如需了解详情,请参阅汇总感知文档页面。
简介
本页介绍了如何在实际场景中实现汇总感知,包括确定实现机会、汇总感知带来的价值,以及在实际模型中实现汇总感知的简单工作流。本页面并未深入说明所有汇总的感知功能或极端情况,也未详尽列出所有功能。
什么是汇总感知?
在 Looker 中,您主要针对数据库中的原始表或视图运行查询。有时,这些表是 Looker 永久性派生表 (PDT)。
您可能经常会遇到非常大的数据集或表,为了获得良好的性能,需要使用汇总表或汇总数据。
通常,您可能会创建维度有限的汇总表,例如 orders_daily 表。这些变量需要在探索中单独处理和建模,并且无法整齐地纳入模型中。当用户必须在同一数据的多个探索之间进行选择时,这些限制会导致糟糕的用户体验。
现在,借助 Looker 的汇总感知功能,您可以预先构建各种粒度、维度和汇总级别的汇总表;并且可以告知 Looker 如何在现有探索中利用这些汇总表。然后,Looker 会在认为合适的情况下利用这些汇总表,而无需任何用户输入。这样可以减小查询规模、缩短等待时间并提升用户体验。
注意:Looker 的汇总表是一种 永久性派生表 (PDT)。这意味着,汇总表与 PDT 具有相同的数据库和连接要求。如需了解您的数据库方言和 Looker 连接是否支持 PDT,请参阅 Looker 中的派生表文档页面上列出的要求。
如需了解您的数据库方言是否支持汇总感知,请参阅汇总感知文档页面。
总体认知度的价值
汇总意识提供了一些重要的价值主张,可帮助您从现有的 Looker 模型中挖掘更多价值:
- 性能提升:实现汇总感知功能后,用户查询速度会更快。如果较小的表包含完成用户查询所需的数据,Looker 将使用该表。
- 节省费用:某些方言会根据查询的大小按使用量模式收费。通过让 Looker 查询较小的表,您可以降低每次用户查询的费用。
- 增强用户体验:除了能更快地检索答案之外,整合还消除了冗余的探索创建。
- 减少 LookML 占用空间:用灵活的原生实现替换基于 Liquid 的现有汇总感知策略,可提高恢复能力并减少错误。
- 能够利用现有的 LookML:汇总表使用
query对象,该对象会重复使用现有的模型逻辑,而不是通过显式自定义 SQL 来复制逻辑。
基本示例
以下是 Looker 模型中的一个非常简单的实现,用于演示轻量级汇总感知功能。假设数据库中有一个 flights 表,其中包含 FAA 记录的每次航班对应的一行数据,我们可以在 Looker 中使用自己的视图和探索来对该表进行建模。以下是我们可以为探索定义的汇总表的 LookML:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
有了此汇总表,用户可以查询 flights 探索,而 Looker 会自动利用 LookML 中定义的汇总表,并使用该汇总表来回答查询。用户无需向 Looker 说明任何特殊条件:如果表适合用户选择的字段,Looker 将使用该表。
具有 see_sql 权限的用户可以使用探索的 SQL 标签页中的注释来查看查询将使用哪个汇总表。以下是使用汇总表 flights:flights_by_week_and_carrier in teach_scratch 的查询的 Looker SQL 标签页示例:
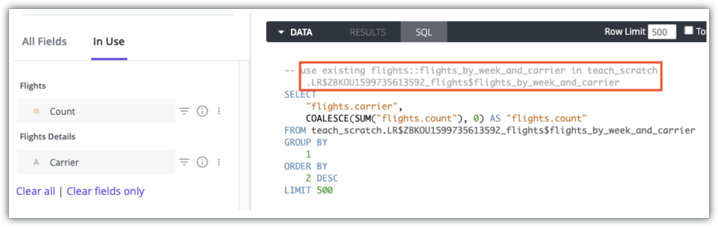
如需详细了解如何确定是否为查询使用了汇总表,请参阅汇总感知文档页面。
发掘机会
为了最大限度地发挥汇总感知的好处,您应确定汇总感知可以在哪些方面发挥作用,以实现优化或提升汇总感知的价值。
确定运行时较长的信息中心
一个很好的机会是,为运行时非常高的常用信息中心创建汇总表,以提高汇总意识。您可能会收到用户关于信息中心运行缓慢的反馈,但如果您拥有 see_system_activity,还可以使用 Looker 的系统活动历史记录探索功能来查找运行时长低于平均水平的信息中心。作为快捷方式,您可以在浏览器中使用以下网址,并将 HOSTNAME 替换为 Looker 实例的名称(例如 example.cloud.looker.com)。
https://HOSTNAME/explore/system__activity/history?fields=dashboard.title,dashboard.link,history.count,history.average_runtime,history.cache_result_query_count,history.database_result_query_count,query.count_of_explores&f[history.created_date]=30+days&f[dashboard.title]=-NULL%2C-Limejump+Dashboard&sorts=history.count+desc&limit=500&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22gray%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_column_widths%22%3A%7B%22dashboard.link%22%3A80%2C%22history.average_runtime%22%3A94%2C%22history.count%22%3A96%7D%2C%22series_cell_visualizations%22%3A%7B%22history.count%22%3A%7B%22is_active%22%3Afalse%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%232196F3%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22constraints%22%3A%7B%22min%22%3A%7B%22type%22%3A%22minimum%22%7D%2C%22mid%22%3A%7B%22type%22%3A%22number%22%2C%22value%22%3A0%7D%2C%22max%22%3A%7B%22type%22%3A%22maximum%22%7D%7D%2C%22mirror%22%3Atrue%2C%22reverse%22%3Atrue%2C%22stepped%22%3Afalse%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%2C%22hidden_fields%22%3A%5B%22history.cache_result_query_count%22%2C%22history.database_result_query_count%22%2C%22dashboard.link%22%5D%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22dashboard.title%22%3A%5B%7B%22type%22%3A%22%21null%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22%22%7D%2C%7B%7D%5D%2C%22id%22%3A2%2C%22error%22%3Afalse%7D%2C%7B%22type%22%3A%22%21%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Limejump+Dashboard%22%7D%2C%7B%7D%5D%2C%22id%22%3A3%2C%22error%22%3Afalse%7D%5D%7D&dynamic_fields=%5B%7B%22table_calculation%22%3A%22ratio_from_cache_vs_database%22%2C%22label%22%3A%22Ratio+from+Cache+vs+Database%22%2C%22expression%22%3A%22%24%7Bhistory.cache_result_query_count%7D%2F%24%7Bhistory.database_result_query_count%7D%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3A%22decimal_2%22%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22number%22%7D%2C%7B%22table_calculation%22%3A%22is_performing_worse_than_mean%22%2C%22label%22%3A%22Is+Performing+Worse+Than+Mean%22%2C%22expression%22%3A%22%24%7Bhistory.average_runtime%7D%3Emean%28%24%7Bhistory.average_runtime%7D%29%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3Anull%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22yesno%22%7D%5D&origin=share-expanded" rel="undefined">this System Activity History Explore link
您将看到一个“探索”可视化图表,其中包含有关实例的各个信息中心的数据,包括标题、历史记录、探索次数、缓存与数据库的比率和是否低于平均水平:
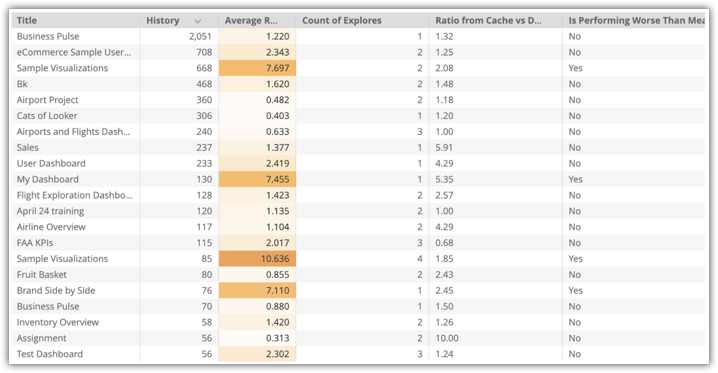
在此示例中,有多个利用率较高但效果低于平均水平的信息中心,例如可视化示例信息中心。可视化图表示例信息中心使用了两个探索,因此一个不错的策略是为这两个探索都创建汇总表。
确定速度缓慢且用户查询次数较多的探索
另一种提高总体认知度的机会是,对于用户查询量大但查询响应低于平均水平的探索,
您可以先使用系统活动历史记录探索,找出可优化探索的机会。作为快捷方式,您可以在浏览器中使用以下网址,并将 HOSTNAME 替换为 Looker 实例的名称(例如 example.cloud.looker.com)。
https://HOSTNAME/explore/system__activity/history?fields=query.view,history.query_run_count,user.count,query.model,history.average_runtime&f[history.created_date]=30+days&f[history.source]=Explore&sorts=history.query_run_count+desc&limit=15&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22white%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_labels%22%3A%7B%22user.count%22%3A%22User+Count%22%7D%2C%22series_column_widths%22%3A%7B%22query.model%22%3A179%2C%22query.view%22%3A128%7D%2C%22series_cell_visualizations%22%3A%7B%22history.query_run_count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A106%7D%2C%22user.count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A108%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%233EB0D5%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22reverse%22%3Atrue%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22truncate_column_names%22%3Afalse%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22history.source%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Explore%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
您将看到一个“探索”可视化图表,其中包含有关实例的探索的数据,包括探索、模型、查询运行次数、用户数和平均运行时长(以秒为单位):

在历史记录探索中,您可以确定实例上的以下类型的探索:
- 由用户查询的探索(与来自 API 的查询或来自预定交付的查询相对)
- 经常查询的探索
- 效果不佳的探索(与其他探索相比)
在之前的“系统活动历史记录”探索示例中,flights 和 order_items 探索很可能适合实现汇总感知。
确定查询中经常使用的字段
最后,您可以通过了解用户在查询和过滤条件中经常包含的字段,在数据层面发现其他机会。
作为快捷方式,您可以在浏览器中使用以下网址,并将 HOSTNAME 替换为 Looker 实例的名称(例如 example.cloud.looker.com)。
https://HOSTNAME/explore/system__activity/field_usage?fields=field_usage.model,field_usage.explore,field_usage.field,field_usage.times_used&f[field_usage.model]=faa%2C%22advanced_data_analyst_bootcamp%22&f[field_usage.explore]=flights%2C%22order_items%22&sorts=field_usage.times_used+desc&limit=500&query_timezone=America%2FNew_York&vis=%7B%22x_axis_gridlines%22%3Afalse%2C%22y_axis_gridlines%22%3Atrue%2C%22show_view_names%22%3Afalse%2C%22show_y_axis_labels%22%3Atrue%2C%22show_y_axis_ticks%22%3Atrue%2C%22y_axis_tick_density%22%3A%22default%22%2C%22y_axis_tick_density_custom%22%3A5%2C%22show_x_axis_label%22%3Atrue%2C%22show_x_axis_ticks%22%3Atrue%2C%22y_axis_scale_mode%22%3A%22linear%22%2C%22x_axis_reversed%22%3Afalse%2C%22y_axis_reversed%22%3Afalse%2C%22plot_size_by_field%22%3Afalse%2C%22trellis%22%3A%22%22%2C%22stacking%22%3A%22%22%2C%22limit_displayed_rows%22%3Atrue%2C%22legend_position%22%3A%22center%22%2C%22point_style%22%3A%22none%22%2C%22show_value_labels%22%3Afalse%2C%22label_density%22%3A25%2C%22x_axis_scale%22%3A%22auto%22%2C%22y_axis_combined%22%3Atrue%2C%22ordering%22%3A%22none%22%2C%22show_null_labels%22%3Afalse%2C%22show_totals_labels%22%3Afalse%2C%22show_silhouette%22%3Afalse%2C%22totals_color%22%3A%22%23808080%22%2C%22limit_displayed_rows_values%22%3A%7B%22show_hide%22%3A%22show%22%2C%22first_last%22%3A%22first%22%2C%22num_rows%22%3A%2215%22%7D%2C%22series_types%22%3A%7B%7D%2C%22type%22%3A%22looker_bar%22%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22field_usage.model%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22faa%2Cadvanced_data_analyst_bootcamp%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22field_usage.explore%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22flights%2Corder_items%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
相应地替换过滤条件。您会看到一个“探索”,其中包含一个条形图可视化,用于指示某个字段在查询中被使用的次数:
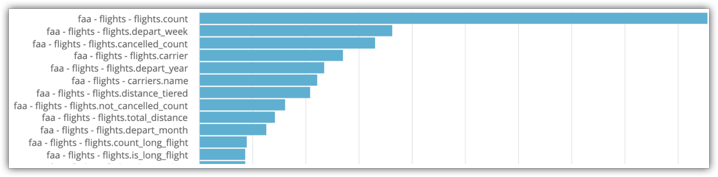
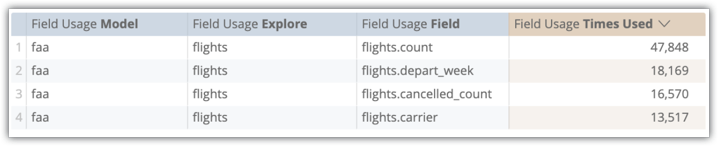
在图片中显示的“系统活动”探索示例中,您可以看到 flights.count 和 flights.depart_week 是该探索最常选择的两个字段。因此,这些字段非常适合纳入汇总表。
这类具体数据很有帮助,但也有一些主观因素会影响您的选择标准。例如,通过查看前四个字段,您可以放心地假设用户通常会查看预定航班数和已取消航班数,并且希望按周和按航空公司细分这些数据。这是一个清晰、合理且贴近实际的字段和指标组合示例。
摘要
此文档页面上的步骤应作为指南,帮助您找到需要考虑进行优化的信息中心、探索和字段。另请注意,这三者可能互斥:存在问题的信息中心可能并非由存在问题的探索提供支持,而使用常用字段构建汇总表可能对这些信息中心毫无帮助。这可能是三种不同的汇总认知度实现。
设计汇总表
在确定可提高总体认知度的机会后,您可以设计最能抓住这些机会的汇总表。如需了解汇总表中支持的字段、度量和时间范围,以及设计汇总表的其他准则,请参阅汇总感知文档页面。
注意:汇总表不一定需要与查询完全匹配才能使用。如果您的查询采用的是周粒度,并且您有一个每日汇总表,Looker 将使用您的汇总表,而不是原始的时间戳级层表。同样,如果您有一个汇总到brand和date级别的汇总表,而用户仅在brand级别进行查询,则 Looker 仍可将该表用于汇总感知。
以下指标支持汇总感知:
- 标准度量: SUM、COUNT、AVERAGE、MIN 和 MAX 类型的度量
- 复合指标: NUMBER、STRING、YESNO 和 DATE 类型的指标
- 近似不同度量: 可以使用 HyperLogLog 功能的方言
以下指标不支持汇总感知:
- 非近似的衡量指标:由于只能对原子级非汇总数据计算唯一性,因此除了使用 HyperLogLog 的这些近似值之外,不支持
*_DISTINCT衡量指标。 - 基于基数的度量:与不同度量一样,中位数和百分位数无法预先汇总,因此不受支持。
注意:如果您知道某个潜在的用户查询包含汇总感知功能不支持的衡量类型,那么在这种情况下,您可能需要创建与查询完全匹配的汇总表。如果汇总表与查询完全匹配,则可用于回答包含以下衡量类型(否则汇总感知功能不支持)的查询:
汇总表粒度
在为维度和度量的组合构建表之前,您应确定常见的使用模式和字段选择,以创建尽可能频繁使用且影响最大的汇总表。请注意,查询中使用的所有字段(无论是选择的字段还是过滤的字段)都必须位于汇总表中,才能将该表用于查询。不过,如前所述,汇总表不必与查询完全匹配,才能用于查询。您可以在单个汇总表中处理许多潜在的用户查询,同时仍能获得显著的性能提升。
从确定查询中经常使用的字段的示例中可以看出,有两个维度(flights.depart_week 和 flights.carrier)被非常频繁地选择,还有两个指标(flights.count 和 flights.cancelled_count)。因此,构建一个使用所有这四个字段的汇总表是合乎逻辑的。此外,为 flights_by_week_and_carrier 创建单个汇总表将比为 flights_by_week 和 flights_by_carrier 表创建两个不同的汇总表更频繁地使用汇总表。
以下是我们可能会为针对常见字段的查询创建的汇总表示例:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
您的业务用户和轶事证据以及 Looker 的系统活动中的数据都可以帮助您指导决策流程。
兼顾适用性和性能
以下示例展示了对 flights_by_week_and_carrier 汇总表中的“Flights Depart Week”(航班出发周)、“Flights Details Carrier”(航班详细信息 - 航空公司)、“Flights Count”(航班数量)和“Flights Detailed Cancelled Count”(航班详细信息 - 取消的航班数量)字段进行的探索查询:
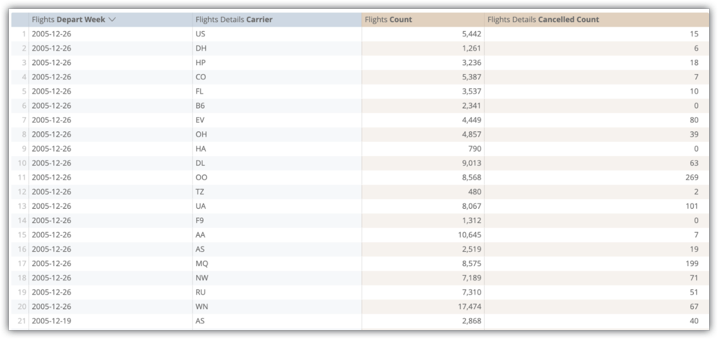
在原始数据库表中运行此查询花费了 15.8 秒,扫描了 3,800 万行,未使用任何联接(使用 Amazon Redshift)。透视查询(正常的用户操作)耗时 29.5 秒。
实现 flights_by_week_and_carrier 汇总表后,后续查询耗时 7.2 秒,扫描了 4, 592 行。这使得表大小缩减了 99.98%。透视查询用时 9.8 秒。
从“系统活动字段使用情况”探索中,我们可以看到用户在查询中包含这些字段的频率。在此示例中,flights.count 被使用了 47,848 次,flights.depart_week 被使用了 18,169 次,flights.cancelled_count 被使用了 16,570 次,flights.carrier 被使用了 13,517 次。
即使我们非常保守地估计,这些查询中有 25% 以最简单的方式(简单选择,无透视)使用了所有 4 个字段,3379 次查询 x 8.6 秒 = 8 小时 4 分钟,用户总等待时间缩短了。
注意:此处使用的示例模型非常基础。这些结果不应用作模型的基准或参考框架。
将完全相同的流程应用于我们的电子商务模型 order_items(实例中最常用的探索)后,结果如下:
| 来源 | 查询时间 | 扫描的行数 |
|---|---|---|
| 基表 | 13.1 秒 | 285,000 |
| 汇总表 | 5.1 秒 | 138,000 |
| Delta | 8 秒 | 147,000 |
查询和后续汇总表中使用的字段为 brand、created_date、orders_count 和 total_revenue,使用了两次联接。这些字段的总使用次数为 11,000 次。假设用户同样节省了约 25% 的时间,那么用户节省的总时间将为 6 小时 6 分钟 (8 秒 * 2750 = 22000 秒)。构建汇总表花费了 17.9 秒。
查看这些结果后,不妨花点时间退后一步,评估以下方面可能带来的回报:
- 优化性能“尚可”但可能因采用更好的建模实践而提升性能的更大型、更复杂的模型/探索
versus
- 使用汇总认知度来优化使用频率更高但效果欠佳的简单模型
当您尝试从 Looker 和数据库中获取最后一点性能时,会发现回报逐渐减少。您应始终了解基准性能预期(尤其是来自业务用户的预期)以及数据库施加的限制(例如并发性、查询阈值、费用等)。您不应期望汇总感知功能能克服这些限制。
此外,在设计汇总表时,请注意,字段越多,汇总表越大,速度越慢。较大的表可以优化更多查询,因此可用于更多情况,但大型表不如较小、更简单的表快。
例如:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week,flights.distance, flights.arrival_week,flights.cancelled]
measures: [cancelled_count, count, flights.average_distance, flights.total_distance]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}这样一来,系统就会针对显示的任何维度组合和包含的任何指标使用汇总表,因此该表可用于回答许多不同的用户查询。但如果使用此表简单地选择 carrier 和 count 查询,则需要扫描一个包含 885,000 行的表。相比之下,如果表基于两个维度,则同一查询只需扫描 4,592 行。88.5 万行的表仍比之前的 3,800 万行减少了 97%;但再添加一个维度后,表的大小会增加到 2,000 万行。因此,在汇总表中包含更多字段以提高其对更多查询的适用性时,回报会逐渐减少。
构建汇总表
以我们确定为优化机会的 Flights Explore 为例,最佳策略是为其构建三个不同的汇总表:
-
flights_by_week_and_carrier -
flights_by_month_and_distance -
flights_by_year
构建这些汇总表的最简单方法是从探索查询或从信息中心获取汇总表 LookML,然后将该 LookML 添加到 Looker 项目文件中。
将汇总表添加到 LookML 项目并将更新部署到生产环境后,探索将利用汇总表来处理用户的查询。
持久性
为了便于进行汇总感知,汇总表必须持久保存在数据库中。最佳做法是利用数据组,使这些汇总表的自动重新生成与您的缓存政策保持一致。对于用于关联探索的汇总表,您应使用相同的数据组。如果您无法使用数据组,另一种替代方案是改用 sql_trigger_value 参数。以下示例展示了 sql_trigger_value 的通用日期值:
sql_trigger_value: SELECT CURRENT_DATE() ;;
这样一来,系统每天午夜都会自动构建您的汇总表。
时间范围逻辑
当 Looker 构建汇总表时,它将包含构建汇总表时的数据。随后附加到数据库中基表的任何数据通常都会从使用相应汇总表的查询结果中排除。
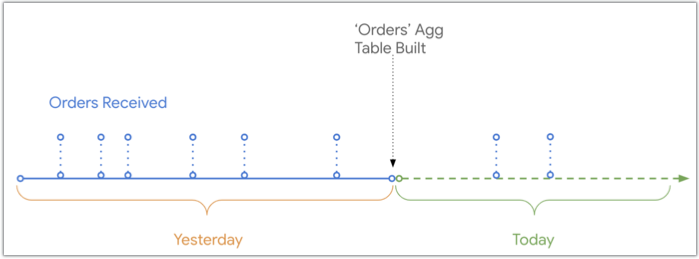
此图显示了订单在数据库中被接收和记录的时间与构建订单汇总表的时间点相比的时间轴。今天收到的两份订单不会显示在订单汇总表中,因为这些订单是在汇总表构建完成后收到的:
不过,当用户查询的时间范围与汇总表重叠时,Looker 可以将新数据与汇总表进行 UNION 操作,如同一时间轴图所示:
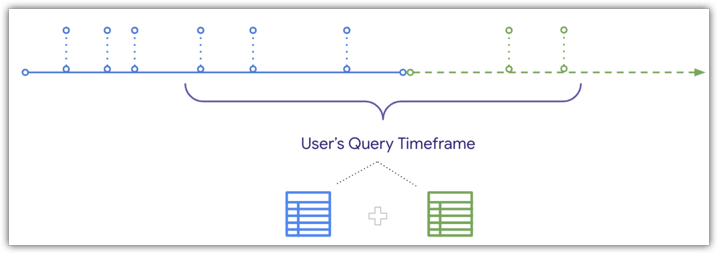
由于 Looker 可以将新数据与汇总表进行并集运算,因此如果用户过滤的时间范围与汇总表和基础表的结束时间重叠,则在构建汇总表后收到的订单将包含在用户的结果中。如需了解详情以及需要满足哪些条件才能将新数据与汇总表查询进行并集运算,请参阅汇总感知文档页面。
摘要
总而言之,如需构建汇总的感知实现,需要执行三个基本步骤:
- 确定适合使用汇总表进行优化且效果显著的机会。
- 设计聚合表,以便尽可能覆盖常见的用户查询,同时仍保持足够小的规模,从而充分减小这些查询的大小。
- 在 Looker 模型中构建汇总表,将表的持久性与探索缓存的持久性配对。