용어집을 사용하여 도메인에 특정한 용어를 정의할 수 있습니다. 용어집을 사용하면 소스 및 타겟 언어 용어를 포함한 용어 쌍을 추가할 수 있습니다. 용어 쌍을 사용하면 Vertex AI Translation 서비스에서 용어를 일관되게 번역할 수 있습니다.
다음은 용어집 항목을 정의할 수 있는 사례의 예입니다.
- 제품 이름: 번역에 유지할 제품 이름을 식별합니다. 예를 들어 Google Home은 Google Home으로 번역되어야 합니다.
- 모호한 단어: 모호한 단어와 동음이의어의 의미를 지정합니다. 예를 들어 bat은 스포츠 장비나 동물을 의미할 수 있습니다.
- 차용어: 다른 언어에서 채택된 단어의 의미를 명확히 합니다. 예를 들어 프랑스어 bouillabaisse는 영어로 bouillabaisse(생선 스튜 요리)로 번역됩니다.
용어집의 용어는 단일 단어(토큰이라고도 함) 또는 짧은 구문(보통 5단어 미만)일 수 있습니다. 단어가 불용어인 경우 Vertex AI Translation은 일치하는 용어집 항목을 무시합니다.
Vertex AI Translation은 Google Distributed Cloud (GDC) 에어 갭에서 사용할 수 있는 다음과 같은 용어집 메서드를 제공합니다.
| 메서드 | 설명 |
|---|---|
CreateGlossary |
용어집을 만듭니다. |
GetGlossary |
저장된 용어집을 반환합니다. |
ListGlossaries |
프로젝트의 용어집 ID 목록을 반환합니다. |
DeleteGlossary |
더 이상 필요 없는 용어집을 삭제합니다. |
시작하기 전에
번역 용어를 정의하는 용어집을 만들기 전에 translation-glossary-project라는 프로젝트가 있어야 합니다. 프로젝트의 맞춤 리소스는 다음 예시와 같이 표시되어야 합니다.
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
labels:
atat.config.google.com/clin-number: CLIN_NUMBER
atat.config.google.com/task-order-number: TASK_ORDER_NUMBER
name: translation-glossary-project
namespace: platform
용어를 사용하는 데 필요한 권한을 얻으려면 프로젝트 IAM 관리자에게 프로젝트 네임스페이스에서 다음 역할을 부여해 달라고 요청하세요.
- AI 번역 개발자: Vertex AI Translation 서비스에 액세스하려면 AI 번역 개발자 (
ai-translation-developer) 역할을 부여받습니다. - 프로젝트 버킷 관리자: 버킷 내의 스토리지 버킷과 객체를 관리할 수 있는 프로젝트 버킷 관리자(
project-bucket-admin) 역할을 획득하여 파일을 만들고 업로드할 수 있습니다.
기본 요건에 대한 자세한 내용은 번역 프로젝트 설정을 참고하세요.
용어집 파일 만들기
출발어와 도착어 용어를 저장할 용어집 파일을 만들어야 합니다. 이 섹션에는 용어를 정의하는 데 사용할 수 있는 두 가지 다른 용어집 레이아웃이 포함되어 있습니다.
다음 표에서는 Distributed Cloud에서 지원되는 용어집 파일의 한도를 설명합니다.
| 설명 | 한도 |
|---|---|
| 최대 파일 크기 | 1,040만(10,485,760) UTF-8 바이트 |
| 용어집 용어의 최대 길이 | 1,024 UTF-8 바이트 |
| 프로젝트의 최대 용어집 리소스 수 | 10,000 |
용어집 파일에 다음 레이아웃 중 하나를 선택합니다.
- 단방향 용어집: 특정 언어의 출발어 및 도착어 쌍에 예상되는 번역을 지정합니다. 단방향 용어집은 TSV, CSV, TMX 파일 형식을 지원합니다.
- 동의어 세트 용어집: 각 행에 여러 언어로 예상되는 번역을 지정합니다. 동의어 세트 용어집은 CSV 파일 형식을 지원합니다.
단방향 용어집
Vertex AI Translation API는 탭으로 구분된 값 (TSV)과 쉼표로 구분된 값 (CSV)을 허용합니다. 이러한 파일 형식의 경우 각 행에는 탭 (\t) 또는 쉼표 (,)로 구분된 용어 쌍이 포함됩니다.
Vertex AI Translation API는 번역의 소스 및 타겟 용어 쌍을 제공하는 표준 XML 형식인 Translation Memory eXchange (TMX) 형식도 허용합니다. 지원되는 입력 파일은 TMX 버전 1.4를 기반으로 하는 형식입니다.
다음 예에서는 단방향 용어집의 TSV, CSV, TMX 파일 형식에 필요한 구조를 보여줍니다.
TSV 및 CSV
다음 이미지는 TSV 또는 CSV 파일의 두 열을 보여줍니다. 첫 번째 열에는 소스 언어 용어가 포함되고 두 번째 열에는 타겟 언어 용어가 포함됩니다.

용어집 파일을 만들 때 헤더 행을 정의할 수 있습니다. 용어집 요청을 통해 Vertex AI Translation API에서 파일을 사용할 수 있습니다.
TMX
다음 예에서는 TMX 파일의 필수 구조를 보여줍니다.
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE tmx SYSTEM "tmx14.dtd">
<tmx version="1.4">
<header segtype="sentence" o-tmf="UTF-8" adminlang="en" srclang="en" datatype="PlainText"/>
<body>
<tu>
<tuv xml:lang="en">
<seg>account</seg>
</tuv>
<tuv xml:lang="es">
<seg>cuenta</seg>
</tuv>
</tu>
<tu>
<tuv xml:lang="en">
<seg>directions</seg>
</tuv>
<tuv xml:lang="es">
<seg>indicaciones</seg>
</tuv>
</tu>
</body>
</tmx>
파일에 이 예에 표시되지 않은 XML 태그가 포함되어 있으면 Vertex AI Translation API는 해당 태그를 무시합니다.
Vertex AI Translation API에서 성공적으로 처리되도록 TMX 파일에 다음 요소를 포함하세요.
<header>:srclang속성을 사용하여 소스 언어를 식별합니다.<tu>: 동일한 출발어와 도착어를 가진<tuv>요소 쌍을 포함합니다. 이러한<tuv>요소는 다음을 준수합니다.- 각
<tuv>요소는xml:lang속성을 사용하여 포함된 텍스트의 언어를 지정합니다. ISO-639-1 코드를 사용하여 출발어와 도착어를 식별합니다. 지원되는 언어 및 해당 언어 코드 목록을 참고하세요. <tu>요소에<tuv>요소가 3개 이상 포함되어 있으면 Vertex AI Translation API는 출발어와 일치하는 첫 번째<tuv>요소와 도착어와 일치하는 첫 번째<tuv>요소만 처리합니다. 서비스는 나머지<tuv>요소를 무시합니다.<tu>요소에 일치하는<tuv>요소 쌍이 없으면 Vertex AI Translation API는 잘못된<tu>요소를 무시합니다.
- 각
<seg>: 일반화된 텍스트 문자열을 나타냅니다. Vertex AI Translation API는 파일을 처리하기 전에<seg>요소에서 마크업 태그를 제외합니다.<tuv>요소에<seg>요소가 2개 이상 포함되어 있으면 Vertex AI Translation API는 텍스트를 사이에 공백이 있는 단일 요소로 연결합니다.
단방향 용어집에서 용어집 용어를 식별한 후 스토리지 버킷에 파일을 업로드하고 용어집을 만들어 가져와 Vertex AI Translation API에서 사용할 수 있도록 합니다.
동의어 세트 용어집
Vertex AI Translation API는 CSV 형식을 사용하여 동의어 세트의 용어집 파일을 허용합니다. 동의어 세트를 정의하려면 각 행에 여러 언어의 용어가 나열되는 다중 열 CSV 파일을 만듭니다. 지원되는 언어 목록과 각 언어 코드를 참고하세요.
다음 이미지는 다중 열 CSV 파일의 예를 보여줍니다. 각 행은 용어집 용어를 나타내고 각 열은 용어의 다양한 언어 번역을 나타냅니다.
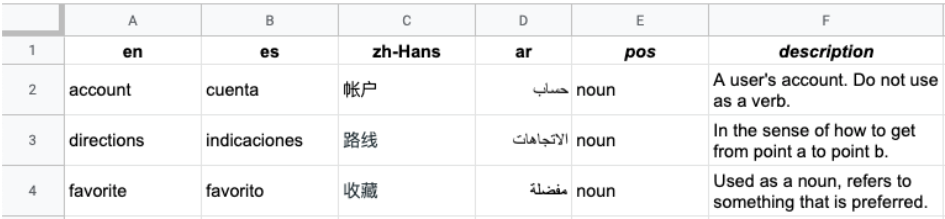
헤더는 파일의 첫 번째 행으로, 각 열의 언어를 식별합니다. 헤더 행은 ISO-639-1 또는 BCP-47 표준 언어 코드를 사용합니다. Vertex AI Translation API는 품사 (pos) 정보를 사용하지 않으며 특정 위치 값은 검증되지 않습니다.
각 후속 행에는 헤더에 지정된 언어의 동의어가 포함됩니다. 해당 용어가 모든 언어로 제공되지 않은 경우 열을 비워 둘 수 있습니다.
동의어 세트에서 용어집 용어를 식별한 후 파일을 스토리지 버킷에 업로드하고 용어집을 만들어 가져와 Vertex AI Translation API에서 사용할 수 있도록 합니다.
용어집 파일을 스토리지 버킷에 업로드
다음 단계에 따라 용어집 파일을 스토리지 버킷에 업로드합니다.
- 객체 스토리지를 위한 gdcloud CLI 구성
프로젝트 네임스페이스에 스토리지 버킷을 만듭니다.
Standard스토리지 클래스를 사용합니다.프로젝트 네임스페이스에
Bucket리소스를 배포하여 스토리지 버킷을 만들 수 있습니다.apiVersion: object.gdc.goog/v1 kind: Bucket metadata: name: glossary-bucket namespace: translation-glossary-project spec: description: bucket for translation glossary storageClass: Standard bucketPolicy: lockingPolicy: defaultObjectRetentionDays: 90Vertex AI Translation 서비스에서 사용하는 서비스 계정(
ai-translation-system-sa)에 버킷에 대한read권한을 부여합니다.다음 단계에 따라 맞춤 리소스를 사용하여 역할과 역할 바인딩을 만들 수 있습니다.
프로젝트 네임스페이스에
Role리소스를 배포하여 역할을 만듭니다.apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: ai-translation-glossary-reader namespace: translation-glossary-project rules: - apiGroups: - object.gdc.goog resources: - buckets verbs: - read-object프로젝트 네임스페이스에
RoleBinding리소스를 배포하여 역할 바인딩을 만듭니다.apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: ai-translation-glossary-reader-rolebinding namespace: translation-glossary-project roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: ai-translation-glossary-reader subjects: - kind: ServiceAccount name: ai-translation-system-sa namespace: ai-translation-system
만든 스토리지 버킷에 용어집 파일을 업로드합니다. 자세한 내용은 프로젝트에서 스토리지 객체 업로드 및 다운로드를 참고하세요.
용어집 만들기
CreateGlossary 메서드는 용어집을 만들고 용어집을 생성하는 장기 실행 작업의 식별자를 반환합니다.
용어집을 만들려면 요청 데이터를 사용하기 전에 다음을 바꿉니다.
ENDPOINT: 조직에서 사용하는 Vertex AI Translation 엔드포인트입니다. 자세한 내용은 서비스 상태 및 엔드포인트 보기를 참고하세요.PROJECT_ID: 프로젝트 ID입니다.GLOSSARY_ID: 용어집 ID(리소스 이름)입니다.BUCKET_NAME: 용어집 파일이 있는 스토리지 버킷의 이름입니다.GLOSSARY_FILENAME: 스토리지 버킷에 있는 용어집 파일의 이름입니다.
다음은 용어집을 만들기 위한 HTTP 요청의 구문입니다.
POST https://ENDPOINT/v3/projects/PROJECT_ID/glossaries
생성한 용어집 파일에 따라 다음 옵션 중 하나를 선택하여 용어집을 만듭니다.
단방향
단방향 용어집을 만들려면 출발어(source_language_code)와 도착어 (target_language_code)가 포함된 언어 조합 (language_pair)을 지정합니다.
단방향 용어집을 만들려면 다음 단계를 따르세요.
다음 요청 본문을
request.json이라는 JSON 파일에 저장합니다.{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID, "language_pair": { "source_language_code": "SOURCE_LANGUAGE", "target_language_code": "TARGET_LANGUAGE" }, "{"input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }다음을 바꿉니다.
요청합니다. 다음 예에서는 REST API 메서드와 명령줄을 사용하지만 클라이언트 라이브러리를 사용하여 단방향 용어집을 만들 수도 있습니다.
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
TOKEN을 획득한 인증 토큰으로 바꿉니다.
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest
-Method POST
-Headers $headers
-ContentType: "application/json; charset=utf-8"
-InFile request.json
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
TOKEN을 획득한 인증 토큰으로 바꿉니다.
다음과 비슷한 JSON 응답이 표시되어야 합니다.
{
"name": "projects/PROJECT_ID/operations/operation-id",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
동의어 세트
동의어 세트 용어집을 만들려면 용어집의 언어 코드(language_codes)를 사용하여 언어 세트 (language_codes_set)를 지정합니다.
동의어 세트 용어집을 만들려면 다음 단계를 따르세요.
다음 요청 본문을
request.json이라는 JSON 파일에 저장합니다.{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID", "language_codes_set": { "language_codes": ["LANGUAGE_CODE_1", "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ... ] }, "input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }LANGUAGE_CODE을 용어집의 언어 코드로 바꿉니다. 지원되는 언어 및 해당 언어 코드 목록을 참고하세요.요청을 합니다.
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
TOKEN을 획득한 인증 토큰으로 바꿉니다.
다음과 비슷한 JSON 응답이 표시되어야 합니다.
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID,
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
TOKEN을 획득한 인증 토큰으로 바꿉니다.
다음과 비슷한 JSON 응답이 표시되어야 합니다.
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Python
만든 Python 스크립트에 다음 코드를 추가합니다.
from google.cloud import translate_v3 as translate def create_glossary( project_id=PROJECT_ID, input_uri= "s3://BUCKET_NAME/GLOSSARY_FILENAME", glossary_id=GLOSSARY_ID, timeout=180, ): client = translate.TranslationServiceClient() # Supported language codes source_lang_code = "LANGUAGE_CODE_1" target_lang_code = "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ...Python 스크립트를 저장합니다.
Python 스크립트를 실행합니다.
python SCRIPT_NAME
SCRIPT_NAME을 Python 스크립트에 지정한 이름(예: glossary.py)으로 바꿉니다.
create_glossary 메서드에 대한 자세한 내용은 Python 클라이언트 라이브러리를 참고하세요.
용어집 파일의 크기에 따라 용어집을 만드는 데 일반적으로 10분 미만이 걸립니다. 이 작업의 상태를 검색하여 완료 시점을 알 수 있습니다.
용어집 가져오기
GetGlossary 메서드는 저장된 용어를 반환합니다. 용어가 없으면 출력에서 NOT_FOUND 값을 반환합니다. GetGlossary 메서드를 호출하려면 프로젝트 ID와 용어집 ID를 지정합니다. CreateGlossary 및 ListGlossaries 메서드는 모두 용어집 ID를 반환합니다.
예를 들어 다음 요청은 프로젝트의 특정 용어집에 관한 정보를 반환합니다.
curl
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
TOKEN을 획득한 인증 토큰으로 바꿉니다.
Python
from google.cloud import translate_v3 as translate
def get_glossary(project_id="PROJECT_ID", glossary_id="GLOSSARY_ID"):
"""Get a particular glossary based on the glossary ID."""
client = translate.TranslationServiceClient()
name = client.glossary_path(project_id, glossary_id)
response = client.get_glossary(name=name)
print(u"Glossary name: {}".format(response.name))
print(u"Input URI: {}".format(response.input_config.s3_source.input_uri))
용어집 나열
ListGlossaries 메서드는 프로젝트의 용어집 ID 목록을 반환합니다. 용어가 없는 경우 출력은 NOT_FOUND 값을 반환합니다. ListGlossaries 메서드를 호출하려면 프로젝트 ID와 Vertex AI Translation 엔드포인트를 지정합니다.
예를 들어 다음 요청은 프로젝트의 용어집 ID 목록을 반환합니다.
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries?page_size=10"
TOKEN을 획득한 인증 토큰으로 바꿉니다.
용어집 삭제
DeleteGlossary 메서드는 용어집을 삭제합니다. 용어가 존재하지 않으면 출력에서 NOT_FOUND 값을 반환합니다. DeleteGlossary 메서드를 호출하려면 프로젝트 ID, 용어집 ID, Vertex AI Translation 엔드포인트를 지정합니다.
CreateGlossary 및 ListGlossaries 메서드는 모두 용어집 ID를 반환합니다.
예를 들어 다음 요청은 프로젝트에서 용어집을 삭제합니다.
curl -X DELETE \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
TOKEN을 획득한 인증 토큰으로 바꿉니다.