BigQuery 中的 Apache Iceberg BigLake 表
适用于 Apache Iceberg 的 BigQuery BigLake 表(以下称为“BigQuery 中的 BigLake Iceberg 表”)为在 Google Cloud上构建开放格式湖仓一体提供了基础。BigQuery 中的 BigLake Iceberg 表提供与标准 BigQuery 表相同的全托管式体验,但将数据存储在客户拥有的存储桶中。BigQuery 中的 BigLake Iceberg 表支持开放式 Iceberg 表格式,可在单个数据副本上与开源和第三方计算引擎实现更好的互操作性。
BigQuery 中的 Apache Iceberg BigLake 表与 Apache Iceberg 外部表不同。BigQuery 中的 Apache Iceberg BigLake 表是全托管式表,可直接在 BigQuery 中进行修改,而 Apache Iceberg 外部表由客户管理,并提供 BigQuery 的只读权限。
BigQuery 中的 BigLake Iceberg 表支持以下功能:
- 使用 GoogleSQL 数据操纵语言 (DML) 进行表变更。
- 通过 Spark、Dataflow 和其他引擎等 BigLake 连接器使用 Storage Write API 进行统一批处理和高吞吐量流式处理。
- 在每次表格变更时执行 Iceberg V2 快照导出和自动刷新,以便使用开源和第三方查询引擎直接查询。
- 架构演变:您可以添加、删除和重命名列,以满足您的需求。借助此功能,您还可以更改现有列的数据类型和列模式。如需了解详情,请参阅类型转换规则。
- 自动存储优化,包括自适应文件大小调整、自动聚簇、垃圾回收和元数据优化。
- 在 BigQuery 中使用时间旅行访问历史数据。
- 列级安全性和数据遮盖。
- 多语句事务(预览版)。
架构
BigQuery 中的 BigLake Iceberg 表可为位于您自己的云存储桶中的表提供 BigQuery 资源管理的便利。您可以在这些表上使用 BigQuery 和开源计算引擎,而无需将数据从您控制的存储桶中移出。您必须先配置 Cloud Storage 存储桶,然后才能开始在 BigQuery 中使用 BigLake Iceberg 表。
BigQuery 中的 BigLake Iceberg 表使用 BigLake metastore 作为所有 Iceberg 数据的统一运行时 metastore。BigLake metastore 提供了一个可信来源,用于管理来自多个引擎的元数据,并支持引擎互操作性。
下图简要展示了托管式表架构:
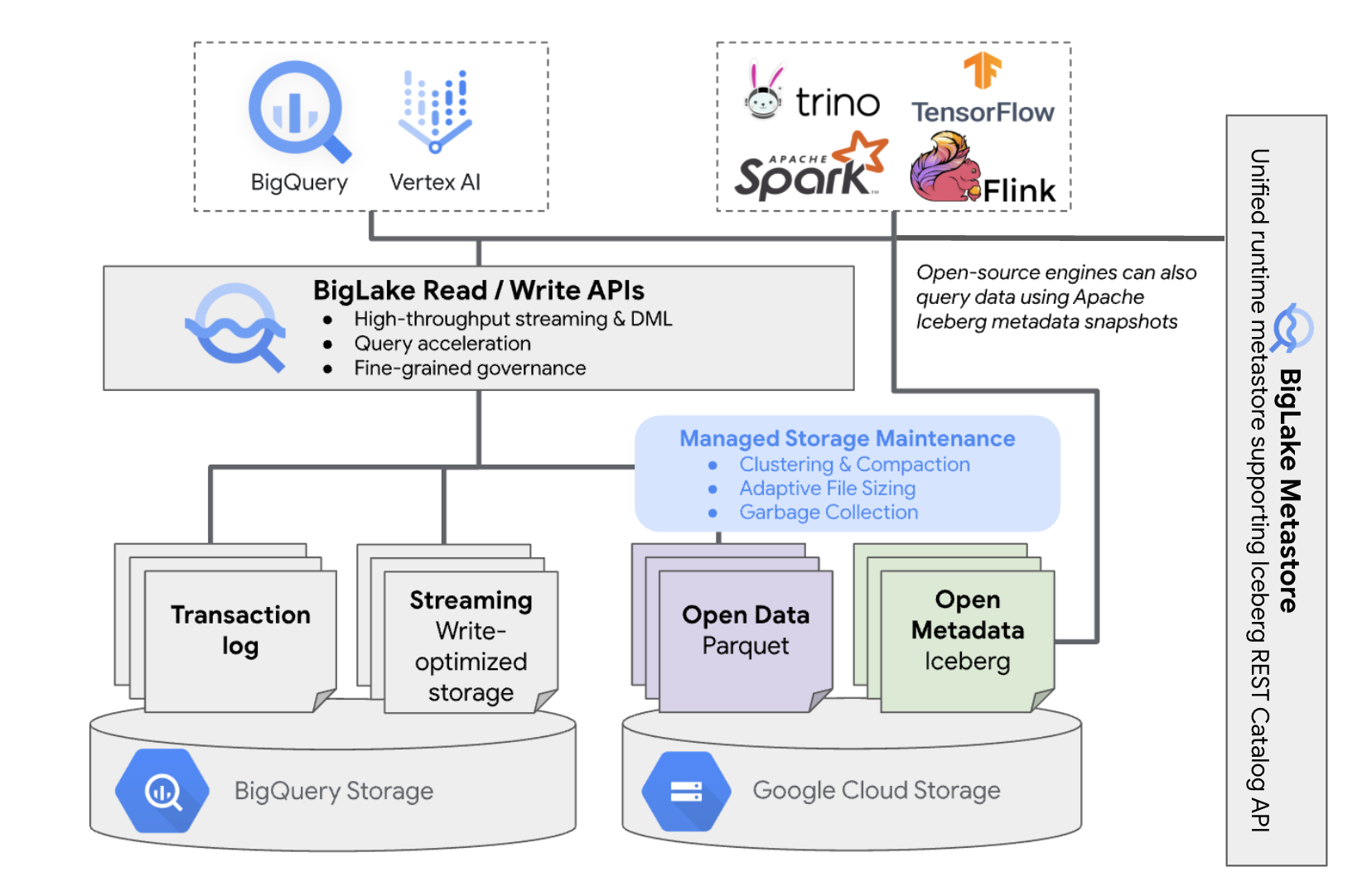
此表管理会对存储桶产生以下影响:
- BigQuery 会在存储桶中创建新的数据文件,以响应写入请求和后台存储优化(例如 DML 语句和流式处理)。
- 当您在 BigQuery 中删除托管式表时,BigQuery 会在时间旅行期到期后在 Cloud Storage 中收集关联的数据文件。
在 BigQuery 中创建 BigLake Iceberg 表的过程与创建 BigQuery 表类似。由于 Iceberg 表以开放格式在 Cloud Storage 上存储数据,因此您必须执行以下操作:
- 使用
WITH CONNECTION指定 Cloud 资源连接,以便为 BigLake 访问 Cloud Storage 配置连接凭据。 - 使用
file_format = PARQUET语句将数据存储的文件格式指定为PARQUET。 - 使用
table_format = ICEBERG语句将开源元数据表格式指定为ICEBERG。
最佳做法
在 BigQuery 外部直接更改文件或向存储桶添加文件可能会导致数据丢失或不可恢复的错误。下表介绍了可能的场景:
| 操作 | 结果 | 预防措施 |
|---|---|---|
| 向 BigQuery 外部的存储桶添加新文件。 | 数据丢失:BigQuery 不会跟踪在 BigQuery 外部添加的新文件或对象。未跟踪的文件会由后台垃圾回收进程删除。 | 仅通过 BigQuery 添加数据。这可让 BigQuery 跟踪这些文件并防止它们被垃圾回收。 为防止意外添加和数据丢失,我们还建议您限制对 BigQuery 中包含 BigLake Iceberg 表的存储桶的外部工具写入权限。 |
| 在 BigQuery 中使用非空前缀创建一个新的 BigLake Iceberg 表。 | 数据丢失:BigQuery 不会跟踪现有数据,因此这些文件会被视为未跟踪,并由后台垃圾回收进程删除。 | 仅在 BigQuery 中使用空前缀创建新的 BigLake Iceberg 表。 |
| 修改或替换 BigQuery 数据文件中的 BigLake Iceberg 表。 | 数据丢失:在外部修改或替换时,表会无法通过一致性检查,并且变得不可读。对表进行的查询会失败。 您无法通过自助方式从这个时间点恢复。如需数据恢复方面的帮助,请与支持团队联系。 |
仅通过 BigQuery 修改数据。这可让 BigQuery 跟踪这些文件并防止它们被垃圾回收。 为防止意外添加和数据丢失,我们还建议您限制对 BigQuery 中包含 BigLake Iceberg 表的存储桶的外部工具写入权限。 |
| 在 BigQuery 中使用相同或重叠的 URI 创建两个 BigLake Iceberg 表。 | 数据丢失:BigQuery 不会桥接 BigQuery 中 BigLake Iceberg 表的相同 URI 实例。每个表的后台垃圾回收进程都会将相反表的文件视为未跟踪,并将其删除,从而导致数据丢失。 | 为 BigQuery 中的每个 BigLake Iceberg 表使用唯一的 URI。 |
Cloud Storage 存储桶配置最佳实践
Cloud Storage 存储桶的配置及其与 BigLake 的连接会直接影响 BigQuery 中 BigLake Iceberg 表的性能、费用、数据完整性、安全性和治理。以下最佳实践可帮助您完成此配置:
选择一个名称,明确表明该存储桶仅用于 BigQuery 中的 BigLake Iceberg 表。
选择与您的 BigQuery 数据集位于同一区域的单区域 Cloud Storage 存储桶。这种协调可以避免数据传输费用,从而提高性能并降低成本。
默认情况下,Cloud Storage 会将数据存储在标准存储类别中,以提供足够的性能。如需优化数据存储费用,您可以启用 Autoclass 来自动管理存储类别转换。Autoclass 从标准存储类别开始,并将未被访问的对象移至越来越冷的类别,以降低存储费用。再次读取对象时,系统会将其移回 Standard 类别。
启用统一存储桶级访问权限和禁止公开访问。
验证是否已向正确的用户和服务账号分配了所需的角色。
为防止 Cloud Storage 存储桶中的 Iceberg 数据意外删除或损坏,请限制贵组织中大多数用户的写入和删除权限。为此,您可以设置存储桶权限政策,并设置条件,以便拒绝所有用户(除了您指定的用户)的
PUT和DELETE请求。应用 Google 管理的或客户管理的加密密钥,以便对敏感数据提供额外保护。
启用审核日志记录,以实现运营透明度、问题排查和数据访问监控。
保留默认的软删除政策(保留 7 天)以防止意外删除。不过,如果您发现 Iceberg 数据已被删除,请与支持团队联系,而不是手动恢复对象,因为 BigQuery 元数据不会跟踪在 BigQuery 外部添加或修改的对象。
系统会自动启用自适应文件大小调整、自动聚类和垃圾回收功能,以帮助优化文件性能和成本。
请避免使用以下 Cloud Storage 功能,因为 BigQuery 不支持在 BigLake Iceberg 表中使用这些功能:
您可以通过使用以下命令创建存储桶来实现这些最佳实践:
gcloud storage buckets create gs://BUCKET_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --enable-autoclass \ --public-access-prevention \ --uniform-bucket-level-access
替换以下内容:
BUCKET_NAME:新存储桶的名称PROJECT_ID:您的项目的 IDLOCATION:新存储桶的位置
BigQuery 工作流中的 BigLake Iceberg 表
以下部分介绍了如何创建、加载、管理和查询托管式表。
准备工作
在 BigQuery 中创建和使用 BigLake Iceberg 表之前,请确保您已设置与存储桶的 Cloud 资源连接。您的连接需要具有对存储桶的写入权限,如以下所需角色部分中所述。 如需详细了解连接所需的角色和权限,请参阅管理连接。
所需的角色
如需获得让 BigQuery 管理项目中的表所需的权限,请让您的管理员为您授予以下 IAM 角色:
-
如需在 BigQuery 中创建 BigLake Iceberg 表,请执行以下操作:
-
针对项目的 BigQuery Data Owner (
roles/bigquery.dataOwner) -
针对项目的 BigQuery Connection Admin (
roles/bigquery.connectionAdmin)
-
针对项目的 BigQuery Data Owner (
-
如需在 BigQuery 中查询 BigLake Iceberg 表,请执行以下操作:
-
针对项目的 BigQuery Data Viewer (
roles/bigquery.dataViewer) -
针对项目的 BigQuery User (
roles/bigquery.user)
-
针对项目的 BigQuery Data Viewer (
-
向连接服务账号授予以下角色,以便其能够在 Cloud Storage 中读取和写入数据:
-
针对存储桶的 Storage Object User (
roles/storage.objectUser) -
针对存储桶的 Storage Legacy Bucket Reader (
roles/storage.legacyBucketReader)
-
针对存储桶的 Storage Object User (
如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
这些预定义角色可提供让 BigQuery 管理项目中的表所需的权限。如需查看所需的确切权限,请展开所需权限部分:
所需权限
让 BigQuery 管理项目中的表需要以下权限:
-
针对您的项目的
bigquery.connections.delegate权限 -
针对您的项目的
bigquery.jobs.create权限 -
针对您的项目的
bigquery.readsessions.create权限 -
针对您的项目的
bigquery.tables.create权限 -
针对您的项目的
bigquery.tables.get权限 -
针对您的项目的
bigquery.tables.getData权限 -
针对存储桶的
storage.buckets.get权限 -
针对存储桶的
storage.objects.create权限 -
针对存储桶的
storage.objects.delete权限 -
针对存储桶的
storage.objects.get权限 -
针对存储桶的
storage.objects.list权限
在 BigQuery 中创建 BigLake Iceberg 表
如需在 BigQuery 中创建 BigLake Iceberg 表,请选择以下方法之一:
SQL
CREATE TABLE [PROJECT_ID.]DATASET_ID.TABLE_NAME ( COLUMN DATA_TYPE[, ...] ) CLUSTER BY CLUSTER_COLUMN_LIST WITH CONNECTION {CONNECTION_NAME | DEFAULT} OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'STORAGE_URI');
替换以下内容:
- PROJECT_ID:包含数据集的项目。如果未定义,该命令会假定为默认项目。
- DATASET_ID:现有数据集。
- TABLE_NAME:您要创建的表的名称。
- DATA_TYPE:列中包含的信息的数据类型。
- CLUSTER_COLUMN_LIST(可选):以英文逗号分隔的列表,最多包含四个列。它们必须是顶级非重复列。
CONNECTION_NAME:连接的名称。 例如
myproject.us.myconnection。如需使用默认连接,请指定
DEFAULT,而不是包含 PROJECT_ID.REGION.CONNECTION_ID 的连接字符串。STORAGE_URI:完全限定的 Cloud Storage URI。例如
gs://mybucket/table。
bq
bq --project_id=PROJECT_ID mk \ --table \ --file_format=PARQUET \ --table_format=ICEBERG \ --connection_id=CONNECTION_NAME \ --storage_uri=STORAGE_URI \ --schema=COLUMN_NAME:DATA_TYPE[, ...] \ --clustering_fields=CLUSTER_COLUMN_LIST \ DATASET_ID.MANAGED_TABLE_NAME
替换以下内容:
- PROJECT_ID:包含数据集的项目。如果未定义,该命令会假定为默认项目。
- CONNECTION_NAME:连接的名称。 例如
myproject.us.myconnection。 - STORAGE_URI:完全限定的 Cloud Storage URI。例如
gs://mybucket/table。 - COLUMN_NAME:列名称。
- DATA_TYPE:列中包含的信息的数据类型。
- CLUSTER_COLUMN_LIST(可选):以英文逗号分隔的列表,最多包含四个列。它们必须是顶级非重复列。
- DATASET_ID:现有数据集的 ID。
- MANAGED_TABLE_NAME:您要创建的表的名称。
API
使用定义的表资源调用 tables.insert 方法,如下所示:
{ "tableReference": { "tableId": "TABLE_NAME" }, "biglakeConfiguration": { "connectionId": "CONNECTION_NAME", "fileFormat": "PARQUET", "tableFormat": "ICEBERG", "storageUri": "STORAGE_URI" }, "schema": { "fields": [ { "name": "COLUMN_NAME", "type": "DATA_TYPE" } [, ...] ] } }
替换以下内容:
- TABLE_NAME:您要创建的表的名称。
- CONNECTION_NAME:连接的名称。 例如
myproject.us.myconnection。 - STORAGE_URI:完全限定的 Cloud Storage URI。通配符也受支持。 例如
gs://mybucket/table。 - COLUMN_NAME:列名称。
- DATA_TYPE:列中包含的信息的数据类型。
将数据导入 BigQuery 中的 BigLake Iceberg 表
以下部分介绍了如何将数据从各种表格式导入 BigQuery 中的 BigLake Iceberg 表。
从平面文件标准加载数据
BigQuery 中的 BigLake Iceberg 表使用 BigQuery 加载作业将外部文件加载到 BigQuery 中的 BigLake Iceberg 表中。如果您在 BigQuery 中已有 BigLake Iceberg 表,请按照 bq load CLI 指南或 LOAD SQL 指南加载外部数据。加载数据后,新的 Parquet 文件会写入 STORAGE_URI/data 文件夹。
如果使用上述说明时 BigQuery 中没有现有的 BigLake Iceberg 表,则改为创建 BigQuery 表。
如需查看将数据批量加载到托管式表的工具特定示例,请参阅以下内容:
SQL
LOAD DATA INTO MANAGED_TABLE_NAME FROM FILES ( uris=['STORAGE_URI'], format='FILE_FORMAT');
替换以下内容:
- MANAGED_TABLE_NAME:BigQuery 中现有 BigLake Iceberg 表的名称。
- STORAGE_URI:完全限定的 Cloud Storage URI 或以英文逗号分隔的 URI 列表。通配符也受支持。 例如
gs://mybucket/table。 - FILE_FORMAT:源表格式。如需了解支持的格式,请参阅
load_option_list的format行。
bq
bq load \ --source_format=FILE_FORMAT \ MANAGED_TABLE \ STORAGE_URI
替换以下内容:
- FILE_FORMAT:源表格式。如需了解支持的格式,请参阅
load_option_list的format行。 - MANAGED_TABLE_NAME:BigQuery 中现有 BigLake Iceberg 表的名称。
- STORAGE_URI:完全限定的 Cloud Storage URI 或以英文逗号分隔的 URI 列表。通配符也受支持。 例如
gs://mybucket/table。
从 Hive 分区文件标准加载数据
您可以使用标准 BigQuery 加载作业将 Hive 分区文件加载到 BigQuery 中的 BigLake Iceberg 表中。如需了解详情,请参阅加载外部分区数据。
从 Pub/Sub 加载流式数据
您可以使用 Pub/Sub BigQuery 订阅将流式数据加载到 BigQuery 中的 BigLake Iceberg 表中。
从 BigQuery 中的 BigLake Iceberg 表导出数据
以下部分介绍了如何将 BigQuery 中的 BigLake Iceberg 表中的数据导出为各种表格式。
将数据导出为平面格式
如需将 BigQuery 中的 BigLake Iceberg 表导出为平面格式,请使用 EXPORT DATA 语句并选择目标格式。如需了解详情,请参阅导出数据。
在 BigQuery 元数据快照中创建 BigLake Iceberg 表
如需在 BigQuery 元数据快照中创建 BigLake Iceberg 表,请按以下步骤操作:
使用
EXPORT TABLE METADATASQL 语句将元数据导出为 Iceberg V2 格式。可选:安排 Iceberg 元数据快照刷新。如需根据设定的时间间隔刷新 Iceberg 元数据快照,请使用预定查询。
可选:为您的项目启用元数据自动刷新功能,以便在每次表格变更时自动更新 Iceberg 表元数据快照。如需启用元数据自动刷新功能,请联系 bigquery-tables-for-apache-iceberg-help@google.com。每次刷新操作都会产生
EXPORT METADATA费用。
以下示例会使用 DDL 语句 EXPORT TABLE METADATA FROM mydataset.test 创建名为 My Scheduled Snapshot Refresh Query 的预定查询。DDL 语句每 24 小时运行一次。
bq query \ --use_legacy_sql=false \ --display_name='My Scheduled Snapshot Refresh Query' \ --schedule='every 24 hours' \ 'EXPORT TABLE METADATA FROM mydataset.test'
在 BigQuery 元数据快照中查看 BigLake Iceberg 表
在 BigQuery 元数据快照中刷新 BigLake Iceberg 表后,您可以在 BigQuery 中的 BigLake Iceberg 表最初创建的 Cloud Storage URI 中找到该快照。/data 文件夹包含 Parquet 文件数据分片,/metadata 文件夹包含 BigQuery 元数据快照中的 BigLake Iceberg 表。
SELECT table_name, REGEXP_EXTRACT(ddl, r"storage_uri\s*=\s*\"([^\"]+)\"") AS storage_uri FROM `mydataset`.INFORMATION_SCHEMA.TABLES;
请注意,mydataset 和 table_name 是实际数据集和表的占位项。
使用 Apache Spark 读取 BigQuery 中的 BigLake Iceberg 表
以下示例会将您的环境设置为搭配使用 Spark SQL 与 Apache Iceberg,然后执行查询以从 BigQuery 中的指定 BigLake Iceberg 表中提取数据。
spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-ICEBERG_VERSION_NUMBER \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.type=hadoop \ --conf spark.sql.catalog.CATALOG_NAME.warehouse='BUCKET_PATH' \ # Query the table SELECT * FROM CATALOG_NAME.FOLDER_NAME;
替换以下内容:
- ICEBERG_VERSION_NUMBER:Apache Spark Iceberg 运行时的当前版本。从 Spark 版本下载最新版本。
- CATALOG_NAME:用于在 BigQuery 中引用 BigLake Iceberg 表的目录。
- BUCKET_PATH:包含表文件的存储桶的路径。例如
gs://mybucket/。 - FOLDER_NAME:包含表文件的文件夹。例如
myfolder。
在 BigQuery 中修改 BigLake Iceberg 表
如需修改 BigQuery 中的 BigLake Iceberg 表,请按照修改表架构中所示的步骤操作。
使用多语句事务
如需访问 BigQuery 中 BigLake Iceberg 表的多语句事务,请填写注册表单。
价格
BigQuery 定价中的 BigLake Iceberg 表由存储空间、存储空间优化以及查询和作业组成。
存储
BigQuery 中的 BigLake Iceberg 表将所有数据存储在 Cloud Storage 中。您需要为所有存储的数据付费,包括历史表数据。您还可能需要支付 Cloud Storage 数据处理和转移费用。对于通过 BigQuery 或 BigQuery Storage API 处理的操作,可能会免除部分 Cloud Storage 操作费用。无需支付 BigQuery 特定的存储费用。如需了解详情,请参阅 Cloud Storage 价格。
存储优化
BigQuery 中的 BigLake Iceberg 表会执行自动表管理,包括压缩、聚簇、垃圾回收和 BigQuery 元数据生成/刷新,以优化查询性能并降低存储费用。BigLake 表管理所用的计算资源用量按数据计算单元 (DCU) 随时间变化来计费,以秒为增量。如需了解详情,请参阅 BigQuery 价格中的 BigLake Iceberg 表。
通过 BigQuery Storage Write API 进行流式传输时发生的数据导出操作包含在 Storage Write API 价格中,不会作为后台维护计费。如需了解详情,请参阅数据注入价格。
您可以在 INFORMATION_SCHEMA.JOBS 视图中查看存储优化和 EXPORT TABLE METADATA 用量。
查询和作业
与 BigQuery 表类似,如果您使用 BigQuery 按需价格,则需要为查询和读取的字节(每 TiB)付费;如果您使用 BigQuery 容量计算价格,则需要为槽使用量(每个槽每小时)付费。
BigQuery 价格也适用于 BigQuery Storage Read API 和 BigQuery Storage Write API。
加载和导出操作(例如 EXPORT METADATA)使用企业版随用随付型槽。这与 BigQuery 表不同,后者不会针对这些操作计费。如果提供了具有企业版或企业 Plus 版槽的 PIPELINE 预留,则加载和导出操作会优先改为使用这些预留槽。
限制
BigQuery 中的 BigLake Iceberg 表具有以下限制:
- BigQuery 中的 BigLake Iceberg 表不支持重命名操作或
ALTER TABLE RENAME TO语句。 - BigQuery 中的 BigLake Iceberg 表不支持表副本或
CREATE TABLE COPY语句。 - BigQuery 中的 BigLake Iceberg 表不支持表克隆或
CREATE TABLE CLONE语句。 - BigQuery 中的 BigLake Iceberg 表不支持表快照或
CREATE SNAPSHOT TABLE语句。 - BigQuery 中的 BigLake Iceberg 表不支持以下表架构:
- BigQuery 中的 BigLake Iceberg 表不支持以下架构演变场景:
NUMERIC到FLOAT类型强制转换INT到FLOAT类型强制转换- 使用 SQL DDL 语句向现有
RECORD列添加新的嵌套字段
- 通过控制台或 API 查询时,BigQuery 中的 BigLake Iceberg 表会显示 0 字节的存储大小。
- BigQuery 中的 BigLake Iceberg 表不支持具体化视图。
- BigQuery 中的 BigLake Iceberg 表不支持授权视图,但支持列级访问权限控制。
- BigQuery 中的 BigLake Iceberg 表不支持变更数据捕获 (CDC) 更新。
- BigQuery 中的 BigLake Iceberg 表不支持托管式灾难恢复
- BigQuery 中的 BigLake Iceberg 表不支持分区。请考虑使用聚簇作为替代方案。
- BigQuery 中的 BigLake Iceberg 表不支持行级安全性。
- BigQuery 中的 BigLake Iceberg 表不支持故障安全窗口。
- BigQuery 中的 BigLake Iceberg 表不支持提取作业。
INFORMATION_SCHEMA.TABLE_STORAGE视图不包含 BigQuery 中的 BigLake Iceberg 表。- BigQuery 中的 BigLake Iceberg 表不支持用作查询结果目标位置。您可以改为使用
CREATE TABLE语句和AS query_statement参数来创建表作为查询结果目标。 CREATE OR REPLACE不支持将标准表替换为 BigQuery 中的 BigLake Iceberg 表,也不支持将 BigQuery 中的 BigLake Iceberg 表替换为标准表。- 批量加载和
LOAD DATA语句仅支持将数据附加到 BigQuery 中的现有 BigLake Iceberg 表。 - 批量加载和
LOAD DATA语句不支持架构更新。 TRUNCATE TABLE不支持 BigQuery 中的 BigLake Iceberg 表。可以使用两种替代方案:CREATE OR REPLACE TABLE,使用相同的表创建选项。DELETE FROM表WHEREtrue
APPENDS表值函数 (TVF) 不支持 BigQuery 中的 BigLake Iceberg 表。- Iceberg 元数据可能不包含在过去 90 分钟内通过 Storage Write API 流式传输到 BigQuery 的数据。
- 使用
tabledata.list的基于记录的分页访问不支持 BigQuery 中的 BigLake Iceberg 表。 - BigQuery 中的 BigLake Iceberg 表不支持关联的数据集。
- BigQuery 中每个 BigLake Iceberg 表仅会运行一个并发变更 DML 语句(
UPDATE、DELETE和MERGE)。其他变更 DML 语句将排入队列。