SQL 쿼리를 사용하여 데이터를 검색하면 Spanner는 데이터를 더 효율적으로 검색하는 데 도움이 되는 모든 보조 색인을 자동으로 사용합니다. 하지만 Spanner에서 쿼리 속도가 느려질 수 있는 색인을 선택하는 경우도 있습니다. 따라서 일부 쿼리는 이전에 실행한 쿼리보다 느리게 실행됩니다.
이 페이지에서는 쿼리 실행 속도의 변화를 감지하는 방법, 쿼리에 대한 쿼리 실행 계획 검사, 필요한 경우 향후 쿼리에 다른 색인을 지정하는 방법을 설명합니다.
쿼리 실행 속도 변경 감지
다음 중 한 가지를 변경하면 쿼리 실행 속도가 변경될 수 있습니다.
- 보조 색인이 있는 많은 양의 기존 데이터를 대폭 변경.
- 보조 색인 추가, 변경 또는 삭제.
여러 다른 도구를 사용하여 Spanner가 평소보다 느리게 실행되는 특정 쿼리를 식별할 수 있습니다.
- 쿼리 통계 및 쿼리 통계
Cloud Monitoring으로 캡처하고 분석하는 애플리케이션 별 측정항목. 예를 들어 쿼리 수 측정항목을 모니터링하여 시간 경과에 따른 인스턴스의 쿼리 수를 확인하고 쿼리를 실행하는 데 사용되는 쿼리 최적화 도구 버전을 확인할 수 있습니다.
애플리케이션의 성능을 측정하는 클라이언트 측 모니터링 도구.
새 데이터베이스 참고사항
쿼리 옵티마이저가 옵티마이저 통계를 자동으로 수집하는 데 최대 3일이 걸리기 때문에 새로 삽입되거나 가져온 데이터가 있는 새로 생성된 데이터베이스를 쿼리할 경우 Spanner는 가장 적합한 색인을 선택하지 못할 수 있습니다. 이보다 이전의 새로운 Spanner 데이터베이스의 색인 사용을 최적화하려면 새 통계 패키지를 수동으로 구성하면 됩니다.
스키마 검토
속도가 느린 쿼리를 찾은 후 쿼리에 대한 SQL 문을 살펴보고 해당 구문에서 사용하는 테이블과 이러한 테이블에서 검색하는 열을 확인합니다.
다음으로 이 테이블에 대한 보조 색인을 찾습니다. 쿼리 중인 열이 색인에 포함되어 있는지 확인합니다. 즉, Spanner에서 색인 중 하나를 사용하여 쿼리를 처리할 수 있습니다.
- 적용 가능한 색인이 있는 경우 다음 단계는 Spanner에서 쿼리에 사용한 색인 찾기입니다.
적용 가능한 색인이 없는 경우,
gcloud spanner operations list명령어를 사용하여 최근에 해당 색인을 삭제했는지 확인합니다.gcloud spanner operations list \ --instance=INSTANCE \ --database=DATABASE \ --filter="@TYPE:UpdateDatabaseDdlMetadata"해당 색인을 삭제한 경우 쿼리 성능에 영향을 미칠 수 있습니다. 보조 색인을 테이블에 다시 추가합니다. Spanner에서 색인을 추가한 후 쿼리를 다시 실행하고 성능을 확인합니다. 성능이 개선되지 않으면 다음 단계는 Spanner에서 쿼리에 사용한 색인을 찾는 것입니다.
적용 가능한 색인을 삭제하지 않은 경우, 색인 선택으로 인해 쿼리 성능이 회귀하지 않습니다. 성능에 영향을 미칠 수 있는 데이터 또는 사용 패턴의 다른 변경 사항을 찾습니다.
쿼리에 사용된 색인 찾기
Spanner가 쿼리 처리에 사용하는 색인을 확인하려면 Google Cloud 콘솔에서 쿼리 실행 계획을 확인하세요.
Google Cloud 콘솔에서 Spanner 인스턴스 페이지로 이동합니다.
쿼리할 인스턴스의 이름을 클릭합니다.
왼쪽 창에서 쿼리할 데이터베이스를 클릭한 후 Spanner 스튜디오를 클릭합니다.
테스트할 쿼리를 입력합니다.
쿼리 실행 드롭다운 목록에서 설명만을 선택합니다. Spanner가 쿼리 계획을 표시합니다.
쿼리 계획에서 다음 연산자 중 적어도 하나를 찾습니다.
- 테이블 스캔
- 색인 스캔
- 교차 적용 또는 분산 교차 적용
다음 섹션에서는 각 연산자의 의미를 설명합니다.
테이블 스캔 연산자
테이블 스캔 연산자는 Spanner가 보조 색인을 사용하지 않았음을 나타냅니다.
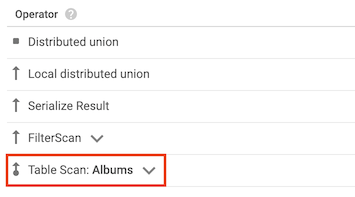
예를 들어 Albums 테이블에 보조 색인이 없으면 다음 쿼리를 실행합니다.
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
사용할 인덱스가 없으므로 쿼리 계획에는 테이블 검색 연산자가 포함됩니다.
색인 스캔 연산자
색인 스캔 연산자는 Spanner가 쿼리를 처리할 때 보조 색인을 사용했음을 나타냅니다.
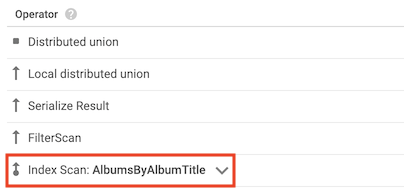
예를 들어 Albums 테이블에 색인을 추가했다고 가정합니다.
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
이어서 다음 쿼리를 실행합니다.
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
AlbumsByAlbumTitle 색인은 쿼리가 선택하는 유일한 열인 AlbumTitle를 포함합니다. 결과적으로 쿼리 계획에는 색인 스캔 연산자가 포함됩니다.
교차 적용 연산자
경우에 따라 Spanner는 쿼리에서 선택하는 일부 열만 포함하는 색인을 사용합니다. 따라서 Spanner는 인덱스를 기본 테이블과 조인해야 합니다.
이러한 조인 유형이 발생하면 쿼리 계획은 다음 입력을 갖는 교차 적용 또는 분산 교차 적용 연산자를 호출합니다.
- 테이블 색인의 색인 스캔 연산자
- 색인을 소유한 테이블의 테이블 스캔 연산자입니다.
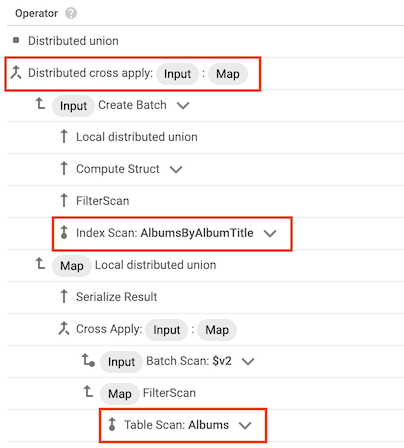
예를 들어 Albums 테이블에 색인을 추가했다고 가정합니다.
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
이어서 다음 쿼리를 실행합니다.
SELECT * FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
AlbumsByAlbumTitle 색인은 AlbumTitle을 포함하지만 쿼리는 AlbumTitle을 제외한 테이블의 모든 열을 선택합니다. 결과적으로 쿼리 계획에는 AlbumsByAlbumTitle 인덱스 스캔 및 Albums 테이블 스캔을 입력으로 사용하는 분산 교차 적용 연산자가 포함됩니다.
다른 색인 선택
Spanner에서 사용자의 쿼리에 사용한 색인을 찾은 후 다른 색인을 사용하거나 색인 대신 기본 테이블을 스캔하여 쿼리를 실행해 봅니다. 색인을 지정하려면 쿼리에 FORCE_INDEX 지시문을 추가합니다.
더 빠른 버전의 쿼리를 찾으면 빠른 버전을 사용하도록 애플리케이션을 업데이트합니다.
색인 선택 가이드라인
다음 가이드라인을 사용하여 쿼리를 테스트할 색인을 결정합니다.
쿼리가 다음 기준 중 하나라도 충족하는 경우 보조 색인 대신 기본 테이블을 사용해 보세요.
- 쿼리가 기본 테이블의 기본 키 프리픽스와 같은지 확인합니다(예:
SELECT * FROM Albums WHERE SingerId = 1). - 많은 수의 행이 쿼리 조건부를 충족합니다(예:
SELECT * FROM Albums WHERE AlbumTitle != "There Is No Album With This Title"). - 쿼리가 수백 개의 행만 포함하는 기본 테이블을 사용합니다.
- 쿼리가 기본 테이블의 기본 키 프리픽스와 같은지 확인합니다(예:
쿼리가 매우 선택적인 조건자(예:
REGEXP_CONTAINS,STARTS_WITH,<,<=,>,>=또는!=)만 포함하는 경우, 조건자가 사용하는 것과 동일한 열을 포함하는 색인을 사용해 봅니다.
업데이트된 쿼리 테스트
Google Cloud 콘솔을 사용하여 업데이트된 쿼리를 테스트하고 쿼리를 처리하는 데 걸리는 시간을 확인합니다.
쿼리 매개변수가 쿼리 매개변수를 포함하고 쿼리 매개변수가 일부 값에 다른 값보다 더 자주 결합되는 경우, 쿼리 매개변수를 테스트의 값 중 하나로 결합합니다. 예를 들어 쿼리에 WHERE country = @countryId과 같은 조건자를 포함하면, 거의 모든 쿼리는 @countryId를 US에 결합하고, 성능 테스트를 위해 @countryId를 US에 결합합니다. 이 방법을 사용하면 가장 자주 실행하는 쿼리를 최적화할 수 있습니다.
Google Cloud 콘솔에서 업데이트된 쿼리를 테스트하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 Spanner 인스턴스 페이지로 이동합니다.
쿼리할 인스턴스의 이름을 클릭합니다.
왼쪽 창에서 쿼리할 데이터베이스를 클릭한 후 Spanner 스튜디오를 클릭합니다.
FORCE_INDEX지시문을 포함해 테스트할 쿼리를 입력하고 쿼리 실행을 클릭합니다.Google Cloud 콘솔은 결과 테이블 탭을 열어 Spanner 서비스가 쿼리를 처리하는 데 걸린 시간이 포함된 쿼리 결과를 표시합니다.
이 측정항목에는 Google Cloud 콘솔이 쿼리 결과를 해석하고 표시하는 데 걸린 시간과 같은 다른 지연 시간 원인이 포함되지 않습니다.
REST API를 사용하여 JSON 형식으로 된 쿼리의 상세 프로필 가져오기
쿼리를 실행하면 기본적으로 구문 결과만 반환됩니다.
이는 QueryMode가 NORMAL로 설정되었기 때문입니다.
쿼리 결과에 자세한 실행 통계를 포함하려면 QueryMode를 PROFILE로 설정합니다.
세션 만들기
쿼리 모드를 업데이트하기 전에 Spanner 데이터베이스 서비스와의 통신 채널을 나타내는 세션을 만듭니다.
projects.instances.databases.sessions.create를 클릭합니다.다음 형식으로 프로젝트, 인스턴스, 데이터베이스 ID를 제공합니다.
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]실행을 클릭합니다. 응답은 다음 형식으로 만든 세션을 표시합니다.
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]/sessions/[\SESSION\]이를 사용하여 다음 단계에서 쿼리 프로필을 수행합니다. 생성된 세션은 연속 사용 사이에 최대 1시간 동안 활성 상태가 되고 데이터베이스에 의해 삭제됩니다.
쿼리 프로필 만들기
쿼리에 PROFILE 모드를 사용 설정합니다.
projects.instances.databases.sessions.executeSql을 클릭합니다.세션의 경우 이전 단계에서 만든 세션 ID를 입력하세요.
projects/[PROJECT_ID]/instances/[INSTANCE_ID]/databases/[DATABASE_ID]/sessions/[SESSION]요청 본문에 다음을 사용합니다.
{ "sql": "[YOUR_SQL_QUERY]", "queryMode": "PROFILE" }실행을 클릭합니다. 반환된 응답에는 쿼리 결과, 쿼리 계획, 쿼리의 실행 통계가 포함됩니다.