quartiers de votre ville qui présentent un style architectural homogène. Vous devez passer au crible des centaines de milliers d'instantanés de maisons. Toutefois, tenter de classifier toutes ces images manuellement est bien trop fastidieux et risque de générer des erreurs. Un stagiaire a commencé à étiqueter plusieurs centaines de ces images il y a quelques mois, mais personne n'a examiné les données. Quel soulagement si vous pouviez apprendre à votre ordinateur à les classifier pour vous !
Tabulaire
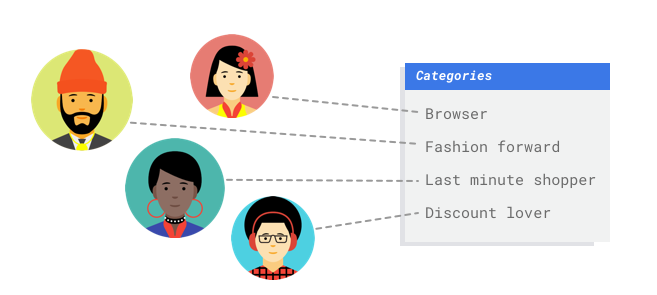
Vous travaillez dans le service marketing d'un marchand en ligne. Avec votre équipe, vous créez un programme de diffusion d'e-mails personnalisés basé sur des personas de clients. Vous avez créé les personas et les e-mails marketing sont prêts pour diffusion. Vous devez maintenant créer un système qui classe les clients par persona selon les préférences de vente et le comportement d'achat, même pour les nouveaux clients. Pour optimiser l'engagement client, vous souhaitez également prédire leurs habitudes d'achat afin de déterminer le meilleur moment pour envoyer les e-mails.
Grâce aux ventes en ligne, vous disposez de données sur vos clients et les achats qu'ils ont effectués. Mais qu'en est-il des nouveaux clients ? Les approches classiques peuvent calculer ces données pour les clients existants ayant de longs historiques d'achats, mais ne sont pas adaptées aux clients dont l'historique est récent. Et si vous pouviez créer un système permettant de prédire ces valeurs et de proposer plus rapidement des programmes marketing personnalisés à tous vos clients ?
Les systèmes de machine learning et Vertex AI constituent des outils adaptés pour répondre à ces questions.
Texte
Votre entreprise dispose d'un formulaire de contact sur son site Web. Vous recevez chaque jour de nombreux messages via ce formulaire, dont beaucoup sont exploitables. Ils arrivent tous ensemble, et vous pouvez facilement vous retrouver débordé. Les différents messages ne sont pas gérés par les mêmes employés.
Pour remédier à cela, il faudrait que les commentaires soient classés par un système automatisé afin qu'ils soient adressés à la personne appropriée.
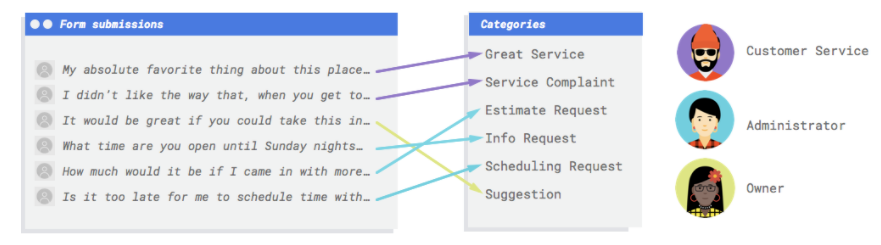
Il faudrait que ce système puisse analyser les commentaires et déterminer s'ils constituent des réclamations, des compliments sur vos services, des demandes d'informations sur votre entreprise, des prises de rendez-vous ou des mises en relation.
Vidéo
Vous disposez d'une vaste vidéothèque de matchs que vous souhaitez utiliser à des fins d'analyses. Cependant, cela impliquerait des centaines d'heures de vidéos à examiner. Qui plus est, visionner chaque vidéo en délimitant manuellement les séquences pour mettre en évidence chaque action est un travail tout aussi fastidieux que chronophage, qui doit être répété à chaque saison. Imaginons maintenant un modèle informatique capable d'identifier et de signaler automatiquement ces actions chaque fois qu'elles apparaissent dans une vidéo.
Voici quelques scénarios spécifiques aux objectifs.
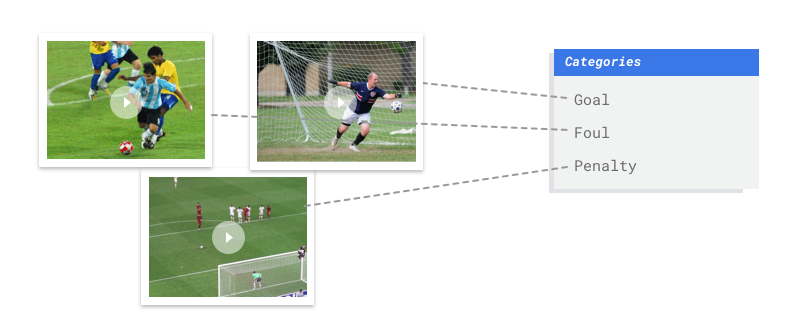
- Reconnaissance d'actions : identifiez des actions comme marquer un but, commettre une faute, effectuer un tir de penalty. Utile pour les entraîneurs qui étudient les points forts et les points faibles de leur équipe.
- Classification : classez chaque plan vidéo selon qu'il s'agit d'une mi-temps, d'une vue du match, d'une vue du public, ou d'une vue de l'entraîneur. Utile pour les entraîneurs qui peuvent ainsi parcourir uniquement les plans vidéo qui les intéressent.
- Suivi des objets : suivez le ballon de football ou les joueurs. Utile aux entraîneurs pour obtenir les statistiques des joueurs telles que la carte thermique sur le terrain ou le taux de passes réussies.
Ce guide décrit le fonctionnement de Vertex AI pour les ensembles de données et les modèles AutoML, et illustre les types de problèmes que Vertex AI est conçu pour résoudre.
Un mot sur l'équité
Google s'engage à faire avancer la mise en place des pratiques d'IA responsables. À cette fin, nos produits de ML, y compris AutoML, sont conçus selon des principes de base tels que l'équité et le machine learning centré sur l'humain. Pour en savoir plus des bonnes pratiques pour limiter les biais lors de la création de votre propre système de ML, consultez le Guide sur l'inclusion dans le ML – AutoML.
En quoi Vertex AI constitue-t-il un outil adapté pour résoudre ce problème ?
La programmation classique nécessite qu'un programmeur spécifie des instructions pas à pas à suivre par un ordinateur. Mais considérons le cas d'utilisation où il s'agit d'identifier des actions spécifiques dans des matchs de football. Il y a tellement de différences de couleur, d'angle, de résolution et d'éclairage qu'il faudrait coder un trop grand nombre de règles pour indiquer à une machine comment prendre la bonne décision. Vous ne sauriez même pas par où commencer. Ou bien, lorsque les commentaires des clients, qui utilisent un vocabulaire varié et de nombreuses syntaxes différentes, présentent une trop grande diversité pour être capturés à l'aide d'un simple ensemble de règles. Si vous avez tenté d'appliquer des filtres définis manuellement, vous allez vite constater que la plupart des commentaires de vos clients échappent à cette classification. Il vous faut donc un système capable de généraliser un modèle à un grand nombre de commentaires. Nous avons ici affaire à un cas de figure où l'adoption d'une séquence de règles spécifiques vous mènera forcément à une impasse, car elle est condamnée à se développer de manière exponentielle. Vous devez plutôt opter pour un système capable d'apprendre à partir d'exemples.
Heureusement, le machine learning permet de résoudre ces problèmes.
Comment fonctionne Vertex AI ?
 Vertex AI implique des tâches d'apprentissage supervisé pour atteindre le résultat souhaité.
Les spécificités de l'algorithme et les méthodes d'entraînement varient selon le type de données et le cas d'utilisation. Il existe de nombreuses sous-catégories de machine learning, qui résolvent toutes des problèmes différents et fonctionnent avec des contraintes variées.
Vertex AI implique des tâches d'apprentissage supervisé pour atteindre le résultat souhaité.
Les spécificités de l'algorithme et les méthodes d'entraînement varient selon le type de données et le cas d'utilisation. Il existe de nombreuses sous-catégories de machine learning, qui résolvent toutes des problèmes différents et fonctionnent avec des contraintes variées.
Image
Vous entraînez, testez et validez le modèle de machine learning avec des exemples d'images qui sont annotés avec des étiquettes pour la classification, ou annotés avec des étiquettes et des cadres de délimitation pour la détection d'objets. L'apprentissage supervisé vous permet d'entraîner un modèle personnalisé à reconnaître le contenu qui vous intéresse dans des images.
Tabulaire
Vous entraînez un modèle de machine learning à l'aide d'exemples de données. Vertex AI utilise des données tabulaires (structurées) pour entraîner un modèle de machine learning à réaliser des prédictions sur de nouvelles données. Une colonne de votre ensemble de données, dénommée cible, indique ce que le modèle va apprendre à prédire. Parmi les autres colonnes de données, certaines contiennent des entrées (dénommées caractéristiques) à partir desquelles le modèle va identifier des tendances pour son apprentissage. Vous pouvez utiliser les mêmes caractéristiques d'entrée pour créer plusieurs types de modèles en modifiant simplement la colonne cible et les options d'entraînement. Dans l'exemple de marketing par e-mail, cela signifie que vous pouvez créer des modèles avec les mêmes caractéristiques d'entrée, mais avec des prédictions cibles différentes. Un modèle peut prédire le persona d'un client (cible catégorielle), un autre modèle peut prédire ses dépenses mensuelles (cible numérique), et un autre modèle peut prévoir la demande quotidienne de vos produits pour les trois prochains mois (séries de cibles numériques).
Texte
Vertex AI vous permet d'effectuer un apprentissage supervisé. Cette opération consiste à apprendre à un ordinateur à détecter des tendances à partir de données étiquetées. L'apprentissage supervisé vous permet d'entraîner un modèle AutoML à reconnaître le contenu qui vous intéresse dans du texte.
Vidéo
Vous entraînez, testez et validez le modèle de machine learning avec des vidéos que vous avez déjà étiquetées. Avec un modèle entraîné, vous pouvez ensuite introduire de nouvelles vidéos pour que ce dernier génère des segments vidéo étiquetés. Un segment vidéo définit les heures de début et de fin d'une vidéo. Il peut s'agir de la vidéo dans sa totalité, d'un laps de temps défini par l'utilisateur, d'un plan vidéo détecté automatiquement, ou d'un simple horodatage lorsque l'heure de début est la même que l'heure de fin. Une étiquette est une "réponse" prédite par le modèle. Par exemple, dans les cas d'utilisation relatifs au football mentionnés plus tôt, pour chaque nouvelle vidéo de football, en fonction du type de modèle :
- Un modèle de reconnaissance d'actions entraîné génère des horodatages vidéo avec des étiquettes décrivant des actions telles que "but", "faute personnelle", etc.
- Un modèle de classification entraîné génère automatiquement des segments de plan détectés à l'aide de thèmes définis par l'utilisateur, tels que "vue du match", ou encore "vue du public".
- Un modèle de suivi des objets entraîné génère des suivis du ballon ou des joueurs au moyen de cadres de délimitation dans les images où les objets apparaissent.
Workflow de Vertex AI
Vertex AI utilise un workflow de machine learning standard :
- Collecte de données : vous déterminez les données dont vous avez besoin pour entraîner et tester votre modèle en fonction du résultat que vous souhaitez obtenir.
- Préparation des données : vous vérifiez que vos données sont correctement formatées et étiquetées.
- Entraînement : vous définissez les paramètres et construisez votre modèle.
- Évaluation : vous examinez les métriques du modèle.
- Déploiement et prédiction : vous rendez votre modèle disponible à l'utilisation.
Avant de commencer à collecter des données, vous devez toutefois réfléchir au problème que vous essayez de résoudre. Cela vous permettra de déterminer vos besoins en termes de données.
Préparation des données
Appréciation de votre cas d'utilisation
Commencez par réfléchir à votre problème : quel résultat souhaitez-vous obtenir ?
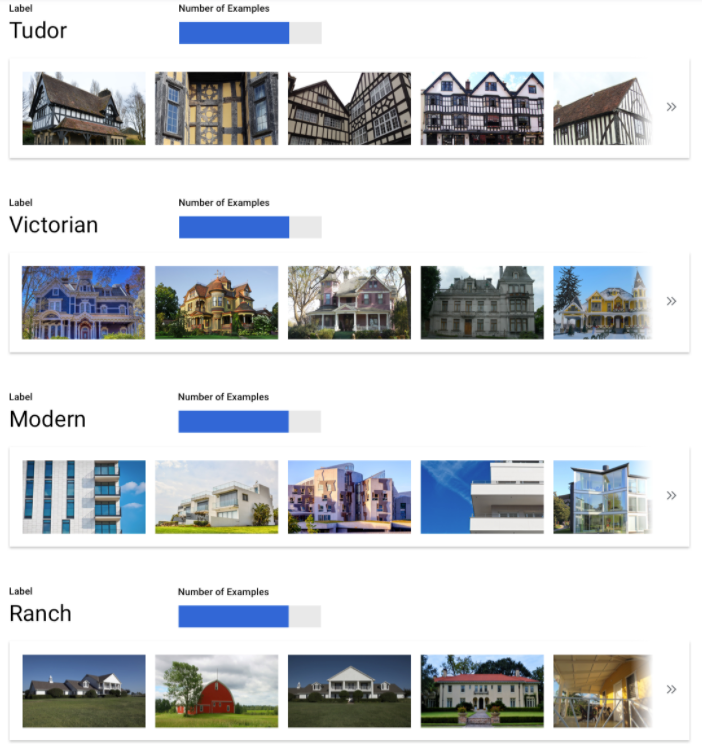
Image
Lorsque vous constituez un ensemble de données, commencez toujours par définir votre cas d'utilisation. Dans un premier temps, posez-vous les questions suivantes :
- Quel résultat souhaitez-vous obtenir ?
- Quels types de catégories ou d'objets devez-vous identifier pour obtenir ce résultat ?
- En tant qu'humain, est-il possible de reconnaître ces catégories ? La capacité de Vertex AI à gérer et à attribuer à tout moment un panel de catégories est certes supérieure à celle de l'être humain. Toutefois, si ce dernier ne parvient pas à reconnaître une catégorie spécifique, son traitement posera également problème à Vertex AI.
- Quels types d'exemples refléteraient le mieux le type et la plage de données que votre système détectera et tentera de classer ?
Tabulaire
À quel type de données la colonne cible correspond-elle ? À quelle quantité de données avez-vous accès ? En fonction des réponses, Vertex AI crée le modèle nécessaire pour trouver une solution à votre cas d'utilisation :
- Un modèle de classification binaire prédit un résultat binaire (l'une des deux classes). Utilisez cette option pour les questions de type "oui" ou "non", par exemple pour prédire si un client achètera ou non un abonnement. Toutes choses égales par ailleurs, un problème de classification binaire nécessite moins de données que les autres types de modèle.
- Un modèle de classification à classes multiples prédit une classe à partir de trois classes distinctes ou plus. Utilisez cette option pour classer différents éléments. Dans l'exemple de vente au détail, vous souhaitez créer un modèle de classification à classes multiples pour segmenter les clients en différents personnages.
- Un modèle de prévision prédit une séquence de valeurs. Par exemple, en tant que revendeur, vous souhaitez peut-être prévoir la demande quotidienne de vos produits pour les trois prochains mois afin de pouvoir anticiper convenablement les stocks de produits nécessaires.
- Un modèle de régression prédit une valeur continue. Dans l'exemple de vente au détail, vous souhaitez créer un modèle de régression afin de prédire le montant qu'un client dépensera le mois prochain.
Texte
Lorsque vous constituez un ensemble de données, commencez toujours par définir votre cas d'utilisation. Dans un premier temps, posez-vous les questions suivantes :
- Quel résultat souhaitez-vous obtenir ?
- Quels types de catégories devez-vous identifier pour atteindre ce résultat ?
- En tant qu'humain, est-il possible de reconnaître ces catégories ? La capacité de Vertex AI à mémoriser et à attribuer à tout moment un panel de catégories est supérieure à celle de l'être humain. Toutefois, si ce dernier ne parvient pas à reconnaître une catégorie spécifique, son traitement posera également problème à Vertex AI.
- Quels types d'exemples refléteraient le mieux le type et la plage de données que votre système va classer ?
Vidéo
Sélectionnez l'objectif de modèle approprié en fonction du résultat que vous souhaitez obtenir :
- L'objectif de reconnaissance d'actions permet de détecter dans une vidéo les passages où il y a des actions, comme marquer un but, faire une faute ou tirer un pénalty.
- Utilisez l'objectif de classification pour classer les séquences dans les catégories suivantes : commercial, actualités, émissions télévisées, etc.
- Pour localiser et suivre les objets dans une vidéo, utilisez l'objectif de suivi d'objets.
Pour en savoir plus sur les bonnes pratiques en matière de préparation des ensembles de données pour les objectifs de reconnaissance d'actions, de classification et de suivi des objets, consultez la section Préparer des données vidéo.
Collecter les données
Une fois que vous avez établi votre cas d'utilisation, vous devez collecter les données qui vous permettront de créer le modèle souhaité.
Image
 Après que vous avez défini les données dont vous avez besoin, vous devez trouver un moyen de les collecter. Vous pouvez commencer par prendre en compte toutes les données que votre organisation recueille. Vous allez peut-être constater que vous collectez déjà les données pertinentes dont vous avez besoin pour entraîner un modèle. Si vous ne disposez pas de ces données, vous pouvez les obtenir manuellement ou confier cette étape à un fournisseur tiers.
Après que vous avez défini les données dont vous avez besoin, vous devez trouver un moyen de les collecter. Vous pouvez commencer par prendre en compte toutes les données que votre organisation recueille. Vous allez peut-être constater que vous collectez déjà les données pertinentes dont vous avez besoin pour entraîner un modèle. Si vous ne disposez pas de ces données, vous pouvez les obtenir manuellement ou confier cette étape à un fournisseur tiers.
Inclure suffisamment d'exemples étiquetés pour chaque catégorie
 Pour la classification, vous devez inclure au strict minimum 100 exemples d'images par catégorie ou étiquette sur Vertex AI Training.
Plus vous fournissez d'exemples de bonne qualité par étiquette, plus les chances qu'elle soit correctement reconnue augmentent. De manière générale, plus vous incluez de données étiquetées dans le processus d'entraînement, meilleur sera votre modèle. Essayez de fournir au moins 1000 exemples par étiquette.
Pour la classification, vous devez inclure au strict minimum 100 exemples d'images par catégorie ou étiquette sur Vertex AI Training.
Plus vous fournissez d'exemples de bonne qualité par étiquette, plus les chances qu'elle soit correctement reconnue augmentent. De manière générale, plus vous incluez de données étiquetées dans le processus d'entraînement, meilleur sera votre modèle. Essayez de fournir au moins 1000 exemples par étiquette.
Répartir équitablement les exemples entre les catégories
Il est important d'inclure un nombre à peu près similaire d'exemples d'entraînement pour chaque catégorie. Même si vous disposez d'une abondance de données pour une étiquette, il est préférable d'avoir une distribution égale pour chaque étiquette. Voici un exemple illustrant ce principe : imaginez que 80 % des images que vous utilisez pour créer votre modèle concernent des maisons individuelles de style contemporain. En présence d'une répartition des étiquettes aussi déséquilibrée, il est très probable que votre modèle apprenne qu'il est judicieux de toujours indiquer cette catégorie de construction pour chaque photo, plutôt que de s'aventurer à essayer de prédire une étiquette beaucoup moins courante.
Ce cas de figure est comparable à un questionnaire à choix multiples où presque toutes les bonnes réponses sont "C" et où la personne répondant au questionnaire va très vite déduire qu'elle peut répondre "C" à chaque fois, sans même regarder la question.
Nous savons qu'il n'est pas toujours possible de trouver un nombre à peu près équivalent d'exemples pour chaque étiquette. Pour certaines catégories, il peut être plus difficile de collecter des exemples impartiaux de bonne qualité. Dans ce cas, vous pouvez suivre le principe général suivant : l'étiquette comprenant le moins d'exemples doit compter au moins 10 % du total d'exemples de l'étiquette en comportant le plus. Par exemple, si l'étiquette la plus représentée comporte 10 000 exemples, la moins importante devrait en présenter au moins 1 000.
Tenir compte des variations dans votre espace de problème
Pour des raisons similaires, assurez-vous que vos données tiennent compte de la variété et de la diversité de votre espace de problème. Plus la sélection proposée au processus d'entraînement du modèle est vaste, plus celui-ci sera facile à généraliser pour de nouveaux exemples. Par exemple, si vous essayez de classer les photos de produits électroniques grand public en catégories, plus vous exposerez le modèle à une large variété de produits lors de l'entraînement, plus il saura distinguer la dernière tablette, ou le dernier téléphone ou ordinateur portable, même s'il n'a jamais vu ce produit spécifique auparavant.
Trouver des données correspondant aux résultats souhaités du modèle

Recherchez des images qui ressemblent visuellement à celles que vous prévoyez d'utiliser pour vos prédictions. Si vous essayez de classer des images de maisons qui ont toutes été photographiées en hiver sous la neige, et que vous utilisez un modèle qui n'a été entraîné que sur des photos prises par temps ensoleillé, vous obtiendrez probablement des performances médiocres. Le fait d'avoir indiqué les tags et classes voulus n'y changera rien, car l'éclairage et les paysages sont trop différents pour donner un résultat optimal. Dans l'idéal, vos exemples d'entraînement sont constitués de données réelles tirées du même ensemble de données que celui sur lequel vous prévoyez d'utiliser le modèle pour la classification.
Tabulaire
Une fois que vous avez établi votre cas d'utilisation, vous devez collecter des données pour entraîner votre modèle.
La collecte et la préparation des données sont des étapes essentielles dans la création d'un modèle de machine learning.
Les données dont vous disposez permettent de déterminer le type de problèmes que vous pouvez résoudre. De combien de données disposez-vous ? Sont-elles pertinentes pour les questions auxquelles vous tentez de répondre ? Lors de la collecte de données, gardez à l'esprit les considérations suivantes.
Sélectionner les caractéristiques pertinentes
Les caractéristiques sont des attributs d'entrée utilisés pour l'entraînement d'un modèle. Elles lui permettent d'identifier des tendances pour réaliser des prédictions. Leur pertinence par rapport à votre problème est donc importante. Par exemple, pour créer un modèle permettant de prédire si une transaction par carte de crédit est frauduleuse ou non, vous devez créer un ensemble de données contenant les détails de la transaction : acheteur, vendeur, montant, date et heure, et articles achetés. D'autres informations peuvent être utiles, telles que les données historiques de l'acheteur et du vendeur, et la fréquence à laquelle l'article acheté a été impliqué dans une fraude. Existe-t-il d'autres caractéristiques pouvant s'avérer pertinentes ?
Considérons le cas d'utilisation de marketing par e-mail du marchand présenté en introduction. Voici quelques colonnes de caractéristiques dont vous pourriez avoir besoin :
- Liste des articles achetés (y compris marques, catégories, prix, remises)
- Quantité d'articles achetés (jour précédent, semaine, mois, année)
- Somme d'argent dépensée (jour précédent, semaine, mois, année)
- Pour chaque article, nombre total de produits vendus chaque jour
- Pour chaque article, le total en stock chaque jour
- Si vous diffusez ou non une promotion certains jours
- Profil démographique connu de l'acheteur
Inclure suffisamment de données
En général, plus vous avez d’exemples d'entraînement, meilleur sera le résultat. La quantité d'exemples de données nécessaires varie également en fonction de la complexité du problème que vous tentez de résoudre. Vous n'aurez pas besoin d'autant de données pour obtenir un modèle de classification binaire précis comparé à un modèle à classes multiples, car il est moins compliqué de prédire à partir de deux classes qu'à partir de plusieurs.
Si la formule parfaite n'existe pas, le nombre minimal conseillé d'exemples de données est le suivant :
- Problème de classification : nombre de caractéristiques x 50 lignes
- Problème de prévision :
- 5 000 lignes x nombre d'éléments de caractéristiques
- 10 valeurs uniques dans la colonne "Identifiant de série temporelle" x nombre de caractéristiques
- Problème de régression : nombre de caractéristiques x 200
Capturer les nuances
Votre ensemble de données doit capturer la diversité de votre espace-problème. Plus un modèle traite des exemples diversifiés au cours de son entraînement, plus il peut facilement se généraliser à des exemples nouveaux ou moins courants. Imaginez que votre modèle de vente au détail n'ait été entraîné que sur les données d'achat de l'hiver. Serait-il capable de prédire correctement les préférences de vêtements ou les comportements d'achat de l'été ?
Texte
Une fois que vous avez défini les données dont vous avez besoin, vous devez trouver un moyen de les collecter. Vous pouvez commencer par prendre en compte toutes les données que votre organisation recueille. Vous constaterez peut-être que vous collectez déjà les données dont vous avez besoin pour entraîner un modèle. Dans le cas contraire, vous pouvez les obtenir manuellement ou confier cette étape à un fournisseur tiers.
Inclure suffisamment d'exemples étiquetés pour chaque catégorie
Plus vous fournissez d'exemples de bonne qualité par étiquette, plus les chances qu'elle soit correctement reconnue augmentent. De manière générale, plus vous incluez de données étiquetées dans le processus d'entraînement, meilleur sera votre modèle. Le nombre d'échantillons nécessaires varie également en fonction du degré de cohérence des données à prédire et du niveau de précision à atteindre. Vous pouvez utiliser moins d'exemples pour des ensembles de données cohérents ou pour atteindre une précision de 80 % plutôt que 97 %.
Entraînez un modèle, puis évaluez les résultats. Ajoutez plus d'exemples et reprenez l'entraînement jusqu'à ce que vous atteigniez vos objectifs de précision, ce qui peut nécessiter des centaines, voire des milliers d'exemples par étiquette. Pour plus d'informations sur les exigences et les recommandations concernant les données, consultez la section Préparer des données textuelles d'entraînement pour des modèles AutoML.
Répartir équitablement les exemples entre les catégories
Il est important d'obtenir un nombre d'exemples d'entraînement similaire pour chaque catégorie. Même si vous disposez d'une abondance de données pour une étiquette, il est préférable d'avoir une distribution égale pour chaque étiquette. Pour comprendre pourquoi, imaginez que 80 % des commentaires des clients que vous utilisez pour créer votre modèle correspondent à des demandes de devis. En présence d'une répartition des étiquettes aussi déséquilibrée, il est très probable que votre modèle apprenne qu’il est judicieux de toujours indiquer que les commentaires des clients correspondent à des demandes de devis, plutôt que d'essayer de prédire une étiquette beaucoup moins courante. Ce cas de figure est comparable à un questionnaire à choix multiples où presque toutes les bonnes réponses sont "C" et où la personne répondant au questionnaire va très vite déduire qu'elle peut répondre "C" à chaque fois, sans même regarder la question.

Il n'est pas toujours possible de trouver un nombre à peu près équivalent d'exemples pour chaque étiquette. Pour certaines catégories, il peut être plus difficile de collecter des exemples impartiaux de bonne qualité. Dans ce cas, l'étiquette comprenant le moins d'exemples doit compter au moins 10 % du total d'exemples de l'étiquette en comportant le plus. Par exemple, si l'étiquette la plus représentée comporte 10 000 exemples, la moins importante devrait en présenter au moins 1 000.
Tenir compte des variations dans votre espace de problème
Pour des raisons similaires, essayez de faire en sorte que vos données tiennent compte de la variété et de la diversité de votre espace de problème. Lorsque vous fournissez un ensemble d'exemples plus important, le modèle peut plus facilement être généralisé à de nouvelles données. Supposons que vous essayiez de classer des articles sur les produits électroniques grand public en fonction de leur sujet. Plus vous fournissez de noms de marques et de caractéristiques techniques, plus le modèle comprendra facilement le sujet d'un article, même si cet article concerne une marque qui n'a pas été intégrée à l'ensemble de données d'entraînement. Vous pouvez également inclure une étiquette "Autres" pour les documents ne correspondant à aucune des étiquettes définies afin d'améliorer plus encore les performances du modèle.
Trouver des données correspondant aux résultats souhaités du modèle

Trouvez des exemples textuels similaires à ceux sur lesquels vous prévoyez d'effectuer des prédictions. Si vous essayez de classer des posts sur les réseaux sociaux concernant le soufflage de verre, un modèle entraîné sur des sites Web contenant des informations sur ce sujet risque de ne pas s'avérer très performant, car le vocabulaire et le style peuvent varier. Dans l'idéal, vos exemples d'entraînement sont constitués de données réelles tirées du même ensemble de données que celui sur lequel vous prévoyez d'utiliser le modèle pour la classification.
Vidéo
Une fois que vous avez établi votre cas d'utilisation, vous devez collecter les données vidéo qui vous permettront de créer le modèle souhaité. Les données que vous collectez pour l'entraînement déterminent le type de problèmes que vous pouvez résoudre. Combien de vidéos pouvez-vous utiliser ? Les vidéos contiennent-elles suffisamment d'exemples pour les éléments que votre modèle doit prédire ? Lors de la collecte de données vidéo, gardez à l'esprit les considérations suivantes.
Inclure suffisamment de vidéos
En règle générale, plus votre ensemble de données contient de vidéos d'entraînement, plus le résultat sera fiable. Le nombre de vidéos recommandé dépend également de la complexité du problème que vous essayez de résoudre. Par exemple, pour la classification, vous aurez besoin de moins de données vidéo pour un problème de classification binaire (prédiction d'une classe sur deux) que pour un problème à étiquettes multiples (prédiction d'une ou de plusieurs classes parmi de nombreuses autres).
La complexité des éléments que vous essayez de classifier peut également déterminer la quantité de données vidéo dont vous avez besoin. Prenons l'exemple du cas d'utilisation du football pour la classification, où il s'agit de créer un modèle pour distinguer les actions de tir, plutôt que d'entraîner un modèle capable de classer différents styles de natation. Par exemple, pour distinguer la brasse, le papillon, le dos crawlé, etc., vous aurez besoin de davantage de données d'entraînement pour identifier les différents styles de natation afin que le modèle puisse apprendre à identifier chaque type de manière précise. Consultez la section Préparer des données vidéo pour comprendre la quantité minimum de données vidéo dont vous aurez besoin pour la reconnaissance des actions, la classification et le suivi des objets.
La quantité de données vidéo requise peut être supérieure à celle dont vous disposez actuellement. Envisagez d'obtenir davantage de vidéos auprès d'un fournisseur tiers. Par exemple, vous pourriez acquérir ou obtenir davantage de vidéos de colibris si vous n'en avez pas suffisamment pour entraîner votre modèle d'identificateur d'actions de match.
Répartir équitablement les vidéos entre les classes
Essayez de fournir un nombre semblable d'exemples d'entraînement pour chaque classe. Voici pourquoi : imaginez que les 80 % de votre ensemble de données d'entraînement soient des vidéos de football contenant des tirs au but, mais que seulement 20 % des vidéos décrivent des fautes personnelles ou des penalties. Lorsque les classes sont réparties de manière aussi inégale, le modèle est plus susceptible de prédire qu'une action donnée est un but. C'est comme si vous conceviez un test à choix multiples où 80 % des réponses correctes sont "C" : le modèle avisé comprendra rapidement que la plupart du temps, "C" est sans doute la bonne réponse.

Vous ne pourrez peut-être pas générer un nombre égal de vidéos pour chaque classe. De même, pour certaines classes, il peut être difficile d'obtenir des exemples non biaisés de grande qualité. Vous devez donc essayer de respecter un rapport de 1:10 : si la classe la plus nombreuse compte 10 000 vidéos, alors la plus petite devrait en contenir au moins 1 000.
Capturer les nuances
Vos données vidéo doivent capturer la diversité de votre espace-problème. Plus un modèle traite des exemples diversifiés au cours de son entraînement, plus il peut facilement se généraliser à des exemples nouveaux ou moins courants. Pensez au modèle de classification des actions de football : assurez-vous d'inclure des vidéos présentant divers angles de caméra, des heures diurnes et nocturnes, ainsi qu'une variété de mouvements de joueurs. L'exposition du modèle à des données diversifiées améliorera sa capacité à distinguer une action d'une autre.
Faire correspondre les données aux résultats souhaités

Recherchez des vidéos d'entraînement visuellement similaires aux vidéos que vous prévoyez d'introduire dans le modèle de prédiction. Par exemple, si toutes vos vidéos d'entraînement sont prises en hiver ou en soirée, les caractéristiques d'éclairage et de couleur de ces environnements affecteront votre modèle. Si vous l'utilisez ensuite pour tester des vidéos prises en été ou en plein jour, vous risquez d'obtenir des prédictions inexactes.
Tenez compte de ces facteurs supplémentaires : résolution vidéo, images vidéo par seconde, angle de caméra, arrière-plan.
Préparer vos données
Image
 Une fois que vous avez déterminé quel procédé vous convient le mieux (une répartition manuelle ou par défaut), vous pouvez ajouter des données dans Vertex AI à l'aide de l'une des méthodes suivantes :
Une fois que vous avez déterminé quel procédé vous convient le mieux (une répartition manuelle ou par défaut), vous pouvez ajouter des données dans Vertex AI à l'aide de l'une des méthodes suivantes :
- Vous pouvez importer des données depuis votre ordinateur ou Cloud Storage dans un format disponible (CSV ou JSON Lines), avec les étiquettes (et les cadres de délimitation, le cas échéant) intégrées. Pour en savoir plus sur le format de fichier d'importation, consultez la section Préparer les données d'entraînement. Si vous souhaitez effectuer une répartition manuelle de votre ensemble de données, vous pouvez spécifier les répartitions dans votre fichier d'importation CSV ou JSON Lines.
- Si vos données n'ont pas été annotées, vous pouvez importer des images sans étiquette et utiliser la console Google Cloud pour appliquer des annotations. Vous pouvez gérer ces annotations dans plusieurs ensembles d'annotations pour le même ensemble d'images. Par exemple, pour un seul ensemble d'images, vous pouvez disposer d'un ensemble d'annotations avec des informations de cadres de délimitation et d'étiquettes pour effectuer une détection d'objets, et disposer d'un autre ensemble d'annotations avec seulement des annotations d'étiquettes pour la classification.
Tabulaire
Une fois que vous avez identifié les données disponibles, vous devez vérifier qu'elles sont prêtes pour l'entraînement.
Si vos données sont biaisées ou comportent des valeurs manquantes ou erronées, cela affectera la qualité du modèle. Considérez ce qui suit avant de commencer à entraîner votre modèle.
En savoir plus
Prévenir les fuites de données et le décalage entraînement/diffusion
Une fuite de données se produit lorsque vous utilisez des caractéristiques d'entrée lors de l'entraînement qui "divulguent" des informations sur la cible que vous essayez de prédire, lesquelles ne sont pas disponibles lorsque le modèle est réellement diffusé. Cela peut être détecté lorsqu'une caractéristique fortement corrélée à la colonne cible est incluse parmi les caractéristiques d'entrée. Par exemple, si vous créez un modèle pour prédire si un client souscrira un abonnement le mois prochain et que l'une des caractéristiques d'entrée est un futur paiement d'abonnement de ce client. Les performances du modèle peuvent être très élevées lors des tests, mais de faible niveau lors du déploiement en production, car les informations de paiement d'abonnement futur ne sont pas disponibles au moment de la diffusion.
Le décalage entraînement/diffusion survient lorsque les caractéristiques d'entrée utilisées pendant l'entraînement diffèrent de celles fournies au modèle au moment de la diffusion, ce qui entraîne une baisse de qualité du modèle en production. Par exemple, créer un modèle de prédiction des températures par heure, mais l'entraîner avec des données ne contenant que des températures par semaine. Autre exemple : fournir les notes d'un élève dans les données d'entraînement pour prédire le décrochage scolaire, mais ne pas les inclure au moment de la diffusion.
Il est important de comprendre vos données d’entraînement pour prévenir les fuites de données et éviter tout décalage entraînement/diffusion :
- Avant d'utiliser des données, veillez à bien comprendre leur signification pour déterminer s'il convient de les utiliser comme caractéristiques.
- Vérifiez la corrélation dans l'onglet "Entraînement". Les corrélations élevées doivent être signalées pour examen.
- Décalage entraînement/diffusion : veillez à ne fournir au modèle que des caractéristiques d'entrée disponibles dans un format identique au moment de la diffusion.
Nettoyer les données manquantes, incomplètes et incohérentes
Il est fréquent que des valeurs manquantes et inexactes figurent dans les exemples de données. Prenez le temps d'examiner et, si possible, d'améliorer la qualité de vos données avant de les utiliser pour l'entraînement. Plus il y a de valeurs manquantes, moins les données seront utiles pour l'entraînement d'un modèle de machine learning.
- Vérifiez les valeurs manquantes dans vos données et corrigez-les si possible. Sinon, vous pouvez laisser la valeur vide si la colonne est définie comme pouvant être vide. Vertex AI peut gérer les valeurs manquantes, mais vous avez plus de chances d'obtenir des résultats optimaux si toutes les valeurs sont disponibles.
- Pour les prévisions, vérifiez que l'intervalle entre les lignes d'entraînement est cohérent. Vertex AI peut imputer les valeurs manquantes, mais vous avez plus de chances d'obtenir des résultats optimaux si toutes les lignes sont disponibles.
- Nettoyez vos données en corrigeant ou en supprimant les erreurs ou le bruit. Assurez leur cohérence : vérifiez l'orthographe, les abréviations et le formatage.
Analyser les données après l'importation
Vertex AI fournit une vue d'ensemble de votre ensemble de données après son importation. Examinez l'ensemble de données importé pour vérifier que chaque colonne comporte bien le type de variable correct. Vertex AI détecte automatiquement le type de variable en fonction des valeurs des colonnes, mais il est préférable de les examiner une par une. Vous devez également vérifier le paramètre de valeur vide de chaque colonne, qui détermine si la colonne peut contenir des valeurs manquantes ou NULL.
Texte
Une fois que vous avez déterminé quel procédé vous convient le mieux (une répartition manuelle ou par défaut), vous pouvez ajouter des données dans Vertex AI à l'aide de l'une des méthodes suivantes :
- Vous pouvez importer des données à partir de votre ordinateur ou de Cloud Storage au format CSV ou JSON Lines avec les étiquettes intégrées, comme spécifié dans la section Préparer vos données d'entraînement. Si vous souhaitez effectuer une répartition manuelle de votre ensemble de données, vous pouvez spécifier les répartitions dans votre fichier CSV ou JSON Lines.
- Si vos données n'ont pas d'étiquette, vous pouvez importer des exemples textuels sans étiquette et utiliser la console de Vertex AI pour appliquer des étiquettes.
Vidéo
Une fois que vous avez collecté les vidéos que vous souhaitez inclure dans votre ensemble de données, vous devez vous assurer qu'elles contiennent des étiquettes associées aux segments vidéo ou aux cadres de délimitation. Dans le cadre de la reconnaissance d'actions, le segment vidéo correspond à un horodatage et, pour la classification, il peut s'agir d'un plan vidéo, d'un segment ou de l'intégralité de la vidéo. Pour le suivi des objets, les étiquettes sont associées à des cadres de délimitation.
Pourquoi mes vidéos ont-elles besoin de cadres de délimitation et d'étiquettes ?
Pour le suivi des objets, comment un modèle Vertex AI apprend-t-il à identifier des schémas ? C'est à cela que servent les cadres de délimitation et les étiquettes pendant l'entraînement. Prenons l'exemple du football : chaque exemple vidéo devra contenir des cadres de délimitation autour des scènes d'action qui vous intéressent. Ces cadres doivent également comporter des étiquettes, telles que "personne" et "ballon", qui leur sont attribués. Sinon, le modèle ne saura pas quoi rechercher. Dessiner des cadres de délimitation et attribuer des étiquettes à vos exemples vidéo peut prendre du temps.
Si vos données ne sont pas encore étiquetées, vous pouvez également importer des vidéos non étiquetées et utiliser la console Google Cloud pour appliquer des cadres de délimitation et des étiquettes. Pour en savoir plus, consultez la page Ajouter des libellés à des données à l'aide de la console Google Cloud.
Entraîner le modèle
Image
Comprendre comment Vertex AI utilise les ensembles de données lors de la création de modèles personnalisés
Votre ensemble de données contient des ensembles d'entraînement, de validation et de test. Si vous ne spécifiez pas cette répartition (consultez la section Préparer vos données), Vertex AI utilise par défaut 80 % de vos images pour l'entraînement, 10 % à des fins de validation et 10 % à des fins de test.
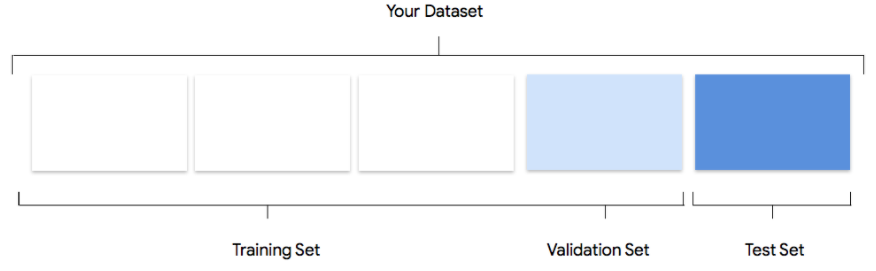
Ensemble d'entraînement
 La grande majorité de vos données doit figurer dans l'ensemble d'entraînement. Il s'agit des données auxquelles votre modèle accède pendant l'entraînement : elles sont utilisées pour apprendre les paramètres du modèle, à savoir la pondération des connexions entre les nœuds du réseau de neurones.
La grande majorité de vos données doit figurer dans l'ensemble d'entraînement. Il s'agit des données auxquelles votre modèle accède pendant l'entraînement : elles sont utilisées pour apprendre les paramètres du modèle, à savoir la pondération des connexions entre les nœuds du réseau de neurones.
Ensemble de validation
 L'ensemble de validation, parfois aussi appelé ensemble "dev", est également utilisé lors du processus d'entraînement.
Une fois que le framework d'apprentissage du modèle a incorporé les données d'entraînement à chaque itération du processus, il utilise les performances du modèle sur l'ensemble de validation pour ajuster ses hyperparamètres, qui sont des variables spécifiant sa structure. Si vous essayez d'utiliser l'ensemble d'entraînement pour régler les hyperparamètres, il est fort probable que le modèle finisse par trop se focaliser sur les données d'entraînement. Vous aurez alors du mal à généraliser le modèle à des exemples légèrement différents.
L'utilisation d'un ensemble de données relativement nouveau pour affiner la structure du modèle permet une meilleure généralisation du modèle à d'autres données.
L'ensemble de validation, parfois aussi appelé ensemble "dev", est également utilisé lors du processus d'entraînement.
Une fois que le framework d'apprentissage du modèle a incorporé les données d'entraînement à chaque itération du processus, il utilise les performances du modèle sur l'ensemble de validation pour ajuster ses hyperparamètres, qui sont des variables spécifiant sa structure. Si vous essayez d'utiliser l'ensemble d'entraînement pour régler les hyperparamètres, il est fort probable que le modèle finisse par trop se focaliser sur les données d'entraînement. Vous aurez alors du mal à généraliser le modèle à des exemples légèrement différents.
L'utilisation d'un ensemble de données relativement nouveau pour affiner la structure du modèle permet une meilleure généralisation du modèle à d'autres données.
Ensemble de test
 L'ensemble de test n'est pas du tout impliqué dans le processus d'entraînement. Une fois l'entraînement du modèle terminé, l'utilisation de l'ensemble de test représente un défi complètement nouveau pour le modèle. Ses performances sur l'ensemble de test sont supposées vous fournir une idée plutôt fidèle de son comportement sur des données réelles.
L'ensemble de test n'est pas du tout impliqué dans le processus d'entraînement. Une fois l'entraînement du modèle terminé, l'utilisation de l'ensemble de test représente un défi complètement nouveau pour le modèle. Ses performances sur l'ensemble de test sont supposées vous fournir une idée plutôt fidèle de son comportement sur des données réelles.
Répartition manuelle
 Vous pouvez également scinder votre ensemble de données vous-même. Il est judicieux de répartir manuellement vos données lorsque vous souhaitez exercer davantage de contrôle sur le processus, ou si vous souhaitez absolument inclure des exemples spécifiques dans une certaine partie du cycle de vie de l'entraînement d'un modèle.
Vous pouvez également scinder votre ensemble de données vous-même. Il est judicieux de répartir manuellement vos données lorsque vous souhaitez exercer davantage de contrôle sur le processus, ou si vous souhaitez absolument inclure des exemples spécifiques dans une certaine partie du cycle de vie de l'entraînement d'un modèle.
Tabulaire
Une fois votre ensemble de données importé, l'étape suivante consiste à entraîner un modèle. Vertex AI génère un modèle de machine learning fiable avec les valeurs d’entraînement par défaut, mais vous pouvez ajuster certains paramètres en fonction de votre cas d'utilisation.
Sélectionnez autant de colonnes de caractéristiques que possible pour l'entraînement, mais examinez chacune d'entre elles afin d'être certain de leur pertinence pour l'entraînement. Tenez compte des éléments suivants dans votre sélection :
- Ne sélectionnez pas de colonnes de caractéristiques qui produiront du bruit, comme les colonnes d'identifiants attribuées de manière aléatoire contenant une valeur unique pour chaque ligne.
- Assurez-vous de bien comprendre chaque colonne de caractéristique et les valeurs correspondantes.
- Si vous créez plusieurs modèles à partir d'un ensemble de données, supprimez les colonnes cibles qui ne font pas partie du problème de prédiction en cours.
- Rappelez-vous les principes d'équité : entraînez-vous le modèle avec une caractéristique qui pourrait conduire à une prise de décision biaisée ou injuste pour des groupes marginalisés ?
Comment Vertex AI utilise l'ensemble de données
Votre ensemble de données sera divisé en trois : ensemble d'entraînement, ensemble de validation et ensemble de test. La répartition par défaut que Vertex AI applique dépend du type de modèle que vous entraînez. Vous pouvez également spécifier les répartitions (répartitions manuelles) si nécessaire. Pour en savoir plus, consultez la section À propos des répartitions de données pour les modèles AutoML.
Ensemble d'entraînement
La grande majorité de vos données doit figurer dans l'ensemble d'entraînement. Il s'agit des données auxquelles votre modèle accède pendant l'entraînement : elles sont utilisées pour apprendre les paramètres du modèle, à savoir la pondération des connexions entre les nœuds du réseau de neurones.
Ensemble de validation
L'ensemble de validation, parfois aussi appelé ensemble "dev", est également utilisé lors du processus d'entraînement.
Une fois que le framework d'apprentissage du modèle a incorporé les données d'entraînement à chaque itération du processus, il utilise les performances du modèle sur l'ensemble de validation pour ajuster ses hyperparamètres, qui sont des variables spécifiant sa structure. Si vous essayez d'utiliser l'ensemble d'entraînement pour régler les hyperparamètres, il est fort probable que le modèle finisse par trop se focaliser sur les données d'entraînement. Vous aurez alors du mal à généraliser le modèle à des exemples légèrement différents.
L'utilisation d'un ensemble de données relativement nouveau pour affiner la structure du modèle permet une meilleure généralisation du modèle à d'autres données.
Ensemble de test
L'ensemble de test n'est pas du tout impliqué dans le processus d'entraînement. Une fois l'entraînement du modèle terminé, Vertex AI exploite l'ensemble de test qui représente un défi complètement nouveau pour le modèle.
Ses performances sur l'ensemble de test sont supposées vous fournir une idée plutôt fidèle de son comportement sur des données réelles.
Texte
Comprendre comment Vertex AI utilise votre ensemble de données pour créer un modèle personnalisé
Votre ensemble de données contient des ensembles d'entraînement, de validation et de test. Si vous ne spécifiez pas cette répartition comme décrit sur la page Préparer vos données, Vertex AI utilise automatiquement 80 % de vos documents textuels pour l'entraînement, 10 % pour la validation et 10 % pour les tests.
Ensemble d'entraînement
La grande majorité de vos données doit figurer dans l'ensemble d'entraînement. Il s'agit des données auxquelles votre modèle accède pendant l'entraînement : elles sont utilisées pour apprendre les paramètres du modèle, à savoir la pondération des connexions entre les nœuds du réseau de neurones.
Ensemble de validation
L'ensemble de validation, parfois aussi appelé ensemble "dev", est également utilisé lors du processus d'entraînement.
Une fois que le framework d'apprentissage du modèle a incorporé les données d'entraînement à chaque itération du processus, il utilise les performances du modèle sur l'ensemble de validation pour ajuster ses hyperparamètres, qui sont des variables spécifiant sa structure. Si vous essayez d'utiliser l'ensemble d'entraînement pour régler les hyperparamètres, il est fort probable que le modèle finisse par trop se focaliser sur les données d'entraînement. Vous aurez alors du mal à généraliser le modèle à des exemples légèrement différents.
L'utilisation d'un ensemble de données relativement nouveau pour affiner la structure du modèle permet une meilleure généralisation du modèle à d'autres données.
Ensemble de test
L'ensemble de test n'est pas du tout impliqué dans le processus d'entraînement. Une fois l'entraînement du modèle terminé, l'utilisation de l'ensemble de test représente un défi complètement nouveau pour le modèle. Ses performances sur l'ensemble de test sont supposées vous fournir une idée plutôt fidèle de son comportement sur des données réelles.
Répartition manuelle
Vous pouvez également scinder votre ensemble de données vous-même. Il est judicieux de répartir manuellement vos données lorsque vous souhaitez exercer davantage de contrôle sur le processus, ou si vous souhaitez absolument inclure des exemples spécifiques dans une certaine partie du cycle de vie de l'entraînement d'un modèle.
Vidéo
Une fois vos données vidéo d'entraînement préparées, vous êtes prêt à créer un modèle de machine learning. Notez que vous pouvez créer des ensembles d'annotations pour différents objectifs de modèle dans le même ensemble de données. Consultez la section Créer un ensemble d'annotations.
L'un des avantages de Vertex AI est que les paramètres par défaut vous guideront vers un modèle de machine learning fiable. En revanche, vous devrez peut-être les ajuster en fonction de la qualité de vos données et du résultat recherché. Exemple :
- Le type de prédiction est le niveau de granularité selon lequel vos vidéos sont traitées.
- La fréquence d'images est importante si les étiquettes que vous essayez de classer sont sensibles aux changements de mouvement, comme lors de la reconnaissance d'actions. Prenons par exemple courir, par opposition à marcher. Avec un faible nombre d'images par seconde (FPS), un extrait de marche pourrait ressembler à une course. Tout comme pour le suivi des objets, il est également sensible à la fréquence d'images. En pratique, l'objet à suivre doit avoir un chevauchement suffisant entre les images adjacentes.
- Pour le suivi des objets, la résolution est plus importante que la reconnaissance des actions ou la classification des vidéos. Lorsque les objets sont petits, assurez-vous d'importer les vidéos en haute résolution. Le pipeline actuel utilise uunn résolution de 256x256 pour l'entraînement standard, ou 512x512 s'il y a trop d'objets de petite taille (dont la zone est inférieure à 1 % de la zone de l'image) dans les données utilisateur. Nous vous recommandons d'utiliser des vidéos d'au moins 256 pixels. L'utilisation de vidéos en haute résolution pourrait ne pas aider à améliorer les performances du modèle, car les images internes sont sous-échantillonnées pour améliorer la vitesse d'entraînement et d'inférence.
Évaluer, tester et déployer votre modèle
Évaluer le modèle
Image
Une fois le modèle entraîné, vous recevez un résumé de ses performances. Cliquez sur Évaluation ou Voir l'évaluation complète pour afficher l'analyse détaillée.
 Le débogage d'un modèle consiste davantage à déboguer les données que le modèle proprement dit. Si, à un moment quelconque, votre modèle commence à se comporter de manière inattendue lorsque vous évaluez ses performances avant et après le passage en production, vous devez revenir en arrière et vérifier les données pour voir où elles pourraient être améliorées.
Le débogage d'un modèle consiste davantage à déboguer les données que le modèle proprement dit. Si, à un moment quelconque, votre modèle commence à se comporter de manière inattendue lorsque vous évaluez ses performances avant et après le passage en production, vous devez revenir en arrière et vérifier les données pour voir où elles pourraient être améliorées.
Quels types d'analyses puis-je effectuer dans Vertex AI ?
Dans la section d'évaluation de Vertex AI, vous pouvez évaluer les performances de votre modèle personnalisé en vous appuyant sur la sortie générée par le modèle sur les exemples de test et sur les principales statistiques d'apprentissage du machine learning. Dans cette section, nous aborderons la signification de chacun des concepts suivants :
- Les résultats du modèle
- Le seuil de score
- Les vrais positifs, les vrais négatifs, les faux positifs et les faux négatifs
- Précision et rappel
- Les courbes de précision/rappel
- Précision moyenne
Comment interpréter la sortie du modèle ?
Vertex AI extrait des exemples de vos données de test pour exposer votre modèle à de tout nouveaux défis. Pour chaque exemple, le modèle génère une série de nombres qui indiquent le degré de confiance selon lequel il associe chaque étiquette à cet échantillon. Si le nombre est élevé, le modèle conclut avec une confiance élevée que l'étiquette doit être attribuée à ce document.

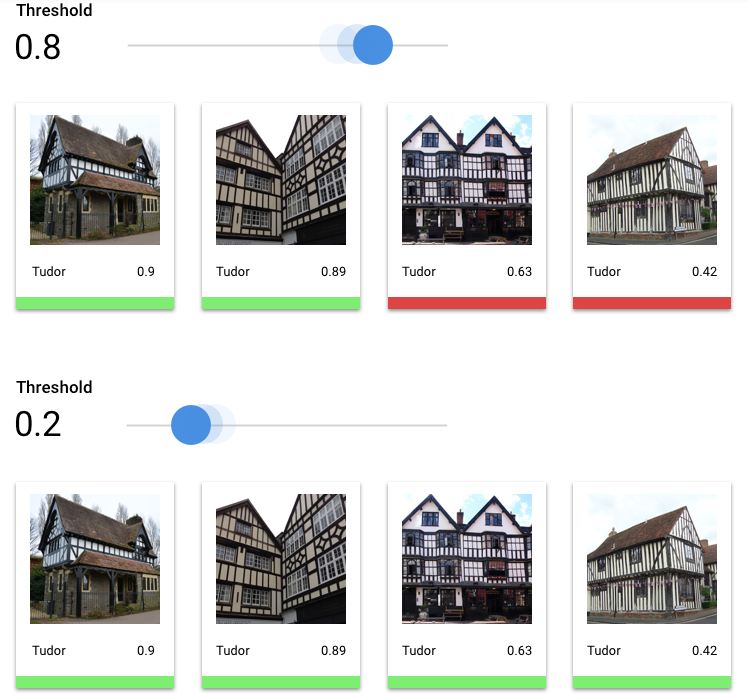
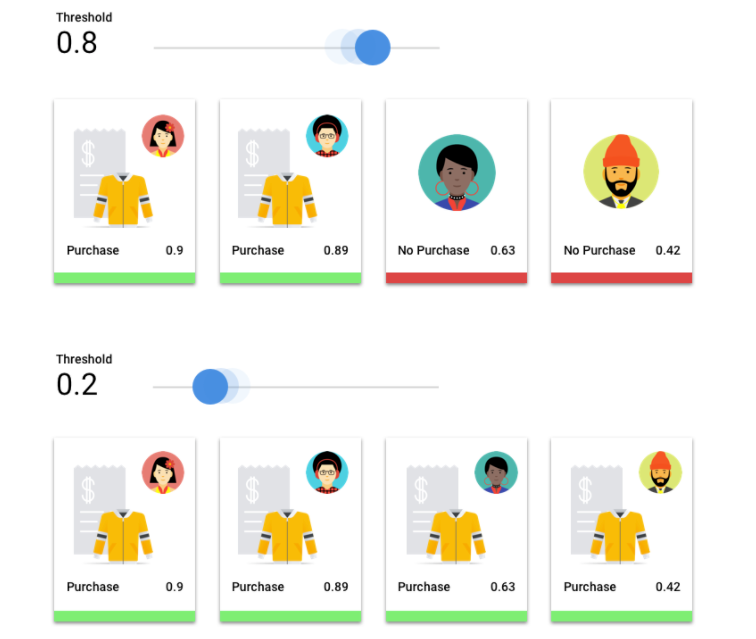
Qu'est-ce que le seuil de score ?
Nous pouvons convertir ces probabilités en valeurs binaires "on" ou "off" (0/1) en définissant un seuil de score.
Le seuil de score représente le degré de confiance que le modèle doit avoir pour attribuer une catégorie à un élément de test. Le curseur du seuil de score dans la console Google Cloud est un outil visuel permettant de tester l'effet de différents seuils pour toutes les catégories de votre ensemble de données, ainsi que pour des catégories individuelles.
Si le seuil de score est bas, votre modèle classera davantage d'images, au risque cependant de commettre quelques erreurs de classification. Si le seuil de score est élevé, le modèle classifie moins d'images, mais le risque de commettre des erreurs de classification est moindre. Vous pouvez effectuer des tests en modifiant les seuils par catégorie dans la console Google Cloud. Toutefois, lorsque vous utilisez votre modèle en production, vous devez appliquer les seuils que vous avez trouvés optimaux de votre côté.
En quoi consistent les vrais positifs, vrais négatifs, faux positifs et faux négatifs ?
Après application du seuil de score, les prédictions effectuées par votre modèle sont classées dans l’une des quatre catégories suivantes :
les seuils que vous avez constatés comme étant les plus performants.
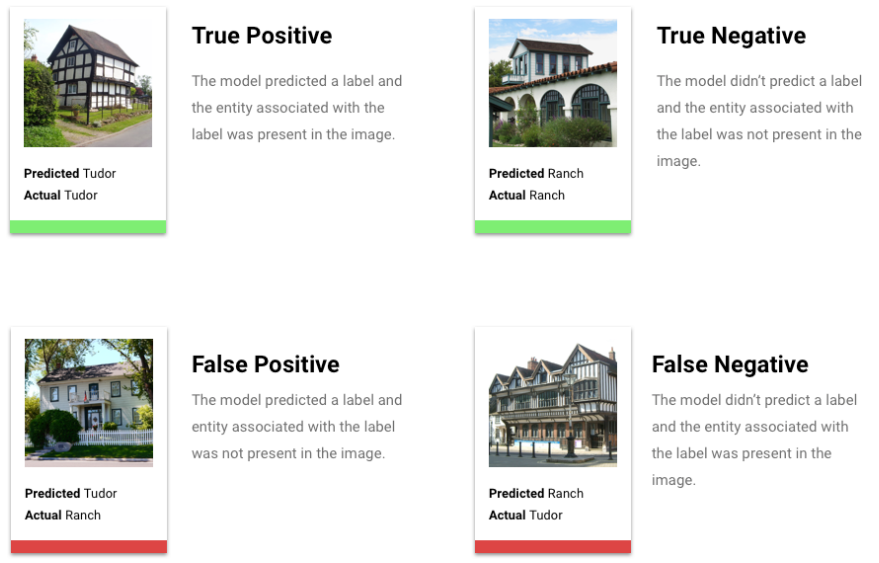
Ces catégories peuvent être utilisées pour calculer la précision et le rappel, des métriques permettant d'évaluer plus facilement l'efficacité d'un modèle.
Que sont la précision et le rappel ?
La précision et le rappel permettent d'évaluer la qualité de la collecte d'informations, ainsi que la quantité d'informations omises par un modèle. La précision indique le nombre d'exemples de test auxquels une étiquette a été correctement attribuée parmi tous les exemples classifiés. Le rappel indique le nombre d'exemples de test auxquels une étiquette donnée a été attribuée, parmi tous les exemples qui auraient dû être classifiés sous cette étiquette.
Dois-je privilégier l'optimisation de la précision ou celle du rappel ?
Selon votre cas d'utilisation, il se peut que vous souhaitiez privilégier la précision ou le rappel. Tenez compte des deux cas d'utilisation suivants lorsque vous décidez de l'approche qui vous convient le mieux.
Cas d'utilisation : confidentialité dans les images
Imaginons que vous vouliez créer un système capable de détecter automatiquement les informations sensibles et de les flouter.

Dans ce cas, les faux positifs correspondraient à des éléments qui ont été floutés alors que ce n'était pas nécessaire, ce qui peut être ennuyeux, mais non dommageable.

À l'inverse, les faux négatifs représenteraient des éléments qui auraient dû être floutés, mais qui ne l'ont pas été, tels que des données de carte de crédit, ce qui risque d'entraîner une usurpation d'identité.
Dans cette situation, il convient d'optimiser le paramètre de rappel. Cette statistique mesure le nombre de documents non détectés sur l'ensemble des prédictions effectuées. Un modèle disposant d'un taux de rappel élevé est susceptible d'attribuer une étiquette à des exemples dont la pertinence est faible, ce qui est utile dans les cas où une catégorie contient peu de données d'entraînement.
Cas d'utilisation : recherche dans les banques de photos
Imaginons que vous souhaitiez créer un système qui recherche la meilleure photo pour un mot clé donné.

Un faux positif dans ce cas renverrait une image non pertinente. Étant donné que votre produit est censé ne fournir que les images les plus adaptées, ce serait un échec complet.

Dans ce cas, un faux négatif ne renvoie pas une image pertinente pour une recherche par mot clé.
Dans la mesure où il existe des milliers de photos susceptibles de correspondre à de nombreux termes de recherche, ce ne serait pas un problème.
Dans cette situation, il convient d'optimiser le paramètre de précision. Cette statistique mesure l'exactitude de l'ensemble des prédictions effectuées. Un modèle disposant d'un taux de précision élevé est susceptible de n'indiquer que les exemples les plus pertinents, ce qui est utile dans les cas où une classe est récurrente dans les données d'entraînement.
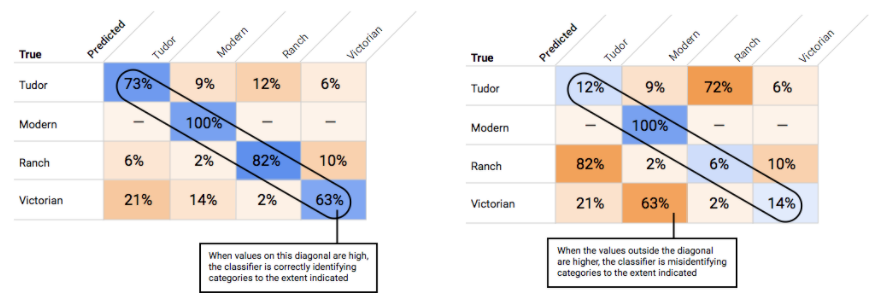
Comment utiliser la matrice de confusion ?
Comment interpréter les courbes de précision/rappel ?
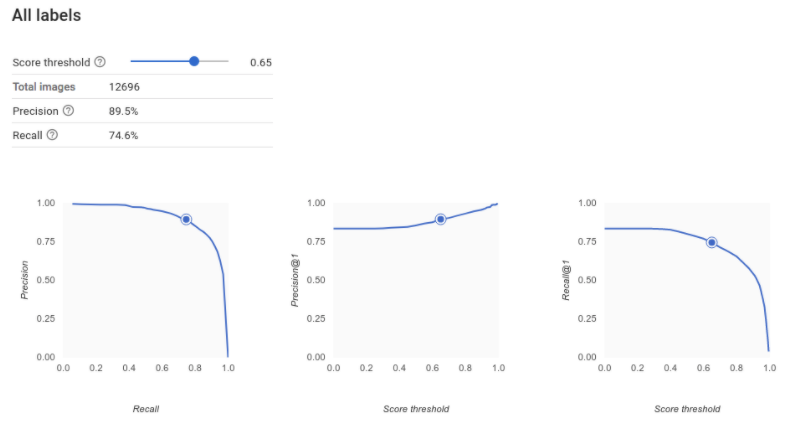
L'outil de seuil de score permet de découvrir comment le seuil choisi affecte la précision et le rappel. En faisant glisser le curseur le long de la barre du seuil de score, vous pouvez voir où se situe ce seuil sur la courbe de compromis précision/rappel, ainsi que son effet sur ces paramètres (Pour les modèles multiclasses, les paramètres de précision et de rappel de ces graphiques indiquent que l'unique étiquette utilisée pour calculer ces métriques correspond à celle la mieux notée parmi l'ensemble d'étiquettes renvoyées). Cela permet de trouver un bon équilibre entre les faux positifs et les faux négatifs.
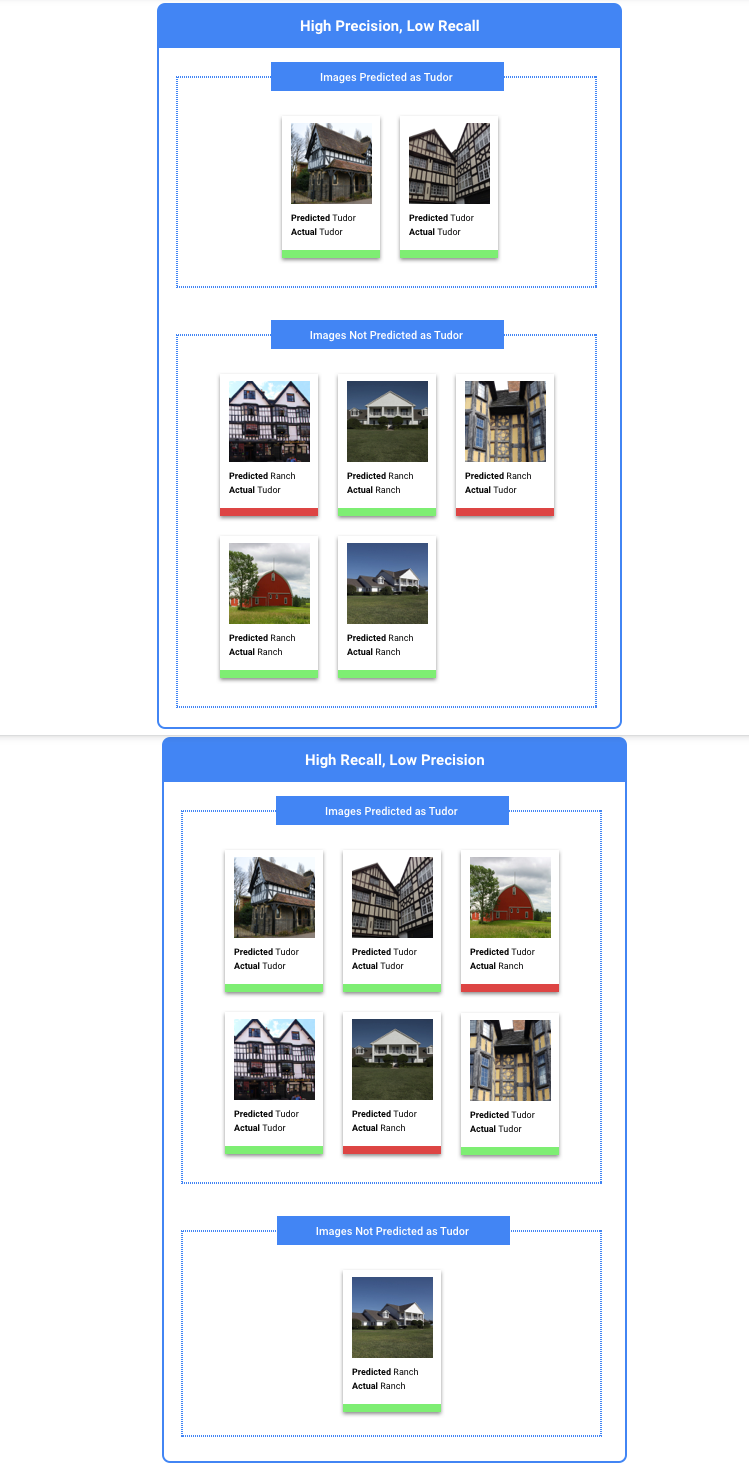
Une fois que vous avez choisi un seuil qui vous semble globalement acceptable pour votre modèle, cliquez sur les étiquettes individuelles afin de voir, pour chacune d'elles, où se situe ce seuil sur la courbe de précision/rappel. Dans certains cas, cela peut impliquer un grand nombre de prédictions incorrectes pour certaines étiquettes, ce qui peut vous conduire à définir un seuil personnalisé pour les classes correspondant à ces étiquettes. Supposons que vous examiniez l'ensemble de données des maisons et que vous remarquiez qu'un seuil de 0,5 dispose d'un taux de précision et de rappel convenable pour tous les types d'images, à l'exception du style "Tudor", probablement en raison du caractère très général de cette catégorie. Vous constatez en effet une multitude de faux positifs pour cette catégorie. Dans ce cas, vous pouvez décider d'utiliser un seuil de 0,8 uniquement pour la catégorie "Tudor", lorsque vous appelez le classificateur pour effectuer des prédictions.
Qu'est-ce que la précision moyenne ?
La zone sous la courbe de précision/rappel constitue une métrique utile pour cerner la précision du modèle. Elle permet de mesurer les performances de votre modèle vis-à-vis de l'ensemble des seuils de score. Dans Vertex AI, cette statistique s'appelle la précision moyenne. Plus ce score est proche de 1, meilleures seront les performances de votre modèle sur l'ensemble de test. Pour un modèle effectuant des prédictions de manière aléatoire pour chaque étiquette, la précision moyenne obtenue avoisinerait le score de 0,5.
Tabulaire
Après avoir entraîné le modèle, vous recevez un résumé de ses performances. Les métriques d'évaluation du modèle sont basées sur ses performances par rapport à une tranche de l'ensemble de données (ensemble de données de test). Il existe plusieurs métriques et concepts clés à prendre en compte pour déterminer si votre modèle est prêt à traiter des données réelles.
Métriques de classification
Seuil de score
Examinons un modèle de machine learning qui prédit si un client achètera un blouson l’année prochaine. Quel doit être le degré de certitude du modèle avant de prédire qu'un client donné achètera un blouson ? Dans les modèles de classification, un score de confiance est attribué à chaque prédiction, soit une évaluation numérique de la certitude du modèle quant à l'exactitude de la classe prédite. Le seuil de score est la valeur numérique qui détermine le moment où un score donné est converti en une décision positive ou négative, c'est-à-dire la valeur à laquelle le modèle indique "oui, ce score de confiance est suffisamment élevé pour conclure que ce client achètera un blouson au cours de la prochaine année".
Si votre seuil de score est bas, votre modèle risque de générer des erreurs de classification. C'est pourquoi ce seuil devrait être déterminé en fonction d'un cas d'utilisation donné.
Résultats de prédiction
Après l'application du seuil de score, les prédictions effectuées par votre modèle entrent dans l'une des quatre catégories ci-dessous. Pour comprendre ces catégories, imaginons à nouveau un modèle de classification binaire pour un blouson. Dans cet exemple, la classe positive (ce que le modèle tente de prédire) est que le client achètera un blouson l'année prochaine.
- Vrai positif : le modèle prédit correctement la classe positive. Le modèle a correctement prédit qu'un client allait acheter un blouson.
- Faux positif : le modèle prédit incorrectement la classe positive. Le modèle a prédit qu'un client allait acheter un blouson, ce qu'il n'a pas fait.
- Vrai négatif : le modèle prédit correctement la classe négative. Le modèle a correctement prédit qu'un client n'allait pas acheter de blouson.
- Faux négatif : le modèle prédit incorrectement une classe négative. Le modèle a prédit qu'un client n'allait pas acheter de blouson, or c'est ce qu'il a fait.

Précision et rappel
Les métriques de précision et de rappel permettent d'évaluer la capacité de votre modèle à capturer des informations et à en laisser certaines de côté. En savoir plus sur la précision et le rappel.
- La précision est la fraction des prédictions positives qui étaient correctes. Quelle était la fraction d'achats réels de toutes les prédictions d'achat d'un client ?
- Le rappel est la fraction des lignes comportant cette étiquette que le modèle a correctement prédites. Quelle était la fraction de tous les achats clients qui auraient pu être identifiés ?
Selon votre cas d'utilisation, vous devrez peut-être optimiser la précision ou le rappel.
Autres métriques de classification
- AUC PR : aire sous la courbe de précision/rappel (PR). Cette valeur est comprise entre zéro et un. Plus elle est élevée, plus le modèle est de bonne qualité.
- AUC ROC : aire sous la courbe ROC (Receiver Operating Characteristic). Cette valeur est comprise entre zéro et un. Plus elle est élevée, plus le modèle est de bonne qualité.
- Justesse : fraction des prédictions de classification produites par le modèle qui étaient correctes.
- Perte logistique : entropie croisée entre les prédictions du modèle et les valeurs cibles. Cette valeur varie de zéro à l'infini. Plus elle est faible, plus le modèle est de bonne qualité.
- Score F1 : moyenne harmonique de la précision et du rappel. F1 est une métrique utile si vous souhaitez équilibrer précision et rappel, et que les classes sont réparties de façon inégale.
Métriques de prévision et de régression
Une fois votre modèle créé, Vertex AI fournit une variété de métriques standards que vous pouvez examiner. Il n'existe pas de réponse parfaite quant à la façon d'évaluer un modèle. Considérez les métriques d'évaluation dans le contexte de votre type de problème et de ce que vous souhaitez obtenir avec votre modèle. La liste suivante présente certaines métriques que Vertex AI peut fournir.
Erreur absolue moyenne (EAM)
L'EAM correspond à l'écart absolu moyen entre les valeurs cibles et les valeurs prédites. Cette métrique mesure la magnitude moyenne des erreurs dans un ensemble de prédictions, soit la différence entre une valeur cible et une valeur prédite. En outre, comme elle utilise des valeurs absolues, l'EAM ne prend pas en compte l'orientation de la relation et n'indique ni sous-performance, ni surperformance. Lors de l'évaluation de l'EAM, une valeur inférieure indique un modèle de qualité supérieure (0 représentant un prédicteur parfait).
Racine carrée de l'erreur quadratique moyenne (RMSE)
La RMSE correspond à la racine carrée de l'écart moyen au carré entre la valeur cible et la valeur prédite. La RMSE est plus sensible aux anomalies que l'EAM. Par conséquent, si vous craignez des erreurs importantes, cette métrique est sans doute plus utile pour procéder à une évaluation. Comme pour l'EAM, une valeur inférieure indique un modèle de qualité supérieure (0 représentant un prédicteur parfait).
Erreur logarithmique quadratique moyenne (RMSLE)
La RMSLE est équivalente à la RMSE sur une échelle logarithmique. La RMSLE est plus sensible aux erreurs relatives qu'aux erreurs absolues et se focalise davantage sur la sous-performance que sur la surperformance.
Quantile observé (prévisions uniquement)
Pour un quantile cible donné, le quantile observé indique la fraction réelle des valeurs observées en dessous des valeurs de prédiction des quantiles spécifiées. Le quantile observé montre à quel point le modèle est éloigné ou proche du quantile cible. Une différence plus faible entre les deux valeurs indique un modèle de meilleure qualité.
Perte pinball mise à l'échelle (prévision uniquement)
Mesure la qualité d'un modèle à un quantile cible donné. Plus le nombre est faible, plus le modèle est de bonne qualité. Vous pouvez comparer la métrique de perte pinball mise à l'échelle à différents quantiles pour déterminer la justesse relative de votre modèle entre ces différents quantiles.
Texte
Une fois le modèle entraîné, vous recevez un résumé de ses performances. Pour afficher une analyse détaillée, cliquez sur Évaluation ou Voir l'évaluation complète.
Que dois-je garder à l'esprit avant d'évaluer un modèle ?
Le débogage d'un modèle consiste davantage à déboguer les données que le modèle proprement dit. Si votre modèle commence à agir de manière inattendue alors que vous évaluez ses performances avant et après le passage en production, vous devez de nouveau vérifier vos données afin d'identifier des axes d'amélioration.
Quels types d'analyses puis-je effectuer dans Vertex AI ?
Dans la section d'évaluation de Vertex AI, vous pouvez évaluer les performances de votre modèle personnalisé en vous appuyant sur la sortie générée par le modèle sur les exemples de test et sur les principales statistiques d'apprentissage du machine learning. Cette section explique la signification de chacun des concepts suivants :
- Les résultats du modèle
- Le seuil de score
- Les vrais positifs, les vrais négatifs, les faux positifs et les faux négatifs
- La précision et le rappel
- Les courbes de précision/rappel
- Précision moyenne
Comment interpréter la sortie du modèle ?
Vertex AI extrait des exemples de vos données de test pour exposer votre modèle à de nouveaux défis. Pour chaque exemple, le modèle génère une série de nombres qui indiquent le degré de confiance selon lequel il associe chaque étiquette à cet échantillon. Si le nombre est élevé, le modèle conclut avec une confiance élevée que l'étiquette doit être attribuée à ce document.
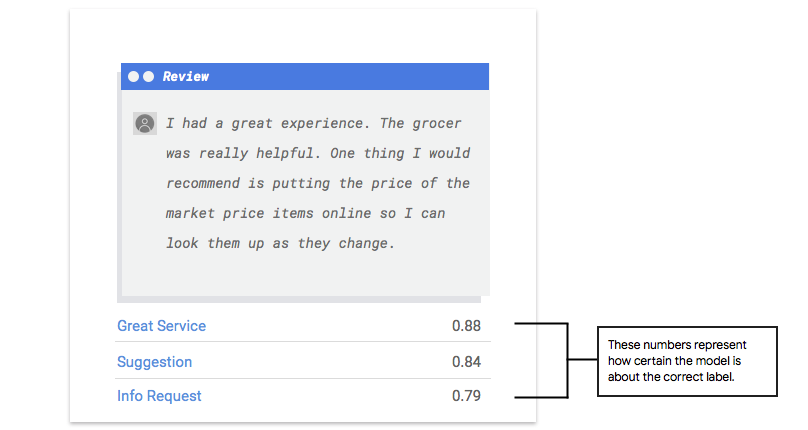
Qu'est-ce que le seuil de score ?
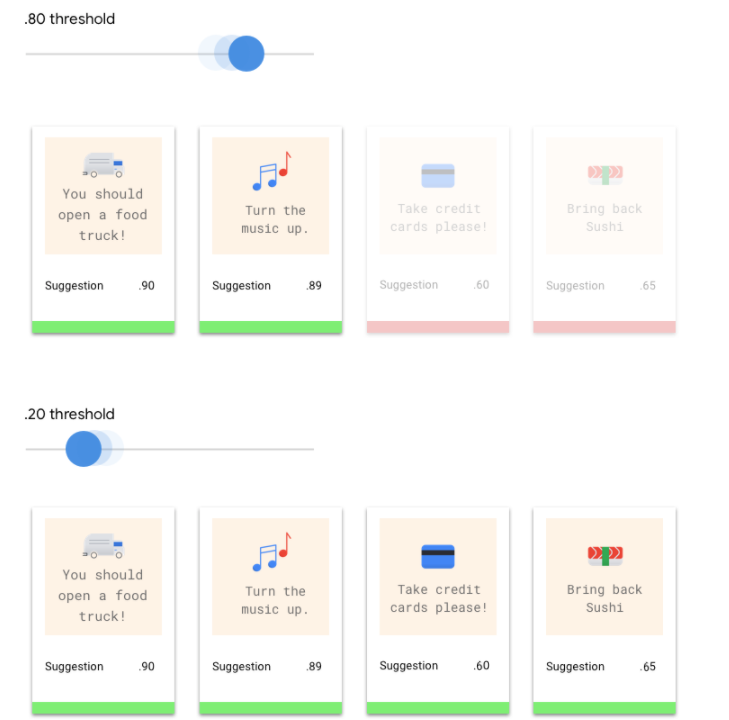
Le seuil de score permet à Vertex AI de convertir les probabilités en valeurs binaires "on"/"off". Le seuil de score représente le degré de confiance que le modèle doit avoir pour attribuer une catégorie à un élément de test. Le curseur du seuil du score dans la console est un outil visuel permettant de tester l'impact des différents seuils dans votre ensemble de données. Dans l'exemple ci-dessus, si nous définissons le seuil de score sur 0,8 pour toutes les catégories, les étiquettes "Excellent service" et "Suggestion" seront attribuées, mais pas "Demande d'informations". Si votre seuil de score est faible, votre modèle classera davantage d'éléments textuels, mais risque de mal classer plus d'éléments textuels par la même occasion. Si votre seuil de score est élevé, le modèle classera moins d'éléments textuels, mais le risque d'erreur de classification de ces éléments sera moindre. Vous pouvez effectuer des tests en modifiant les seuils par catégorie dans la console Google Cloud.
Toutefois, lorsque vous utilisez votre modèle en production, vous devez appliquer les seuils que vous avez trouvés optimaux de votre côté.
En quoi consistent les vrais positifs, vrais négatifs, faux positifs et faux négatifs ?
Après application du seuil de score, les prédictions effectuées par votre modèle sont classées dans l'une des quatre catégories suivantes.
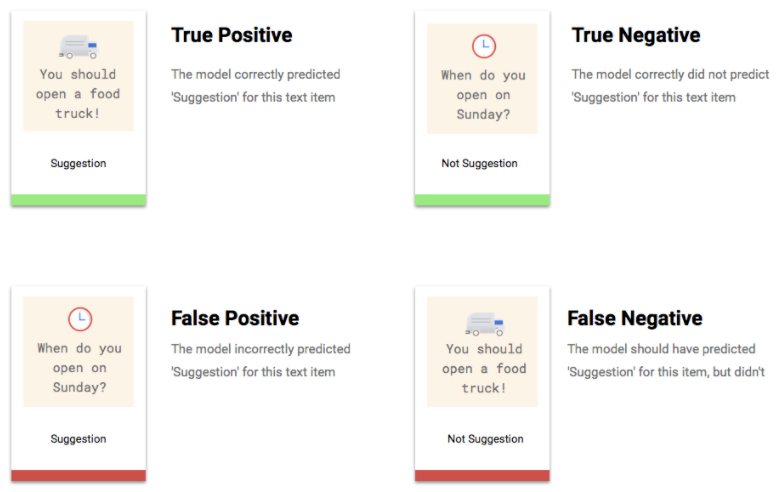
Ces catégories peuvent être utilisées pour calculer la précision et le rappel, des statistiques permettant d'évaluer plus facilement l'efficacité d'un modèle.
Que sont la précision et le rappel ?
La précision et le rappel permettent d'évaluer la qualité de la collecte d'informations, ainsi que la quantité d'informations omises par un modèle. La précision indique le nombre d'exemples de test auxquels une étiquette a été correctement attribuée parmi tous les exemples classifiés. Le rappel indique le nombre d'exemples de test auxquels une étiquette donnée a été attribuée, parmi tous les exemples qui auraient dû être classifiés sous cette étiquette.
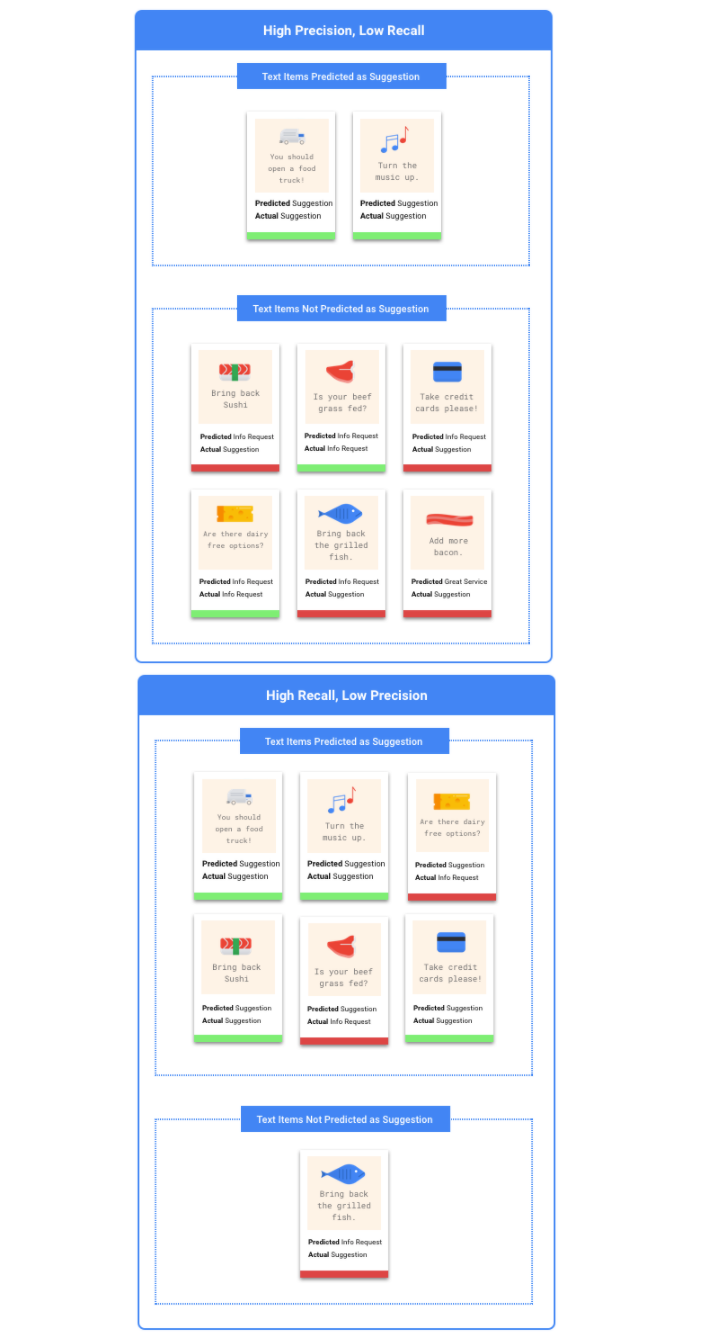
Dois-je privilégier l'optimisation de la précision ou celle du rappel ?
Selon votre cas d'utilisation, il se peut que vous souhaitiez privilégier la précision ou le rappel. Tenez compte des deux cas d'utilisation suivants lorsque vous décidez de l'approche qui vous convient le mieux.
Cas d'utilisation : documents urgents
Imaginons que vous souhaitiez créer un système capable de hiérarchiser les documents urgents par rapport à ceux qui ne le sont pas.

Dans ce cas, un faux positif correspond à un document qui n’est pas urgent, mais qui est indiqué comme tel.
L'utilisateur peut le classifier de nouveau comme non urgent avant de consulter les autres documents.

Dans ce cas, un faux négatif correspond à un document urgent, mais non détecté comme tel par le système. Cela risque d'entraîner des problèmes.
Dans cette situation, il convient d'optimiser le paramètre de rappel. Cette statistique mesure le nombre de documents non détectés sur l'ensemble des prédictions effectuées. Un modèle disposant d'un taux de rappel élevé est susceptible d'attribuer une étiquette à des exemples dont la pertinence est faible, ce qui est utile dans les cas où une catégorie contient peu de données d'entraînement.
Cas d'utilisation : filtre anti-spam
Supposons que vous souhaitiez créer un système permettant de filtrer automatiquement les e-mails en séparant les spams des autres messages.

Dans ce cas, un faux négatif correspond à un spam non détecté qui s'affiche dans votre boîte de réception. En général, c'est un peu frustrant.

Dans ce cas, un faux positif correspond à un e-mail signalé à tort comme du spam, et qui est supprimé de votre boîte de réception. Si l'e-mail était important, cela peut avoir une incidence négative sur l'utilisateur.
Dans cette situation, il convient d'optimiser le paramètre de précision. Cette statistique mesure l'exactitude de l'ensemble des prédictions effectuées. Un modèle disposant d'un taux de précision élevé est susceptible de n'indiquer que les exemples les plus pertinents, ce qui est utile dans les cas où une catégorie est récurrente dans les données d'entraînement.
Comment utiliser la matrice de confusion ?
Nous pouvons comparer les performances du modèle pour chaque étiquette en utilisant une matrice de confusion. Dans un modèle idéal, toutes les valeurs comprises dans la diagonale de la matrice sont élevées, et toutes les autres valeurs sont faibles. Cela indique que les catégories souhaitées sont correctement identifiées. Si d'autres valeurs sont élevées, cela permet de comprendre les motifs d'erreurs de classification des éléments d'évaluation du modèle.
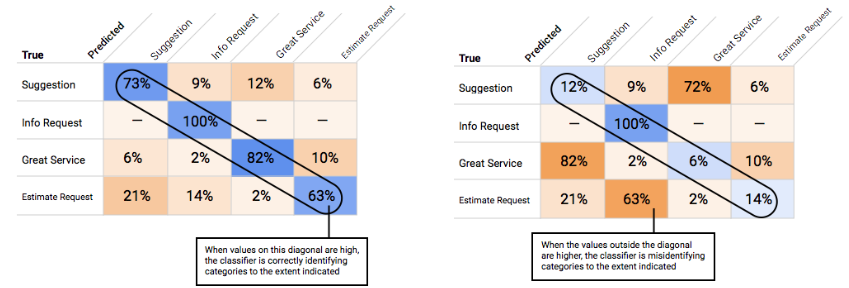
Comment interpréter les courbes de précision et de rappel ?
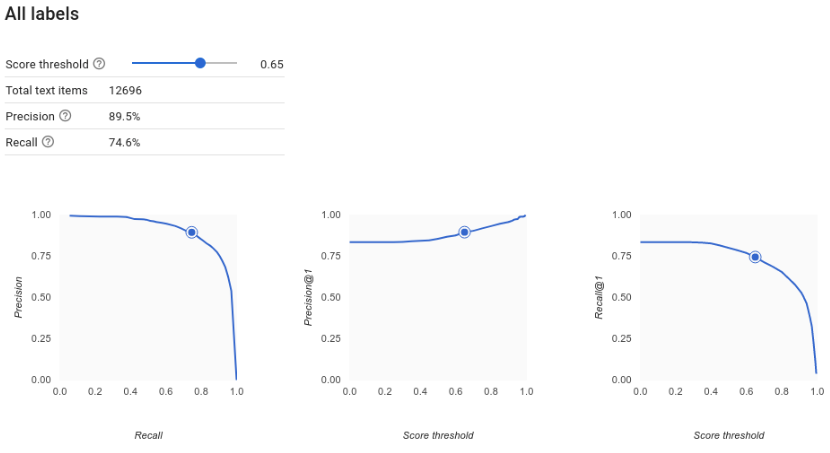
L'outil de seuil de score permet de découvrir comment le seuil choisi affecte la précision et le rappel. En faisant glisser le curseur le long de la barre du seuil de score, vous pouvez voir où se situe ce seuil sur la courbe de compromis précision/rappel, ainsi que son effet sur ces paramètres (Pour les modèles multiclasses, les paramètres de précision et de rappel de ces graphiques indiquent que l'unique étiquette utilisée pour calculer ces métriques correspond à celle la mieux notée parmi l'ensemble d'étiquettes renvoyées). Cela permet de trouver un bon équilibre entre les faux positifs et les faux négatifs.
Une fois que vous avez choisi un seuil qui vous semble globalement acceptable pour votre modèle, vous pouvez cliquer sur des étiquettes spécifiques afin de voir, pour chacune d'elles, où se situe ce seuil sur la courbe de précision/rappel. Dans certains cas, cela peut impliquer un grand nombre de prédictions incorrectes pour certaines étiquettes, ce qui peut vous conduire à définir un seuil personnalisé pour les classes correspondant à ces étiquettes. Supposons, par exemple, que vous examiniez l'ensemble de données contenant les commentaires de vos clients et que vous remarquiez qu'un seuil de 0,5 dispose d'un taux de précision et de rappel convenable pour tous les types de commentaires, à l'exception des suggestions. Vous constatez en effet une multitude de faux positifs pour cette catégorie. Dans ce cas, vous pouvez décider d'utiliser un seuil de 0,8 uniquement pour la catégorie "Suggestion", lorsque vous appelez le classificateur pour effectuer des prédictions.
Qu'est-ce que la précision moyenne ?
La zone sous la courbe de précision/rappel constitue une métrique utile pour cerner la précision du modèle. Elle permet de mesurer les performances de votre modèle vis-à-vis de l'ensemble des seuils de score. Dans Vertex AI, cette statistique s'appelle la précision moyenne. Plus ce score est proche de 1, meilleures seront les performances de votre modèle sur l'ensemble de test. Pour un modèle effectuant des prédictions de manière aléatoire pour chaque étiquette, la précision moyenne obtenue avoisinerait le score de 0,5.
Vidéo
Après avoir entraîné le modèle, vous recevez un résumé de ses performances. Les métriques d'évaluation du modèle sont basées sur ses performances par rapport à une tranche de l'ensemble de données (ensemble de données de test). Il existe plusieurs métriques et concepts clés à prendre en compte pour déterminer si votre modèle est prêt à être utilisé avec de nouvelles données.
Seuil de score
Comment un modèle de machine learning sait-il qu'un tir au but est réellement un but ? Un score de confiance est attribué à chaque prédiction. Il s'agit d'une évaluation numérique de la certitude du modèle qu'une séquence vidéo donnée contient une classe. Le seuil de score est le nombre qui détermine le moment où un score donné est converti en décision positive ou négative, c'est-à-dire la valeur à laquelle votre modèle indique "oui, ce nombre de confiance est suffisamment élevé pour conclure que cette séquence vidéo contient un but".

Si le seuil de score est bas, votre modèle risque de ne pas étiqueter correctement les séquences vidéo. C'est pourquoi ce seuil devrait être déterminé en fonction d'un cas d'utilisation donné. Par exemple, imaginez un cas d'utilisation médicale tel que la détection du cancer, où les conséquences d'un mauvais étiquetage sont plus lourdes que celles de l'étiquetage incorrect de vidéos sportives. La détection du cancer justifie donc un seuil de score plus élevé.
Résultats de prédiction
Après l'application du seuil de score, les prédictions effectuées par votre modèle entrent dans l'une des quatre catégories ci-dessous. Pour comprendre ces catégories, imaginons que vous ayez construit un modèle permettant de détecter si une séquence donnée contient un but au football (ou non). Dans cet exemple, le but correspond à la classe positive (ce que le modèle tente de prédire).
- Vrai positif : le modèle prédit correctement la classe positive. Le modèle a correctement prédit la présence d'un but dans la séquence vidéo.
- Faux positif : le modèle prédit incorrectement la classe positive. Le modèle a prédit la présence d'un but dans la séquence, mais en réalité il n'y en avait pas.
- Vrai négatif : le modèle prédit correctement la classe négative. Le modèle a prédit correctement l'absence de but dans la séquence.
- Faux négatif : le modèle prédit incorrectement une classe négative. Le modèle a prédit l'absence de but dans la séquence, alors qu'en réalité il y en avait un.

Précision et rappel
Les métriques de précision et de rappel permettent d'évaluer la capacité de votre modèle à capturer des informations et à en laisser certaines de côté. En savoir plus sur la précision et le rappel.
- La précision est la fraction des prédictions positives qui étaient correctes. Parmi toutes les prédictions étiquetées "but", quelle fraction contient réellement un but ?
- Le rappel est la fraction de toutes les prédictions positives qui ont été réellement identifiées. Parmi tous les buts de football qui auraient pu être identifiés, quelle fraction de ces buts l'ont été ?
Selon votre cas d'utilisation, vous devrez peut-être optimiser la précision ou le rappel. Voici quelques exemples de cas d'utilisation :
Cas d'utilisation : informations personnelles contenues dans des vidéos
Imaginez que vous développiez un logiciel qui détecte et floute automatiquement les informations sensibles dans une vidéo. Les faux résultats peuvent inclure les conséquences suivantes :
- Un faux positif identifie un élément qui n'a pas besoin d'être censuré, mais qui l'est quand même. Cela pourrait être gênant mais pas préjudiciable.
- Un faux négatif ne permet pas d'identifier les informations à censurer, telles qu'un numéro de carte de crédit. Cela aurait pour effet de divulguer des informations personnelles, ce qui constitue le pire des cas.
Dans ce cas d'utilisation, il est essentiel d'optimiser le rappel pour s'assurer que le modèle détecte tous les éléments pertinents. Un modèle optimisé pour le rappel est plus susceptible d'étiqueter des exemples marginalement pertinents, mais également plus susceptible d'étiqueter des exemples incorrects (floutant plus d'informations que nécessaire).
Cas d'utilisation : recherche au sein d'une vidéothèque
Supposons que vous souhaitiez créer un logiciel permettant aux utilisateurs de lancer une recherche dans une vidéothèque à partir d'un mot clé. Considérez les résultats incorrects :
- Un faux positif renvoie une vidéo non pertinente. Étant donné que votre système tente de renvoyer seulement des vidéos pertinentes, il ne fait pas vraiment ce pour quoi il a été conçu.
- Un faux négatif ne renvoie pas une vidéo pourtant pertinente. Étant donné que de nombreux mots clés renvoient des centaines de vidéos, ce problème n'est pas aussi grave que de renvoyer une vidéo non pertinente.
Dans cet exemple, il faudra optimiser la précision pour que votre modèle renvoie des résultats à la fois très pertinents et corrects. Un modèle de haute précision ne traitera probablement que les exemples les plus pertinents, mais peut en laisser certains de côté. En savoir plus sur les métriques d'évaluation de modèle.
Tester votre modèle
Image
Pour tester un modèle, Vertex AI utilise 10 % de vos données par défaut (ou le pourcentage de données défini si vous avez choisi de les répartir vous-même). La page "Évaluation" vous indique les performances du modèle sur les données de test. Toutefois, si vous souhaitez contrôler l'intégrité du modèle, plusieurs solutions s'offrent à vous. Le plus simple consiste à importer quelques images sur la page "Déployer et tester" et d'examiner les étiquettes que le modèle choisit pour vos exemples. Elles devraient correspondre à vos attentes. Testez quelques exemples pour chaque type d'image que vous pensez recevoir.
Si vous souhaitez utiliser votre modèle dans vos propres tests automatisés, la page "Déployer et tester" vous indique comment appeler le modèle par programmation.
Tabulaire
L'évaluation des métriques de votre modèle consiste principalement à déterminer s'il est prêt à être déployé, mais vous pouvez également le tester avec de nouvelles données. Importez d'autres données pour vérifier si les prédictions du modèle correspondent à vos attentes. En fonction des métriques d'évaluation ou des tests avec de nouvelles données, vous devrez peut-être continuer à améliorer les performances du modèle.
Texte
Pour tester un modèle, Vertex AI utilise 10 % de vos données par défaut (ou le pourcentage de données défini si vous avez choisi de les répartir vous-même). La page Évaluation vous indique les performances du modèle sur les données de test. Toutefois, si vous souhaitez vérifier votre modèle, plusieurs solutions s'offrent à vous. Après avoir déployé votre modèle, vous pouvez saisir des exemples textuels dans le champ de la page Déployer et tester, puis examiner les étiquettes choisies par le modèle pour vos exemples. Elles devraient correspondre à vos attentes. Essayez de saisir quelques exemples pour chaque type de commentaire que vous pensez recevoir.
Si vous souhaitez utiliser votre modèle dans vos propres tests automatisés, la page Déployer et tester fournit un exemple de requête API qui vous montre comment appeler le modèle par programmation.
Si vous souhaitez utiliser votre modèle dans vos propres tests automatisés, la page Déployer et tester fournit un exemple de requête API qui vous montre comment appeler le modèle par programmation.
Sur la page Prédictions par lot, vous pouvez créer une prédiction par lot, qui regroupe de nombreuses requêtes de prédiction en une seule. Une prédiction par lot est asynchrone, ce qui signifie que le modèle attendra d'avoir traité toutes les requêtes de prédiction avant de renvoyer les résultats.
Vidéo
Les vidéos de Vertex AI utilisent automatiquement 20 % de vos données (ou le pourcentage de données que vous avez choisi d'utiliser si vous avez choisi de les répartir vous-même) pour tester le modèle. L'onglet "Évaluer" de la console vous indique les performances du modèle avec ces données de test. Toutefois, si vous souhaitez vérifier votre modèle, plusieurs solutions s'offrent à vous. L'une d'elles consiste à spécifier un fichier CSV de données vidéo à tester dans l'onglet "Test et utilisation" et à examiner les étiquettes que le modèle prédit pour ces vidéos. Elles devraient correspondre à vos attentes.
Pour visualiser les prédictions, vous pouvez ajuster le seuil et examiner les prédictions selon trois échelles temporelles : à des intervalles de 1 seconde, aux prises de vue après détection automatique des limites de prises de vues et à la fin de séquences vidéo complètes.
Déployer le modèle
Image
Lorsque vous êtes satisfait des performances de votre modèle, il est temps de l'utiliser dans la réalité. Quel que soit votre cas d'utilisation, qu'il s'agisse de l'appliquer en production ou de traiter une requête de prédiction unique, vous pouvez exploiter votre modèle de différentes manières.
Prédiction par lot
La prédiction par lot est utile pour effectuer plusieurs requêtes de prédiction à la fois. La prédiction par lot est asynchrone, ce qui signifie que le modèle attend d'avoir traité toutes les requêtes de prédiction avant de renvoyer un fichier JSON Lines contenant les valeurs de prédiction.
Prédiction en ligne
Déployez votre modèle pour le rendre disponible aux requêtes de prédiction à l'aide d'une API REST. Les prédictions en ligne sont synchrones (en temps réel), ce qui signifie qu'elles sont renvoyées rapidement, mais le système n'accepte qu'une seule requête de prédiction par appel de l'API. Les prédictions en ligne sont utiles si votre modèle est intégré à une application et que certaines parties de votre système dépendent d'une résolution rapide des prédictions.
Tabulaire
Lorsque vous êtes satisfait des performances de votre modèle, il est temps de l'utiliser dans la réalité. Quel que soit votre cas d'utilisation, qu'il s'agisse de l'appliquer en production ou de traiter une requête de prédiction unique, vous pouvez exploiter votre modèle de différentes manières.
Prédiction par lot
La prédiction par lot est utile pour effectuer plusieurs requêtes de prédiction à la fois. La prédiction par lot est asynchrone, c'est-à-dire que le modèle attend d'avoir traité toutes les requêtes de prédiction avant de renvoyer un fichier CSV ou une table BiqQuery contenant les valeurs de prédiction.
Prédiction en ligne
Déployez votre modèle pour le rendre disponible aux requêtes de prédiction à l'aide d'une API REST. Les prédictions en ligne sont synchrones (en temps réel), ce qui signifie qu'elles sont renvoyées rapidement, mais le système n'accepte qu'une seule requête de prédiction par appel de l'API. Les prédictions en ligne sont utiles si votre modèle est intégré à une application et que certaines parties de votre système dépendent d'une résolution rapide des prédictions.
Vidéo
Lorsque vous êtes satisfait des performances de votre modèle, il est temps de l'utiliser dans la réalité. Vertex AI s'appuie sur la prédiction par lot, ce qui vous permet de télécharger un fichier CSV avec des chemins de fichiers vers des vidéos hébergées sur Cloud Storage. Votre modèle traitera chaque vidéo et générera les prédictions dans un autre fichier CSV. La prédiction par lot est asynchrone, ce qui signifie que le modèle traitera toutes les requêtes de prédiction avant de générer les résultats.
Effectuer un nettoyage
Pour éviter des frais inutiles, annulez le déploiement de votre modèle lorsqu'il n'est pas utilisé.
Lorsque vous avez terminé d'utiliser votre modèle, supprimez les ressources que vous avez créées pour éviter que des frais inutiles ne soient facturés sur votre compte.
- Données d'images Hello : nettoyer votre projet
- Données tabulaires Hello : nettoyer votre projet
- Données textuelles Hello : nettoyer votre projet
- Données vidéo Hello : nettoyer votre projet