Auf dieser Seite werden verschiedene Möglichkeiten zur Implementierung der Mehrmandantenfähigkeit in Spanner beschrieben. Außerdem werden Datenverwaltungsmuster und die Verwaltung des Mandantenlebenszyklus erläutert. Es richtet sich an Datenbankarchitekten, Datenarchitekten und Entwickler, die Mehrmandantenanwendungen in Spanner als relationale Datenbanken implementieren. In diesem Kontext werden verschiedene Ansätze zum Speichern von Mehrmandantendaten beschrieben. Die Begriffe "Mandant", "Kunde" und "Organisation" werden im gesamten Artikel gleichbedeutend verwendet, um die Entität anzugeben, die auf die Mehrmandantenanwendung zugreift. Die Beispiele auf dieser Seite basieren auf der Implementierung der mehrmandantenfähigen Anwendung eines HR-SaaS-Anbieters (Human Resources) auf Google Cloud. Eine Anforderung ist, dass mehrere Kunden des HR-SaaS-Anbieters auf die mehrmandantenfähige Anwendung zugreifen müssen. Diese Kunden werden als Mandanten bezeichnet.
Mehrinstanzenfähigkeit
Die Mehrmandantenfähigkeit bezeichnet die Option, eine einzelne Instanz oder mehrere Instanzen einer Softwareanwendung für mehrere Mandanten oder Kunden bereitzustellen. Dieses Softwaremuster kann von einem einzelnen Mandanten oder Kunden auf Hunderte oder Tausende Mandanten skaliert werden. Dieser Ansatz ist ein fundamentaler Bestandteil von Cloud-Computing-Plattformen, bei denen die zugrunde liegende Infrastruktur von mehreren Organisationen gemeinsam genutzt wird.
Stellen Sie sich eine Mehrmandantenfähigkeit als eine Art Partitionierung vor, die auf gemeinsam genutzten Computing-Ressourcen wie z. B. Datenbanken basiert. Eine weitere Analogie wären Mieter in einem Apartmentgebäude: Die Mieter teilen sich die Infrastruktur, z. B. Wasserleitungen und Stromleitungen, aber jeder Mieter hat eigene Räume in einer Wohnung. Die Mehrmandantenfähigkeit ist Teil der meisten, vielleicht sogar von allen SaaS-Anwendungen (Software as a Service).
Spanner ist die vollständig verwaltete, für Unternehmen geeignete, verteilte und konsistente Datenbank von Google Cloud, die die Vorteile des relationalen Datenbankmodells mit nicht-relationaler horizontaler Skalierbarkeit vereint. Spanner nutzt relationale Semantiken – mit Schemas, erzwungenen Datentypen, strikter Konsistenz, ACID-Transaktionen mit mehreren Anweisungen und einer SQL-Abfragesprache, die ANSI 2011 SQL implementiert. Es vermeidet Ausfallzeiten bei geplanten Wartungsarbeiten oder Regionalfehlern und bietet ein Verfügbarkeits-SLA von 99, 999%. Spanner unterstützt auch moderne Mehrmandantenanwendungen durch hohe Verfügbarkeit und Skalierbarkeit.
Überlegungen zu Kriterien zum Mandanten-Datenabgleich
In einer Mehrmandantenanwendung sind die Daten jedes Mandanten in einem von mehreren Architekturansätzen in der zugrundeliegenden Spanner-Datenbank isoliert. In folgender Liste werden die verschiedenen Architekturansätze dargestellt, mit denen die Daten eines Mandanten Spanner zugeordnet werden:
- Instanz: Mandanten befinden sich ausschließlich in einer Spanner-Instanz, mit genau einer Datenbank pro Mandant.
- Datenbank: Mandanten befinden sich in einer Datenbank in einer einzelnen Spanner-Instanz mit mehreren Datenbanken.
- Tabelle:Mandanten befinden sich in exklusiven Tabellen innerhalb einer Datenbank; es können mehrere Mandanten in derselben Datenbank sein.
- Zeile:Mandantendaten sind Zeilen in Datenbanktabellen. Diese Tabellen werden für andere Mandanten freigegeben.
Die vorherigen Kriterien werden als Datenverwaltungsmuster bezeichnet und im Abschnitt Datenverwaltungsmuster für Mehrmandantenfähigkeit ausführlich erläutert. Diese Diskussion basiert auf folgenden Kriterien:
- Datenisolation:Der Grad der Datenisolation über mehrere Mandanten hinweg ist ein wichtiger Aspekt der Mehrmandantenfähigkeit. Dazu gehört beispielsweise, ob Daten physisch oder logisch getrennt werden müssen und ob unabhängige ACLs (Access Control Lists) für die Daten jedes Mandanten festgelegt werden können. Die Isolation wird durch Entscheidungen bedingt, die für die Kriterien in anderen Kategorien getroffen wurden. Beispielsweise können bestimmte Vorgaben- und Compliance-Anforderungen ein höheres Maß an Isolation erforderlich machen.
- Agilität:Die Einrichtung und Deaktivierung von Aktivitäten für einen Mandanten in Bezug auf das Erstellen von Instanzen, Datenbanken, Tabellen oder Zeilen.
- Vorgänge:Die Verfügbarkeit oder Komplexität der Implementierung von typischen, mandantenspezifischen Datenbankvorgängen und Administrationsaktivitäten. Dazu gehören beispielsweise regelmäßige Wartungs-, Logging-, Sicherungs- oder Notfallwiederherstellungsvorgänge.
- Skalieren: Die Fähigkeit, nahtlos zu skalieren, um zukünftiges Wachstum zu ermöglichen. Die Beschreibung jedes Musters enthält die Anzahl der Mandanten, die das Muster unterstützen kann.
- Leistung:
- Ressourcenisolation: Die Möglichkeit, jedem Mandanten exklusive Ressourcen zuzuweisen, das Noisy Neighbour-Phänomen anzusprechen und allen Mandanten eine vorhersehbare Lese- und Schreibleistung zu ermöglichen.
- Mindestressourcen pro Mandant: Die durchschnittliche Mindestmenge an Ressourcen pro Mandant. Das bedeutet nicht unbedingt, dass Sie für jeden einzelnen Mandanten mindestens diesen Betrag bezahlen müssen, sondern dass Sie für alle N Mandanten zusammen mindestens N * diesen Betrag bezahlen müssen.
- Ressourceneffizienz: Die Möglichkeit, inaktive Ressourcen anderer Mandanten zu nutzen, um die Gesamtkosten zu senken.
- Standortauswahl zur Latenzoptimierung: Die Möglichkeit, für jeden Mandanten eine bestimmte Replikationstopologie auszuwählen, damit die Daten für jeden Mandanten an dem Standort platziert werden können, der die beste Latenz für den Mandanten bietet.
- Vorschriften und Compliance:Die Möglichkeit, die Anforderungen von stark regulierten Branchen und Ländern zu erfüllen, in denen eine vollständige Isolation von Ressourcen und Wartungsvorgängen erforderlich ist. Beispielsweise ist es bei den Anforderungen an den Datenspeicherort für Frankreich erforderlich, dass personenidentifizierbare Informationen ausschließlich physisch in Frankreich gespeichert werden. In der Finanzbranche sind in der Regel vom Kunden verwaltete Verschlüsselungsschlüssel (Customer-Managed Encryption Keys, CMEK) erforderlich und jeder Mandant möchte möglicherweise seinen eigenen Verschlüsselungsschlüssel verwenden.
Die einzelnen Datenverwaltungsmuster, die diesen Kriterien genügen, werden im nächsten Abschnitt detailliert. Verwenden Sie dieselben Kriterien, wenn Sie ein Datenverwaltungsmuster für eine bestimmte Mandantengruppe auswählen.
Mehrmandantenfähigkeit-Datenverwaltungsmuster
In den folgenden Abschnitten werden die vier wichtigsten Datenverwaltungsmuster beschrieben: Instanz, Datenbank, Tabelle und Zeile.
Instanz
Um für eine vollständige Isolation zu sorgen, speichert das Datenverwaltungsmuster der Instanz die Daten jedes Mandanten in einer eigenen Spanner-Instanz und -Datenbank. Eine Spanner-Instanz kann eine oder mehrere Datenbanken haben. In diesem Muster wird nur eine einzelne Datenbank erstellt. Für die zuvor erwähnte HR-Anwendung wird eine separate Spanner-Instanz mit jeweils einer Datenbank pro Kundenorganisation erstellt.
Wie im folgenden Diagramm dargestellt, hat das Datenverwaltungsmuster jeweils einen Mandanten pro Instanz.
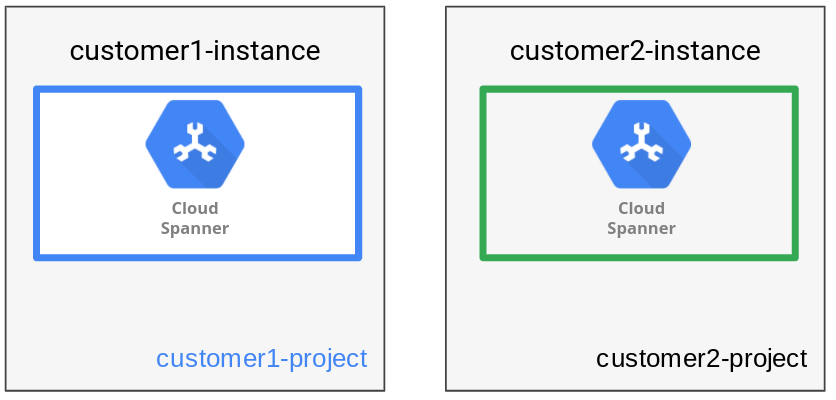
Die Verwendung separater Instanzen für jeden Mandanten ermöglicht die Verwendung separaterGoogle Cloud -Projekte, um für die einzelnen Mandanten separate Vertrauensgrenzen zu erzielen. Ein weiterer Vorteil besteht darin, dass jede Instanzkonfiguration basierend auf dem Standort jedes Mandanten ausgewählt werden kann (entweder regional oder multiregional), wodurch die Flexibilität und Leistung des Standorte optimiert werden.
Die Architektur kann auf eine beliebige Anzahl von Mandanten skaliert werden. SaaS-Anbieter können eine beliebige Anzahl an Instanzen in den gewünschten Regionen erstellen, ohne echte Beschränkungen.
Die folgende Tabelle zeigt, wie das Datenverwaltungsmuster "Instanz" verschiedene Kriterien erfüllt.
| Kriterien | Instanz – Ein Mandanten pro Instanz-Datenverwaltungsmuster |
|---|---|
| Datenisolation |
|
| Agilität |
|
| Vorgänge |
|
| Skalieren |
|
| Leistung |
|
| Vorschriften und Compliance-Anforderungen |
|
Die wichtigsten Punkte sind:
- Vorteil: Höchste Isolationsebene
- Nachteil:Höchster operativer Aufwand und möglicherweise höhere Kosten aufgrund des Mindestwerts von 100 Verarbeitungseinheiten pro Mandant. Das Teilen von Ressourcen zwischen Mandanten wird nicht unterstützt.
Das Datenverwaltungsmuster „Instanz“ eignet sich am besten für folgende Szenarien:
- Verschiedene Mandanten sind über eine Vielzahl an Regionen verteilt und erfordern eine lokalisierte Lösung.
- Rechtliche und Compliance-Anforderungen für einige Mandanten erfordern höhere Sicherheitsebenen und Audit-Logs.
- Die Mandantengröße variiert erheblich, sodass die gemeinsame Nutzung von Ressourcen durch Mandanten mit hohem Volumen und hohem Traffic zu Konflikten und gegenseitigen Beeinträchtigungen führen kann.
Datenbank
Im Datenverwaltungsmuster "Datenbank" befindet sich jeder Mandant in einer Datenbank innerhalb einer einzelnen Spanner-Instanz. Mehrere Datenbanken können sich in einer einzelnen Instanz befinden. Wenn eine Instanz für die Anzahl der Mandanten nicht ausreicht, erstellen Sie mehrere Instanzen. Dieses Muster impliziert, dass eine einzelne Spanner-Instanz von mehreren Mandanten gemeinsam genutzt wird.
Spanner hat ein festes Limit von 100 Datenbanken pro Instanz. Dieses Limit bedeutet, dass der SaaS-Anbieter mehrere Spanner-Instanzen erstellen und verwenden muss, falls er auf mehr als 100 Kunden skalieren muss.
Für die Personalwesen-Anwendung erstellt und verwaltet der SaaS-Anbieter jeden Mandanten mit einer separaten Datenbank in einer Spanner-Instanz.
Wie im folgenden Diagramm dargestellt, hat das Datenverwaltungsmuster jeweils einen Mandanten pro Datenbank.

Mit dem Datenverwaltungsmuster "Datenbank" wird die logische Isolation auf Datenbankebene für die Daten verschiedener Mandanten erreicht. Da es sich jedoch um eine einzelne Spanner-Instanz handelt, nutzen alle Mandantendatenbanken die gleiche Replikationstopologie und die zugrunde liegende Compute- und Speichereinrichtung, sofern nicht die Funktion Geopartitionierung verwendet wird. Mit der Spanner-Funktion zur Geopartitionierung können Sie Instanzpartitionen an verschiedenen Standorten erstellen und verschiedene Instanzpartitionen für verschiedene Datenbanken in derselben Instanz verwenden.
Die folgende Tabelle zeigt die Verbindung zwischen dem Datenverwaltungsmuster "Datenbank" und verschiedenen Kriterien.
| Kriterien | Datenbank – Ein Mandant pro Datenbank-Datenverwaltungsmuster |
|---|---|
| Datenisolation |
|
| Agilität |
|
| Vorgänge |
|
| Skalieren |
|
| Leistung |
|
| Vorschriften und Compliance-Anforderungen |
|
Die wichtigsten Punkte sind:
- Vorteil:Mittlere Daten- und Ressourcenisolation; mittlere Ressourceneffizienz; jeder Mandant kann ein eigenes Backup und CMEK haben.
- Nachteil:Begrenzte Anzahl an Mandanten pro Instanz; keine Standortflexibilität, wenn die Funktion für geografische Partitionierung nicht verwendet wird.
Das Datenverwaltungsmuster „Datenbank“ eignet sich für folgende Szenarien:
- Mehrere Kunden befinden sich im selben Datenbereich oder unterstehen derselben Aufsichtsbehörde.
- Mandanten erfordern eine systembasierte Datentrennung und die Möglichkeit, ihre Daten zu sichern und wiederherzustellen, die Freigabe von Infrastrukturressourcen ist aber akzeptabel.
- Mandanten benötigen einen eigenen CMEK.
- Die Kosten sind ein wichtiger Faktor. Die Mindestressourcen, die pro Mandant benötigt werden, sind geringer als die Kosten einer Instanz. Es ist wünschenswert, dass Mandanten die inaktiven Ressourcen anderer Mandanten nutzen.
Tabelle
Im Datenverwaltungsmuster "Tabelle" wird eine einzelne Datenbank, die ein einzelnes Schema implementiert, für mehrere Mandanten verwendet. Für die Daten jedes Mandanten wird eine separate Tabellengruppe verwendet. Um diese Tabellen zu unterscheiden, sollten Sie tenant ID als Präfix oder Suffix in die Tabellennamen aufnehmen oder benannte Schemas verwenden.
Dieses Datenverwaltungsmuster (die Nutzung einer eigenen Tabellengruppe pro Mandant) bietet im Vergleich zu den vorherigen Optionen (Datenverwaltungsmuster "Instanz" und "Datenbank") eine viel höhere Isolation. Das Onboarding umfasst das Erstellen neuer Tabellen, der zugehörigen referenziellen Integrität und von Indexes.
Pro Datenbank sind maximal 5.000 Tabellen zulässig. Für einige Kunden kann dieses Limit die Nutzung der Anwendung einschränken.
Außerdem kann die Verwendung von separaten Tabellen pro Kunde dazu führen, dass ein großer Rückstand an Schemaaktualisierungsvorgängen entsteht. Ein solcher Rückstand kann sehr viel Zeit in Anspruch nehmen.
Für die HR-Anwendung kann der SaaS-Anbieter eine Reihe an Tabellen für jeden Kunden erstellen und dabei das Präfix tenant ID in den Tabellennamen nutzen. Beispiel: customer1_employee, customer1_payroll und customer1_department.
Alternativ können sie die Mandanten-ID als benanntes Schema verwenden und ihre Tabelle als customer1.employee, customer1.payroll und customer1.department benennen.
Wie im folgenden Diagramm dargestellt, enthält das Datenverwaltungsmuster "Tabelle" einen Satz Tabellen pro Mandant.
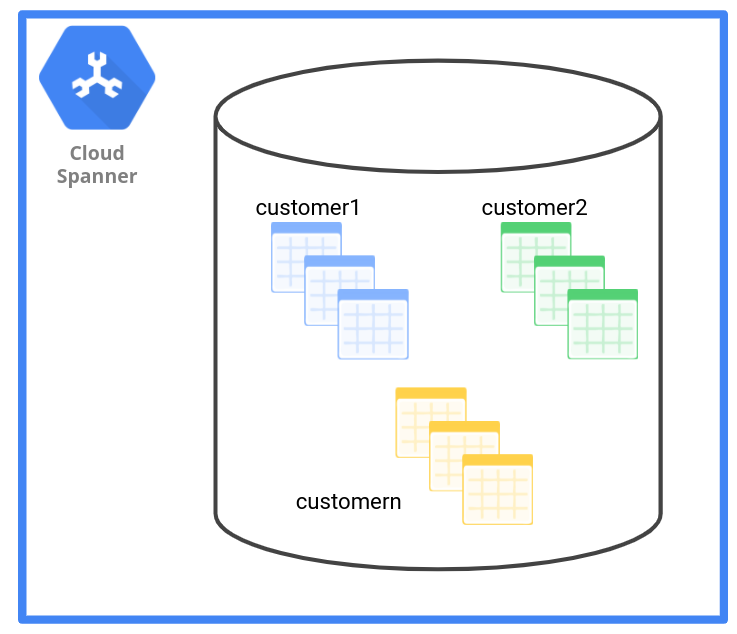
Die folgende Tabelle zeigt, wie sich das Datenverwaltungsmuster "Tabelle" auf verschiedene Kriterien auswirkt.
| Kriterium | Tabelle – Ein Tabellensatz pro Mandanten-Datenverwaltungsmuster |
|---|---|
| Datenisolation |
|
| Agilität |
|
| Vorgänge |
|
| Skalieren |
|
| Leistung |
|
| Vorschriften und Compliance-Anforderungen |
|
Die wichtigsten Punkte sind:
- Vorteil:Mittlere Skalierbarkeit und Ressourceneffizienz.
- Nachteil:
- Mittleres Maß an Daten- und Ressourcenisolation.
- Standortunabhängigkeit, wenn die neue Funktion für geografische Partitionierung nicht verwendet wird.
- Mandanten können nicht separat überwacht werden. Die einzigen verfügbaren Informationen zum Ressourcenverbrauch auf Tabellenebene sind Statistiken zur Tabellengröße.
- Mandanten können keine eigenen CMEK-Schlüssel und Sicherungen haben.
Das Datenverwaltungsmuster „Tabelle“ eignet sich für folgende Szenarien:
- Mehrmandantenanwendungen, bei denen keine rechtliche Trennung der Daten erforderlich ist, Sie aber eine logische Trennung und Sicherheitskontrolle wünschen.
- Die Kosten sind ein wichtiger Faktor. Die Mindestkosten pro Mandant sind niedriger als die Kosten pro Datenbank.
Zeile
Das endgültige Datenverwaltungsmuster stellt mehrere Mandanten mit einem gemeinsamen Satz von Tabellen bereit, wobei jede Zeile zu einem bestimmten Mandanten gehört. Dieses Datenverwaltungsmuster stellt ein extremes Maß an Mehrinstanzenfähigkeit dar, wobei alles – von der Infrastruktur über das Schema bis zum Datenmodell – von mehreren Mandanten gemeinsam genutzt wird. Innerhalb einer Tabelle werden Zeilen anhand von Primärschlüsseln partitioniert, wobei tenant ID das erste Element des Schlüssels ist. Aus Sicht der Skalierung unterstützt Spanner dieses Muster am besten, da es Tabellen ohne Einschränkung skalieren kann.
Für die Personalwesen-Anwendung kann der Primärschlüssel der Lohnabrechnungstabelle eine Kombination aus customerID und payrollID sein.
Wie im folgenden Diagramm dargestellt, enthält das Datenverwaltungsmuster "Zeile" eine Tabelle für mehrere Mandanten.

Im Gegensatz zu allen anderen Mustern kann der Datenzugriff im Muster „Zeile“ nicht separat für verschiedene Mandanten gesteuert werden. Wenn weniger Tabellen verwendet werden, werden Schemaaktualisierungsvorgänge schneller abgeschlossen, wenn jeder Mandant eigene Datenbanktabellen hat. Dieser Ansatz vereinfacht das Onboarding, Offboarding und den Betrieb erheblich.
Die folgende Tabelle zeigt, wie sich das Datenverwaltungsmuster "Zeile" auf verschiedene Kriterien auswirkt.
| Kriterium | Zeile – Ein Satz Zeilen pro Mandanten-Datenverwaltungsmuster |
|---|---|
| Datenisolation |
|
| Agilität |
|
| Vorgänge |
|
| Skalieren |
|
| Leistung |
|
| Vorschriften und Compliance-Anforderungen |
|
Die wichtigsten Punkte sind:
- Vorteil:Hoch skalierbar; hat nur geringen operativen Aufwand; vereinfachte Schemas.
- Nachteil:Hoher Ressourcenverbrauch; es gibt keine pro Mandant zuständigen Sicherheitskontrollen und kein Monitoring.
Dieses Muster eignet sich optimal für folgende Szenarien:
- Interne Anwendungen für verschiedene Abteilungen, bei denen eine strikte Datensicherheits-Isolierung im Vergleich zur Wartungsfreundlichkeit weniger wichtig ist.
- Maximale Ressourcenfreigabe für Mandanten, die kostenlose Anwendungen nutzen, wobei die Ressourcenbereitstellung gleichzeitig minimiert wird.
Datenverwaltungsmuster und Verwaltung des Mandantenlebenszyklus
In folgender Tabelle werden die verschiedenen Datenverwaltungsmuster über alle Kriterien hinweg allgemein verglichen.
| Instanz | Datenbank | Tabelle | Zeile | |
|---|---|---|---|---|
| Datenisolation | Abgeschlossen | Hoch | Mittel | Niedrig |
| Agilität | Niedrig | Mäßig besucht | Mäßig besucht | Highest |
| Bedienkomfort | Hoch | Hoch | Niedrig | Niedrig |
| Skalieren | Hoch | Eingeschränkt (es sei denn, zusätzliche Instanzen werden verwendet, wenn das Limit erreicht wird) | Eingeschränkt (sofern beim Erreichen des Limits keine zusätzlichen Datenbanken verwendet werden) | Highest |
| Leistung1 – Ressourcenisolation | Hoch | Niedrig | Niedrig | Niedrig |
| Leistung1 – Mindestressourcen pro Mandant | Hoch | Mäßig hoch | Mittel | Kein Mindestbetrag pro Mandant |
| Leistung1 – Ressourceneffizienz | Niedrig | Hoch | Hoch | Hoch |
| Leistung1: Auswahl des Standorts zur Latenzoptimierung | Hoch | Mäßig besucht | Mittel | Mittel |
| Verordnungen und Compliance | Highest | Hoch | Mittel | Niedrig |
1 Die Leistung hängt stark vom Schemadesign und den Best Practices für Abfragen ab. Die Werte hier sind nur ein durchschnittlicher Erwartungswert.
Die besten Datenverwaltungsmuster für eine bestimmte mehrmandantenfähige Anwendung sind diejenigen, die die meisten ihrer Anforderungen je nach Kriterien erfüllen. Ist ein bestimmtes Kriterium nicht erforderlich, können Sie die Zeile, in der es enthalten ist, ignorieren.
Kombinierte Datenverwaltungsmuster
Oft reicht ein einzelnes Datenverwaltungsmuster aus, um die Anforderungen einer Mehrmandantenanwendung zu erfüllen. Ist dies der Fall, kann das Design ein einzelnes Datenverwaltungsmuster nutzen.
Einige Mehrmandantenanwendungen erfordern jedoch mehrere Datenverwaltungsmuster gleichzeitig. Beispiel: eine Mehrmandantenanwendung, die eine kostenlose Stufe, eine reguläre Stufe und eine Unternehmensstufe unterstützt.
Kostenlose Stufe:
- Muss Kostengünstig sein
- Muss ein Limit als Obergrenze für das Datenvolumen haben
- Unterstützt in der Regel eingeschränkte Funktionen
- Das Datenverwaltungsmuster "Zeile" ist ein guter Kandidat für die kostenlose Stufe.
- Die Mandantenverwaltung ist unkompliziert
- Keine Erstellung bestimmter oder exklusiver Mandantenressourcen erforderlich
Reguläre Stufe:
- Geeignet für zahlende Kunden, die keine besonderen Anforderungen an die Skalierung oder Isolation haben.
- Die Datenverwaltungsmuster "Tabelle" und "Datenbank" sind gute Kandidaten für die reguläre Stufe:
- Tabellen und Indexe sind exklusiv für den Mandanten.
- Die Sicherung im Datenverwaltungsmuster „Datenbank“ ist einfach
- Die Sicherung wird für das Datenverwaltungsmuster „Tabelle“ nicht unterstützt.
- Die Mandantensicherung muss als Dienstprogramm außerhalb von Spanner implementiert werden.
Unternehmensstufe:
- In der Regel eine gehobene Stufe mit vollständiger Autonomie in allen Aspekten.
- Mandanten haben dedizierte Ressourcen, die eine dedizierte Skalierung und vollständige Isolation umfassen.
- Das Datenverwaltungsmuster „Instanz“ eignet sich gut für die Unternehmensstufe.
Eine Best Practice besteht darin, unterschiedliche Datenverwaltungsmuster in verschiedenen Datenbanken zu speichern. Es ist zwar möglich, verschiedene Datenverwaltungsmuster in einer Spanner-Datenbank zu kombinieren, aber die Implementierung der Zugriffslogik und Lebenszyklusvorgänge der Anwendung ist dann schwierig.
Im Abschnitt Anwendungsdesign finden Sie einige Überlegungen zum Design von Mehrmandantenanwendungen, die bei der Verwendung eines einzelnen Datenverwaltungsmusters oder mehrerer Datenverwaltungsmuster relevant sind.
Mandantenlebenszyklus verwalten
Mandanten haben einen Lebenszyklus. Daher müssen Sie die entsprechenden Verwaltungsvorgänge in Ihrer mehrmandantenfähigen Anwendung implementieren. Berücksichtigen Sie neben den grundlegenden Vorgängen zum Erstellen, Aktualisieren und Löschen von Mandanten die folgenden zusätzlichen datenbezogenen Vorgänge:
Mandantendaten exportieren:
- Beim Löschen von Mandanten hat es sich bewährt, deren Daten zuerst zu exportieren und Ihnen ggf. das Dataset zur Verfügung zu stellen.
- Wenn Sie das Datenverwaltungsmuster „Zeile“ oder „Tabelle“ verwenden, muss die Mehrmandantenanwendung den Export implementieren oder der Datenbankfunktion (Datenbankexport) zuordnen und eine benutzerdefinierte Logik implementieren, um den Teil der Daten zu entfernen, der dem Mandanten entspricht.
Mandantendaten sichern:
- Verwenden Sie die Export- oder Sicherungsfunktionen der Datenbank, wenn Sie eines der Datenverwaltungsmuster "Instanz" oder "Datenbank" verwenden und die Daten der einzelnen Mandanten sichern.
- Wenn Sie das Datenverwaltungsmuster "Tabelle" oder "Zeile" verwenden und Daten für einzelne Mandanten sichern, muss die Mehrmandantenanwendung diesen Vorgang implementieren. Die Spanner-Datenbank kann nicht ermitteln, welche Daten zu welchem Mandanten gehören.
Mandantendaten verschieben:
Um einen Mandanten von einem Datenverwaltungsmuster zu einem anderen zu verschieben (oder um einen Mandanten innerhalb desselben Datenverwaltungsmusters zwischen Instanzen oder Datenbanken zu bewegen) müssen die Daten aus dem einen Datenverwaltungsmuster extrahiert und in das neue Datenverwaltungsmuster eingefügt werden.
- Führen Sie einen Export/Import durch, wenn eine Anwendungsausfallzeit möglich ist.
- Führen Sie eine Datenbankmigration ohne Ausfallzeit durch, falls Ausfallzeiten nicht vertretbar sind.
Probleme mit "Noisy Neighbours" sind ein weiterer Grund für das Verschieben von Mandanten.
Anwendungsdesign
Beim Entwerfen einer Mehrmandantenanwendung sollten Sie eine mandantenfähige Geschäftslogik implementieren Das bedeutet, dass die Anwendung Geschäftslogiken immer im Kontext eines bekannten Mandanten ausüben muss.
Aus Datenbankperspektive bedeutet das Anwendungsdesign, dass jede Abfrage nach dem Datenverwaltungsmuster ausgeführt werden muss, in dem der Mandanten ausgeführt wird. In folgenden Abschnitten werden einige der zentralen Konzepte des Designs von Mehrmandantenanwendungen vorgestellt.
Konfiguration von dynamischem Mandanten und Abfragen
Beim dynamischen Zuordnen von Mandantendaten zu Mandantenanwendungsanfragen wird eine Zuordnungskonfiguration verwendet:
- Bei den Datenverwaltungsmustern „Datenbank“ und „Instanz“ ist ein Verbindungsstring ausreichend, um auf die Daten eines Mandanten zuzugreifen.
- Beim Datenverwaltungsmuster „Tabelle“ müssen die korrekten Tabellennamen festgelegt werden.
- Verwenden Sie für Datenverwaltungsmuster für Zeilen die entsprechenden Prädikate, um die Daten eines bestimmten Mandanten abzurufen.
Ein Mandant kann in einem der vier Datenverwaltungsmuster residieren. Die folgende Zuordnungsimplementierung spricht eine Verbindungskonfiguration für den allgemeinen Fall einer Mehrmandantenanwendung an, die alle Datenverwaltungsmuster gleichzeitig nutzt. Wenn ein bestimmter Mandanten in einem Muster residiert, verwenden einige Mehrmandantenanwendungen ein Datenverwaltungsmuster für alle Mandanten. Dieser Fall wird implizit durch folgende Zuordnung abgedeckt.
Wenn ein Mandant eine Geschäftslogik ausführt (z. B. ein Mitarbeiter, der sich mit seiner Mandanten-ID anmeldet), muss die Anwendungslogik das Datenverwaltungsmuster des Mandanten, den Speicherort der Daten für eine bestimmte Mandanten-ID und optional die Tabellen-Namenskonvention (für das Tabellenmuster) bestimmen.
Diese Anwendungslogik erfordert eine Zuordnung des Mandanten-zu-Daten-Verwaltungsmusters. Im folgenden Codebeispiel bezieht sich connection string auf die Datenbank, in der sich die Mandantendaten befinden. Im Beispiel werden die Spanner-Instanz und die Datenbank identifiziert. Für die Datenverwaltungsmuster-Instanz und die Datenbank reicht der folgende Code aus, damit die Anwendung eine Verbindung herstellen und Abfragen ausführen kann:
tenant id -> (data management pattern,
database connection string)
Für die Datenverwaltungsmuster „Tabelle“ und „Zeile“ ist ein zusätzliches Design erforderlich.
Datenverwaltungsmuster "Tabelle"
Für das Datenverwaltungsmuster "Tabelle" gibt es mehrere Mandanten innerhalb derselben Datenbank. Jeder Mandant hat eine eigene Reihe Tabellen. Die Tabellen unterscheiden sich durch ihre Namen. Die Zugehörigkeit zwischen Tabellen und Mandanten ist klar.
Ein Ansatz besteht darin, die Tabelle jedes Mandanten in einem Namespace zu platzieren, der nach dem Mandanten benannt ist, und den Tabellennamen mit namespace.name vollständig zu qualifizieren. Sie platzieren beispielsweise eine EMPLOYEE-Tabelle im Namespace T356 für den Mandanten mit der ID 356 und Ihre Anwendung kann T356.EMPLOYEE verwenden, um die Anfragen an die Tabelle zu richten.
Ein anderer Ansatz besteht darin, den Tabellennamen die Mandanten-ID voranzustellen. Die Tabelle EMPLOYEE wird beispielsweise für den Mandanten mit der ID 356 als T356_EMPLOYEE bezeichnet.
Die Anwendung muss jeder Tabelle das Präfix tenant
ID voranstellen, bevor die Abfrage an die Datenbank gesendet wird, die von der Zuordnung zurückgegeben wurde.
Wenn Sie anstelle der Mandanten-ID einen anderen Text verwenden möchten, können Sie eine Zuordnung von der Mandanten-ID zum benannten Schemanamespace oder zum Tabellenpräfix erstellen.
Um die Anwendungslogik zu vereinfachen, können Sie eine Ebene der Indirektion einführen. Sie können beispielsweise eine gemeinsame Bibliothek mit Ihrer Anwendung verwenden, um automatisch den Namespace oder das Tabellenpräfix für den Aufruf vom Mandanten anzuhängen.
Datenverwaltungsmuster "Zeile"
Ein ähnliches Design ist für das Datenverwaltungsmuster "Zeile" erforderlich. In diesem Muster gibt es ein einzelnes Schema. Mandantendaten werden als Zeilen gespeichert. Für einen ordnungsgemäßen Zugriff auf die Daten hängen Sie an jede Abfrage ein Prädikat an, um den entsprechenden Mandanten auszuwählen.
Ein möglicher Ansatz zum Ermitteln des entsprechenden Mandanten besteht darin, in jeder Tabelle eine Spalte namens TENANT zu verwenden. Zur besseren Datenisolation sollte dieser Spaltenwert Teil des Primärschlüssels sein. Der Spaltenwert ist tenant ID. Jede Abfrage muss das Prädikat AND TENANT = tenant ID an eine vorhandene WHERE-Klausel anhängen oder eine WHERE-Klausel mit dem Prädikat AND TENANT = tenant
ID hinzufügen.
Die Mandanten-ID muss in der Anwendungslogik verfügbar sein, damit eine Verbindung zur Datenbank hergestellt und die ordnungsgemäßen Abfragen erstellt werden können. Sie kann als Parameter übergeben oder als Thread-Kontext gespeichert werden.
Bei einigen Lebenszyklusvorgängen müssen Sie die Zuordnungskonfiguration für Mandanten-zu-Daten-Verwaltungsmuster ändern. Wenn Sie beispielsweise einen Mandanten zwischen Datenverwaltungsmustern verschieben, müssen Sie das Datenverwaltungsmuster und den Datenbank-Verbindungsstring aktualisieren. Möglicherweise müssen Sie auch das Tabellenpräfix aktualisieren.
Abfrage erstellen und zuweisen
Ein Grundprinzip von Mehrmandantenanwendungen ist es, dass mehrere Mandanten eine einzige Cloudressource gemeinsam nutzen können. Die vorherigen Datenverwaltungsmuster fallen in diese Kategorie, außer in Fällen, in denen ein einzelner Mandant einer einzelnen Spanner-Instanz zugewiesen wird.
Das gemeinsame Nutzen von Ressourcen geht über die gemeinsame Nutzung von Daten hinaus. Monitoring und Logging werden ebenfalls gemeinsam genutzt. Beispielsweise werden im Tabellendatenverwaltungsmuster und Zeilendatenverwaltungsmuster alle Abfragen für alle Mandanten im selben Audit-Log aufgezeichnet.
Wird eine Abfrage protokolliert, so muss der Abfragetext überprüft werden, um festzustellen, für welchen Mandanten die Abfrage ausgeführt wurde. Im Datenverwaltungsmuster "Zeile" müssen Sie das Prädikat parsen. Im Datenverwaltungsmuster "Tabelle" müssen Sie einen der Tabellennamen parsen.
In den Datenverwaltungsmustern „Datenbank“ und „Instanz“ enthält der Abfragetext keine Mandanteninformationen. Wenn Sie Mandanteninformationen für diese Muster abrufen möchten, müssen Sie die Zuordnungstabelle der Mandanten-zu-Daten-Verwaltungsmuster abfragen.
Die Analyse von Logs und Abfragen ist einfacher, wenn der Mandant für eine bestimmte Abfrage bestimmt wird, ohne den Abfragetext zu parsen. Eine Möglichkeit, einen Mandanten für eine Abfrage über alle Datenverwaltungsmuster hinweg einheitlich zu identifizieren, besteht darin, dem Abfragetext einen Kommentar mit tenant ID und (optional) einem label hinzuzufügen.
Mit der folgenden Abfrage werden alle Mitarbeiterdaten für den mit TENANT 356 identifizierten Mandanten ausgewählt. Damit die SQL-Syntax nicht geparst und die Mandanten-ID nicht aus dem Prädikat extrahiert werden müssen, wird die Mandanten-ID als Kommentar hinzugefügt. Ein Kommentar kann extrahiert werden, ohne dass die SQL-Syntax geparst werden muss.
SELECT * FROM EMPLOYEE
-- TENANT 356
WHERE TENANT = 'T356';
oder
SELECT * FROM T356_EMPLOYEE;
-- TENANT 356
Bei diesem Design wird jede Abfrage, die für einen Mandanten ausgeführt wird, diesem Mandanten unabhängig vom Datenverwaltungsmuster zugeordnet. Wenn ein Mandant von einem Datenverwaltungsmuster zu einem anderen verschoben wird, kann sich der Abfragetext ändern, die Attribution bleibt jedoch im Abfragetext gleich.
Das vorherige Codebeispiel ist nur eine der verfügbaren Methoden. Eine weitere Methode besteht darin, ein JSON-Objekt als Kommentar einzufügen, statt Label und Wert:
SELECT * FROM T356_EMPLOYEE;
-- {"TENANT": 356}
Sie können auch Tags verwenden, um Abfragen Mandanten zuzuordnen und die Statistiken in den integrierten spanner_sys-Tabellen aufzurufen.
Vorgänge des Mandantenzugriffszyklus
Abhängig von Ihrer Entwurfsphilosophie kann eine Mehrmandantenanwendung die zuvor beschriebenen Datenlebenszyklus-Vorgänge direkt implementieren oder ein separates Tool zur Mandantenverwaltung erstellen.
Unabhängig von der Implementierungsstrategie müssen Lebenszyklusvorgänge möglicherweise ausgeführt werden, ohne dass gleichzeitig die Anwendungslogik ausgeführt wird. Beispiel: Wenn ein Mandanten von einem Datenverwaltungsmuster in ein anderes verschoben wird, kann die Anwendungslogik nicht ausgeführt werden, da sich die Daten nicht in nur einer Datenbank befinden. Befinden sich die Daten nicht in einer einzigen Datenbank, so macht das aus der Anwendungsperspektive zwei weitere Vorgänge erforderlich:
- Mandanten beenden: Unterbindet jeden Zugriff auf die Anwendungslogik und erlaubt gleichzeitig Datenlebenszyklus-Vorgänge.
- Mandanten starten: Die Anwendungslogik kann auf die Daten eines Mandanten zugreifen, während die Lebenszyklusvorgänge, die die Anwendungslogik beeinträchtigen würden, deaktiviert sind.
Dies wird nur selten genutzt. Dennoch kann das Notfall-Herunterfahren eines Mandanten ein wichtiger Lebenszyklus-Vorgang sein. Verwenden Sie diese Einstellung, wenn Sie einen Verstoß vermuten und den Zugriff auf die Daten eines Mandanten umfassend unterbinden möchten – nicht nur auf die Anwendungslogik, sondern auch auf die Lebenszyklus-Vorgänge. Ein Verstoß kann innerhalb oder außerhalb der Datenbank erfolgen.
Außerdem muss ein übereinstimmender Lebenszyklus-Vorgang zum Entfernen des Notfallstatus verfügbar sein. Bei einem solchen Vorgang können sich zwei oder mehr Administratoren gleichzeitig anmelden, um die gegenseitige Kontrolle zu implementieren.
Isolierte Anwendungen
Die verschiedenen Datenverwaltungsmuster unterstützen unterschiedliche Grade der Isolation der Mandantendaten. Zwischen der am meisten isolierten Ebene (Instanz) und der am wenigsten isolierten Ebene (Zeile) sind unterschiedliche Isolationsgrade möglich.
Im Zusammenhang mit Mehrmandantenanwendungen müssen ähnliche Bereitstellungsentscheidungen getroffen werden: Haben alle Mandanten über dieselbe Anwendungsbereitstellung Zugriff auf ihre Daten (möglicherweise unter Nutzung verschiedener Datenverwaltungsmuster)? Beispielsweise kann ein einzelner Kubernetes-Cluster alle Mandanten unterstützen. Wenn dann ein Mandant auf seine Daten zugreift, führt derselbe Cluster die Geschäftslogik aus.
Alternativ werden, wie im Fall der Datenverwaltungsmuster, verschiedene Mandanten auf verschiedene Anwendungsbereitstellungen weitergeleitet. Größere Mandanten haben möglicherweise Zugriff auf eine Anwendungsbereitstellung, die ausschließlich ihnen vorbehalten ist. Kleinere Mandanten oder Mandanten auf der kostenlosen Stufe teilen sich eine Anwendungsbereitstellung.
Anstatt die in diesem Dokument beschriebenen Datenverwaltungsmuster direkt mit entsprechenden Mustern zur Anwendungsverwaltung zu vergleichen, können Sie das Datenverwaltungsmuster „Datenbank“ verwenden, sodass alle Mandanten eine einzige Anwendungsbereitstellung gemeinsam nutzen. Sie können das Datenverwaltungsmuster "Datenbank" nutzen, während alle Mandanten eine einzige Anwendungsbereitstellung verwenden.
Die Mehrinstanzenfähigkeit ist ein wichtiges Verwaltungsmuster für Anwendungs-Designdaten, insbesondere, wenn die Ressourceneffizienz eine wichtige Rolle spielt. Spanner unterstützt mehrere Datenverwaltungsmuster für die Implementierung von Mehrmandantenanwendungen. Es vermeidet Ausfallzeiten bei geplanten Wartungsarbeiten oder Regionalfehlern und bietet ein Verfügbarkeits-SLA von 99, 999%. Spanner unterstützt moderne Mehrmandantenanwendungen durch hohe Verfügbarkeit und Skalierbarkeit.