- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- 사용해 보기 기능은 Spanner API 참조 문서를 참조하세요. 이 페이지에 제시된 예시에서는 사용해 보기 기능을 사용합니다.
- Cloud Spanner API와 기타 Google API를 포함하고 있는 Google API 탐색기
- HTTP REST 호출을 지원하는 기타 도구나 프레임워크
이 예시에서는
[PROJECT_ID]를 Google Cloud 프로젝트 ID로 사용합니다.Google Cloud 프로젝트 ID를[PROJECT_ID]로 대체합니다. 프로젝트 ID에[와]를 포함하지 마세요.이 예에서는
test-instance의 인스턴스 ID를 만들고 사용합니다.test-instance를 사용하지 않는 경우 인스턴스 ID로 대체합니다.이 예시에서는
example-db의 데이터베이스 ID를 만들고 사용합니다.example-db를 사용하지 않는 경우 데이터베이스 ID로 대체합니다.여기에 제시된 예에서는
[SESSION]을 세션 이름의 일부로 사용합니다.[SESSION]을 세션 생성 시 받은 값으로 바꿉니다. 세션 이름에[와]를 포함하지 마세요.여기에 제시된 예시에서는
[TRANSACTION_ID]라는 트랜잭션 ID를 사용합니다.[TRANSACTION_ID]를 트랜잭션 생성 시 받은 값으로 바꾸세요. 트랜잭션 ID에[와]를 포함하지 마세요.사용해 보기 기능은 각 HTTP 요청 필드를 양방향으로 추가하는 기능을 지원합니다. 이 항목에 제시된 대부분의 예시는 각 필드를 요청에 양방향으로 추가하는 방법을 설명하기보다는 전체 요청을 제시합니다.
projects.instanceConfigs.list을 클릭합니다.상위 요소에 다음을 입력합니다.
projects/[PROJECT_ID]실행을 클릭합니다. 이에 대한 응답으로, 사용 가능한 인스턴스 구성이 표시됩니다. 다음은 응답의 예시입니다(사용자의 프로젝트는 이와 다른 인스턴스 구성을 가질 수 있음).
{ "instanceConfigs": [ { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-south1", "displayName": "asia-south1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-east1", "displayName": "asia-east1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-northeast1", "displayName": "asia-northeast1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-europe-west1", "displayName": "europe-west1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-us-east4", "displayName": "us-east4" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-us-central1", "displayName": "us-central1" } ] }projects.instances.create을 클릭합니다.상위 요소에 다음을 입력합니다.
projects/[PROJECT_ID]요청 본문 매개변수 추가를 클릭하고
instance를 선택합니다.인스턴스의 힌트 풍선을 클릭하여 사용할 수 있는 필드를 확인합니다. 다음 필드에 값을 추가합니다.
nodeCount:1를 입력합니다.config: 인스턴스 구성 나열 시 반환되는 리전 인스턴스 구성 중 하나의name값을 입력합니다.displayName:Test Instance를 입력합니다.
인스턴스의 오른쪽 꺾쇠괄호 다음에 오는 힌트 풍선을 클릭하고 instanceId를 선택합니다.
instanceId에test-instance를 입력합니다.
사용해 보기 인스턴스 생성 페이지는 다음과 같이 표시됩니다.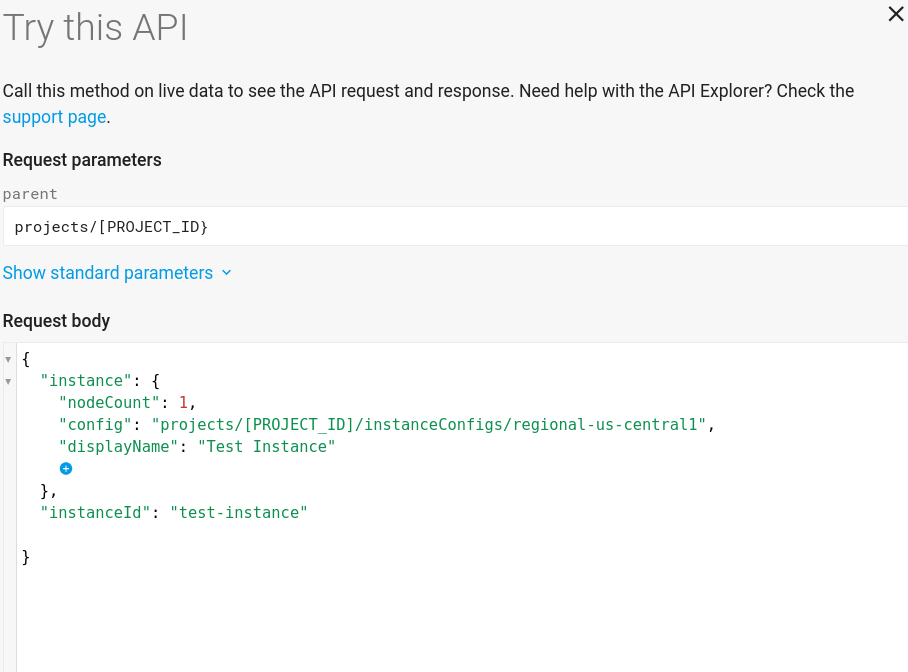
실행을 클릭합니다. 이에 대한 응답으로, 사용자가 쿼리를 통해 상태를 확인할 수 있는 장기 실행 작업이 반환됩니다.
projects.instances.databases.create을 클릭합니다.상위 요소에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance요청 본문 매개변수 추가를 클릭하고
createStatement를 선택합니다.createStatement에 다음을 입력합니다.CREATE DATABASE `example-db`데이터베이스 이름,
example-db, 하이픈을 포함하며 백틱(`)으로 묶어 포함해야 합니다.실행을 클릭합니다. 이에 대한 응답으로, 사용자가 쿼리를 통해 상태를 확인할 수 있는 장기 실행 작업이 반환됩니다.
projects.instances.databases.updateDdl을 클릭합니다.데이터베이스에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db요청 본문에 다음을 사용합니다.
{ "statements": [ "CREATE TABLE Singers ( SingerId INT64 NOT NULL, FirstName STRING(1024), LastName STRING(1024), SingerInfo BYTES(MAX) ) PRIMARY KEY (SingerId)", "CREATE TABLE Albums ( SingerId INT64 NOT NULL, AlbumId INT64 NOT NULL, AlbumTitle STRING(MAX)) PRIMARY KEY (SingerId, AlbumId), INTERLEAVE IN PARENT Singers ON DELETE CASCADE" ] }statements배열은 스키마를 정의하는 DDL 구문을 포함합니다.실행을 클릭합니다. 이에 대한 응답으로, 사용자가 쿼리를 통해 상태를 확인할 수 있는 장기 실행 작업이 반환됩니다.
projects.instances.databases.sessions.create을 클릭합니다.데이터베이스에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db실행을 클릭합니다.
이에 대한 응답으로, 사용자가 만든 세션이 다음과 같은 형태로 표시됩니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]데이터베이스를 읽거나 쓸 때 이 세션을 사용하게 됩니다.
projects.instances.databases.sessions.commit을 클릭합니다.세션에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](세션 만들기에서 이 값을 받습니다.)
요청 본문에 다음을 사용합니다.
{ "singleUseTransaction": { "readWrite": {} }, "mutations": [ { "insertOrUpdate": { "table": "Singers", "columns": [ "SingerId", "FirstName", "LastName" ], "values": [ [ "1", "Marc", "Richards" ], [ "2", "Catalina", "Smith" ], [ "3", "Alice", "Trentor" ], [ "4", "Lea", "Martin" ], [ "5", "David", "Lomond" ] ] } }, { "insertOrUpdate": { "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "values": [ [ "1", "1", "Total Junk" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "2", "Forever Hold Your Peace" ], [ "2", "3", "Terrified" ] ] } } ] }실행을 클릭합니다. 이에 대한 응답으로, 커밋 타임스탬프가 표시됩니다.
projects.instances.databases.sessions.executeSql을 클릭합니다.세션에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](세션 만들기에서 이 값을 받습니다.)
요청 본문에 다음을 사용합니다.
{ "sql": "SELECT SingerId, AlbumId, AlbumTitle FROM Albums" }실행을 클릭합니다. 이에 대한 응답으로, 쿼리 결과가 표시됩니다.
projects.instances.databases.sessions.read을 클릭합니다.세션에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](세션 만들기에서 이 값을 받습니다.)
요청 본문에 다음을 사용합니다.
{ "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "keySet": { "all": true } }실행을 클릭합니다. 이에 대한 응답으로, 읽기 결과가 표시됩니다.
projects.instances.databases.updateDdl을 클릭합니다.데이터베이스에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db요청 본문에 다음을 사용합니다.
{ "statements": [ "ALTER TABLE Albums ADD COLUMN MarketingBudget INT64" ] }statements배열은 스키마를 정의하는 DDL 구문을 포함합니다.실행을 클릭합니다. REST 호출이 응답을 반환한 후에도 완료되는 데 몇 분 정도 걸릴 수 있습니다. 이에 대한 응답으로, 사용자가 쿼리를 통해 상태를 확인할 수 있는 장기 실행 작업이 반환됩니다.
projects.instances.databases.sessions.commit을 클릭합니다.세션에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](세션 만들기에서 이 값을 받습니다.)
요청 본문에 다음을 사용합니다.
{ "singleUseTransaction": { "readWrite": {} }, "mutations": [ { "update": { "table": "Albums", "columns": [ "SingerId", "AlbumId", "MarketingBudget" ], "values": [ [ "1", "1", "100000" ], [ "2", "2", "500000" ] ] } } ] }실행을 클릭합니다. 이에 대한 응답으로, 커밋 타임스탬프가 표시됩니다.
projects.instances.databases.sessions.executeSql을 클릭합니다.세션에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](세션 만들기에서 이 값을 받습니다.)
요청 본문에 다음을 사용합니다.
{ "sql": "SELECT SingerId, AlbumId, MarketingBudget FROM Albums" }실행을 클릭합니다. 응답의 일부로 업데이트된
MarketingBudget값이 포함된 두 행이 표시됩니다."rows": [ [ "1", "1", "100000" ], [ "1", "2", null ], [ "2", "1", null ], [ "2", "2", "500000" ], [ "2", "3", null ] ]projects.instances.databases.updateDdl을 클릭합니다.데이터베이스에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db요청 본문에 다음을 사용합니다.
{ "statements": [ "CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle)" ] }실행을 클릭합니다. REST 호출이 응답을 반환한 후에도 완료되는 데 몇 분 정도 걸릴 수 있습니다. 이에 대한 응답으로, 사용자가 쿼리를 통해 상태를 확인할 수 있는 장기 실행 작업이 반환됩니다.
projects.instances.databases.sessions.executeSql을 클릭합니다.세션에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](세션 만들기에서 이 값을 받습니다.)
요청 본문에 다음을 사용합니다.
{ "sql": "SELECT AlbumId, AlbumTitle, MarketingBudget FROM Albums WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo'" }실행을 클릭합니다. 이에 대한 응답의 일부로, 다음 행이 표시됩니다.
"rows": [ [ "2", "Go, Go, Go", null ], [ "2", "Forever Hold Your Peace", "500000" ] ]projects.instances.databases.sessions.read을 클릭합니다.세션에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](세션 만들기에서 이 값을 받습니다.)
요청 본문에 다음을 사용합니다.
{ "table": "Albums", "columns": [ "AlbumId", "AlbumTitle" ], "keySet": { "all": true }, "index": "AlbumsByAlbumTitle" }실행을 클릭합니다. 이에 대한 응답의 일부로, 다음 행이 표시됩니다.
"rows": [ [ "2", "Forever Hold Your Peace" ], [ "2", "Go, Go, Go" ], [ "1", "Green" ], [ "3", "Terrified" ], [ "1", "Total Junk" ] ]projects.instances.databases.updateDdl을 클릭합니다.데이터베이스에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db요청 본문에 다음을 사용합니다.
{ "statements": [ "CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget)" ] }실행을 클릭합니다. REST 호출이 응답을 반환한 후에도 완료되는 데 몇 분 정도 걸릴 수 있습니다. 이에 대한 응답으로, 사용자가 쿼리를 통해 상태를 확인할 수 있는 장기 실행 작업이 반환됩니다.
projects.instances.databases.sessions.read을 클릭합니다.세션에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](세션 만들기에서 이 값을 받습니다.)
요청 본문에 다음을 사용합니다.
{ "table": "Albums", "columns": [ "AlbumId", "AlbumTitle", "MarketingBudget" ], "keySet": { "all": true }, "index": "AlbumsByAlbumTitle2" }실행을 클릭합니다. 이에 대한 응답의 일부로, 다음 행이 표시됩니다.
"rows": [ [ "2", "Forever Hold Your Peace", "500000" ], [ "2", "Go, Go, Go", null ], [ "1", "Green", null ], [ "3", "Terrified", null ], [ "1", "Total Junk", "100000" ] ]projects.instances.databases.sessions.beginTransaction을 클릭합니다.세션에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]요청 본문에 다음을 사용합니다.
{ "options": { "readOnly": {} } }실행을 클릭합니다.
이에 대한 응답으로, 사용자가 만든 트랜잭션의 ID가 표시됩니다.
projects.instances.databases.sessions.executeSql을 클릭합니다.세션에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](세션 만들기에서 이 값을 받습니다.)
요청 본문에 다음을 사용합니다.
{ "sql": "SELECT SingerId, AlbumId, AlbumTitle FROM Albums", "transaction": { "id": "[TRANSACTION_ID]" } }실행을 클릭합니다. 이에 대한 응답으로 다음과 비슷한 행이 표시됩니다.
"rows": [ [ "2", "2", "Forever Hold Your Peace" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "3", "Terrified" ], [ "1", "1", "Total Junk" ] ]projects.instances.databases.sessions.read을 클릭합니다.세션에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](세션 만들기에서 이 값을 받습니다.)
요청 본문에 다음을 사용합니다.
{ "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "keySet": { "all": true }, "transaction": { "id": "[TRANSACTION_ID]" } }실행을 클릭합니다. 이에 대한 응답으로 다음과 비슷한 행이 표시됩니다.
"rows": [ [ "1", "1", "Total Junk" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "2", "Forever Hold Your Peace" ], [ "2", "3", "Terrified" ] ]projects.instances.databases.dropDatabase을 클릭합니다.이름에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance/databases/example-db실행을 클릭합니다.
projects.instances.delete을 클릭합니다.이름에 다음을 입력합니다.
projects/[PROJECT_ID]/instances/test-instance실행을 클릭합니다.
REST 호출 방법
다음을 사용하여 Spanner REST를 호출할 수 있습니다.
이 페이지에서 사용하는 규칙
인스턴스
Spanner를 처음 사용할 때는 인스턴스를 만들어야 합니다. 이 인스턴스는 Spanner 데이터베이스에서 사용하는 리소스를 할당한 것입니다. 인스턴스를 만들 때 데이터가 저장되는 위치와 인스턴스의 컴퓨팅 용량을 선택합니다.
인스턴스 구성 나열
인스턴스를 만들 때 해당 인스턴스에 있는 데이터베이스의 지리적 위치와 복제를 정의하는 인스턴스 구성을 지정합니다. 한 리전에 데이터를 저장하는 리전 구성이나 여러 지역에 데이터를 분산하는 멀티 리전 구성을 선택할 수 있습니다. 인스턴스에서 자세히 알아보세요.
projects.instanceConfigs.list를 사용하여 Google Cloud 프로젝트에 사용 가능한 구성을 파악합니다.
인스턴스를 만들 때 인스턴스 구성 중 하나의 name 값을 사용합니다.
인스턴스 만들기
projects.instances.list를 사용하여 인스턴스를 나열할 수 있습니다.
데이터베이스 만들기
example-db라는 데이터베이스를 만듭니다.
projects.instances.databases.list를 사용하여 데이터베이스를 나열할 수 있습니다.
스키마 만들기
Spanner의 데이터 정의 언어(DDL)를 사용하여 테이블을 만들거나 변경하거나 삭제하고 색인을 만들거나 삭제합니다.
이 스키마는 기본 음악 애플리케이션용 테이블 두 개(Singers 및 Albums)를 정의합니다. 이러한 테이블은 이 페이지 전체에서 사용됩니다. 스키마 예시를 아직 보지 않았다면 살펴보세요.
projects.instances.databases.getDdl을 사용하여 스키마를 검색할 수 있습니다.
세션 만들기
데이터를 추가, 업데이트, 삭제 또는 쿼리하려면 먼저 Spanner 데이터베이스 서비스와의 통신 채널을 의미하는 세션을 만들어야 합니다. Spanner 클라이언트 라이브러리를 사용할 경우 클라이언트 라이브러리가 개발자를 대신하여 세션을 관리하므로 개발자가 직접 세션을 사용하지 않습니다.
세션은 오랫동안 유지됩니다. Spanner 데이터베이스 서비스는 1시간 넘게 유휴 상태인 세션을 삭제할 수 있습니다. 삭제된 세션을 사용하려고 하면 NOT_FOUND가 나타납니다. 이 오류가 발생하면 새 세션을 만들어 사용합니다. projects.instances.databases.sessions.get을 사용하여 세션이 아직 사용 중인지 확인할 수 있습니다.
이와 관련된 내용은 유휴 상태의 세션을 활성 상태로 유지하기를 참조하세요.
다음 단계는 데이터베이스에 데이터를 쓰는 것입니다.
데이터 쓰기
Mutation 유형을 사용하여 데이터를 씁니다. Mutation은 변형 작업의 컨테이너입니다. Mutation은 Spanner 데이터베이스의 여러 행과 테이블에 원자적으로 적용될 수 있는 일련의 삽입, 업데이트, 삭제, 기타 작업을 나타냅니다.
이 예시에서는 insertOrUpdate를 사용했습니다. Mutations의 다른 작업은 insert, update, replace, delete입니다.
데이터 유형을 인코딩하는 방법은 TypeCode를 참조하세요.
SQL을 사용하여 데이터 쿼리
읽기 API를 사용하여 데이터 읽기
데이터베이스 스키마 업데이트
Albums 테이블에 MarketingBudget이라는 새 열을 추가해야 한다고 가정합니다. 여기에서 데이터베이스 스키마를 업데이트해야 합니다. Spanner는 데이터베이스에서 트래픽이 계속 처리되는 동안 스키마를 데이터베이스로 업데이트할 수 있습니다. 스키마를 업데이트할 때 데이터베이스를 오프라인으로 전환할 필요가 없고 전체 표 또는 열을 잠그지 않습니다. 따라서 스키마 업데이트 중에도 데이터베이스에 데이터를 계속 쓸 수 있습니다.
열 추가
새 열에 데이터 쓰기
다음 코드는 새 열에 데이터를 씁니다. 이 코드는 MarketingBudget을 Albums(1, 1)로 키가 지정된 행에서는 100000으로, Albums(2, 2)로 키가 지정된 행에서는 500000으로 설정합니다.
방금 쓴 값을 가져오기 위해 SQL 쿼리 또는 읽기 호출을 실행할 수도 있습니다.
다음은 쿼리를 실행하는 방법입니다.
보조 색인 사용
Albums에서 특정 범위의 AlbumTitle 값이 있는 모든 행을 가져오려고 한다고 가정합니다. SQL 문 또는 읽기 호출을 사용하여 AlbumTitle 열에서 모든 값을 읽은 다음 기준을 충족하지 않는 행을 삭제할 수 있지만 이렇게 전체 테이블 스캔을 수행하는 것은 비용이 많이 들며, 특히 많은 행이 있는 테이블의 경우에는 더욱 그렇습니다. 대신 테이블에 보조 색인을 만들어 기본 키가 아닌 열로 검색하면 행을 빠르게 검색할 수 있습니다.
기존 테이블에 보조 색인을 추가하려면 스키마를 업데이트해야 합니다. 다른 스키마 업데이트와 같이 Spanner는 데이터베이스에서 트래픽이 계속 처리되는 동안 색인을 추가할 수 있습니다. Spanner는 기존 데이터로 색인을 자동 백필합니다. 백필을 완료하는 데 몇 분 정도 걸릴 수 있지만 이 프로세스가 진행되는 동안 데이터베이스를 오프라인으로 전환하거나 특정 테이블 또는 열에 대한 쓰기를 금지할 필요는 없습니다. 자세한 내용은 색인 백필을 참조하세요.
보조 색인을 추가하고 나면 Spanner는 보조 색인 사용 시 더 빨리 실행될 가능성이 높은 SQL 쿼리에 자동으로 보조 색인을 사용합니다. 읽기 인터페이스를 사용하는 경우에는 사용할 색인을 지정해야 합니다.
보조 색인 추가
updateDdl을 사용하여 색인을 추가할 수 있습니다.
색인을 사용하여 쿼리
색인을 사용하여 읽기
STORING 절을 포함하는 색인 추가
위의 읽기 예시에서는 MarketingBudget 열 읽기가 포함되지 않았습니다. 이는 Spanner의 읽기 인터페이스가 색인에 저장되지 않은 값을 찾기 위해 색인을 데이터 테이블에 조인하는 기능을 지원하지 않기 때문입니다.
색인에 MarketingBudget 사본을 저장하는 AlbumsByAlbumTitle 대체 정의를 만듭니다.
updateDdl을 사용하여 STORING 색인을 추가할 수 있습니다.
이제 AlbumsByAlbumTitle2 색인의 AlbumId, AlbumTitle, MarketingBudget 열을 모두 가져오는 읽기를 실행할 수 있습니다.
읽기 전용 트랜잭션을 사용하여 데이터 검색
같은 타임스탬프에서 읽기를 하나 이상 실행한다고 가정해 봅시다. 읽기 전용 트랜잭션은 트랜잭션 커밋 기록의 일관적인 접두사를 관찰하므로 애플리케이션이 항상 일관된 데이터를 가져옵니다.
읽기 전용 트랜잭션 만들기
읽기 전용 트랜잭션을 만든 후 데이터가 변경되었더라도 이제 읽기 전용 트랜잭션을 사용하여 일관된 타임스탬프로 데이터를 검색할 수 있습니다.
읽기 전용 트랜잭션을 사용하여 쿼리 실행
읽기 전용 트랜잭션을 사용하여 읽기
Spanner에서는 단일 논리적 시점에 일련의 읽기와 쓰기를 원자적으로 실행하는 읽기-쓰기 트랜잭션도 지원합니다. 자세한 내용은 읽기-쓰기 트랜잭션을 참조하세요. (사용해 보기 기능은 읽기-쓰기 트랜잭션을 시연하는 데 적합하지 않습니다.)
삭제
이 튜토리얼에서 사용한 리소스에 대한 추가 비용이 Google Cloud 계정에 청구되지 않도록 하려면 데이터베이스와 새로 만든 인스턴스를 삭제합니다.