Trino (früher Presto) ist eine verteilte SQL-Abfrage-Engine für die Abfrage großer Datasets, die über eine oder mehrere heterogene Datenquellen verteilt sind. Trino kann Hive, MySQL, Kafka und andere Datenquellen über Connectors abfragen. In dieser Anleitung wird Folgendes erläutert:
- Trino-Dienst in einem Dataproc-Cluster installieren
- Öffentliche Daten über einen Trino-Client abfragen, der auf Ihrem lokalen Computer installiert ist und mit einem Trino-Dienst im Cluster kommuniziert
- Abfragen mit einer Java-Anwendung ausführen, die über den Java-JDBC-Treiber für Trino mit dem Trino-Dienst im Cluster kommuniziert
Ziele
- Daten aus BigQuery extrahieren
- Daten in Cloud Storage als CSV-Dateien laden
- Daten transformieren:
- Daten als externe Hive-Tabelle zur Verfügung stellen, damit sie von Trino abgefragt werden können
- Daten aus dem CSV-Format in das Parquet-Format konvertieren, um die Abfrage zu beschleunigen
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweise
Erstellen Sie ein Google Cloud -Projekt und einen Cloud Storage-Bucket für die in dieser Anleitung verwendeten Daten, sofern noch nicht geschehen. 1. Projekt einrichten- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init - In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
- Umgebungsvariablen festlegen:
- PROJECT: Ihre Projekt-ID
- BUCKET_NAME: Der Name des Cloud Storage-Buckets, den Sie unter Hinweise erstellt haben
- REGION: Die Region, in der der Cluster für diese Anleitung erstellt wird, z. B. "us-west1"
- WORKERS: Für diese Anleitung werden drei bis fünf Worker empfohlen.
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- Führen Sie die Google Cloud CLI auf Ihrem lokalen Computer aus, um den Cluster zu erstellen.
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway - Führen Sie den folgenden Befehl auf Ihrem lokalen Computer aus, um die Taxidaten aus BigQuery als CSV-Dateien ohne Header in den Cloud Storage-Bucket zu importieren, den Sie unter Vorbereitung erstellt haben.
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - Erstellen Sie externe Hive-Tabellen, die von den CSV- und Parquet-Dateien im Cloud Storage-Bucket unterstützt werden.
- Erstellen Sie die externe Hive-Tabelle
chicago_taxi_trips_csv.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - Prüfen Sie die Erstellung der externen Hive-Tabelle.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - Erstellen Sie eine weitere externe Hive-Tabelle
chicago_taxi_trips_parquetmit denselben Spalten, aber mit Daten im Parquet-Format, um die Abfrageleistung zu verbessern.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - Laden Sie die Daten aus der Hive-CSV-Tabelle in die Hive Parquet-Tabelle.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - Prüfen Sie, ob die Daten korrekt geladen wurden.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- Erstellen Sie die externe Hive-Tabelle
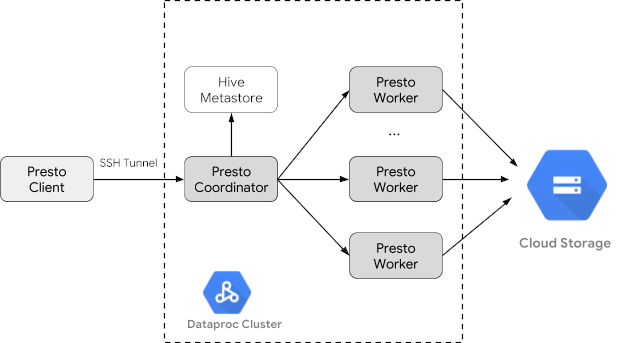
- Führen Sie den folgenden Befehl auf Ihrem lokalen Computer aus, um eine SSH-Verbindung zum Masterknoten des Clusters herzustellen. Das lokale Terminal reagiert während der Ausführung des Befehls nicht mehr.
gcloud compute ssh trino-cluster-m
- Führen Sie im SSH-Terminalfenster auf dem Masterknoten des Clusters die Trino-Befehlszeile aus, die eine Verbindung zum Trino-Server herstellt, der auf dem Masterknoten ausgeführt wird.
trino --catalog hive --schema default
- Prüfen Sie an der Eingabeaufforderung
trino:default, ob Trino die Hive-Tabellen finden kann.show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- Führen Sie Abfragen an der Eingabeaufforderung
trino:defaultaus und vergleichen Sie die Leistung von Parquet-Datenabfragen mit CSV-Datenabfragen.- Parquet-Datenabfrage
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - CSV-Datenabfrage
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Parquet-Datenabfrage
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- So löschen Sie den Cluster:
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION} - So löschen Sie den Cloud Storage-Bucket, den Sie unter Hinweise erstellt haben, einschließlich der im Bucket gespeicherten Datendateien:
gcloud storage rm gs://${BUCKET_NAME} --recursive
Dataproc-Cluster erstellen
Erstellen Sie einen Dataproc-Cluster mit dem Flag optional-components (verfügbar ab Image-Version 2.1), um die optionale Komponente "Trino" auf dem Cluster zu installieren, und mit dem Flag enable-component-gateway, um Component Gateway zu aktivieren, damit Sie über die Google Cloud -Konsole auf die Trino-Web-UI zugreifen können.
Daten vorbereiten
Exportieren Sie das bigquery-public-data-Dataset chicago_taxi_trips als CSV-Dateien in Cloud Storage und erstellen Sie dann eine externe Hive-Tabelle, um auf die Daten zu verweisen.
Abfragen ausführen
Sie können Abfragen lokal über die Trino-Befehlszeile oder über eine Anwendung ausführen.
Trino-Befehlszeilenabfragen
In diesem Abschnitt wird gezeigt, wie Sie das Hive Parquet-Taxi-Dataset mithilfe der Trino-Befehlszeile abfragen.
Java-Anwendungsabfragen
So führen Sie Abfragen mit einer Java-Anwendung über den Java-JDBC-Treiber für Trino aus:
1. Laden Sie den Java-JDBC-Treiber für Trino herunter.
1. Fügen Sie eine trino-jdbc-Abhängigkeit in die Maven-pom.xml ein.
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}Logging und Monitoring
Logging
Die Trino-Logs befinden sich auf den Master- und Worker-Knoten des Clusters unter /var/log/trino/.
Web-UI
Unter Component Gateway-URLs ansehen und auf diese zugreifen erfahren Sie, wie Sie die auf dem Masterknoten des Clusters ausgeführte Trino-Web-UI in Ihrem lokalen Browser öffnen.
Monitoring
Trino stellt Informationen zur Clusterlaufzeit über Laufzeittabellen bereit.
Führen Sie in einer Trino-Sitzung an der Eingabeaufforderung trino:default die folgende Abfrage aus, um die Daten der Laufzeittabelle anzuzeigen:
select * FROM system.runtime.nodes;
Bereinigen
Nachdem Sie die Anleitung abgeschlossen haben, können Sie die erstellten Ressourcen bereinigen, damit sie keine Kontingente mehr nutzen und keine Gebühren mehr anfallen. In den folgenden Abschnitten erfahren Sie, wie Sie diese Ressourcen löschen oder deaktivieren.
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten durch Löschen des für die Anleitung erstellten Projekts.
So löschen Sie das Projekt: