Este instructivo es la segunda parte de una serie que te muestra cómo crear una solución de extremo a extremo para proporcionar a los analistas acceso seguro a los datos cuando usan herramientas de inteligencia empresarial (IE).
Este instructivo está dirigido a operadores y administradores de TI que configuran entornos que proporcionan capacidades de procesamiento de datos y datos a las herramientas de inteligencia empresarial (IE) que usan los analistas de datos.
En este instructivo, se usa Tableau como la herramienta de IE. Para continuar con este instructivo, debes tener Tableau Desktop instalado en tu estación de trabajo.
La serie consta de las siguientes partes:
- En la primera parte de la serie, Arquitectura para conectar un software de visualización a Hadoop en Google Cloud, se define la arquitectura de la solución, sus componentes y cómo interactúan los componentes.
- En esta segunda parte de la serie, se explica cómo configurar los componentes de la arquitectura que conforman la topología de Hive de extremo a extremo en Google Cloud. En el instructivo, se usan herramientas de código abierto del ecosistema de Hadoop, con Tableau como herramienta de IE.
Los fragmentos de código de este instructivo están disponibles en un repositorio de GitHub. El repositorio de GitHub también incluye archivos de configuración de Terraform para ayudarte a configurar un prototipo en funcionamiento.
Durante el instructivo, usarás el nombre sara como la identidad ficticia del usuario de un analista de datos. Esta identidad de usuario se encuentra en el directorio LDAP que usan Apache Knox y Apache Ranger. También puedes configurar los grupos de LDAP, pero este procedimiento está fuera del alcance de este instructivo.
Objetivos
- Crear una configuración de extremo a extremo que permita que una herramienta de IE use datos de un entorno de Hadoop.
- Autenticar y autorizar solicitudes del usuario.
- Configura y usa canales de comunicación seguros entre la herramienta IE y el clúster.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS).
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS).
Inicializa un entorno
-
En la consola de Google Cloud, activa Cloud Shell.
En Cloud Shell, configura las variables de entorno con el ID del proyecto y las regiones y zonas de los clústeres de Dataproc:
export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bPuedes elegir cualquier región y zona, pero mantenerlas coherentes a medida que sigues este instructivo.
Configura una cuenta de servicio
En Cloud Shell, crea una cuenta de servicio:
gcloud iam service-accounts create cluster-service-account \ --description="The service account for the cluster to be authenticated as." \ --display-name="Cluster service account"El clúster usa esta cuenta para acceder a los recursos de Google Cloud.
Otorga las siguientes funciones a la cuenta de servicio
- Trabajador de Dataproc: para crear y administrar clústeres de Dataproc
- Editor de Cloud SQL: para que Ranger se conecte a su base de datos mediante un proxy de Cloud SQL.
Desencriptador de CryptoKey de Cloud KMS: para desencriptar las contraseñas encriptadas con Cloud KMS,
bash -c 'array=( dataproc.worker cloudsql.editor cloudkms.cryptoKeyDecrypter ) for i in "${array[@]}" do gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "serviceAccount:cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com" \ --role roles/$i done'
Crea el clúster de backend
En esta sección, crearás el clúster de backend en el que se encuentra Ranger. También debes crear la base de datos Ranger para almacenar las reglas de la política y una tabla de muestra en Hive a fin de aplicar las políticas Ranger.
Crea la instancia de base de datos de Ranger
Crea una instancia de MySQL para almacenar las políticas de Apache Ranger:
export CLOUD_SQL_NAME=cloudsql-mysql gcloud sql instances create ${CLOUD_SQL_NAME} \ --tier=db-n1-standard-1 --region=${REGION}Con este comando, se crea una instancia llamada
cloudsql-mysqlcon el tipo de máquinadb-n1-standard-1ubicado en la región que especifica la variable${REGION}. Para obtener más información, consulta la documentación de Cloud SQL.Configura la contraseña de la instancia para el usuario
rootque se conectará desde cualquier host. Puedes usar la contraseña de ejemplo con fines demostrativos o crear la tuya. Si creas tu propia contraseña, usa un mínimo de ocho caracteres, incluidos al menos una letra y un número.gcloud sql users set-password root \ --host=% --instance ${CLOUD_SQL_NAME} --password mysql-root-password-99
Encripta las contraseñas
En esta sección, crearás una clave criptográfica para encriptar las contraseñas de Ranger y MySQL. Para evitar el robo de datos, almacena la clave criptográfica en Cloud KMS. Por motivos de seguridad, no puedes ver, extraer ni exportar los bits de clave.
Usas la clave criptográfica para encriptar las contraseñas y escribirlas en archivos.
Sube estos archivos a un bucket de Cloud Storage para que la cuenta de servicio que actúa en nombre de los clústeres pueda acceder a ellos.
La cuenta de servicio puede desencriptar estos archivos porque tiene la función cloudkms.cryptoKeyDecrypter y el acceso a los archivos y a la clave criptográfica. Incluso si se roba un archivo, no se puede desencriptar sin la función y la clave.
Como medida de seguridad adicional, debes crear archivos de contraseña independientes para cada servicio. Esta acción minimiza el posible área afectada si se roba una contraseña.
Para obtener más información sobre la administración de claves, consulta la documentación de Cloud KMS.
En Cloud Shell, crea un llavero de claves de Cloud KMS para guardar tus claves:
gcloud kms keyrings create my-keyring --location globalPara encriptar tus contraseñas, crea una clave criptográfica de Cloud KMS:
gcloud kms keys create my-key \ --location global \ --keyring my-keyring \ --purpose encryptionEncripta la contraseña de usuario de administrador de Ranger mediante la clave. Puedes usar la contraseña de ejemplo o crear la tuya. La contraseña debe tener al menos ocho caracteres, incluidos al menos una letra y un número.
echo "ranger-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-admin-password.encryptedEncripta la contraseña de usuario de administrador de la base de datos de Ranger con la siguiente clave:
echo "ranger-db-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-db-admin-password.encryptedEncripta tu contraseña raíz de MySQL con la siguiente clave:
echo "mysql-root-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=mysql-root-password.encryptedCrea un bucket de Cloud Storage para almacenar archivos de contraseñas encriptados:
gsutil mb -l ${REGION} gs://${PROJECT_ID}-rangerSube los archivos de contraseñas encriptados al bucket de Cloud Storage:
gsutil -m cp *.encrypted gs://${PROJECT_ID}-ranger
Cree el clúster
En esta sección, crearás un clúster de backend compatible con Ranger. Para obtener más información sobre el componente opcional de Ranger en Dataproc, consulta la página de documentación del componente Ranger de Dataproc.
En Cloud Shell, crea un bucket de Cloud Storage para almacenar los registros de auditoría de Apache Solr:
gsutil mb -l ${REGION} gs://${PROJECT_ID}-solrExporta todas las variables requeridas para crear el clúster:
export BACKEND_CLUSTER=backend-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-b export CLOUD_SQL_NAME=cloudsql-mysql export RANGER_KMS_KEY_URI=\ projects/${PROJECT_ID}/locations/global/keyRings/my-keyring/cryptoKeys/my-key export RANGER_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-admin-password.encrypted export RANGER_DB_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-db-admin-password.encrypted export MYSQL_ROOT_PWD_URI=\ gs://${PROJECT_ID}-ranger/mysql-root-password.encryptedPara mayor comodidad, algunas de las variables que configuraste antes se repiten en este comando a fin de que puedas modificarlas según lo necesites.
Las nuevas variables contienen lo siguiente:
- El nombre del clúster de backend.
- El URI de la clave criptográfica para que la cuenta de servicio pueda desencriptar las contraseñas.
- El URI de los archivos que contienen las contraseñas encriptadas.
Si usaste un llavero de claves o una clave diferentes, o nombres de archivos diferentes, usa los valores correspondientes en tu comando.
Crea el clúster de backend de Dataproc:
gcloud beta dataproc clusters create ${BACKEND_CLUSTER} \ --optional-components=SOLR,RANGER \ --region ${REGION} \ --zone ${ZONE} \ --enable-component-gateway \ --scopes=default,sql-admin \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --properties="\ dataproc:ranger.kms.key.uri=${RANGER_KMS_KEY_URI},\ dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PWD_URI},\ dataproc:ranger.db.admin.password.uri=${RANGER_DB_ADMIN_PWD_URI},\ dataproc:ranger.cloud-sql.instance.connection.name=${PROJECT_ID}:${REGION}:${CLOUD_SQL_NAME},\ dataproc:ranger.cloud-sql.root.password.uri=${MYSQL_ROOT_PWD_URI},\ dataproc:solr.gcs.path=gs://${PROJECT_ID}-solr,\ hive:hive.server2.thrift.http.port=10000,\ hive:hive.server2.thrift.http.path=cliservice,\ hive:hive.server2.transport.mode=http"Este comando tiene las siguientes propiedades:
- Las últimas tres líneas en el comando son las propiedades de Hive para configurar HiveServer2 en modo HTTP, de modo que Apache Knox pueda llamar a Apache Hive a través de HTTP.
- Los otros parámetros del comando funcionan de la siguiente manera:
- El parámetro
--optional-components=SOLR,RANGERhabilita Apache Ranger y su dependencia de Solr. - El parámetro
--enable-component-gatewaypermite que la puerta de enlace de componentes de Dataproc haga que las interfaces de usuario de Ranger y otras de Hadoop estén disponibles directamente desde la página del clúster en la consola de Google Cloud. Cuando configuras este parámetro, no es necesario establecer un túnel SSH para el nodo principal del backend. - El parámetro
--scopes=default,sql-adminautoriza a Apache Ranger a acceder a su base de datos de Cloud SQL.
- El parámetro
Si necesitas crear un almacén de metadatos externo de Hive que persista más allá de la vida útil de cualquier clúster y se pueda usar en varios clústeres, consulta Usa Apache Hive en Dataproc.
Para ejecutar el procedimiento, debes ejecutar los ejemplos de creación de tablas directamente en Beeline. Si bien los comandos gcloud dataproc jobs submit hive usan el transporte binario de Hive, estos comandos no son compatibles con HiveServer2 cuando se configura en modo HTTP.
Crea una tabla de Hive de muestra
En Cloud Shell, crea un bucket de Cloud Storage para almacenar un archivo de Apache Parquet de muestra:
gsutil mb -l ${REGION} gs://${PROJECT_ID}-hiveCopia un archivo Parquet de muestra disponible de forma pública en tu bucket:
gsutil cp gs://hive-solution/part-00000.parquet \ gs://${PROJECT_ID}-hive/dataset/transactions/part-00000.parquetConéctate al nodo principal del clúster de backend que creaste en la sección anterior mediante SSH:
gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mEl nombre del nodo de la instancia principal del clúster es el nombre del clúster seguido de
-m.. Los nombres de los nodos principales del clúster con alta disponibilidad tienen un sufijo adicional.Si es la primera vez que te conectas a tu nodo principal desde Cloud Shell, se te pedirá que generes las claves SSH.
En la terminal que abriste con SSH, conéctate a HiveServer2 local con Apache Beeline, que viene preinstalado en el nodo principal:
beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice admin admin-password"\ --hivevar PROJECT_ID=$(gcloud info --format='value(config.project)')Este comando inicia la herramienta de línea de comandos de Beeline y pasa el nombre de tu proyecto de Google Cloud en una variable de entorno.
Hive no realiza ninguna autenticación de usuario, pero para realizar la mayoría de las tareas necesita una identidad de usuario. El usuario
admines un usuario predeterminado que se configura en Hive. El proveedor de identidad que configuras con Apache Knox más adelante en este instructivo controla la autenticación de usuarios para cualquier solicitud que provenga de herramientas de IE.En el mensaje de Beeline, crea una tabla con el archivo Parquet que copiaste antes en tu bucket de Hive:
CREATE EXTERNAL TABLE transactions (SubmissionDate DATE, TransactionAmount DOUBLE, TransactionType STRING) STORED AS PARQUET LOCATION 'gs://${PROJECT_ID}-hive/dataset/transactions';Verifica que se haya creado la tabla.
SELECT * FROM transactions LIMIT 10; SELECT TransactionType, AVG(TransactionAmount) AS AverageAmount FROM transactions WHERE SubmissionDate = '2017-12-22' GROUP BY TransactionType;Los resultados de las dos consultas aparecen en el símbolo del sistema de Beeline.
Sal de la herramienta de línea de comandos de Beeline:
!quitCopia el nombre de DNS interno de la instancia principal del backend:
hostname -A | tr -d '[:space:]'; echoUsarás este nombre en la siguiente sección como
backend-master-internal-dns-namepara configurar la topología de Apache Knox. También usas el nombre para configurar un servicio en Ranger.Sal de la terminal en el nodo:
exit
Crea el clúster del proxy
En esta sección, crearás el clúster del proxy que tiene la acción de inicialización de Apache Knox.
Crea una topología
En Cloud Shell, clona el repositorio de GitHub de acciones de inicialización de Dataproc:
git clone https://github.com/GoogleCloudDataproc/initialization-actions.gitCrea una topología para el clúster de backend:
export KNOX_INIT_FOLDER=`pwd`/initialization-actions/knox cd ${KNOX_INIT_FOLDER}/topologies/ mv example-hive-nonpii.xml hive-us-transactions.xmlApache Knox usa el nombre del archivo como la ruta de URL para la topología. En este paso, debes cambiar el nombre para representar una topología llamada
hive-us-transactions. Luego, puedes acceder a los datos de transacciones ficticias que cargaste en Hive en Crea una tabla de Hive de muestra.Edita el archivo de topología:
vi hive-us-transactions.xmlPara ver cómo se configuran los servicios de backend, consulta el archivo descriptor de topología. Este archivo define una topología que apunta a uno o más servicios de backend. Hay dos servicios configurados con valores de muestra: WebHDFS y HIVE. El archivo también define el proveedor de autenticación para los servicios de esta topología y las LCA de autorización.
Agrega la identidad de usuario LDAP de muestra del analista de datos
sara.<param> <name>hive.acl</name> <value>admin,sara;*;*</value> </param>Agregar la identidad de muestra permite al usuario acceder al servicio de backend de Hive a través de Apache Knox.
Cambia la URL de HIVE para que apunte al servicio de Hive del clúster de backend. Puedes encontrar la definición del servicio de HIVE en la parte inferior del archivo, en WebHDFS.
<service> <role>HIVE</role> <url>http://<backend-master-internal-dns-name>:10000/cliservice</url> </service>Reemplaza el marcador de posición
<backend-master-internal-dns-name>por el nombre de DNS interno del clúster de backend que obtuviste en Crea una tabla de Hive de muestra.Guarda el archivo y cierra el editor de texto.
Para crear topologías adicionales, repite los pasos de esta sección. Crea un descriptor XML independiente para cada topología.
En Crea el clúster de proxy, copia estos archivos en un bucket de Cloud Storage. Para crear topologías nuevas o modificarlas después de crear el clúster del proxy, modifica los archivos y vuelve a subirlos al bucket. La acción de inicialización de Apache Knox crea un trabajo cron que copia con regularidad los cambios del bucket en el clúster del proxy.
Configura el certificado SSL/TLS
Un cliente usa un certificado SSL/TLS cuando se comunica con Apache Knox. La acción de inicialización puede generar un certificado autofirmado o puedes proporcionar tu certificado firmado por una CA.
En Cloud Shell, edita el archivo de configuración general de Apache Knox:
vi ${KNOX_INIT_FOLDER}/knox-config.yamlReemplaza
HOSTNAMEpor el nombre de DNS externo del nodo de la instancia principal del proxy como el valor para el atributocertificate_hostname. En este instructivo, usalocalhost.certificate_hostname: localhostMás adelante en este instructivo, crearás un túnel SSH y el clúster de proxy para el valor
localhost.El archivo de configuración general de Apache Knox también contiene el
master_keyque encripta los certificados de IE que usan las herramientas de comunicación para comunicarse con el clúster de proxy. De forma predeterminada, esta clave es la palabrasecret.Si proporcionas tu propio certificado, cambia las siguientes dos propiedades:
generate_cert: false custom_cert_name: <filename-of-your-custom-certificate>Guarda el archivo y cierra el editor.
Si proporcionas tu propio certificado, puedes especificarlo en la propiedad
custom_cert_name.
Crea el clúster del proxy
En Cloud Shell, crea un bucket de Cloud Storage:
gsutil mb -l ${REGION} gs://${PROJECT_ID}-knoxEste bucket proporciona la configuración que creaste en la sección anterior para la acción de inicialización de Apache Knox.
Copia todos los archivos de la carpeta de acción de inicialización de Apache Knox en el bucket:
gsutil -m cp -r ${KNOX_INIT_FOLDER}/* gs://${PROJECT_ID}-knoxExporta todas las variables requeridas para crear el clúster:
export PROXY_CLUSTER=proxy-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bEn este paso, algunas de las variables que configuraste antes se repiten para que puedas realizar modificaciones según sea necesario.
Crea el clúster del proxy:
gcloud dataproc clusters create ${PROXY_CLUSTER} \ --region ${REGION} \ --zone ${ZONE} \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --initialization-actions gs://goog-dataproc-initialization-actions-${REGION}/knox/knox.sh \ --metadata knox-gw-config=gs://${PROJECT_ID}-knox
Verifica la conexión a través del proxy
Después de crear el clúster de proxy, usa SSH para conectarte a su nodo principal desde Cloud Shell:
gcloud compute ssh --zone ${ZONE} ${PROXY_CLUSTER}-mDesde la terminal del nodo principal del clúster del proxy, ejecuta la siguiente consulta:
beeline -u "jdbc:hive2://localhost:8443/;\ ssl=true;sslTrustStore=/usr/lib/knox/data/security/keystores/gateway-client.jks;trustStorePassword=secret;\ transportMode=http;httpPath=gateway/hive-us-transactions/hive"\ -e "SELECT SubmissionDate, TransactionType FROM transactions LIMIT 10;"\ -n admin -p admin-password
Este comando tiene las siguientes propiedades:
- El comando
beelineusalocalhosten lugar del nombre interno de DNS, ya que el certificado que generaste cuando configuraste Apache Knox especificalocalhostcomo el nombre de host. Si usas tu propio nombre de DNS o certificado, usa el nombre de host correspondiente. - El puerto
8443, que corresponde al puerto SSL predeterminado de Apache Knox. - La línea que comienza con
ssl=truehabilita SSL y proporciona la ruta y la contraseña de SSL Trust Store para que la usen las aplicaciones cliente, como Beeline. - La línea
transportModeindica que la solicitud debe enviarse a través de HTTP y proporciona la ruta para el servicio de HiveServer2. La ruta está compuesta por la palabra clavegateway, el nombre de topología que definiste en una sección anterior y el nombre del servicio configurado en la misma topología, en este casohive. - El parámetro
-eproporciona la consulta que se ejecutará en Hive. Si omites este parámetro, abres una sesión interactiva en la herramienta de línea de comandos de Beeline. - El parámetro
-nproporciona una identidad de usuario y una contraseña. En este paso, usas el usuarioadminpredeterminado de Hive. En las siguientes secciones, crearás una identidad de usuario de analista y configurarás credenciales y políticas de autorización para este usuario.
Agrega un usuario al almacén de autenticación
De forma predeterminada, Apache Knox incluye un proveedor de autenticación que se basa en Apache Shiro.
Este proveedor de autenticación se configura con la autenticación BÁSICA en un almacén LDAP de ApacheDS. En esta sección, agregarás una identidad de usuario de analista de datos de muestra sara al almacén de autenticación.
Desde la terminal en el nodo principal del proxy, instala las utilidades de LDAP:
sudo apt-get install ldap-utilsCrea un archivo con formato de intercambio de datos LDAP (LDIF) para el usuario nuevo
sara:export USER_ID=sara printf '%s\n'\ "# entry for user ${USER_ID}"\ "dn: uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org"\ "objectclass:top"\ "objectclass:person"\ "objectclass:organizationalPerson"\ "objectclass:inetOrgPerson"\ "cn: ${USER_ID}"\ "sn: ${USER_ID}"\ "uid: ${USER_ID}"\ "userPassword:${USER_ID}-password"\ > new-user.ldifAgregue el ID de usuario al directorio LDAP:
ldapadd -f new-user.ldif \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389El parámetro
-Despecifica el nombre distinguido (DN) que se debe vincular cuando el usuario que se representa medianteldapaddaccede al directorio. El DN debe ser una identidad de usuario que ya esté en el directorio, en este caso, el usuarioadmin.Verifica que el usuario nuevo esté en el almacén de autenticación:
ldapsearch -b "uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org" \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389Los detalles del usuario aparecen en la terminal.
Copia y guarda el nombre de DNS interno del nodo de la instancia principal del proxy:
hostname -A | tr -d '[:space:]'; echoUsarás este nombre en la siguiente sección como
<proxy-master-internal-dns-name>para configurar la sincronización de LDAP.Sal de la terminal en el nodo:
exit
Configura la autorización
En esta sección, configurarás la sincronización de identidades entre el servicio de LDAP y Ranger.
Sincroniza las identidades de usuario en el Ranger
A fin de asegurarte de que las políticas de Ranger se apliquen a las mismas identidades de usuario que Apache Knox, configura el daemon UserSync Ranger para sincronizar las identidades desde el mismo directorio.
En este ejemplo, te conectarás al directorio LDAP local que está disponible de forma predeterminada con Apache Knox. Sin embargo, en un entorno de producción, recomendamos que configures un directorio de identidad externo. Para obtener más información, consulta la guía del usuario de Apache Knox y Cloud Identity de Google Cloud, Active Directory administrado y AD federado.
Mediante SSH, conéctate al nodo principal del clúster de backend que creaste:
export BACKEND_CLUSTER=backend-cluster gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mEn la terminal, edita el archivo de configuración
UserSync:sudo vi /etc/ranger/usersync/conf/ranger-ugsync-site.xmlEstablece los valores de las siguientes propiedades de LDAP. Asegúrate de modificar las propiedades
user, y no las propiedadesgroup, que tienen nombres similares.<property> <name>ranger.usersync.sync.source</name> <value>ldap</value> </property> <property> <name>ranger.usersync.ldap.url</name> <value>ldap://<proxy-master-internal-dns-name>:33389</value> </property> <property> <name>ranger.usersync.ldap.binddn</name> <value>uid=admin,ou=people,dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.ldap.ldapbindpassword</name> <value>admin-password</value> </property> <property> <name>ranger.usersync.ldap.user.searchbase</name> <value>dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.source.impl.class</name> <value>org.apache.ranger.ldapusersync.process.LdapUserGroupBuilder</value> </property>Reemplaza el marcador de posición
<proxy-master-internal-dns-name>por el nombre de DNS interno del servidor proxy, que recuperaste en la última sección.Estas propiedades son un subconjunto de una configuración LDAP completa que sincroniza usuarios y grupos. Para obtener más información, consulta Cómo integrar Ranger a LDAP.
Guarda el archivo y cierra el editor.
Reinicia el daemon
ranger-usersync:sudo service ranger-usersync restartEjecuta el siguiente comando:
grep sara /var/log/ranger-usersync/*Si las identidades están sincronizadas, verás al menos una línea de registro del usuario
sara.
Crea políticas de Ranger
En esta sección, configurarás un servicio de Hive nuevo en Ranger. También puedes configurar y probar una política de Ranger a fin de limitar el acceso a los datos de Hive para una identidad específica.
Configura el servicio de Ranger
Desde la terminal del nodo principal, edita la configuración de Ranger Hive:
sudo vi /etc/hive/conf/ranger-hive-security.xmlEdita la propiedad
<value>de la propiedadranger.plugin.hive.service.name:<property> <name>ranger.plugin.hive.service.name</name> <value>ranger-hive-service-01</value> <description> Name of the Ranger service containing policies for this YARN instance </description> </property>Guarda el archivo y cierra el editor.
Reinicia el servicio de administrador de HiveServer2:
sudo service hive-server2 restartEstás listo para crear políticas de Ranger.
Configura el servicio en la Consola del administrador de Ranger
En la consola de Google Cloud, ve a la página Dataproc.
Haz clic en el nombre del clúster de backend y, luego, en Interfaces web.
Debido a que creaste tu clúster con Puerta de enlace de componentes, verás una lista de los componentes de Hadoop que están instalados en tu clúster.
Haz clic en el vínculo Ranger para abrir la consola de Ranger.
Accede a Ranger con el usuario
adminy la contraseña de administrador de Ranger. La consola de Ranger muestra la página Administrador de servicio con una lista de servicios.Haz clic en el signo más en el grupo HIVE para crear un nuevo servicio de Hive.

En el formulario, configure los siguientes valores:
- Nombre del servicio:
ranger-hive-service-01. Ya definiste este nombre en el archivo de configuraciónranger-hive-security.xml. - Nombre de usuario:
admin - Contraseña:
admin-password jdbc.driverClassName: conserva el nombre predeterminado comoorg.apache.hive.jdbc.HiveDriver.jdbc.url:jdbc:hive2:<backend-master-internal-dns-name>:10000/;transportMode=http;httpPath=cliservice- Reemplaza el marcador de posición
<backend-master-internal-dns-name>por el nombre que recuperaste en una sección anterior.
- Nombre del servicio:
Haga clic en Add.
La instalación de cada complemento de Ranger admite un solo servicio de Hive. Una forma sencilla de configurar los servicios de Hive adicionales es iniciar clústeres de backend adicionales. Cada clúster tiene su propio complemento Ranger. Estos clústeres pueden compartir la misma base de datos de Ranger para que tengas una vista unificada de todos los servicios cada vez que accedas a la Consola del administrador de Ranger desde cualquiera de esos clústeres.
Configura una política de Ranger con permisos limitados
La política permite que el usuario LDAP analista de muestra sara acceda a las columnas específicas de la tabla de Hive.
En la ventana del Administrador de servicios, haz clic en el nombre del servicio que creaste.
La Consola del administrador de Ranger muestra la ventana Políticas.
Haz clic en AGREGAR POLÍTICA NUEVA.
Con esta política, le otorgas a
sarael permiso para ver solo las columnassubmissionDateytransactionTypede las transacciones de la tabla.En el formulario, configure los siguientes valores:
- Nombre de la política: cualquier nombre, por ejemplo
allow-tx-columns - Base de datos:
default - Tabla:
transactions - Columna de Hive:
submissionDate, transactionType - Condiciones de permiso:
- Seleccionar usuario:
sara - Permisos:
select
- Seleccionar usuario:
- Nombre de la política: cualquier nombre, por ejemplo
En la parte inferior de la pantalla, haz clic en Agregar.
Prueba la política con Beeline
En la terminal del nodo principal, inicia la herramienta de línea de comandos de Beeline con el usuario
sara.beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice sara user-password"Aunque la herramienta de línea de comandos de Beeline no aplica la contraseña, debes proporcionar una contraseña para ejecutar el comando anterior.
Ejecuta la siguiente consulta para verificar que Ranger la bloquee.
SELECT * FROM transactions LIMIT 10;La consulta incluye la columna
transactionAmount, quesarano tiene permiso para seleccionar.Aparecerá un error
Permission denied.Verifica que Ranger permita la siguiente consulta:
SELECT submissionDate, transactionType FROM transactions LIMIT 10;Sal de la herramienta de línea de comandos de Beeline:
!quitSal de la terminal:
exitEn la consola de Ranger, haz clic en la pestaña Auditoría. Se muestran los eventos denegados y permitidos. Puedes filtrar los eventos por el nombre del servicio que definiste antes, por ejemplo,
ranger-hive-service-01.
Conéctate desde una herramienta IE
El último paso de este instructivo es consultar los datos de Hive desde Tableau Desktop.
Crea una regla de firewall
- Copia y guarda tu dirección IP pública.
En Cloud Shell, crea una regla de firewall que abra el puerto TCP
8443para la entrada desde la estación de trabajo:gcloud compute firewall-rules create allow-knox\ --project=${PROJECT_ID} --direction=INGRESS --priority=1000 \ --network=default --action=ALLOW --rules=tcp:8443 \ --target-tags=knox-gateway \ --source-ranges=<your-public-ip>/32Reemplaza el marcador de posición
<your-public-ip>por tu dirección IP pública.Aplica la etiqueta de red de la regla de firewall al nodo principal del clúster del proxy:
gcloud compute instances add-tags ${PROXY_CLUSTER}-m --zone=${ZONE} \ --tags=knox-gateway
Crea un túnel SSH
Este procedimiento solo es necesario si usas un certificado autofirmado válido para localhost. Si usas tu propio certificado o tu nodo principal de proxy tiene su propio nombre DNS externo, puedes pasar a Conectar a Hive.
En Cloud Shell, genera el siguiente comando para crear el túnel:
echo "gcloud compute ssh ${PROXY_CLUSTER}-m \ --project ${PROJECT_ID} \ --zone ${ZONE} \ -- -L 8443:localhost:8443"Ejecuta
gcloud initpara autenticar tu cuenta de usuario y otorgar permisos de acceso.Abre una terminal en tu estación de trabajo.
Crea un túnel SSH para reenviar el puerto
8443. Copia el comando generado en el primer paso, pégalo en la terminal de la estación de trabajo y, luego, ejecuta el comando.Deja la terminal abierta para que el túnel permanezca activo.
Conéctate a Hive
- En tu estación de trabajo, instala el controlador ODBC de Hive.
- Abra Tableau Desktop o reinícielo si estaba abierto.
- En la página principal, en Conectar / A un servidor, selecciona Más.
- Busca y, luego, selecciona Cloudera Hadoop.
Con el usuario LDAP
saradel analista de datos de muestra como identidad del usuario, completa los campos de la siguiente manera:- Servidor: Si creaste un túnel, usa
localhost. Si no creaste un túnel, usa el nombre de DNS externo del nodo de tu instancia principal del proxy. - Puerto
8443 - Tipo:
HiveServer2 - Autenticación:
UsernameyPassword - Nombre de usuario:
sara - Contraseña:
sara-password - Ruta de acceso HTTP:
gateway/hive-us-transactions/hive - Exigir SSL:
yes
- Servidor: Si creaste un túnel, usa
Haz clic en Acceder (Sign In).

Consulta datos de Hive
- En la pantalla Fuente de datos, haz clic en Seleccionar esquema y busca
default. Haz doble clic en el nombre del esquema
default.Se cargará el panel Tabla.
En el panel Tabla, haz doble clic en Nuevo SQL personalizado.
Se abrirá la ventana Editar SQL personalizado.
Ingresa la siguiente consulta, en la que se selecciona la fecha y el tipo de transacción de la tabla de transacciones:
SELECT `submissiondate`, `transactiontype` FROM `default`.`transactions`Haz clic en Aceptar.
Los metadatos de la consulta se recuperan de Hive.
Haz clic en Actualizar ahora.
Tableau recupera los datos de Hive porque
saraestá autorizada para leer estas dos columnas de la tablatransactions.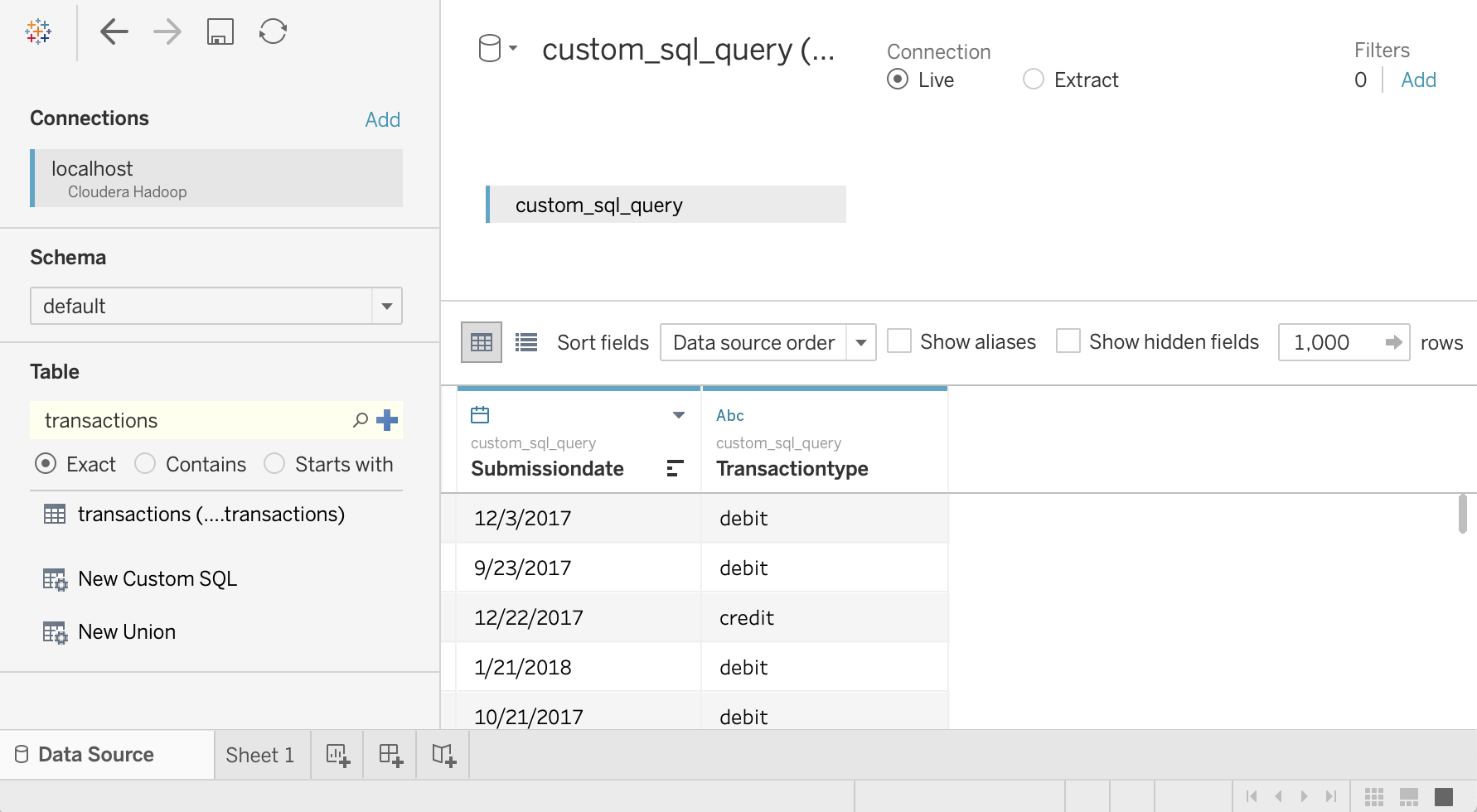
Para intentar seleccionar todas las columnas de la tabla
transactions, en el panel Tabla, vuelve a hacer doble clic en Nuevo SQL personalizado. Se abrirá la ventana Editar SQL personalizado.Ingrese la siguiente consulta:
SELECT * FROM `default`.`transactions`Haga clic en OK. Se muestra el siguiente mensaje de error:
Permission denied: user [sara] does not have [SELECT] privilege on [default/transactions/*].Debido a que
sarano tiene autorización de Ranger para leer la columnatransactionAmount, se espera este mensaje. En este ejemplo, se muestra cómo puedes limitar los datos a los que pueden acceder los usuarios de Tableau.Para ver todas las columnas, repite los pasos con el usuario
admin.Cierra Tableau y tu ventana de la terminal.
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el proyecto
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
¿Qué sigue?
- Lee la primera parte de esta serie: Arquitectura para conectar un software de visualización a Hadoop en Google Cloud.
- Lee la guía de seguridad de migración de Hadoop.
- Aprende a migrar trabajos de Apache Spark a Dataproc.
- Aprende a migrar la infraestructura de Hadoop local a Google Cloud.
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.