Nesta página, descrevemos como usar o início rápido da inferência do GKE para simplificar a implantação de cargas de trabalho de inferência de IA/ML no Google Kubernetes Engine (GKE). O guia de início rápido de inferência é um utilitário que permite especificar seus requisitos comerciais de inferência e receber configurações otimizadas do Kubernetes com base nas práticas recomendadas e nos comparativos de mercado do Google para modelos, servidores de modelos, aceleradores (GPUs, TPUs), escalonamento e armazenamento. Isso ajuda a evitar o processo demorado de ajustar e testar configurações manualmente.
Esta página é destinada a engenheiros de machine learning (ML), administradores e operadores de plataforma e especialistas em dados e IA que querem entender como gerenciar e otimizar o GKE de maneira eficiente para inferência de IA/ML. Para saber mais sobre papéis comuns e tarefas de exemplo que mencionamos no conteúdo do Google Cloud , consulte Tarefas e funções de usuário comuns do GKE.
Para saber mais sobre conceitos e terminologia de disponibilização de modelos e como os recursos de IA generativa do GKE podem melhorar e apoiar a performance de disponibilização de modelos, consulte Sobre a inferência de modelos no GKE.
Antes de ler esta página, confira os conceitos de Kubernetes, GKE e serviço de modelos.
Como usar o guia de início rápido de inferência
Com o início rápido de inferência, você pode analisar a performance e a eficiência de custo das suas cargas de trabalho de inferência e tomar decisões baseadas em dados sobre estratégias de alocação de recursos e implantação de modelos.
As etapas gerais para usar o guia de início rápido de inferência são as seguintes:
Analisar performance e custo: explore as configurações disponíveis e filtre-as com base nos seus requisitos de performance e custo usando o comando
gcloud container ai profiles list. Para conferir o conjunto completo de dados de comparativo de mercado de uma configuração específica, use o comandogcloud container ai profiles benchmarks list. Com esse comando, é possível identificar o hardware mais econômico para seus requisitos específicos de desempenho.Implantar manifestos: depois da análise, é possível gerar e implantar um manifesto otimizado do Kubernetes. Você também pode ativar otimizações para armazenamento e escalonamento automático. É possível fazer a implantação no console do Google Cloud ou usando o comando
kubectl apply. Antes de fazer a implantação, verifique se você tem cota de acelerador suficiente para as GPUs ou TPUs selecionadas no seu projeto Google Cloud .(Opcional) Execute seus próprios comparativos de mercado: as configurações e os dados de desempenho fornecidos são baseados em comparativos de mercado que usam o conjunto de dados ShareGPT. O desempenho das suas cargas de trabalho pode variar em relação a esse valor de referência. Para medir o desempenho do modelo em várias condições, use a ferramenta de comparativo de inferência (link em inglês) experimental.
Vantagens
O guia de início rápido da inferência ajuda você a economizar tempo e recursos fornecendo configurações otimizadas. Essas otimizações melhoram o desempenho e reduzem os custos de infraestrutura das seguintes maneiras:
- Você recebe práticas recomendadas detalhadas e personalizadas para definir o acelerador (GPU e TPU), o servidor de modelo e as configurações de escalonamento. O GKE atualiza rotineiramente o início rápido de inferência com os patches, as imagens e os comparativos de performance mais recentes.
- É possível especificar os requisitos de latência e capacidade de processamento da sua carga de trabalho usando a interface do consoleGoogle Cloud ou uma interface de linha de comando, e receber práticas recomendadas detalhadas e personalizadas como manifestos de implantação do Kubernetes.
Como funciona
O guia de início rápido de inferência oferece práticas recomendadas personalizadas com base em benchmarks internos exaustivos do Google de desempenho de réplica única para combinações de modelo, servidor de modelo e topologia de acelerador. Esses comparativos de mercado representam a latência versus a capacidade, incluindo o tamanho da fila e as métricas de cache KV, que mapeiam as curvas de desempenho para cada combinação.
Como as práticas recomendadas personalizadas são geradas
Medimos a latência em tempo normalizado por token de saída (NTPOT) e tempo para o primeiro token (TTFT) em milissegundos, e a capacidade em tokens de saída por segundo, saturando os aceleradores. Para saber mais sobre essas métricas de desempenho, consulte Sobre a inferência de modelos no GKE.
O perfil de latência de exemplo a seguir ilustra o ponto de inflexão em que a taxa de transferência atinge um patamar (verde), o ponto pós-inflexão em que a latência piora (vermelho) e a zona ideal (azul) para uma taxa de transferência ideal na meta de latência. O início rápido da inferência fornece dados de desempenho e configurações para essa zona ideal.
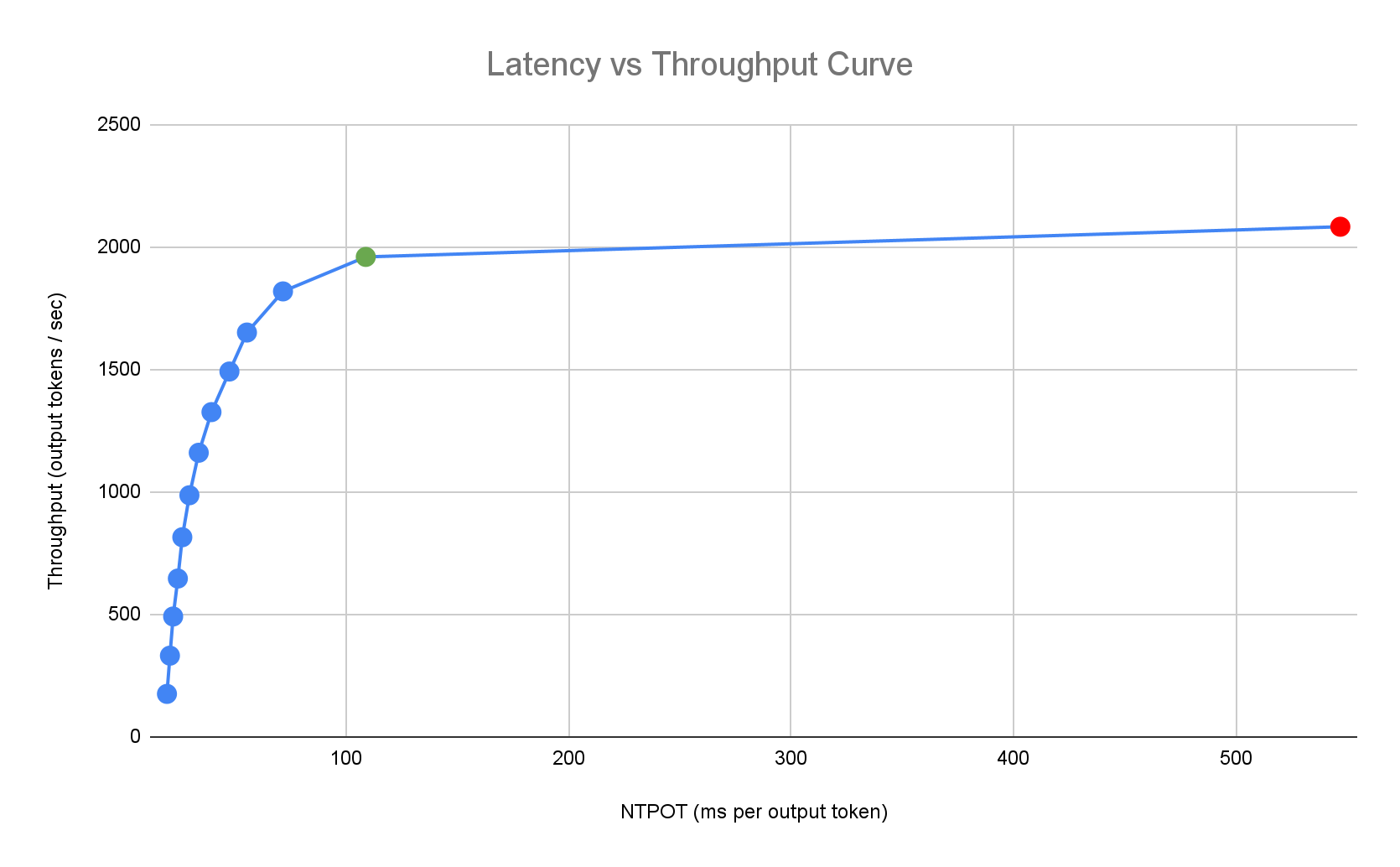
Com base nos requisitos de latência de um aplicativo de inferência, o início rápido da inferência identifica combinações adequadas e determina o ponto de operação ideal na curva de latência-capacidade de processamento. Esse ponto define o limite do escalonador automático horizontal de pods (HPA) com um buffer para considerar a latência de escalonamento vertical. O limite geral também informa o número inicial de réplicas necessárias, embora o HPA ajuste esse número dinamicamente com base na carga de trabalho.
Cálculo dos custos
Para calcular o custo, o guia de início rápido da inferência usa uma proporção de custo de saída para entrada configurável. Por exemplo, se essa proporção for definida como 4, será presumido que cada token de saída custa quatro vezes mais que um token de entrada. As seguintes equações são usadas para calcular as métricas de custo por token:
\[ \$/\text{output token} = \frac{\text{GPU \$/s}}{(\frac{1}{\text{output-to-input-cost-ratio}} \cdot \text{input tokens/s} + \text{output tokens/s})} \]
em que
\[ \$/\text{input token} = \frac{\text{\$/output token}}{\text{output-to-input-cost-ratio}} \]
Comparativo de mercado
As configurações e os dados de performance fornecidos são baseados em comparativos de mercado que usam o conjunto de dados ShareGPT para enviar tráfego com a seguinte distribuição de entrada e saída.
| Tokens de entrada | Tokens de saída | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mín. | Mediana | Média | P90 | P99 | Máx. | Mín. | Mediana | Média | P90 | P99 | Máx. |
| 4 | 108 | 226 | 635 | 887 | 1024 | 1 | 132 | 195 | 488 | 778 | 1024 |
Antes de começar
Antes de começar, verifique se você realizou as tarefas a seguir:
- Ativar a API Google Kubernetes Engine. Ativar a API Google Kubernetes Engine
- Se você quiser usar a CLI do Google Cloud para essa tarefa,
instale e inicialize a
gcloud CLI. Se você instalou a gcloud CLI anteriormente, instale a versão
mais recente executando
gcloud components update.
No console do Google Cloud , na página do seletor de projetos, selecione ou crie um projeto do Google Cloud .
Verifique se o faturamento está ativado para seu projeto do Google Cloud .
Verifique se você tem capacidade de acelerador suficiente para seu projeto:
- Se você usa GPUs: verifique a página "Cotas".
- Se você usa TPUs, consulte Garantir cota para TPUs e outros recursos do GKE.
Preparar-se para usar a interface do usuário de IA/ML do GKE
Se você usar o console do Google Cloud , também precisará criar um cluster do Autopilot, caso ainda não tenha um no seu projeto. Siga as instruções em Criar um cluster do Autopilot.
Preparar para usar a interface de linha de comando
Se você usar a CLI gcloud para executar o guia de início rápido da inferência, também precisará executar estes comandos adicionais:
Ative a
gkerecommender.googleapis.comAPI:gcloud services enable gkerecommender.googleapis.comDefina o projeto de cota de faturamento que você usa para chamadas de API:
gcloud config set billing/quota_project PROJECT_IDVerifique se a versão da CLI gcloud é pelo menos 536.0.1. Caso contrário, execute o seguinte:
gcloud components update
Limitações
Conheça as seguintes limitações antes de começar a usar o tutorial de início rápido da inferência:
- A implantação de modelos do consoleGoogle Cloud é compatível apenas com clusters do Autopilot.
- O guia de início rápido de inferência não fornece perfis para todos os modelos compatíveis com um determinado servidor de modelos.
- Se você não definir a variável de ambiente
HF_HOMEao usar um manifesto gerado para um modelo grande (90 GiB ou mais) do Hugging Face, use um cluster com discos de inicialização maiores do que o padrão ou modifique o manifesto para definirHF_HOMEcomo/dev/shm/hf_cache. Isso vai usar a RAM para o cache em vez do disco de inicialização do nó. Para mais informações, consulte a seção Solução de problemas. - O carregamento de modelos do Cloud Storage só é compatível com a implantação em clusters com o driver CSI do Cloud Storage FUSE e a Federação de Identidade da Carga de Trabalho para GKE ativados, que são ativados por padrão em clusters do Autopilot. Para mais detalhes, consulte Configurar o driver CSI do Cloud Storage FUSE para GKE.
Analisar e conferir configurações otimizadas para inferência de modelo
Nesta seção, descrevemos como analisar e explorar recomendações de configuração usando a Google Cloud CLI.
Use o comando gcloud container ai profiles para explorar e analisar perfis otimizados (combinações de modelo, servidor de modelo, versão do servidor de modelo e aceleradores):
Modelos
Para explorar e selecionar um modelo, use a opção models.
gcloud container ai profiles models list
Perfis
Use o comando list
para analisar os perfis gerados e filtrá-los com base nos seus requisitos de
performance e custo. Exemplo:
gcloud container ai profiles list \
--model=openai/gpt-oss-20b \
--pricing-model=on-demand \
--target-ttft-milliseconds=300
A saída mostra perfis compatíveis com métricas de desempenho, como taxa de transferência, latência e custo por milhão de tokens no ponto de inflexão. Ele é semelhante a este:
Instance Type Accelerator Cost/M Input Tokens Cost/M Output Tokens Output Tokens/s NTPOT(ms) TTFT(ms) Model Server Model Server Version Model
a3-highgpu-1g nvidia-h100-80gb 0.009 0.035 13335 67 297 vllm gptoss openai/gpt-oss-20b
Os valores representam a performance observada no ponto em que a taxa de transferência para de aumentar e a latência começa a aumentar drasticamente (ou seja, o ponto de inflexão ou saturação) para um determinado perfil com esse tipo de acelerador. Para saber mais sobre essas métricas de desempenho, consulte Sobre a inferência de modelos no GKE.
Para conferir a lista completa de flags que podem ser definidas, consulte a documentação do comando
list.
Todas as informações de preços estão disponíveis apenas em dólar americano e são definidas como padrão para a região us-east5, exceto as configurações que usam máquinas A3, que são definidas como padrão para a região us-central1.
Comparativos de mercado
Para receber todos os dados de comparativo de mercado de um perfil específico, use o comando
benchmarks list.
Exemplo:
gcloud container ai profiles benchmarks list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server=vllm \
--pricing-model=on-demand
A saída contém uma lista de métricas de desempenho de comparativos de mercado executados em diferentes taxas de solicitação.
O comando mostra a saída no formato CSV. Para armazenar a saída como um arquivo, use o redirecionamento de saída. Por exemplo: gcloud container ai profiles benchmarks list > profiles.csv.
Para conferir a lista completa de flags que podem ser definidas, consulte a documentação do comando
benchmarks list.
Depois de escolher um modelo, um servidor de modelo, uma versão do servidor de modelo e um acelerador, você pode criar um manifesto de implantação.
Implantar configurações recomendadas
Esta seção descreve como gerar e implantar recomendações de configuração usando o console do Google Cloud ou a linha de comando.
Console
- No console do Google Cloud , acesse a página de IA/ML do GKE.
- Clique em Implantar modelos.
Selecione um modelo que você quer implantar. Os modelos compatíveis com o guia de início rápido de inferência são mostrados com a tag Otimizado.
- Se você selecionou um modelo de fundação, uma página do modelo será aberta. Clique em Implantar. Você ainda pode modificar a configuração antes da implantação real.
- Você vai receber uma solicitação para criar um cluster do Autopilot se não houver um no seu projeto. Siga as instruções em Criar um cluster do Autopilot. Depois de criar o cluster, volte para a página de IA/ML do GKE no console do Google Cloud para selecionar um modelo.
A página de implantação do modelo é preenchida automaticamente com o modelo selecionado, o servidor de modelo e o acelerador recomendados. Você também pode configurar definições como latência máxima e origem do modelo.
(Opcional) Para conferir o manifesto com a configuração recomendada, clique em Ver YAML.
Para implantar o manifesto com a configuração recomendada, clique em Implantar. A operação de implantação pode levar vários minutos para ser concluída.
Para conferir sua implantação, acesse a página Kubernetes Engine > Cargas de trabalho.
gcloud
Prepare-se para carregar modelos do seu registro de modelos: o início rápido de inferência aceita o carregamento de modelos do Hugging Face ou do Cloud Storage.
Hugging face
Se você ainda não tiver um, gere um token de acesso do Hugging Face e um secret correspondente do Kubernetes.
Para criar um secret do Kubernetes que contenha o token do Hugging Face, execute o seguinte comando:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACESubstitua os seguintes valores:
- HUGGING_FACE_TOKEN: o token do Hugging Face que você criou antes.
- NAMESPACE: o namespace do Kubernetes em que você quer implantar o servidor de modelos.
Alguns modelos também podem exigir que você aceite e assine o contrato de licença de consentimento.
Cloud Storage
É possível carregar modelos compatíveis do Cloud Storage com uma configuração ajustada do Cloud Storage FUSE. Para isso, primeiro carregue o modelo do Hugging Face no seu bucket do Cloud Storage.
É possível implantar esse job do Kubernetes para transferir o modelo, mudando
MODEL_IDpara o modelo compatível do início rápido de inferência.Gerar manifestos: você tem estas opções para gerar manifestos:
- Configuração básica: gera os manifestos padrão de implantação, serviço e PodMonitoring do Kubernetes para implantar um servidor de inferência de réplica única.
- (Opcional) Configuração otimizada para armazenamento: gera um manifesto com uma configuração ajustada do Cloud Storage FUSE para carregar modelos de um bucket do Cloud Storage. Para ativar essa configuração, use a flag
--model-bucket-uri. Uma configuração ajustada do Cloud Storage FUSE pode melhorar o tempo de inicialização do pod de LLM em mais de sete vezes. (Opcional) Configuração otimizada para escalonamento automático: gera um manifesto com um escalonador automático horizontal de pods (HPA) para ajustar automaticamente o número de réplicas do servidor de modelo com base no tráfego. Para ativar essa configuração, especifique uma meta de latência com flags como
--target-ntpot-milliseconds.
Configuração básica
No terminal, use a opção
manifestspara gerar manifestos de implantação, serviço e PodMonitoring:gcloud container ai profiles manifests createUse os parâmetros obrigatórios
--model,--model-servere--accelerator-typepara personalizar o manifesto.Também é possível definir estes parâmetros:
--target-ntpot-milliseconds: defina esse parâmetro para especificar o limite do HPA. Esse parâmetro permite definir um limite de escalonamento para manter a latência P50 do tempo normalizado por token de saída (NTPOT, na sigla em inglês), que é medida no 50º percentil, abaixo do valor especificado. Escolha um valor acima da latência mínima do seu acelerador. O HPA é configurado para capacidade de processamento máxima se você especificar um valor de NTPOT acima da latência máxima do acelerador. Exemplo:gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200--target-ttft-milliseconds: filtra perfis que excedem a meta de latência do TTFT.--output-path: se especificado, a saída será salva no caminho fornecido, em vez de ser impressa no terminal. Assim, você pode editar a saída antes de implantá-la. Por exemplo, é possível usar essa opção com--output=manifestse você quiser salvar o manifesto em um arquivo YAML. Exemplo:gcloud container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml
Para conferir a lista completa de flags que podem ser definidas, consulte a documentação do comando
manifests create.Otimização de armazenamento
É possível melhorar o tempo de inicialização do pod carregando modelos do Cloud Storage usando uma configuração ajustada do Cloud Storage FUSE. O carregamento do Cloud Storage exige as versões 1.29.6-gke.1254000, 1.30.2-gke.1394000 ou mais recentes do GKE.
Para isso, siga estas etapas:
- Carregue o modelo do repositório do Hugging Face para seu bucket do Cloud Storage.
Defina a flag
--model-bucket-uriao gerar o manifesto. Isso configura o modelo para carregar de um bucket do Cloud Storage usando o driver CSI do Cloud Storage FUSE. O URI precisa apontar para o caminho que contém o arquivoconfig.jsone os pesos do modelo. É possível especificar um caminho para um diretório no bucket anexando-o ao URI do bucket.Exemplo:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --accelerator-type=nvidia-l4 \ --model-bucket-uri=gs://BUCKET_NAME \ --output-path=manifests.yamlSubstitua
BUCKET_NAMEpelo nome do bucket do Cloud Storage.Antes de aplicar o manifesto, execute o comando
gcloud storage buckets add-iam-policy-bindingencontrado nos comentários do manifesto. Esse comando é necessário para conceder à conta de serviço do GKE permissão para acessar o bucket do Cloud Storage usando a Federação de Identidade da Carga de Trabalho para GKE.Se você pretende escalonar a implantação para mais de uma réplica, escolha uma das seguintes opções para evitar erros de gravação simultânea no caminho do cache XLA (
VLLM_XLA_CACHE_PATH):- Opção 1 (recomendada): primeiro, dimensione a implantação para uma réplica. Aguarde até que o pod esteja pronto, o que permite que ele grave no cache XLA. Em seguida, aumente para o número de réplicas desejado. As réplicas subsequentes vão ler do cache preenchido sem conflitos de gravação.
- Opção 2: remova completamente a variável de ambiente
VLLM_XLA_CACHE_PATHdo manifesto. Essa abordagem é mais simples, mas desativa o armazenamento em cache para todas as réplicas.
Em tipos de aceleradores de TPU, esse caminho de cache é usado para armazenar o cache de compilação XLA, o que acelera a preparação do modelo para implantações repetidas.
Para mais dicas sobre como melhorar o desempenho, consulte Otimizar o driver CSI do Cloud Storage FUSE para o desempenho do GKE.
Otimizado para escalonamento automático
É possível configurar o escalonador automático horizontal de pods (HPA) para ajustar automaticamente o número de réplicas do servidor de modelo com base na carga. Isso ajuda os servidores de modelo a processar cargas variadas de maneira eficiente, escalonando para cima ou para baixo conforme necessário. A configuração do HPA segue as práticas recomendadas de escalonamento automático para guias de GPUs e TPUs.
Para incluir configurações do HPA ao gerar manifestos, use uma ou ambas as flags
--target-ntpot-millisecondse--target-ttft-milliseconds. Esses parâmetros definem um limite de escalonamento para que o HPA mantenha a latência P50 do NTPOT ou do TTFT abaixo do valor especificado. Se você definir apenas uma dessas flags, somente essa métrica será considerada para o escalonamento.Escolha um valor acima da latência mínima do seu acelerador. O HPA é configurado para capacidade de processamento máxima se você especificar um valor acima da latência máxima do seu acelerador.
Exemplo:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=250Criar um cluster: é possível disponibilizar seu modelo em clusters do GKE Autopilot ou Standard. Recomendamos que você use um cluster do Autopilot para ter uma experiência totalmente gerenciada do Kubernetes. Para escolher o modo de operação do GKE mais adequado para suas cargas de trabalho, consulte Escolher um modo de operação do GKE.
Se você não tiver um cluster, siga estas etapas:
Piloto automático
Siga estas instruções para criar um cluster do Autopilot. O GKE processa o provisionamento dos nós com capacidade de GPU ou TPU com base nos manifestos de implantação, se você tiver a cota necessária no seu projeto.
Padrão
- Crie um cluster zonal ou regional.
Crie um pool de nós com os aceleradores adequados. Siga estas etapas com base no tipo de acelerador escolhido:
- GPUs: primeiro, verifique a página "Cotas" no console do Google Cloud para garantir que você tenha capacidade de GPU suficiente. Em seguida, siga as instruções em Criar um pool de nós de GPU.
- TPUs: primeiro, siga as instruções em Garantir cota para TPUs e outros recursos do GKE para verificar se você tem TPUs suficientes. Em seguida, crie um pool de nós de TPU.
(Opcional, mas recomendado) Ative os recursos de capacidade de observação: na seção de comentários do manifesto gerado, outros comandos são fornecidos para ativar os recursos de capacidade de observação sugeridos. Ao ativar esses recursos, você recebe mais insights para monitorar a performance e o status das cargas de trabalho e da infraestrutura subjacente.
Confira um exemplo de comando para ativar recursos de observabilidade:
gcloud container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALLPara mais informações, consulte Monitorar suas cargas de trabalho de inferência.
(Somente HPA) Implante um adaptador de métricas: um adaptador de métricas, como o adaptador de métricas personalizadas do Stackdriver, é necessário se os recursos do HPA foram gerados nos manifestos de implantação. O adaptador de métricas permite que o HPA acesse métricas do servidor de modelo que usam a API de métricas externas do kube. Para implantar o adaptador, consulte a documentação dele no GitHub.
Implante os manifestos: execute o comando
kubectl applye transmita o arquivo YAML dos manifestos. Exemplo:kubectl apply -f ./manifests.yaml
Testar os endpoints de implantação
Se você implantou o manifesto, o serviço implantado será exposto no seguinte endpoint:
http://model-model_server-service:8000/
O servidor de modelo, como o vLLM, geralmente detecta atividade na porta 8000.
Para testar a implantação, configure o encaminhamento de porta. Execute o seguinte comando em um terminal separado:
kubectl port-forward service/model-model_server-service 8000:8000
Para exemplos de como criar e enviar uma solicitação ao seu endpoint, consulte a documentação do vLLM.
Controle de versão do manifesto
O início rápido da inferência fornece os manifestos mais recentes que foram validados em versões recentes do cluster do GKE. O manifesto retornado para um perfil pode mudar com o tempo para que você receba uma configuração otimizada na implantação. Se você precisar de um manifesto estável, salve e armazene-o separadamente.
O manifesto inclui comentários e uma anotação recommender.ai.gke.io/version
no seguinte formato:
# Generated on DATE using:
# GKE cluster CLUSTER_VERSION
# GPU_DRIVER_VERSION GPU driver for node version NODE_VERSION
# Model server MODEL_SERVER MODEL_SERVER_VERSION
A anotação anterior tem os seguintes valores:
- DATE: a data em que o manifesto foi gerado.
- CLUSTER_VERSION: a versão do cluster do GKE usada para validação.
- NODE_VERSION: a versão do nó do GKE usada para validação.
- GPU_DRIVER_VERSION: (somente GPU) a versão do driver da GPU usada para validação.
- MODEL_SERVER: o servidor de modelo usado no manifesto.
- MODEL_SERVER_VERSION: a versão do servidor de modelo usada no manifesto.
Monitore suas cargas de trabalho de inferência
Para monitorar as cargas de trabalho de inferência implantadas, acesse o Metrics Explorer no Google Cloud console.
Ativar o monitoramento automático
O GKE inclui um recurso de monitoramento automático que faz parte dos recursos de observabilidade mais amplos. Esse recurso verifica o cluster em busca de cargas de trabalho executadas em servidores de modelos compatíveis e implanta os recursos PodMonitoring que permitem que essas métricas de carga de trabalho fiquem visíveis no Cloud Monitoring. Para mais informações sobre como ativar e configurar o monitoramento automático, consulte Configurar o monitoramento automático de aplicativos para cargas de trabalho.
Depois de ativar o recurso, o GKE instala painéis pré-criados para monitorar aplicativos em cargas de trabalho compatíveis.
Se você fizer a implantação na página de IA/ML do GKE no console Google Cloud ,
os recursos PodMonitoring e HPA serão criados automaticamente para você usando a
configuração targetNtpot.
Solução de problemas
- Se você definir uma latência muito baixa, o guia de início rápido da inferência talvez não gere uma recomendação. Para corrigir esse problema, selecione uma meta de latência entre os valores mínimo e máximo observados para os aceleradores selecionados.
- O guia de início rápido da inferência existe independentemente dos componentes do GKE. Portanto, a versão do cluster não é diretamente relevante para usar o serviço. No entanto, recomendamos usar um cluster novo ou atualizado para evitar discrepâncias no desempenho.
- Se você receber um erro
PERMISSION_DENIEDpara comandosgkerecommender.googleapis.cominformando que um projeto de cota está faltando, defina-o manualmente. Executegcloud config set billing/quota_project PROJECT_IDpara corrigir isso.
O pod foi removido devido ao pouco armazenamento temporário
Ao implantar um modelo grande (90 GiB ou mais) do Hugging Face, seu pod poderá ser removido com uma mensagem de erro semelhante a esta:
Fails because inference server consumes too much ephemeral storage, and gets evicted low resources: Warning Evicted 3m24s kubelet The node was low on resource: ephemeral-storage. Threshold quantity: 10120387530, available: 303108Ki. Container inference-server was using 92343412Ki, request is 0, has larger consumption of ephemeral-storage..,
Esse erro ocorre porque o modelo é armazenado em cache no disco de inicialização do nó, uma forma de armazenamento efêmero. O disco de inicialização é usado para armazenamento temporário quando o manifesto de implantação não define a variável de ambiente HF_HOME como um diretório na RAM do nó.
- Por padrão, os nós do GKE têm um disco de inicialização de 100 GiB.
- O GKE reserva 10% do disco de inicialização para sobrecarga do sistema, deixando 90 GiB para suas cargas de trabalho.
- Se o tamanho do modelo for de 90 GiB ou mais e for executado em um disco de inicialização de tamanho padrão, o kubelet vai desalojar o pod para liberar o armazenamento efêmero.
Para resolver esse problema, escolha uma das seguintes opções:
- Usar RAM para o cache de modelos: no manifesto de implantação, defina a variável de ambiente
HF_HOMEcomo/dev/shm/hf_cache. Isso usa a RAM do nó para armazenar o modelo em cache em vez do disco de inicialização. - Aumente o tamanho do disco de inicialização:
- GKE Standard: aumente o tamanho do disco de inicialização ao criar um cluster, criar um pool de nós ou atualizar um pool de nós.
- Autopilot: para solicitar um disco de inicialização maior, crie uma classe de computação personalizada e defina o campo
bootDiskSizena regramachineType.
O pod entra em um loop de falhas ao carregar modelos do Cloud Storage
Depois de implantar um manifesto gerado com a flag --model-bucket-uri,
a implantação pode ficar presa e o pod entra em um estado CrashLoopBackOff.
Verificar os registros do contêiner inference-server pode mostrar um erro enganoso, como huggingface_hub.errors.HFValidationError. Exemplo:
huggingface_hub.errors.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '/data'.
Esse erro geralmente ocorre quando o caminho do Cloud Storage fornecido na flag --model-bucket-uri está incorreto. O servidor de inferência, como o vLLM, não consegue encontrar os arquivos de modelo necessários (como config.json) no caminho montado.
Quando não consegue encontrar os arquivos locais, o servidor volta a presumir que o
caminho é um ID de repositório do Hugging Face Hub. Como o caminho não é um ID de repositório válido, o servidor falha com um erro de validação e entra em um loop de falhas.
Para resolver esse problema, verifique se o caminho fornecido à flag --model-bucket-uri aponta para o diretório exato no bucket do Cloud Storage que contém o arquivo config.json do modelo e todos os pesos associados.
A seguir
- Acesse o portal de orquestração de IA/ML no GKE para conferir nossos guias, tutoriais e casos de uso oficiais para executar cargas de trabalho de IA/ML no GKE.
- Para mais informações sobre a otimização da veiculação de modelos, consulte Práticas recomendadas para otimizar a inferência de modelos de linguagem grandes com GPUs. Ele aborda práticas recomendadas para veiculação de LLMs com GPUs no GKE, como quantização, paralelismo de tensor e gerenciamento de memória.
- Para mais informações sobre práticas recomendadas de escalonamento automático, consulte estes guias:
- Para informações sobre práticas recomendadas de armazenamento, consulte Otimizar o driver CSI do Cloud Storage FUSE para a performance do GKE.
- Confira exemplos experimentais de como usar o GKE para acelerar suas iniciativas de IA/ML no GKE AI Labs.