Mit der Vektorsuche in Vertex AI können Nutzer mithilfe von Vektoreinbettungen nach semantisch ähnlichen Elementen suchen. Mit dem Workflow für Spanner to Vertex AI Vector Search können Sie Ihre Spanner-Datenbank in die Vektorsuche einbinden, um eine Vektorähnlichkeitssuche für Ihre Spanner-Daten durchzuführen.
Das folgende Diagramm zeigt den End-to-End-Anwendungs-Workflow, mit dem Sie die Vektorsuche für Ihre Spanner-Daten aktivieren und verwenden können:
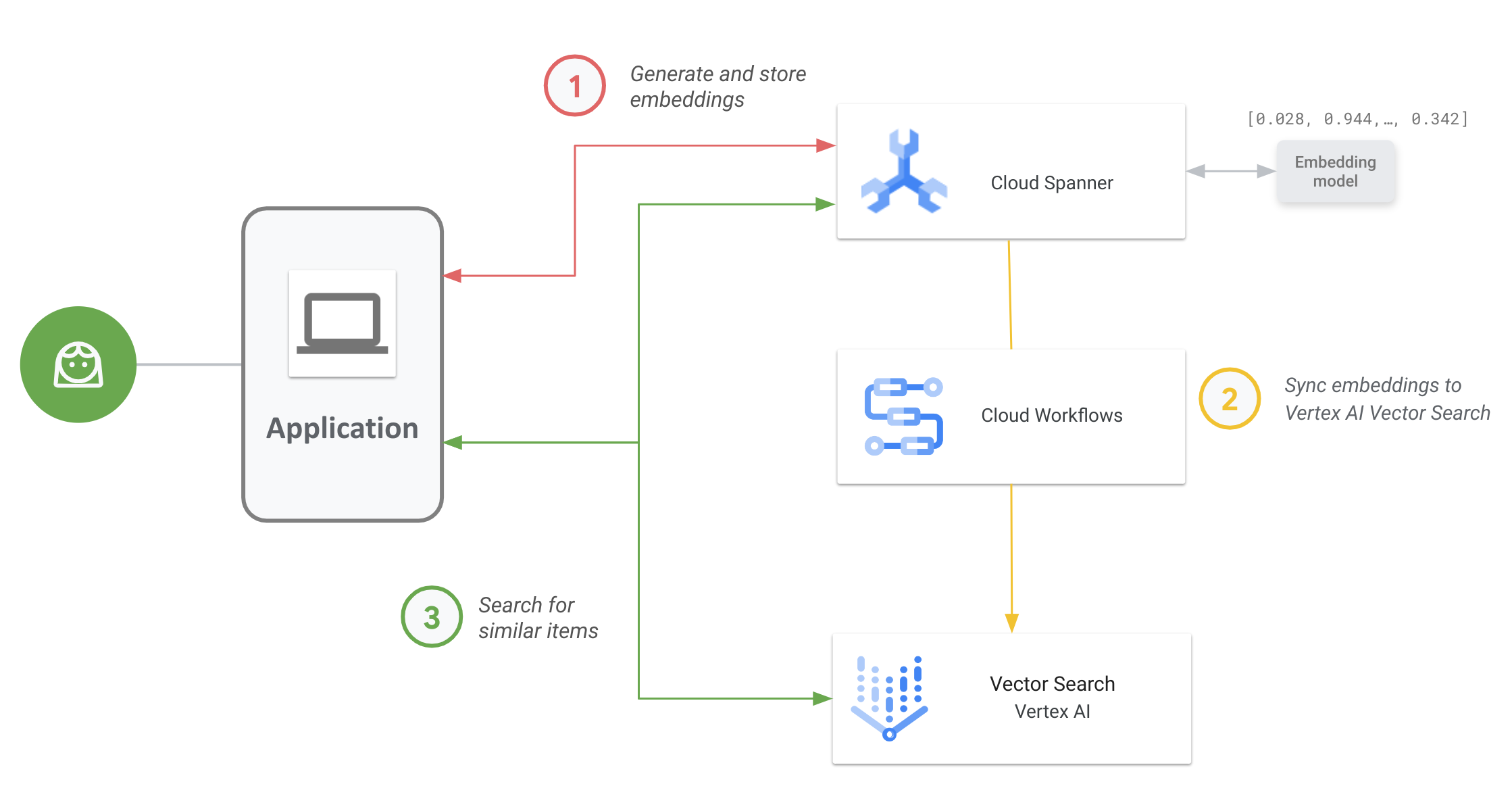
Dies ist der allgemeine Workflow:
Vektoreinbettungen generieren und speichern:
Sie können Vektoreinbettungen Ihrer Daten generieren und sie dann zusammen mit Ihren Betriebsdaten in Spanner speichern und verwalten. Sie können Einbettungen mit der Spanner-SQL-Funktion
ML.PREDICTgenerieren, um auf das Vertex AI-Modell für Texteinbettung zuzugreifen oder andere in Vertex AI bereitgestellte Einbettungsmodelle zu verwenden.Einbettungen mit der Vektorsuche synchronisieren
Verwenden Sie den Workflow für Spanner to Vertex AI Vector Search, der mit Workflows bereitgestellt wird, um Einbettungen zu exportieren und in einen Vektorsucheindex hochzuladen. Sie können diesen Workflow mit Cloud Scheduler regelmäßig planen, um Ihren Vector Search-Index mit den neuesten Änderungen an Ihren Einbettungen in Spanner auf dem neuesten Stand zu halten.
Mit Ihrem Vektorsuchindex eine Suche nach Vektorähnlichkeiten durchführen.
Sie können den Vektorsuche-Index abfragen, um nach semantisch ähnlichen Elementen zu suchen und Ergebnisse zu finden. Sie können Abfragen über einen öffentlichen Endpunkt oder über VPC-Peering ausführen.
Anwendungsbeispiel
Ein anschaulicher Anwendungsfall für die Vektorsuche ist ein Onlinehändler mit einem Inventar von Hunderttausenden von Artikeln. In diesem Szenario sind Sie Entwickler für einen Onlinehändler und möchten die Vektorähnlichkeitssuche für Ihren Produktkatalog in Spanner verwenden, damit Ihre Kunden anhand ihrer Suchanfragen relevante Produkte finden.
Folgen Sie Schritt 1 und Schritt 2 des allgemeinen Workflows, um Vektoreinbettungen für Ihren Produktkatalog zu generieren und diese Einbettungen mit der Vektorsuche zu synchronisieren.
Stellen Sie sich nun vor, ein Kunde, der Ihre Anwendung durchsucht, führt eine Suche wie „beste, schnell trocknende Sporthorts, die ich im Wasser tragen kann“ durch. Wenn Ihre Anwendung diese Anfrage empfängt, müssen Sie mit der Spanner-SQL-Funktion ML.PREDICT ein Anfrage-Embedding für diese Suchanfrage generieren. Verwenden Sie dasselbe Einbettungsmodell, mit dem die Einbettungen für Ihren Produktkatalog generiert wurden.
Als Nächstes fragen Sie den Vektorsuchindex nach Produkt-IDs ab, deren entsprechende Einbettungen der Anfrageeinbettung ähneln, die aus der Suchanfrage Ihres Kunden generiert wurde. Im Suchindex werden möglicherweise Produkt-IDs für semantisch ähnliche Artikel wie Wakeboard-Shorts, Surfbekleidung und Badehosen empfohlen.
Nachdem die Vektorsuche diese ähnlichen Produkt-IDs zurückgegeben hat, können Sie Spanner nach den Beschreibungen, der Anzahl der Artikel auf Lager, dem Preis und anderen relevanten Metadaten der Produkte abfragen und sie Ihrem Kunden anzeigen.
Sie können auch generative KI verwenden, um die von Spanner zurückgegebenen Ergebnisse zu verarbeiten, bevor Sie sie Ihrem Kunden präsentieren. Sie können beispielsweise die großen generativen KI-Modelle von Google verwenden, um eine kurze Zusammenfassung der empfohlenen Produkte zu erstellen. Weitere Informationen finden Sie in diesem Tutorial zur Verwendung generativer KI für personalisierte Empfehlungen in einer E-Commerce-Anwendung.
Nächste Schritte
- Informationen zum Generieren von Einbettungen mit Spanner
- Weitere Informationen zum KI-Multitool: Vektoreinbettungen
- Weitere Informationen zu maschinellem Lernen und Einbettungen finden Sie in unserem Crashkurs zu Einbettungen.
- Weitere Informationen zum Workflow „Spanner to Vertex AI Vector Search“ finden Sie im GitHub-Repository.
- Weitere Informationen zum Open-Source-Paket „spanner-analytics“, das gängige Datenanalysevorgänge in Python ermöglicht und Integrationen mit Jupyter-Notebooks umfasst.