En este instructivo, usarás Striim para migrar Oracle® Database Enterprise Edition 18c o versiones posteriores desde un entorno local o un entorno de nube a una instancia de Cloud SQL para PostgreSQL en Google Cloud. En el instructivo, se usan tablas en el esquema de muestra de RR.HH. de Oracle.
Este instructivo es para arquitectos de bases de datos empresariales, ingenieros de bases de datos y propietarios de datos que planean usar Striim a fin de migrar o replicar bases de datos de Oracle a Cloud SQL para PostgreSQL. Debes tener conocimientos básicos de cómo usar Striim para compilar canalizaciones. También debes estar familiarizado con la IU web de Striim, los Conceptos clave de Striim y cómo crear una aplicación mediante el Diseñador de flujos de Striim.
Striim es socio de tecnología de migración de bases de datos de Google Cloud. Striim simplifica las migraciones en línea mediante una interfaz que permite arrastrar y soltar para configurar el movimiento continuo de datos entre bases de datos. En las migraciones a Google Cloud, Striim ofrece una plataforma de transmisión no intrusiva para extracción, transformación y carga (ETL) que es eficiente de implementar y sencilla de iterar. Para compilar la canalización de migración, usa el diseñador de flujo de Striim en este instructivo.
Si la migración de bases de datos no es algo con lo que estés familiarizado, consulta esta charla tecnológica de Cloud Next '19.
Arquitectura
La migración de bases de datos mediante Striim implica dos etapas de movimiento de datos secuenciales:
- Etapa 1: Una replicación inicial única de la base de datos de Oracle
- Etapa 2: La replicación continua de cada cambio confirmado en el sistema de la base de datos de origen mediante la captura de datos modificados (CDC)
En el siguiente diagrama, se ilustra una arquitectura básica de implementación:

Esta arquitectura implica ejecutar la aplicación de Striim en una instancia de Compute Engine. Se conecta a una base de datos de Oracle que se aloja de forma local o en la nube y escribe datos en una instancia de Cloud SQL para PostgreSQL en Google Cloud.
A fin de evitar problemas de red o conectividad entre las instancias de Striim y Cloud SQL, usa la misma red para ambas instancias. Puedes implementar Striim desde Google Cloud Marketplace en una instancia de Compute Engine o, si necesitas alta disponibilidad, puedes implementar Striim como un clúster
Para este instructivo, implementa desde Cloud Marketplace.
La ventaja de implementar Striim desde Cloud Marketplace es que te permite conectarte a varias bases de datos y fuentes de datos mediante sus adaptadores integrados. Puedes conectar los adaptadores mediante el diseñador deflujos, la interfaz interactiva de arrastrar y soltar de Striim para crear un grafo acíclico. Este grafo también se conoce como canalización de Striim o una aplicación de Striim.
El caso de uso de migración de este instructivo usa tres adaptadores de Striim:
- Lector de bases de datos: Lee datos de la base de datos de origen de Oracle durante la etapa de carga inicial.
- Lector de Oracle: Lee datos mediante LogMiner de la base de datos de origen de Oracle durante la etapa de replicación de datos continua.
- Escritor de base de datos: Escribe datos en la base de datos de Cloud SQL para PostgreSQL durante la carga inicial y durante la replicación de datos continua.
Objetivos
Preparar tu base de datos de Oracle como base de datos de origen para la migración o la replicación.
Preparar una base de datos de Cloud SQL para PostgreSQL como la base de datos de destino para la migración o replicación.
Cumplir con los requisitos para instalar y ejecutar Striim.
Convertir el esquema de la base de datos de Oracle en el esquema correspondiente en PostgreSQL.
Realizar la carga inicial de tu base de datos de Oracle a Cloud SQL para PostgreSQL.
Configurar la replicación continua desde tu base de datos de Oracle a Cloud SQL para PostgreSQL.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
La solución Striim en Cloud Marketplace ofrece una licencia de prueba gratuita por tiempo limitado. Cuando vence la prueba, los cargos por el uso se facturan a tu cuenta de Google Cloud. También puedes obtener licencias de Striim directamente de Striim para una implementación local y en una máquina virtual (VM) de Compute Engine. También es posible que se generen costos asociados con la ejecución de una base de datos de Oracle fuera de Google Cloud.
Antes de comenzar
- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
En este instructivo, suponemos que ya tienes lo siguiente:
- Una base de datos de Oracle Enterprise Edition 18c o una versión posterior para Linux x86-64 que deseas migrar
- Compute Engine que ejecuta CentOS y tiene Striim instalado Puedes implementar Striim a través de la solución Google Cloud Marketplace.
Prepara la base de datos de Oracle
En las siguientes secciones, se analizan los cambios de configuración que puede necesitar para conectarte a tu base de datos de Oracle y migrarlos con Striim. Para obtener más información sobre la configuración, consulta Tarea de configuración básica de Oracle.
Elige la fuente para los CDC de Oracle
Si bien hay diferentes fuentes de los CDC de Oracle, en este instructivo se usa LogMiner. Puedes leer sobre las opciones en Fuentes alternativas de CDC de Oracle.
Prepara Oracle Database Enterprise Edition 18c (o versiones posteriores)
A fin de preparar la base de datos de Oracle, sigue las instrucciones en la página de documentación de Striim y sigue estos pasos:
- Habilita el
archivelogde Striim. - Habilita los datos de registros complementarios de Striim.
- Habilita el registro de claves primarias de Striim.
Crea un usuario de Oracle con privilegios de LogMiner para Striim.
Para ejecutar estos pasos, debes estar conectado a la base de datos del contenedor (CDB), sin importar si migras una CDB o una base de datos conectable (PDB). Recomendamos instalar y usar SQL*Plus para interactuar con la base de datos de Oracle.
Crea la tabla
quiescemarkerde StriimEl adaptador de lector de Oracle de Striim para los CDC necesita una tabla a fin de almacenar metadatos cuando desactiva una aplicación. Si usas LogMiner como fuente para los CDC (como en este instructivo), necesitas la tabla quiescemarker. Debes estar conectado a la CDB cuando sigas los pasos para crear la tabla.
Establece la conectividad de red entre tu base de datos de Oracle y la instancia de Striim.
De forma predeterminada, el objeto de escucha de Oracle está en el puerto
1521. Asegúrate de que la dirección IP de la instancia de Striim pueda conectarse al puerto del objeto de escucha de Oracle y que ninguna regla de firewall lo bloquee. El puerto en el que se configura el objeto de escucha de Oracle está en el archivo$ORACLE_HOME/network/admin/tnsnames.ora.Toma nota del número de cambio del sistema (SCN) de la base de datos de Oracle.
El SCN es una marca de tiempo interna que se usa para hacer referencia a los cambios realizados en una base de datos.
En tu base de datos de Oracle, obtén el SCN más antiguo:
SELECT MIN(start_scn) FROM gv$transaction;Copia este número. Lo necesitarás más adelante en los pasos de canalización de replicación continua.
Prepara la instancia de Striim
Para obtener información sobre los sistemas operativos compatibles con Striim, consulta los requisitos del sistema. Para usar el lector de Oracle con LogMiner, agrega el controlador JDBC de Oracle a la ruta de clase de Java en tu instancia de Striim. Realiza los siguientes pasos en cada servidor de Striim que ejecute un adaptador de lector de Oracle:
- Accede a tu cuenta de Oracle y, luego, descarga el archivo
ojdbc8.jaren tu máquina local.- Si no tienes una cuenta de Oracle, crea una.
Haz clic en el vínculo Descargar para el archivo
ojdbc8.jar.- Haz clic en He revisado y acepto el contrato de licencia de Oracle para descargar el archivo si aceptas los términos de la licencia.
En Cloud Shell, crea un bucket de Cloud Storage y sube el archivo
.jara él:gsutil mb -b on -l REGION gs://BUCKET_NAME gsutil cp PATH/ojdbc8.jar gs://BUCKET_NAMEReemplaza lo siguiente:
- REGION: Es la región en la que deseas crear el bucket de Cloud Storage.
- BUCKET_NAME: Es el nombre del bucket de Cloud Storage en el que deseas almacenar el archivo
ojdbc8.jar. - PATH: Es la ruta en la que descargaste el archivo
ojdbc8.jar.
Después de guardar el archivo en tu máquina local, te recomendamos que subas el archivo
.jara un bucket de Cloud Storage para que puedas descargarlo en cualquier instancia.Abre una sesión SSH con tu instancia de Striim y, luego, descarga el archivo
.jaren tu instancia de Striim y colócalo en el directorio/opt/striim/lib:sudo su - striim gsutil cp gs://BUCKET_NAME/ojdbc8.jar /opt/striim/libVerifica que el archivo
ojdbc8.jartenga los permisos de archivo correctos:sudo ls -l /opt/striim/lib/ojdbc8.jarEl resultado debería ser el siguiente:
-rwxrwx--- striim striimSi el archivo
.jarno tiene los permisos anteriores, configura los permisos correctos (opcional):sudo chmod 770 /opt/striim/lib/ojdbc8.jar sudo chown striim /opt/striim/lib/ojdbc8.jar sudo chgrp striim /opt/striim/lib/ojdbc8.jarDetén y reinicia Striim.
Después de realizar cualquier cambio de configuración (como los cambios de permiso anteriores), debes reiniciar Striim.
Si usas la distribución de CentOS 7 de Linux, se detiene Striim:
sudo systemctl stop striim-node sudo systemctl stop striim-dbmsSi usas la distribución de Linux de CentOS 7, se inicia Striim:
sudo systemctl start striim-dbms sudo systemctl start striim-node
Si deseas obtener más información para detener y reiniciar Striim para un sistema operativo diferente, consulta Inicia y detén Striim.
Instala el cliente psql en la instancia de Striim.
Usa este cliente para conectarte a la instancia de Cloud SQL y crear esquemas más adelante en este instructivo.
Prepara el esquema de Cloud SQL para PostgreSQL
Cuando copias o réplicas de forma continua datos tabulares de una base de datos a otra, en general, Striim requiere que la base de datos de destino contenga tablas correspondientes con el esquema correcto. Google Cloud no tiene una utilidad para preparar el esquema, pero puedes usar la utilidad de conversión de esquemas de Striim o una utilidad de código abierto como ora2pg.
Conserva las claves externas durante la carga inicial
Durante la fase de carga inicial, presta atención al tratamiento de las claves externas. Las claves externas establecen la relación entre las tablas en una base de datos relacional. La creación o la inserción desordenada de una clave externa en la base de datos de destino podría destruir la relación entre las dos tablas. Si la integridad entre las dos bases de datos se ve comprometida, se pueden generar errores. Por lo tanto, es importante enviar todas las declaraciones de claves externas en un archivo separado durante la exportación del esquema más adelante en esta sección.
Durante la replicación continua en las canalizaciones de los CDC, los eventos de la base de datos de origen se propagan a la base de datos de destino en el orden en que ocurren. Si mantienes correctamente las claves externas en tu fuente, las operaciones de clave externa se replican de la fuente a la base de datos de destino en el mismo orden.
Por el contrario, la canalización de carga inicial carga de forma predeterminada tus tablas en orden alfabético. Si no inhabilitas las claves externas antes de la carga inicial, se producirán errores de incumplimiento de clave externa. Para replicar datos durante la carga inicial desde las tablas de la base de datos de origen hasta las tablas de destino en Cloud SQL para PostgreSQL, debes inhabilitar las restricciones de la clave externa en las tablas. De lo contrario, es posible que se infrinjan las restricciones durante el proceso de replicación.
Desde junio de 2021, Cloud SQL para PostgreSQL no admite opciones de configuración a fin de inhabilitar restricciones de claves externas.
Para controlar las restricciones de la clave externa, sigue estos pasos:
- Envía todas las declaraciones de claves externas a un archivo separado durante la exportación del esquema.
- Crea esquemas de tablas en la base de datos de Cloud SQL para PostgreSQL sin las restricciones de claves externas.
- Completa la replicación de datos inicial.
- Aplica las restricciones de clave externa en las tablas.
- Crea la canalización de replicación continua.
En este instructivo, se ofrecen dos opciones para la conversión de esquema, que se describen en las siguientes secciones:
- La utilidad de conversión del esquema de Striim (recomendado)
- El convertidor de esquemas de bases de datos de Oracle a PostgreSQL (Ora2Pg)
Convierte el esquema con la utilidad de conversión de esquema de Striim
Usa la utilidad de conversión de esquemas de Striim a fin de preparar Cloud SQL para PostgreSQL a fin de integrar datos al esquema de destino y crear tablas que reflejen la base de datos de Oracle de origen.
La herramienta de conversión de esquemas de Striim convierte los siguientes objetos de origen en objetos de destino equivalentes:
- Tablas
- Claves primarias
- Tipos de datos
- Restricciones únicas
- Limitaciones
NOT NULL - Claves externas
Con la utilidad de conversión de esquemas de Striim, puedes analizar la base de datos fuente y generar secuencias de comandos DDL para crear esquemas equivalentes en la base de datos de destino.
Te recomendamos que crees de forma manual el esquema en la base de datos de destino mediante las secuencias de comandos de DDL generadas. Es más fácil seleccionar un subconjunto de tus tablas, exportar el esquema y, luego, importarlo a tu base de datos de destino de Cloud SQL para PostgreSQL.
En el siguiente ejemplo, se muestra cómo preparar tu base de datos de destino de Cloud SQL para PostgreSQL para la carga inicial mediante la importación de tu esquema con la utilidad de conversión de esquema de Striim:
Abre una conexión SSH a tu instancia de Striim.
Ve al directorio
/opt/striim:cd /opt/striimEnumera todos los argumentos:
bin/schemaConversionUtility.sh --helpEjecuta la utilidad de conversión del esquema e incluye las marcas adecuadas para tu caso de uso:
bin/schemaConversionUtility.sh \ -s=oracle \ -d=SOURCE_DATABASE_CONNECTION_URL \ -u=SOURCE_DATABASE_USERNAME \ -p=SOURCE_DATABASE_PASSWORD \ -b=SOURCE_TABLES_TO_CONVERT \ -t=postgres \ -f=falseReemplaza lo siguiente:
- SOURCE_DATABASE_CONNECTION_URL: Es la URL de conexión para la base de datos de Oracle, por ejemplo,
"jdbc:oracle:thin:@12.123.123.12:1521/APPSPDB.WORLD"o"jdbc:oracle:thin:@12.123.123.12:1521:XE" - SOURCE_DATABASE_USERNAME: Es el nombre de usuario de Oracle que se usará para conectarse a la base de datos de Oracle.
- SOURCE_DATABASE_PASSWORD: Es la contraseña de Oracle que se usará para conectarse a la base de datos de Oracle.
- SOURCE_TABLES_TO_CONVERT: Son los nombres de tabla de la base de datos de origen que se usan para convertir esquemas.
Asegúrate de usar el argumento
-f=false. Este argumento exporta las declaraciones de claves externas a un archivo separado.La carpeta de salida puede contener algunos de los siguientes archivos o todos ellos. Para obtener más información sobre estos archivos, consulta la documentación de la utilidad de conversión de esquemas de Striim.
Nombre de archivo de salida Descripción converted_tables.sqlContiene todas las tablas convertidas que no requieren ninguna coerción converted_tables_with_striim_intelligence.sqlContiene todas las tablas convertidas que se convirtieron con algún tipo de coerción conversion_failed_tables.sqlContiene tablas en las que se intentó realizar la conversión, pero no se obtuvo una asignación converted_foreignkey.sqlContiene todas las declaraciones de restricciones de clave externa conversion_failed_foreignkey.sqlContiene todas las conversiones de claves externas con errores conversion_report.txtContiene un informe detallado de la conversión del esquema. En este instructivo, se usa el archivo
converted_tables.sqlpara crear tablas equivalentes en la base de datos de Cloud SQL para PostgreSQL sin ninguna restricción de clave externa. Después de la replicación inicial, debes usar el archivoconverted_foreignkey.sqlpara aplicar las restricciones de la clave externa.- SOURCE_DATABASE_CONNECTION_URL: Es la URL de conexión para la base de datos de Oracle, por ejemplo,
Convierte el esquema con Ora2Pg
Otra utilidad para convertir esquemas de tablas de Oracle en esquemas equivalentes de PostgreSQL es la utilidad Ora2Pg. Puedes instalar esta utilidad en una VM de Google Cloud independiente.
La utilidad de Ora2Pg convierte el esquema de Oracle y exporta las declaraciones DDL que se requieren para crear tablas equivalentes en la base de datos de PostgreSQL. Estas declaraciones DDL se exportan en un archivo de salida llamado output.sql.
Durante la exportación del esquema, debes exportar y guardar todas las declaraciones de clave externa en un archivo separado mediante la siguiente marca en el archivo de configuración de Ora2Pg:
FILE_PER_FKEYS 1
De forma predeterminada, las claves externas se exportan al archivo de salida principal (output.sql). Cuando habilitas la marca FILE_PER_FKEYS (1), las claves externas se exportan a un archivo diferente llamado FKEYS_output.sql.
En este instructivo, se usa el archivo output.sql para crear tablas equivalentes en la base de datos de Cloud SQL para PostgreSQL sin ninguna restricción de clave externa.
Después de la replicación inicial, debes usar el archivo FKEY_output.sql para aplicar las restricciones de la clave externa.
Prepara la instancia de Cloud SQL para PostgreSQL
A fin de habilitar Striim para escribir datos en una instancia de Cloud SQL para PostgreSQL, debes crear una instancia de Cloud SQL. También debes crear las tablas de base de datos y el esquema en el que Striim escribe:
En Cloud Shell, crea una instancia de Cloud SQL para PostgreSQL. Te recomendamos configurar Cloud SQL para usar una dirección IP privada. Usa el parámetro
--networkpara configurar esta dirección:$INSTANCE_NAME=INSTANCE_NAME gcloud beta sql instances create INSTANCE_NAME \ --database-version=POSTGRES_12 \ --network=NETWORK \ --cpu=NUMBER_CPUS \ --memory=MEMORY_SIZE \ --region=REGIONReemplaza lo siguiente:
- INSTANCE_NAME: Es el nombre de la instancia.
- NETWORK: Es el nombre de la red de VPC que usas para esta instancia.
- NUMBER_CPUS: Es la cantidad de CPU virtuales en la instancia.
- MEMORY_SIZE: Es la cantidad de memoria para la instancia. Por ejemplo, 3,072 MiB o 9 GiB. Se supone que es GiB si no especificas la unidad.
- REGION: Es la región en la que creaste el bucket de Cloud Storage.
Crea un nombre de usuario y una contraseña en la instancia de Cloud SQL:
CLOUD_SQL_USERNAME=CLOUD_SQL_USERNAME gcloud sql users create $CLOUD_SQL_USERNAME \ --instance=$INSTANCE_NAME \ --password=CLOUD_SQL_PASSWORDReemplaza lo siguiente:
- CLOUD_SQL_USERNAME: Es un nombre de usuario para su instancia de Cloud SQL.
- CLOUD_SQL_PASSWORD: Es la contraseña del nombre de usuario de Cloud SQL.
A este usuario se le otorga la propiedad de las tablas de PostgreSQL. Striim también usa las credenciales de este usuario a fin de conectarse a la base de datos de Cloud SQL para PostgreSQL.
Los archivos de esquema que se exportan durante el paso de conversión del esquema pueden tener una declaración DDL que otorgue la propiedad a un usuario, como en el siguiente ejemplo:
CREATE SCHEMA <SCHEMA_NAME>; ALTER SCHEMA <SCHEMA_NAME> OWNER TO <USER>;
Es posible que debas reemplazar
SCHEMA_NAMEporCLOUD_SQL_SCHEMAyUSERpor elCLOUD_SQL_USERNAMEque creaste antes.Crea una base de datos de PostgreSQL
CLOUD_SQL_DATABASE_NAME=CLOUD_SQL_DATABASE_NAME gcloud sql databases create $CLOUD_SQL_DATABASE_NAME \ --instance=$INSTANCE_NAMEReemplaza lo siguiente:
- CLOUD_SQL_DATABASE_NAME: Es el nombre de la base de datos de PostgreSQL.
Configura la base de datos de Cloud SQL para PostgreSQL a fin de permitir el acceso desde la instancia de Striim Las opciones de conectividad dependen de si configuraste la instancia de Cloud SQL para usar una dirección IP pública o privada.
Si configuraste una dirección IP pública, agrega la dirección IP de la instancia de Striim como una dirección autorizada en la instancia de Cloud SQL. En la siguiente captura de pantalla, se muestra cómo hacerlo desde la consola de Google Cloud:
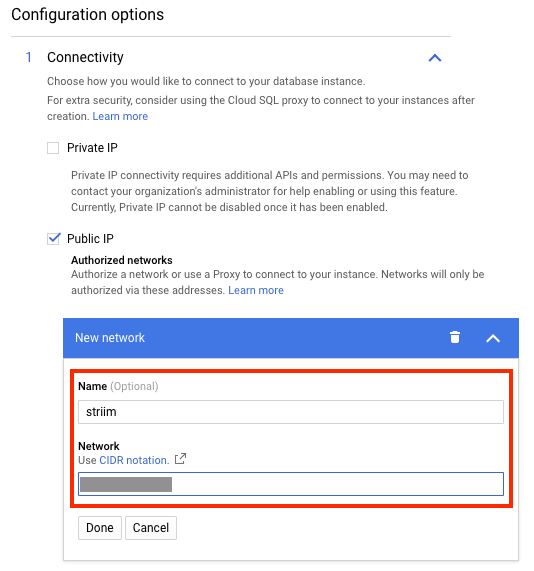
Si configuraste una dirección IP privada, las opciones de conectividad disponibles dependerán de si las instancias de Cloud SQL y Striim están disponibles en la misma red de VPC.
Si tu instancia de Striim está en la misma red de VPC que tu instancia de Cloud SQL, la instancia de Striim puede establecer una conexión con la instancia de Cloud SQL.
En la siguiente captura de pantalla, se muestra que la instancia de Cloud SQL está asociada a la red de VPC predeterminada. Si la instancia de Striim también se creó en la red de VPC predeterminada, puede conectarse de forma privada con la instancia de Cloud SQL.
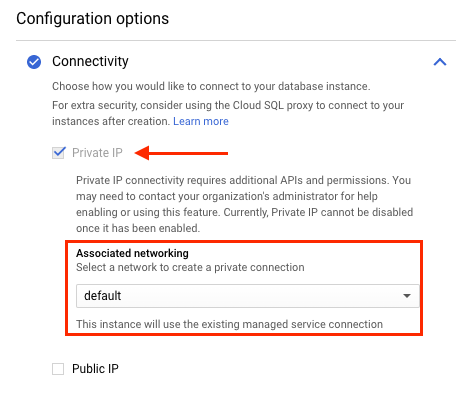
Si tu instancia de Striim está en una red de VPC diferente a la de tu instancia de Cloud SQL, configura el acceso privado a servicios en la red de VPC de tu instancia de Striim.
Crea esquemas de tablas sin restricciones de claves externas en la base de datos de Cloud SQL para PostgreSQL.
Para exportar
output.sqldurante el paso de conversión del esquema, usa el archivooutput.sqla fin de crear los esquemas.Para exportar
converted_tables.sqldurante el paso de conversión del esquema, usa el archivoconverted_tables.sqla fin de crear los esquemas.Puedes ejecutar cualquiera de las secuencias de comandos con cualquier cliente PostgreSQL con conectividad a la instancia de Cloud SQL para PostgreSQL. Sin embargo, te recomendamos usar el cliente PostgreSQL que instalaste antes en la instancia de Striim.
Crea los esquemas:
psql -h HOSTNAME -p CLOUD_SQL_PORT -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAME -f PATH_TO_MAIN_SQL_FILEReemplaza lo siguiente:
- HOSTNAME: Es la dirección IP de la instancia de Cloud SQL.
- CLOUD_SQL_PORT: Es el puerto de la instancia de Cloud SQL al que se conectará. De forma predeterminada, este puerto es
5432. - PATH_TO_MAIN_SQL_FILE: Es la ruta de acceso a la secuencia de comandos principal en la instancia de Striim.
Por ejemplo:
psql -h 12.123.123.123 -d testdb -U hr -p 5432 -f output.sql
Verifica que se hayan creado las tablas:
Conéctate a la base de datos de Cloud SQL para PostgreSQL:
psql -h HOSTNAME -p 5432 -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAMEHaz una lista de las tablas en esta base de datos:
\dtEl resultado es una lista de tablas que la secuencia de comandos de conversión del esquema de la tabla creó en el paso anterior.
Crea una tabla de puntos de control en la base de datos de Cloud SQL para PostgreSQL:
Conéctate a la base de datos de Cloud SQL para PostgreSQL:
psql -h HOSTNAME -p 5432 -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAMECrea la tabla:
CREATE TABLE chkpoint ( id character varying(100) primary key, sourceposition bytea, pendingddl numeric(1), ddl text);Striim necesita esta tabla para mantener los puntos de control durante el proceso de replicación continua.
Carga la base de datos de Oracle a la de Cloud SQL para PostgreSQL
En esta sección, se describe la replicación inicial única de la base de datos de Oracle para la base de datos de Cloud SQL para PostgreSQL.
Establece una conexión con Oracle desde Striim
Sigue las instrucciones en Ejecuta Striim en Google Cloud. Para la carga inicial, usa el adaptador del lector de base de datos de Striim a fin de conectarte a Oracle desde Striim. También puedes usar el asistente de la CDC de Striim.
En el adaptador del lector de base de datos de Striim, ve a Sources y, luego, busca y selecciona Database en la lista.
Configura las siguientes propiedades en la ventana Database:
- Name: Identifica este componente de la canalización de migración.
- Adapter:
DatabaseReader Connection URL: Ingresa una string única para conectarte a la base de datos de Oracle:
jdbc:oracle:thin:@HOSTNAME:ORACLE_PORT:SIDO
jdbc:oracle:thin:@HOSTNAME:ORACLE_PORT/PDB_OR_CDB_SERVICE_NAMEReemplaza lo siguiente:
- ORACLE_PORT: Es el puerto de la base de datos de Oracle (de forma predeterminada
1521). - SID: Es el SID de la base de datos de Oracle.
- PDB_OR_CDB_SERVICE_NAME: Es el nombre de servicio de PDB o CDB de Oracle: Si tus tablas están en una PDB, usa
PDB_SERVICE_NAME, si están en un CDB, usaCDB_SERVICE_NAME.
Puedes encontrar el puerto y el nombre del servicio en el archivo
tnsnames.oraubicado en$ORACLE_HOME/network/admin/tnsnames.oraen la instancia de Oracle.- ORACLE_PORT: Es el puerto de la base de datos de Oracle (de forma predeterminada
Username y password: Usa el usuario de Oracle (usuario
c##striim) que creaste en los pasos de los requisitos. Striim usa este nombre de usuario y contraseña para conectarse a tu base de datos de Oracle y leer las tablas.Tables: Para Oracle, el lector de bases de datos también necesita una lista de nombres de tablas para replicar. Esta propiedad se especifica en el campo Tablas en Show optional properties. El formato de esta propiedad es el siguiente:
ORACLE_SCHEMA.ORACLE_TABLE_NAMEReemplaza lo siguiente:
- ORACLE_SCHEMA: Es el nombre del esquema de Oracle.
- ORACLE_TABLE_NAME: Son los nombres de la tabla de Oracle en ese esquema.
También puedes especificar varias tablas y vistas materializadas como una lista separada por punto y coma, o con los siguientes comodines:
%: Es cualquier serie de caracteres._: Es cualquier carácter único.Por ejemplo,
HR.%lee todas las tablas en el esquema de RR.HH. Al menos una tabla debe coincidir con el comodín. De lo contrario, el lector de la base de datos falla con el siguiente error:Could not find tables specified in the databaseQuiesce On IL Completion: Para activar o desactivar este campo a verde, deslízalo hacia la derecha a fin de pausar la canalización cuando se complete la carga inicial.
Output To: Especifica el resultado de este adaptador. Usa una string que distinga mayúsculas de minúsculas sin caracteres o espacios especiales.
Haz clic en Guardar. Las propiedades del adaptador muestran lo siguiente:
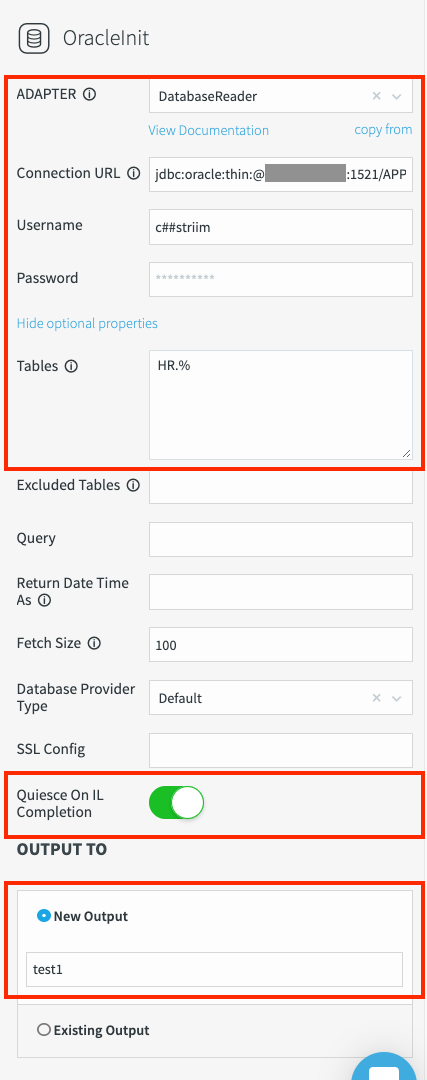
Prueba la conexión
Ahora que se conectó a Oracle desde Striim, pruebe la conexión.
Haz clic en la lista desplegable Creada para probar la conectividad de Striim a la base de datos de Oracle.
Haz clic en Implementar app.
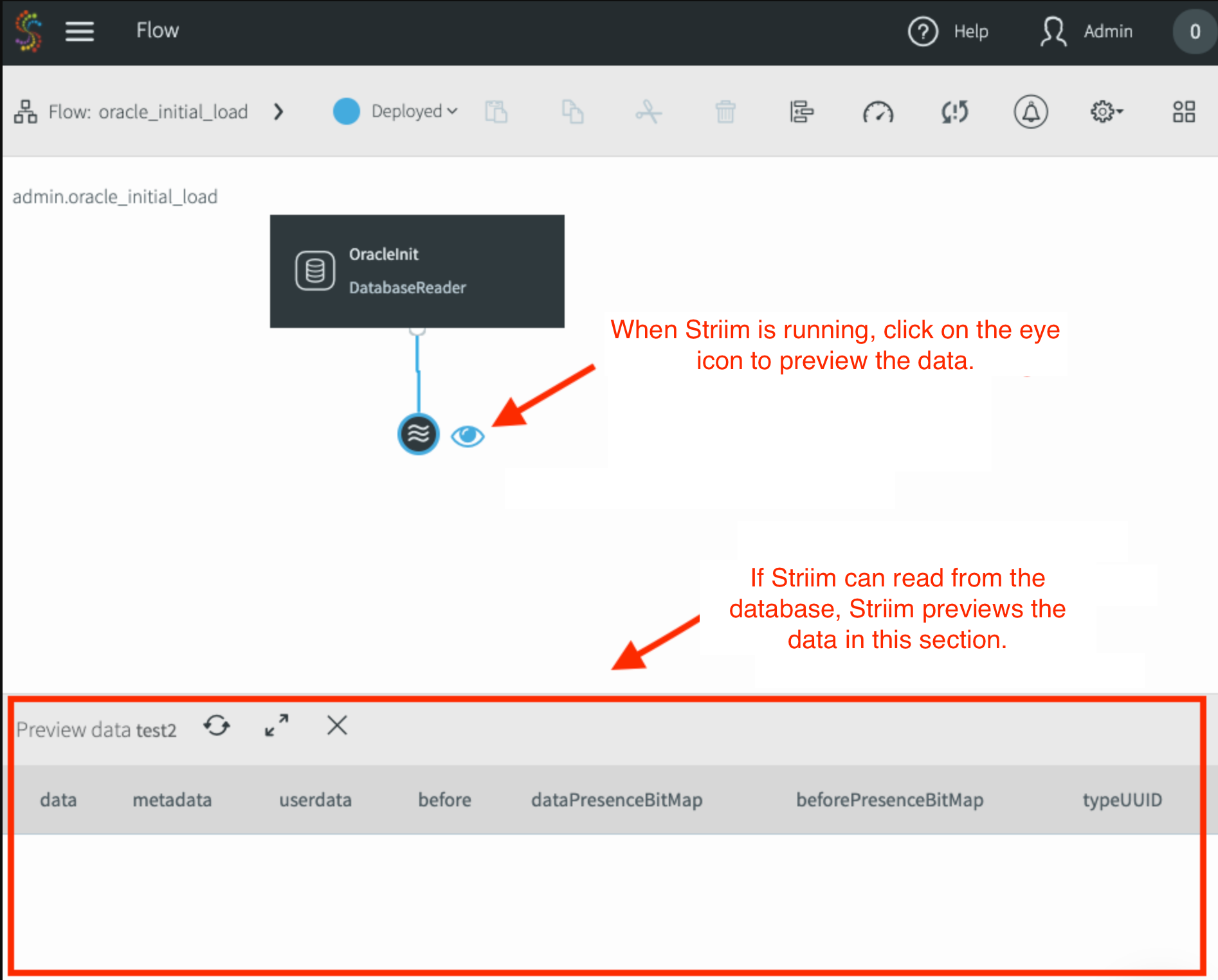
Selecciona el resultado de este adaptador y, luego, haz clic en Vista previa para mostrar los datos en tiempo real a medida que Striim los lee desde la fuente.
Haz clic en la lista desplegable Implementado y, luego, en Iniciar aplicación.
Haz clic en la lista desplegable Implementado y, luego, en Anular implementación de la app para corregir cualquier error que se genere (opcional).
Haz clic en Reanudar app después de corregir todos los errores para reiniciarla (opcional).
Haz clic en el grupo de implementación predeterminado.
Verifica que la opción Validar mapeos de tablas esté activada y, luego, haz clic en Implementar.
El panel de datos de la vista previa y el estado de la canalización cambian a Inactivo.
En este punto del instructivo, verificaste correctamente que Striim puede establecer una conexión con la base de datos de Oracle y leer los datos dentro de ella.
Agrega una base de datos de Cloud SQL para PostgreSQL como destino
En esta migración, escribirás datos en la instancia de Cloud SQL para PostgreSQL. Striim proporciona un adaptador de escritor de base de datos genérico, llamado escritor de base de datos, que puedes usar para la migración.
- En el diseñador de flujos de Striim, ve a Destinos. Busca y selecciona Cloud SQL Postgres en la lista.
- Arrastra Escritor de la base de datos a la canalización.
Establezca las siguientes propiedades:
Adapter:
DatabaseWriterConnection URL: Ingresa una string única para establecer una conexión con la instancia de Cloud SQL:
jdbc:postgresql://CLOUD_SQL_IP_ADDRESS:CLOUD_SQL_PORT/CLOUD_SQL_DATABASE_NAME?stringtype=unspecifiedReemplaza lo siguiente:
- CLOUD_SQL_IP_ADDRESS: Es la dirección IP de la instancia de Cloud SQL.
Por ejemplo:
jdbc:postgresql://12.123.12.12:5432/postgres?stringtype=unspecifiedNombre de usuario y contraseña: Ingresa el nombre de usuario y la contraseña de Cloud SQL que creaste antes.
Tablas: Crea una asignación desde los nombres de la tabla de la base de datos de Oracle hasta los nombres de la tabla de Cloud SQL. Especifica qué tabla de base de datos de Oracle se escribe en qué tabla de Cloud SQL. Esta asignación usa el siguiente formato:
ORACLE_SCHEMA.ORACLE_TABLE_NAME,CLOUD_SQL_SCHEMA.CLOUD_SQL_TABLE_NAMEReemplaza lo siguiente:
- CLOUD_SQL_SCHEMA: Es el nombre del esquema de PostgreSQL.
- CLOUD_SQL_TABLE_NAME: Es el nombre de la tabla de PostgreSQL.
Para asignar varias tablas, puedes usar el símbolo de comodín (%) en el campo Tablas, por ejemplo:
HR.%,hr.%Los campos obligatorios para el escritor de la base de datos se marcan en la siguiente captura de pantalla:
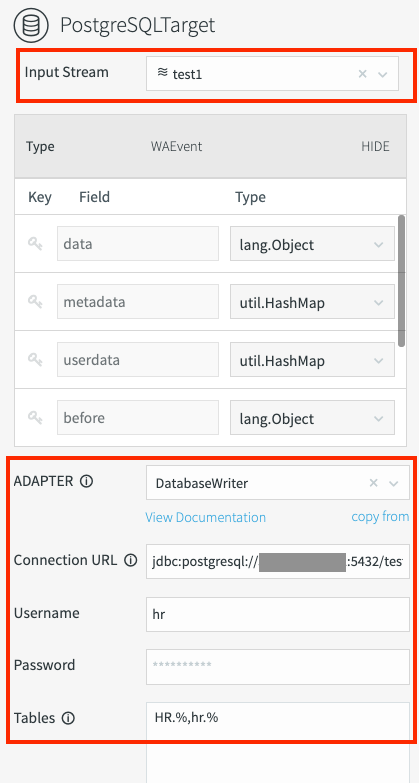
Implementa la canalización de migración
Una vez que la canalización de migración esté lista, impleméntala desde el diseñador de flujos de Striim e inicia la aplicación. También puedes obtener una vista previa de los datos que se replican en tiempo real. Usa los informes de supervisión para realizar un seguimiento del progreso de la replicación. Para realizar un seguimiento del progreso, selecciona el ícono de Progreso de la aplicación.
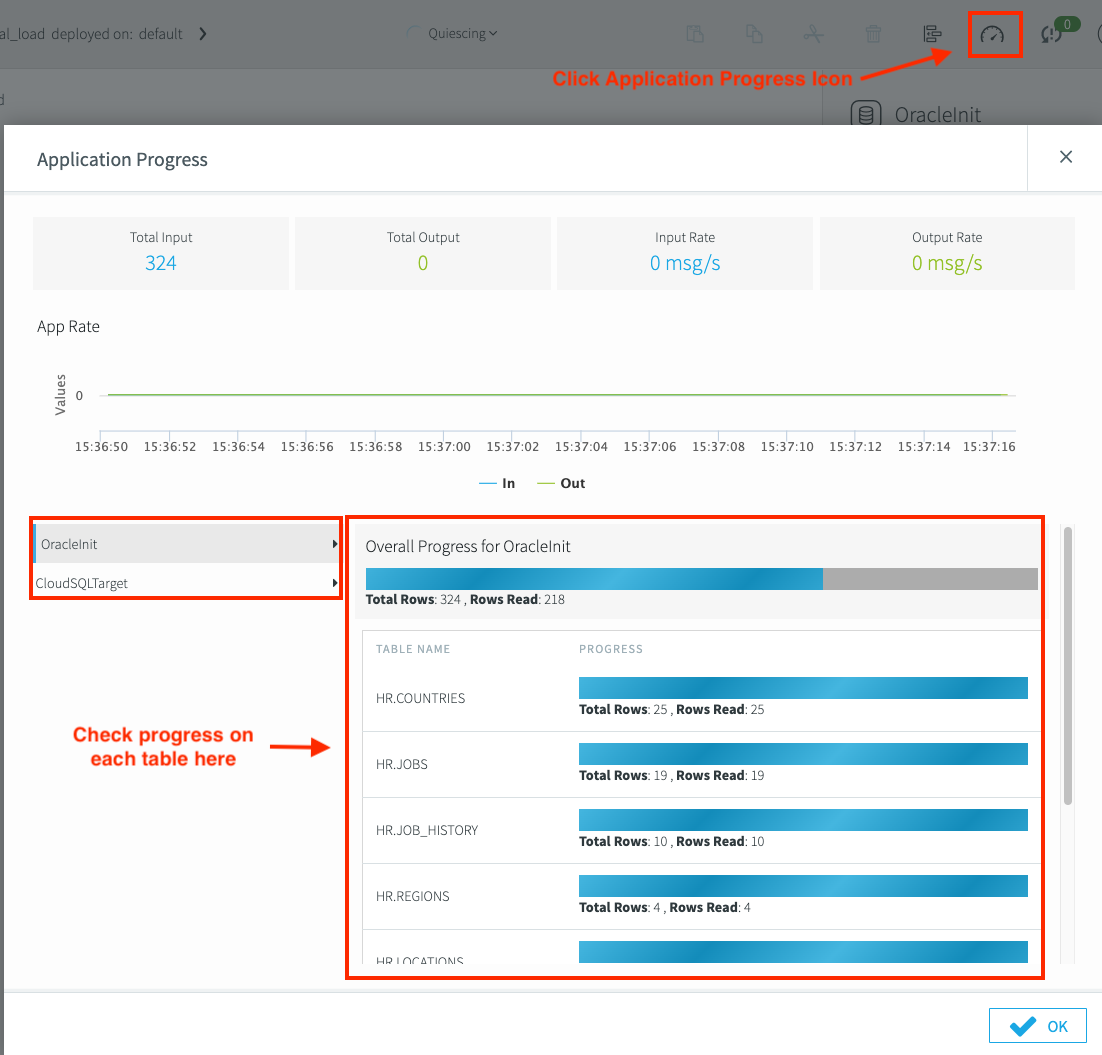
En el diseñador de flujos de Striim, implementa la canalización de migración. Haz clic en la lista desplegable Creada y, luego, en Implementar app. Una vez que se completa la carga inicial, el estado de la canalización cambia a
Quiesced.Haz clic en Anular la implementación de la app para revertir la implementación.
Verifica que la carga de datos se haya realizado correctamente mediante el recuento de filas:
SELECT COUNT(*) FROM <TARGET CLOUD SQL TABLE>;Deberías ver un resultado que no sea cero. Si no lo haces, la carga de datos falló.
La carga de datos inicial de la base de datos de Oracle a Cloud SQL para PostgreSQL es atómica. Toda la carga de datos se realiza de forma correcta o falla toda la carga de datos. Si la carga inicial falla, debes volver a cargar los datos.
Habilita restricciones de clave externa en las tablas de Cloud SQL para PostgreSQL
Una vez completada la carga inicial, habilita las restricciones de clave externa en las tablas de destino. Usa el archivo con las declaraciones de clave externa (FKEY_output.sql o converted_foreignkey.sql) que creaste durante la conversión de esquema.
En Striim, abre una sesión de SSH.
Crea restricciones de clave externa en las tablas:
psql -h HOSTNAME -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAME -p CLOUD_SQL_PORT -f PATH_TO_FOREIGN_KEY_FILEReemplaza lo siguiente:
- CLOUD_SQL_USERNAME: Es el nombre de usuario de Cloud SQL para PostgreSQL.
PATH_TO_FOREIGN_KEY_FILE: Es la ruta de acceso a la secuencia de comandos con restricciones de clave externa en la instancia de Striim.
Por ejemplo:
psql -h 12.123.123.123 -d testdb -U hr -p 5432 -f output.sql
Replica de forma continua la base de datos de Oracle en Cloud SQL para PostgreSQL
Después de completar la carga inicial de datos, crea una canalización independiente para replicar los cambios en la base de datos de Oracle. Siempre que permanezca en ejecución, esta canalización también mantendrá la base de datos de origen sincronizada con la base de datos de destino.
Establece una conexión con Oracle desde Striim
Para la replicación continua, usa el adaptador del lector de Oracle de Striim a fin de conectarte desde Striim a la base de datos de Oracle. Este adaptador de Striim puede leer los datos de los CDC de Oracle.
- En el adaptador del lector de Oracle de Striim, navega a Fuentes.
Busca Oracle y selecciona los CDC de Oracle de la lista que se propaga.
Establezca las siguientes propiedades:
URL de conexión:
HOSTNAME:ORACLE_PORT/SIDO
HOSTNAME:ORACLE_PORT/CDB_SERVICE_NAMEReemplaza lo siguiente:
- CDB_SERVICE_NAME: Es el nombre del servicio de CDB de Oracle.
La URL de conexión es una string única que se usa para conectarse a la base de datos de Oracle. A diferencia del adaptador de lector de base de datos que se usa para la carga inicial, debes usar el nombre del servicio de CDB, sin importar si tus tablas de base de datos están en un PDB o CDB.
Por ejemplo:
12.123.123.12:1521/ORCLCDB.WORLD.Nombre de usuario/contraseña: Usa el nombre de usuario de Oracle (usuario
c##striim) que creaste en los pasos de los requisitos.Este usuario de Oracle debe tener los privilegios para leer tus tablas.
Tablas: También necesitas una lista de nombres de tablas para replicar. El nombre se especifica en el siguiente formato, según si las tablas están en un CDB o PDB.
Para la tabla CDB:
ORACLE_SCHEMA.ORACLE_TABLE_NAMEPara la tabla PDB:
PDB_NAME.ORACLE_SCHEMA.ORACLE_TABLE_NAMEReemplaza lo siguiente:
- PDB_NAME: Es el nombre de PDB de Oracle.
Este comando replica las tablas de CDB o PDB. Puedes encontrar tu
PDB_NAMEen el archivotnsnames.oraubicado en$ORACLE_HOME/network/admin/tnsnames.oraen la instancia de Oracle.Recuerda que
PDB_NAMEyPDB_SERVICE_NAMEson diferentes. UsastePDB_SERVICE_NAMEantes en la sección. Visualiza el archivotnsnames.orapara obtener el nombre del PDB:sudo su - oracle // Login as oracle user cat ORACLE_HOME/network/admin/tnsnames.oraA continuación, se muestra un ejemplo de
PDB_NAME(APPSPDB) en el archivotnsnames.ora:APPSPDB = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP) (HOST = orainst) (PORT = 1521)) ) (CONNECT_DATA = (SERVICE NAME = APPSPDB.WORLD) ) )Para especificar varias tablas y vistas materializadas como una lista, separa los nombres de las tablas o de las vistas por punto y coma o comodines. Al menos una tabla debe coincidir con el comodín; de lo contrario, el lector de Oracle fallará con el error
Could not find tables specified in the database.Iniciar SCN: Para la canalización continua, debes proporcionar la SCN de la base de datos de Oracle. Striim lo necesita para comenzar a replicar todas las transacciones. Ingresa el valor de SCN que generaste antes.
Compatibilidad con PDB y CDB: Puedes usar un CDB o una PDB. Expande Mostrar propiedades opcionales y mueve el interruptor hacia la derecha.
Tabla de marcadores inactiva: Usa el nombre de tabla que creaste antes.
En la siguiente captura de pantalla, se proporciona una descripción general de los campos obligatorios para el adaptador de lector de Oracle:
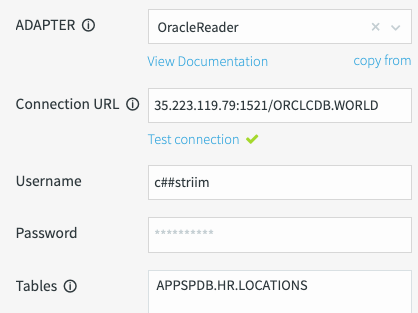
Probar conexión: Haz clic en Probar conexión. Para probar la conectividad de la base de datos, se requieren la URL de conexión, el nombre de usuario y la contraseña. Si Striim logra establecer una conexión correctamente, aparecerá una marca de verificación verde.
Prueba la capacidad de Striim para leer las tablas de base de datos de Oracle:
- En el adaptador de lector de Oracle, selecciona Implementar app.
- Seleccione el grupo de implementación predeterminado.
- Haga clic en Implementar.
Haz clic en el ícono de onda (Resultado) de este adaptador. El ícono del ojo (Vista previa) que aparece se usa para obtener una vista previa de los datos en tiempo real a medida que Striim los lee de la fuente.
Haz clic en Iniciar aplicación, en el menú desplegable Implementado.
Si se produce algún error, selecciona Anular la implementación de la app en el mismo menú desplegable y corrige los errores. Después de corregir los errores, haz clic en Reanudar app para reiniciar la aplicación.
Cuando se inicia la canalización, este se actualiza a Running. Los cambios nuevos que se realicen en la tabla fuente se mostrarán en la ventana de vista previa. Debido a que el adaptador de lector de Oracle usa los CDC, los únicos cambios de tabla que aparecen en el panel de datos de vista previa son los que ocurren después de que se inició la aplicación.
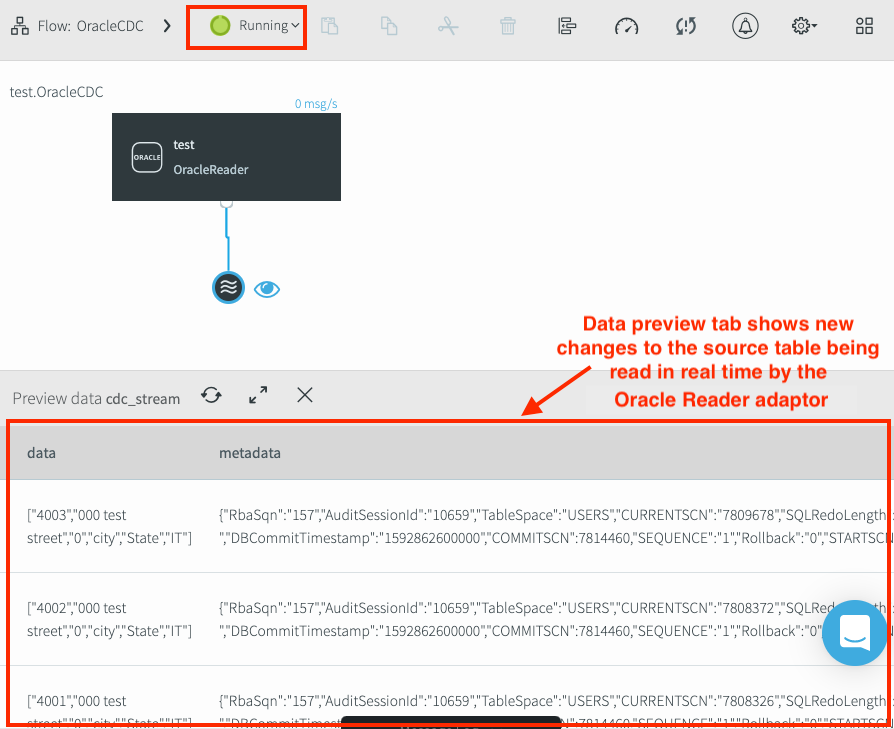
Verifica la capacidad de leer datos de los CDC de Oracle
Para probar si el adaptador puede leer cambios nuevos, sigue estas instrucciones:
- Usa instrucciones de SQL para insertar transacciones nuevas en las tablas de origen de Oracle.
- Verifica que las transacciones nuevas aparezcan en la pestaña Vista previa de los datos del adaptador de lector de Oracle.
- Detén la aplicación y haz clic en Anular la implementación. Ahora estás listo para continuar con el siguiente paso.
Hasta ahora, no agregaste un adaptador de destino a la canalización. No se copiarán datos, a menos que agregues un adaptador de destino. En la siguiente sección, agregarás un adaptador de destino.
Agrega una base de datos de Cloud SQL para PostgreSQL como destino
Si deseas escribir datos en la base de datos de Cloud SQL para PostgreSQL, debes agregar un adaptador de escritor de bases de datos a tu canalización. Para la canalización de replicación continua, usa el mismo adaptador que usaste en la canalización de carga inicial.
- En el diseñador de flujo de Striim, ve a Destinos y busca y selecciona Cloud SQL Postgres en la lista.
- Arrastra Escritor de la base de datos a la canalización.
Establezca las siguientes propiedades:
Adaptador:
DatabaseWriter.URL de conexión: ingresa la URL de conexión que ingresaste para establecer una conexión con la instancia de Cloud SQL:
jdbc:postgresql://CLOUD_SQL_IP_ADDRESS:CLOUD_SQL_PORT/CLOUD_SQL_DATABASE_NAME?stringtype=unspecifiedPor ejemplo:
jdbc:postgresql://12.123.12.12:5432/postgres?stringtype=unspecifiedNombre de usuario y contraseña: Ingresa el nombre de usuario y la contraseña de Cloud SQL que creaste antes.
Tablas: Crea una asignación desde los nombres de la tabla de la base de datos de Oracle hasta los nombres de la tabla de Cloud SQL. Especifica qué tabla de base de datos de Oracle se escribe en qué tabla de Cloud SQL. Esta asignación usa el siguiente formato:
ORACLE_SCHEMA.ORACLE_TABLE_NAME,CLOUD_SQL_SCHEMA.CLOUD_SQL_TABLE_NAMEPara asignar varias tablas, puedes usar el símbolo de comodín (%) en el campo Tablas. Por ejemplo:
HR.%,hr.%Además de esas propiedades, también debes establecer las siguientes propiedades para la canalización de replicación continua:
Haz clic en Mostrar propiedades opcionales.
Selecciona el siguiente valor en el campo Código de excepción que se puede omitir:
23505,NO_OP_UPDATE,NO_OP_DELETEDado que estás iniciando la canalización de los CDC desde un punto histórico, puede haber duplicados. Striim anula el duplicado el objetivo con las propiedades anteriores del código de excepción ignorable. Los detalles sobre los códigos de excepción se pueden encontrar en la siguiente tabla:
Código de excepción Detalles 23505El valor de la clave primaria duplicado infringe la restricción única NO_OP_UPDATENo se pudo actualizar una fila en el destino (en general, porque no había una clave primaria correspondiente) NO_OP_DELETENo se pudo borrar una fila en el destino (en general, porque no había una clave primaria correspondiente) Ingresa
chkpointen el campo Tabla de puntos de control. Striim usa esta tabla para almacenar metadatos asociados con los puntos de control de la canalización de replicación continua.
Habilita la recuperación y la encriptación
Antes de implementar la canalización de los CDC, te recomendamos que habilites la recuperación. Si la aplicación o la VM de Striim fallan, habilitar la recuperación ayuda a garantizar que Striim pueda seguir procesando. Este paso también ayuda a garantizar la semántica de procesamiento del tipo “exactamente una vez”. Estas semánticas realizan un seguimiento del último punto de control de lectura conocido en la base de datos de origen y el último punto de control de escritura conocido en la base de datos de destino. Si una aplicación o una VM fallan, Striim coordina los dos puntos de control para garantizar que no se pierdan o se dupliquen datos. La recuperación no se aplica a las aplicaciones de carga iniciales.
Habilita la recuperación
- En diseñador de flujos de Striim, haz clic en el ícono Configuración y, luego, selecciona Configuración de la aplicación.
- Haz clic en Intervalo de recuperación.
- Escribe
5y selecciona Segundo en la lista desplegable. - Haz clic en habilitar encriptación. Striim encripta todas las transmisiones que transfieren datos entre servidores de Striim o desde un agente de reenvío a un servidor de Striim.
Habilitar encriptación
- En el diseñador de flujo de Striim, haz clic en el ícono Configuración, selecciona Configuración de aplicación y, luego, en Encriptación, selecciona la casilla de verificación.
Consulta el sitio web de Striim para obtener más información sobre los métodos de recuperación de Striim.
Habilita excepciones de registros
Antes de implementar la canalización de replicación continua, te recomendamos que habilites el almacén de excepción en Striim. Como parte de la aplicación de los CDC, puede haber duplicados escritos por la aplicación de carga inicial. La aplicación de Striim ignora esos errores, los escribe en un almacén (para que los revises y los proceses) y continúa con el procesamiento.
- En el diseñador de flujos de Striim, selecciona el ícono Excepciones. El ícono muestra un signo de exclamación entre dos flechas curvas.
- Haz clic en Activar.
Implementa la canalización
Una vez que la canalización esté lista, puedes implementarla y, luego, iniciar la aplicación. También puedes obtener una vista previa de los datos mientras se replican en tiempo real y consultar los informes de supervisión. Cuando la canalización inicia de forma correcta la replicación continua, el estado de la canalización cambia a En ejecución.
- En el adaptador de lector de Oracle, selecciona Implementar app.
- Seleccione el grupo de implementación predeterminado.
- Haga clic en Implementar.
Puedes mantener la canalización en ejecución durante el tiempo que desees mantener las tablas de Oracle sincronizadas con las tablas de Cloud SQL.
Terminaste el instructivo. Si te interesa obtener información sobre otras fuentes de los CDC de Oracle, en la siguiente sección se analizan.
Fuentes alternativas de los CDC de Oracle
Además de LogMiner, el adaptador de Striim puede leer bases de datos de Oracle desde XStream o archivos de seguimiento de Oracle Golden Gate.
Para leer desde XStream, usa el adaptador de lector de Oracle de Striim. XStream puede tener un mejor rendimiento, pero requiere una licencia de Golden Gate y solo es compatible con Oracle Database 11.2.0.4.
Para leer los archivos de registro de Golden Gate usa el adaptador de lector de seguimiento de GG de Striim.
En la siguiente tabla, se describen las diferencias entre LogMiner y XStream:
| Funciones de los CDC de la base de datos de Oracle |
¿Es compatible con LogMiner? |
¿Es compatible con XStream Out? |
|---|---|---|
Lee el lenguaje de definición de datos (DDL), ROLLBACK y las transacciones sin confirmar |
Sí | No |
Usa las funciones DATA() y BEFORE() |
Sí | No |
Mediante QUIESCE (consulta Comandos de Console)
|
Sí | No |
| Recibe eventos de los CDC | Recibe eventos en lotes según lo que define la propiedad FetchSize del lector de Oracle. |
Recepción continua de los eventos de datos de cambios |
| Lee desde tablas que contienen tipos no compatibles | No se leerá la tabla | Lee las columnas de los tipos admitidos |
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
¿Qué sigue?
- Consulta la documentación de Striim: Guía de migración de Oracle a Google Cloud PostgreSQL.
- Mira el video Migra las bases de datos de Oracle a Cloud SQL para PostgreSQL.
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.
Oracle, Java y MySQL son marcas registradas de Oracle o sus afiliados. Otros nombres pueden ser marcas registradas de sus respectivos propietarios.