Esta página descreve como o Cloud TPU funciona com o Google Kubernetes Engine (GKE), incluindo a terminologia, as vantagens das unidades de processamento de tensores (TPUs) e considerações sobre o agendamento de cargas de trabalho. As TPUs são circuitos integrados específicos da aplicação (ASICs) desenvolvidos pela Google para acelerar cargas de trabalho de ML que usam frameworks como o TensorFlow, o PyTorch e o JAX.
Esta página destina-se a administradores e operadores da plataforma, bem como a especialistas em dados e IA que executam modelos de aprendizagem automática (ML) com características como serem de grande escala, de execução prolongada ou dominados por cálculos de matrizes. Para saber mais acerca das funções comuns e das tarefas de exemplo que referimos no Google Cloud conteúdo, consulte o artigo Funções e tarefas comuns do utilizador do GKE.
Antes de ler esta página, certifique-se de que conhece o funcionamento dos aceleradores de ML. Para ver detalhes, consulte o artigo Introdução à Cloud TPU.
Vantagens da utilização de TPUs no GKE
O GKE oferece suporte total para a gestão do ciclo de vida dos nós e dos conjuntos de nós da TPU, incluindo a criação, a configuração e a eliminação de VMs da TPU. O GKE também suporta VMs do Spot e a utilização de Cloud TPUs reservadas. Para mais informações, consulte as opções de consumo de Cloud TPU.
Seguem-se algumas vantagens da utilização de TPUs no GKE:
- Ambiente operacional consistente: pode usar uma única plataforma para todas as cargas de trabalho de aprendizagem automática e outras.
- Atualizações automáticas: o GKE automatiza as atualizações de versões, o que reduz os custos operacionais.
- Equilíbrio de carga: o GKE distribui a carga, reduzindo assim a latência e melhorando a fiabilidade.
- Escalabilidade reativa: o GKE dimensiona automaticamente os recursos de TPU para satisfazer as necessidades das suas cargas de trabalho.
- Gestão de recursos: com o Kueue, um sistema de filas de tarefas nativo do Kubernetes, pode gerir recursos em vários inquilinos na sua organização através de filas, prevenção, priorização e partilha equitativa.
- Opções de sandboxing: o GKE Sandbox ajuda a proteger as suas cargas de trabalho com o gVisor. Para mais informações, consulte o artigo GKE Sandbox.
Vantagens da utilização do TPU Trillium
O Trillium é o TPU de sexta geração da Google. O Trillium tem as seguintes vantagens:
- O Trillium aumenta o desempenho de computação por chip em comparação com a TPU v5e.
- O Trillium aumenta a capacidade e a largura de banda da memória de largura de banda elevada (HBM), bem como a largura de banda da interligação entre chips (ICI) em relação à TPU v5e.
- O Trillium está equipado com o SparseCore de terceira geração, um acelerador especializado para processar incorporações ultragrandes comuns em cargas de trabalho de recomendações e classificação avançadas.
- O Trillium é mais de 67% mais eficiente em termos de energia do que a TPU v5e.
- O Trillium pode ser dimensionado até 256 TPUs numa única fatia de TPU de largura de banda elevada e baixa latência.
- O Trillium suporta a programação da recolha. O agendamento de recolhas permite-lhe declarar um grupo de TPUs (pools de nós de fatias de TPUs de anfitrião único e vários anfitriões) para garantir a elevada disponibilidade para as exigências das suas cargas de trabalho de inferência.
Em todas as superfícies técnicas, como APIs e registos, e em partes específicas da documentação do GKE, usamos v6e ou TPU Trillium (v6e) para nos referirmos às TPUs Trillium. Para saber mais sobre as vantagens do Trillium, leia a publicação no blogue de anúncio do Trillium. Para iniciar a configuração do TPU, consulte o artigo Planeie TPUs no GKE.
Terminologia relacionada com TPUs no GKE
Esta página usa a seguinte terminologia relacionada com as TPUs:
- Tipo de TPU: o tipo de Cloud TPU, como v5e.
- Nó de fatia da TPU: um nó do Kubernetes representado por uma única VM que tem um ou mais chips da TPU interligados.
- Node pool de fatias de TPUs: um grupo de nós do Kubernetes num cluster que têm todos a mesma configuração de TPUs.
- Topologia da TPU: o número e a disposição física dos chips da TPU numa fatia de TPU.
- Atómico: o GKE trata todos os nós interligados como uma única unidade. Durante as operações de escalabilidade, o GKE dimensiona todo o conjunto de nós para 0 e cria novos nós. Se uma máquina no grupo falhar ou terminar, o GKE recria todo o conjunto de nós como uma nova unidade.
- Imutável: não pode adicionar manualmente novos nós ao conjunto de nós interligados. No entanto, pode criar um novo conjunto de nós com a topologia de TPU pretendida e agendar cargas de trabalho no novo conjunto de nós.
Tipos de pools de nós de fatias de TPU
O GKE suporta dois tipos de pools de nós da TPU:
O tipo e a topologia da TPU determinam se o nó da fatia de TPU pode ser de vários anfitriões ou de um único anfitrião. Recomendamos:
- Para modelos de grande escala, use nós de fatia de TPU com vários anfitriões.
- Para modelos de pequena escala, use nós de fatia de TPU de host único.
- Para a preparação ou a inferência em grande escala, use o Pathways. O Pathways simplifica os cálculos de aprendizagem automática em grande escala, permitindo que um único cliente JAX organize cargas de trabalho em várias grandes fatias de TPUs. Para mais informações, consulte o artigo Pathways.
Pools de nós de fatia de TPU multi-host
Um node pool de fatia de TPU multi-host é um node pool que contém duas ou mais VMs de TPU interligadas. Cada VM tem um dispositivo TPU ligado. As TPUs numa fatia de TPU com vários anfitriões estão ligadas através de uma interligação de alta velocidade (ICI). Depois de criar um conjunto de nós de fatia de TPU com vários anfitriões, não pode adicionar-lhe nós. Por exemplo, não pode criar um conjunto de nós v4-32
e, posteriormente, adicionar um nó do Kubernetes (VM da TPU) ao conjunto de nós. Para adicionar uma fatia de TPU a um cluster do GKE, tem de criar um novo conjunto de nós.
As VMs num conjunto de nós de uma fatia de TPU com vários anfitriões são tratadas como uma única unidade atómica. Se o GKE não conseguir implementar um nó na fatia, não são implementados nós no nó da fatia de TPU.
Se um nó numa fatia de TPU com vários anfitriões precisar de reparação, o GKE encerra todas as VMs na fatia de TPU, forçando a remoção de todos os pods do Kubernetes na carga de trabalho. Depois de todas as VMs na fatia de TPU estarem em funcionamento, os pods do Kubernetes podem ser agendados nas VMs na nova fatia de TPU.
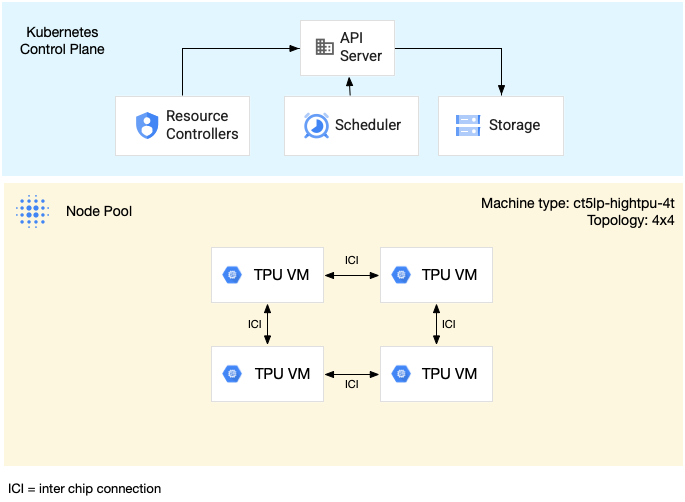
O diagrama seguinte mostra uma fatia de TPU de vários anfitriões v5litepod-16 (v5e). Esta fatia de TPU tem quatro VMs. Cada VM na fatia de TPU tem quatro chips de TPU v5e
ligados com interconexões de alta velocidade (ICI), e cada chip de TPU v5e tem um
TensorCore:
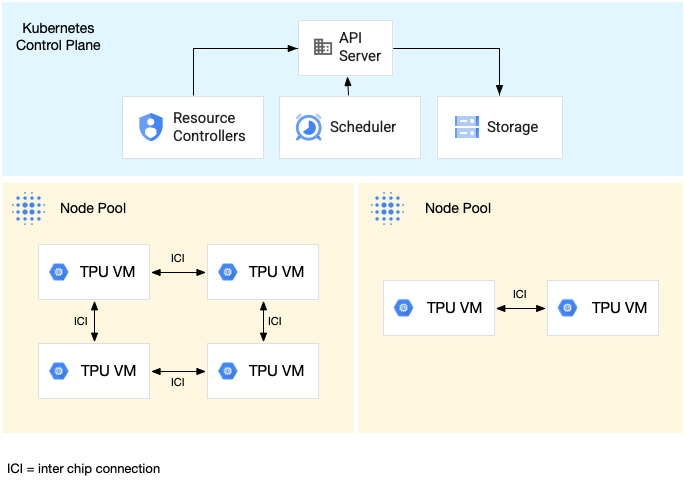
O diagrama seguinte mostra um cluster do GKE que contém uma fatia de TPU v5litepod-16 (v5e) (topologia: 4x4) e uma fatia de TPU v5litepod-8 (v5e) (topologia: 2x4):
Node pools de fatia de TPU de anfitrião único
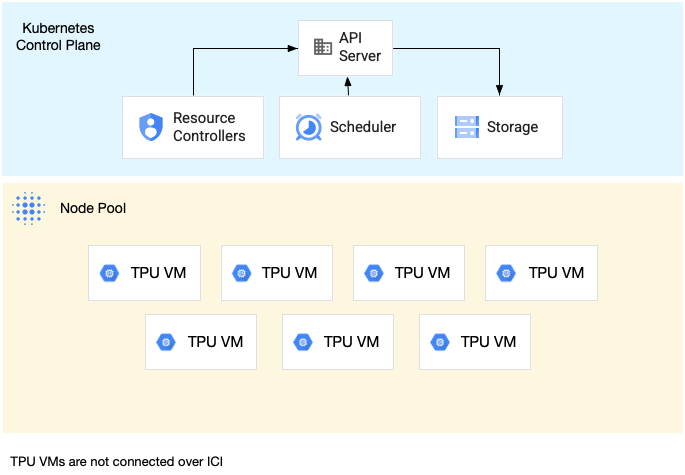
Um conjunto de nós de divisão de anfitrião único é um conjunto de nós que contém uma ou mais VMs de TPU independentes. Cada VM tem um dispositivo TPU ligado. Embora as VMs num conjunto de nós de fatia de anfitrião único possam comunicar através da rede do centro de dados (DCN), as UTPs anexadas às VMs não estão interligadas.
O diagrama seguinte mostra um exemplo de uma fatia de TPU de host único que contém sete v4-8 máquinas:
Caraterísticas das TPUs no GKE
As TPUs têm características únicas que requerem um planeamento e uma configuração especiais.
Consumo de TPUs
Para otimizar a utilização e o custo dos recursos, ao mesmo tempo que equilibra o desempenho da carga de trabalho, o GKE suporta as seguintes opções de consumo de TPUs:
- Início flexível: para proteger recursos durante um máximo de sete dias, com o GKE a atribuir automaticamente o hardware com base no melhor esforço e na disponibilidade. Para mais informações, consulte o artigo Acerca do aprovisionamento de GPUs e TPUs com o modo de aprovisionamento de início flexível.
- VMs do Spot: para aprovisionar VMs do Spot, pode receber descontos significativos, mas as VMs do Spot podem ser anuladas em qualquer altura, com um aviso de 30 segundos. Para mais informações, consulte o artigo VMs de spot.
- Reserva futura até 90 dias (no modo de calendário): para aprovisionar recursos de TPU durante um período máximo de 90 dias, para um período especificado. Para mais informações, consulte o artigo Peça TPUs com reserva futura no modo de calendário.
- Reservas de TPUs: para pedir uma reserva futura durante um ano ou mais.
Para escolher a opção de consumo que cumpre os requisitos da sua carga de trabalho, consulte o artigo Acerca das opções de consumo de aceleradores para cargas de trabalho de IA/ML no GKE.
Antes de usar as TPUs no GKE, escolha a opção de consumo que melhor se adapta aos requisitos da sua carga de trabalho.
Topologia
A topologia define a disposição física das TPUs numa fatia de TPU. O GKE aprovisiona uma fatia de TPU em topologias bidimensionais ou tridimensionais, consoante a versão da TPU. Especifica uma topologia como o número de chips de TPU em cada dimensão da seguinte forma:
Para a TPU v4 e v5p agendada em node pools de fatias de TPU com vários anfitriões, define a
topologia em tuplos de 3 elementos ({A}x{B}x{C}), por exemplo, 4x4x4. O produto de
{A}x{B}x{C} define o número de chips de TPU no conjunto de nós. Por exemplo, pode definir pequenas topologias com menos de 64 chips de TPU com formas de topologia, como 2x2x2, 2x2x4 ou 2x4x4. Se usar topologias maiores com mais de 64 chips de TPU, os valores que atribui a {A}, {B} e {C} têm de cumprir as seguintes condições:
- {A}, {B} e {C} têm de ser múltiplos de quatro.
- A topologia mais extensa suportada para a v4 é
12x16x16e para a v5p é16x16x24. - Os valores atribuídos têm de manter o padrão A ≤ B ≤ C. Por exemplo,
4x4x8ou8x8x8.
Tipo de máquina
Os tipos de máquinas que suportam recursos de TPU seguem uma convenção de nomenclatura que inclui a versão da TPU e o número de chips de TPU por fatia de nó, como ct<version>-hightpu-<node-chip-count>t. Por exemplo, o tipo de máquina
ct5lp-hightpu-1t suporta a TPU v5e e contém apenas um chip de TPU.
Modo privilegiado
Se usar versões do GKE anteriores à 1.28, tem de configurar os contentores com capacidades especiais para aceder às TPUs. Nos clusters do modo padrão, pode usar o modo privilegiado para conceder este acesso. O modo privilegiado
substitui muitas das outras definições de segurança no securityContext. Para obter
detalhes, consulte o artigo Execute contentores sem o modo privilegiado.
As versões 1.28 e posteriores não requerem o modo privilegiado nem capacidades especiais.
Como funcionam as TPUs no GKE
A gestão e a priorização de recursos do Kubernetes tratam as VMs em TPUs da mesma forma que
outros tipos de VMs. Para pedir chips de TPU, use o nome do recurso google.com/tpu:
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
Quando usar as TPUs no GKE, considere as seguintes características das TPUs:
- Uma VM pode aceder a até 8 chips de TPU.
- Uma fatia de TPU contém um número fixo de chips de TPU, sendo que o número depende do tipo de máquina de TPU que escolher.
- O número de
google.com/tpupedidos tem de ser igual ao número total de chips de TPU disponíveis no nó da fatia de TPU. Qualquer contentor num pod do GKE que peça TPUs tem de consumir todos os chips de TPU no nó. Caso contrário, a implementação falha porque o GKE não consegue consumir parcialmente os recursos de TPU. Considere os seguintes cenários:- O tipo de máquina
ct5lp-hightpu-4tcom uma topologia2x4contém dois nós de fatia de TPU com quatro chips de TPU cada, num total de oito chips de TPU. Com este tipo de máquina, pode: - Não é possível implementar um pod do GKE que requer oito chips de TPU nos nós neste conjunto de nós.
- Pode implementar dois pods que requerem quatro chips de TPU cada, cada pod num dos dois nós neste conjunto de nós.
- A TPU v5e com topologia 4x4 tem 16 chips de TPU em quatro nós. A carga de trabalho do GKE Autopilot que seleciona esta configuração tem de pedir quatro chips de TPU em cada réplica, para uma a quatro réplicas.
- O tipo de máquina
- Nos clusters padrão, é possível agendar vários pods do Kubernetes numa VM, mas apenas um contentor em cada pod pode aceder aos chips da TPU.
- Para criar pods kube-system, como kube-dns, cada cluster Standard tem de ter, pelo menos, um grupo de nós de fatia não TPU.
- Por predefinição, os nós de fatia da TPU têm a
google.com/tpucontaminação que impede o agendamento de cargas de trabalho que não sejam da TPU nos nós de fatia da TPU. As cargas de trabalho que não usam TPUs são executadas em nós sem TPUs, libertando capacidade de computação nos nós de fatias de TPU para código que usa TPUs. Tenha em atenção que a contaminação não garante que os recursos da TPU sejam totalmente utilizados. - O GKE recolhe os registos emitidos por contentores executados em nós de fatia da TPU. Para saber mais, consulte o artigo Registo.
- As métricas de utilização da TPU, como o desempenho de tempo de execução, estão disponíveis no Cloud Monitoring. Para saber mais, consulte o artigo Observabilidade e métricas.
- Pode colocar as suas cargas de trabalho de TPU em sandbox com o GKE Sandbox. O GKE Sandbox funciona com modelos de TPU v4 e posteriores. Para saber mais, consulte o artigo GKE Sandbox.
Como funciona o agendamento de recolhas
Na TPU Trillium, pode usar a programação da recolha para agrupar nós de fatias de TPU. O agrupamento destes nós de fatias de TPU facilita o ajuste do número de réplicas para satisfazer a procura da carga de trabalho.O Google Cloud controla as atualizações de software para garantir que existem sempre fatias suficientes na coleção para publicar tráfego.
O TPU Trillium suporta o agendamento da recolha para pools de nós de anfitrião único e vários anfitriões que executam cargas de trabalho de inferência. A seguir, descreve-se como o comportamento do agendamento da recolha depende do tipo de fatia de TPU que usa:
- Segmento de TPU com vários anfitriões: o GKE agrupa segmentos de TPU com vários anfitriões para formar uma coleção. Cada GKE node pool é uma réplica nesta coleção. Para definir uma coleção, crie uma fatia de TPU com vários anfitriões e atribua um nome exclusivo à coleção. Para adicionar mais fatias de TPU à coleção, crie outro conjunto de nós de fatias de TPU multi-anfitrião com o mesmo nome da coleção e tipo de carga de trabalho.
- Segmento de TPU de anfitrião único: o GKE considera o conjunto de nós do segmento de TPU de anfitrião único como uma coleção. Para adicionar mais fatias de TPU à coleção, pode redimensionar o conjunto de nós de fatias de TPU de anfitrião único.
A agendamento da recolha tem as seguintes limitações:
- Só pode agendar recolhas para a TPU Trillium.
- Só pode definir coleções durante a criação do conjunto de nós.
- As VMs de spot não são suportadas.
- As coleções que contêm pools de nós de fatias de TPUs com vários anfitriões têm de usar o mesmo tipo de máquina, topologia e versão para todos os pools de nós na coleção.
Pode configurar o agendamento da recolha nos seguintes cenários:
- Quando cria um node pool de fatia de TPU no GKE Standard
- Ao implementar cargas de trabalho no GKE Autopilot
- Quando cria um cluster que ativa o aprovisionamento automático de nós
O que se segue?
Para saber como configurar o Cloud TPU no GKE, consulte as seguintes páginas:
- Planeie TPUs no GKE para iniciar a configuração das TPUs
- Implemente cargas de trabalho de TPU no GKE Autopilot
- Implemente cargas de trabalho de TPU no GKE Standard
- Saiba mais acerca das práticas recomendadas para usar o Cloud TPU para as suas tarefas de ML
- Vídeo: crie aprendizagem automática em grande escala no Cloud TPU com o GKE
- Implemente modelos de linguagem (conteúdo extenso) com o KubeRay em TPUs
- Saiba mais sobre o sandboxing de cargas de trabalho de GPU com o GKE Sandbox