你可以使用詞彙表定義網域專屬的術語。詞彙表可讓您新增字詞配對,包括來源和目標語言的字詞。詞彙配對可確保 Vertex AI Translation 服務翻譯術語時保持一致。
以下是可定義詞彙表項目的案例範例:
- 產品名稱:識別產品名稱,以便保留在譯文中。例如,「Google Home」必須翻譯為「Google Home」。
- 模稜兩可的字詞:指定含糊不清的字詞和同音異義字的意思。舉例來說,「bat」可以指運動器材或動物。
- 外來語:說明從其他語言借用的字詞意義。舉例來說,法文的「bouillabaisse」翻譯成英文也是「bouillabaisse」,指的是魚湯。
詞彙表中的字詞可以是單一字詞 (也稱為「符記」) 或簡短詞組,通常少於五個字。如果字詞是停用字,Vertex AI Translation 會忽略相符的字彙表項目。
Vertex AI Translation 提供下列詞彙表方法,適用於 Google Distributed Cloud (GDC) 氣隙隔離解決方案:
| 方法 | 說明 |
|---|---|
CreateGlossary |
建立詞彙表。 |
GetGlossary |
傳回儲存的字彙表。 |
ListGlossaries |
傳回專案中的字彙表 ID 清單。 |
DeleteGlossary |
刪除不再需要的字彙表。 |
事前準備
如要建立術語表來定義翻譯術語,您必須先建立名為 translation-glossary-project 的專案。專案的自訂資源必須如下列範例所示:
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
labels:
atat.config.google.com/clin-number: CLIN_NUMBER
atat.config.google.com/task-order-number: TASK_ORDER_NUMBER
name: translation-glossary-project
namespace: platform
如要取得使用字彙表所需的權限,請要求專案 IAM 管理員在專案命名空間中授予下列角色:
- AI Translation 開發人員:取得 AI Translation 開發人員 (
ai-translation-developer) 角色,即可存取 Vertex AI Translation 服務。 - 專案 Bucket 管理員:取得專案 Bucket 管理員 (
project-bucket-admin) 角色,管理 bucket 中的儲存空間 bucket 和物件,以便建立及上傳檔案。
如要進一步瞭解必要條件,請參閱「設定翻譯專案」。
建立詞彙表檔案
您必須建立詞彙表檔案,儲存原文和譯文語言的字詞。本節提供兩種不同的詞彙表版面配置,可用於定義術語。
下表說明 Distributed Cloud 支援的字彙檔案限制:
| 說明 | 限制 |
|---|---|
| 檔案大小上限 | 1,040 萬 (10,485,760) 個 UTF-8 位元組 |
| 詞彙字詞長度上限 | 1,024 個 UTF-8 位元組 |
| 專案詞彙資源數上限 | 10,000 |
為字彙表檔案選擇下列其中一種版面配置:
- 單向詞彙表:指定特定語言中一組原文和譯文的預期翻譯結果。單向字彙表支援 TSV、CSV 和 TMX 檔案格式。
- 對等字詞集詞彙表:在每個資料列中,指定多種語言的預期譯文。對等字詞集詞彙表支援 CSV 檔案格式。
單向詞彙表
Vertex AI Translation API 接受定位點分隔值 (TSV) 和半形逗號分隔值 (CSV)。每個資料列都包含一對以半形定位字元 (\t) 或半形逗號 (,) 分隔的字詞 (適用於這些檔案格式)。
Vertex AI Translation API 也接受 TMX 格式,這是一種標準 XML 格式,可提供翻譯的原文和譯文詞組配對。支援的輸入檔案格式為 TMX 1.4 版。
以下範例顯示單向字彙表 TSV、CSV 和 TMX 檔案格式的必要結構:
TSV 和 CSV
下圖顯示 TSV 或 CSV 檔案中的兩個資料欄。第一欄包含來源語言字詞,第二欄則包含目標語言字詞。

建立詞彙表檔案時,您可以定義標題列。字彙表要求會將檔案提供給 Vertex AI Translation API。
TMX
下列範例說明 TMX 檔案的必要結構:
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE tmx SYSTEM "tmx14.dtd">
<tmx version="1.4">
<header segtype="sentence" o-tmf="UTF-8" adminlang="en" srclang="en" datatype="PlainText"/>
<body>
<tu>
<tuv xml:lang="en">
<seg>account</seg>
</tuv>
<tuv xml:lang="es">
<seg>cuenta</seg>
</tuv>
</tu>
<tu>
<tuv xml:lang="en">
<seg>directions</seg>
</tuv>
<tuv xml:lang="es">
<seg>indicaciones</seg>
</tuv>
</tu>
</body>
</tmx>
如果檔案包含本範例未顯示的 XML 標記,Vertex AI Translation API 會忽略這些標記。
請在 TMX 檔案中加入下列元素,確保 Vertex AI Translation API 能順利處理檔案:
<header>:使用srclang屬性識別來源語言。<tu>:包含一組指定相同原文與譯文語言的<tuv>元素。這些<tuv>元素符合下列規定:- 每個
<tuv>元素都會使用xml:lang屬性,識別所含文字的語言。使用 ISO-639-1 代碼識別原文和譯文語言。如要查看支援的語言及其語言代碼,請參閱這份清單。 - 如果
<tu>元素包含超過兩個<tuv>元素,Vertex AI Translation API 只會處理符合原文語言的第一個<tuv>元素,以及符合譯文語言的第一個<tuv>元素。服務會忽略其餘的<tuv>元素。 - 如果
<tu>元素沒有一組相符的<tuv>元素,Vertex AI Translation API 會忽略無效的<tu>元素。
- 每個
<seg>:代表一般文字字串。Vertex AI Translation API 會先從<seg>元素中排除標記代碼,再處理檔案。如果<tuv>元素包含多個<seg>元素,Vertex AI Translation API 會將文字串聯為單一元素,並以空格分隔文字字串。
找出單向詞彙表中的詞彙後,請將檔案上傳至儲存空間值區,然後建立並匯入詞彙表,讓 Vertex AI Translation API 使用。
對等字詞集詞彙表
Vertex AI Translation API 接受 CSV 格式的同義詞集詞彙表檔案。如要定義對等字詞集,請建立具有多個資料欄的 CSV 檔案,其中每個資料列均列出單一詞彙的多種語言版本。如要查看支援的語言及其語言代碼,請參閱這份清單。
下圖顯示多欄 CSV 檔案的範例。每個資料列代表一個詞彙,每個資料欄則代表該詞彙在不同語言中的翻譯。
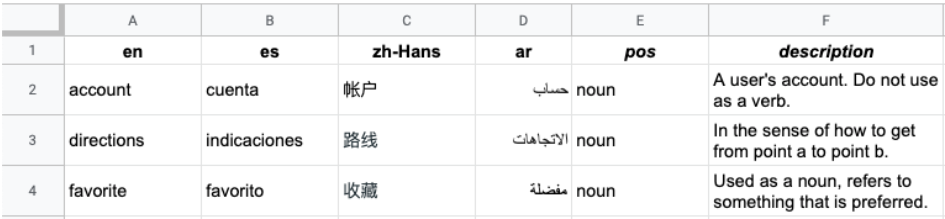
標頭是檔案中的第一列,用來標示各資料欄的語言。標題列使用 ISO-639-1 或 BCP-47 標準語言代碼。Vertex AI Translation API 不會使用詞性 (pos) 資訊,也不會驗證特定位置值。
後續的每個資料列會包含標題所示語言的對等詞彙。如果某個詞彙不適用於所有語言,您可以將資料欄留空。
在對等字詞集中找出詞彙後,請將檔案上傳至儲存空間值區,然後建立及匯入詞彙表,讓 Vertex AI Translation API 使用。
將字彙表檔案上傳至儲存空間值區
請按照下列步驟將字彙表檔案上傳至儲存空間 bucket:
- 設定物件儲存空間的 gcloud CLI。
在專案命名空間中建立儲存空間 bucket。使用
Standard儲存空間類別。您可以在專案命名空間中部署
Bucket資源,藉此建立儲存空間 bucket:apiVersion: object.gdc.goog/v1 kind: Bucket metadata: name: glossary-bucket namespace: translation-glossary-project spec: description: bucket for translation glossary storageClass: Standard bucketPolicy: lockingPolicy: defaultObjectRetentionDays: 90將 bucket 的
read權限授予 Vertex AI Translation 服務使用的服務帳戶 (ai-translation-system-sa)。您可以按照下列步驟,使用自訂資源建立角色和角色繫結:
在專案命名空間中部署
Role資源,即可建立角色:apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: ai-translation-glossary-reader namespace: translation-glossary-project rules: - apiGroups: - object.gdc.goog resources: - buckets verbs: - read-object在專案命名空間中部署
RoleBinding資源,建立角色繫結:apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: ai-translation-glossary-reader-rolebinding namespace: translation-glossary-project roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: ai-translation-glossary-reader subjects: - kind: ServiceAccount name: ai-translation-system-sa namespace: ai-translation-system
將字彙表檔案上傳至您建立的儲存空間 bucket。詳情請參閱「在專案中上傳及下載儲存空間物件」。
建立詞彙集
CreateGlossary 方法會建立字彙表,並將 ID 傳回給產生字彙表的長期執行作業。
如要建立字彙表,請先替換下列項目,再使用任何要求資料:
- :貴機構使用的 Vertex AI Translation 端點。
ENDPOINT詳情請參閱服務狀態和端點。 PROJECT_ID:您的專案 ID。GLOSSARY_ID:您的詞彙表 ID,也就是資源名稱。BUCKET_NAME:詞彙表檔案所在的儲存空間 bucket 名稱。GLOSSARY_FILENAME:儲存空間 bucket 中的詞彙表檔案名稱。
以下是建立字彙表的 HTTP 要求語法:
POST https://ENDPOINT/v3/projects/PROJECT_ID/glossaries
根據您建立的詞彙表檔案,選擇下列任一選項來建立詞彙表:
單向
如要建立單向詞彙表,請指定語言配對 (language_pair),包括原文語言 (source_language_code) 和譯文語言 (target_language_code)。
如要建立單向字彙表,請按照下列步驟操作:
將下列要求主體儲存在名為
request.json的 JSON 檔案中:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID, "language_pair": { "source_language_code": "SOURCE_LANGUAGE", "target_language_code": "TARGET_LANGUAGE" }, "{"input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }更改下列內容:
提出要求。下列範例使用 REST API 方法和指令列,但您也可以使用用戶端程式庫建立單向字彙表。
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
將 TOKEN 替換為您取得的驗證權杖。
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest
-Method POST
-Headers $headers
-ContentType: "application/json; charset=utf-8"
-InFile request.json
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
將 TOKEN 替換為您取得的驗證權杖。
您應該會收到類似以下的 JSON 回應:
{
"name": "projects/PROJECT_ID/operations/operation-id",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
對等字詞集
如要建立對等字詞集詞彙表,請指定語言集 (language_codes_set) 和詞彙表的語言代碼 (language_codes)。
請按照下列步驟建立對應的詞彙集詞彙表:
將下列要求主體儲存在名為
request.json的 JSON 檔案中:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID", "language_codes_set": { "language_codes": ["LANGUAGE_CODE_1", "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ... ] }, "input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }將
LANGUAGE_CODE換成詞彙表所用語言的代碼。如要查看支援的語言及其語言代碼,請參閱這份清單。提出要求:
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
將 TOKEN 替換為您取得的驗證權杖。
您應該會收到類似以下的 JSON 回應:
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID,
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
將 TOKEN 替換為您取得的驗證權杖。
您應該會收到類似以下的 JSON 回應:
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Python
在您建立的 Python 指令碼中新增下列程式碼:
from google.cloud import translate_v3 as translate def create_glossary( project_id=PROJECT_ID, input_uri= "s3://BUCKET_NAME/GLOSSARY_FILENAME", glossary_id=GLOSSARY_ID, timeout=180, ): client = translate.TranslationServiceClient() # Supported language codes source_lang_code = "LANGUAGE_CODE_1" target_lang_code = "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ...儲存 Python 指令碼。
執行 Python 指令碼:
python SCRIPT_NAME
將 SCRIPT_NAME 替換為您為 Python 指令碼提供的名稱,例如 glossary.py。
如要進一步瞭解 create_glossary 方法,請參閱 Python 用戶端程式庫。
視詞彙表檔案大小而定,建立詞彙表通常不到 10 分鐘即可完成。您可以擷取這項作業的狀態,瞭解作業何時完成。
取得詞彙表
GetGlossary 方法會傳回儲存的字彙表。如果詞彙表不存在,輸出內容會傳回 NOT_FOUND 值。如要呼叫 GetGlossary 方法,請指定專案 ID 和詞彙表 ID。CreateGlossary 和 ListGlossaries 方法都會傳回字彙表 ID。
舉例來說,下列要求會傳回專案中特定字彙表的相關資訊:
curl
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
將 TOKEN 替換為您取得的驗證權杖。
Python
from google.cloud import translate_v3 as translate
def get_glossary(project_id="PROJECT_ID", glossary_id="GLOSSARY_ID"):
"""Get a particular glossary based on the glossary ID."""
client = translate.TranslationServiceClient()
name = client.glossary_path(project_id, glossary_id)
response = client.get_glossary(name=name)
print(u"Glossary name: {}".format(response.name))
print(u"Input URI: {}".format(response.input_config.s3_source.input_uri))
可列出詞彙表
ListGlossaries 方法會傳回專案中的字彙表 ID 清單。如果沒有字彙表,輸出內容會傳回 NOT_FOUND 值。如要呼叫 ListGlossaries 方法,請指定專案 ID 和 Vertex AI Translation 端點。
舉例來說,下列要求會傳回專案中的字彙表 ID 清單:
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries?page_size=10"
將 TOKEN 替換為您取得的驗證權杖。
刪除詞彙表
DeleteGlossary 方法會刪除詞彙表。如果詞彙表不存在,輸出內容會傳回 NOT_FOUND 值。如要呼叫 DeleteGlossary 方法,請指定專案 ID、字彙表 ID 和 Vertex AI Translation 端點。CreateGlossary 和 ListGlossaries 方法都會傳回字彙表 ID。
舉例來說,下列要求會從專案中刪除詞彙表:
curl -X DELETE \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
將 TOKEN 替換為您取得的驗證權杖。