Spanner Data Boost は、サポートされている Spanner ワークロード用の独立したコンピューティング リソースを提供する、フルマネージドのサーバーレス サービスです。Data Boost を使用すると、プロビジョニングされた Spanner インスタンス上の既存のワークロードへの影響がほぼゼロの状態で、分析クエリとデータ エクスポートを実行できます。このサービスは、Google がリージョン レベルで管理する Spanner クラスタで構成されています。Data Boost をリクエストする対象となるクエリの場合、Spanner はワークロードをこれらのサーバーに透過的にルーティングします。対象となるクエリは、クエリ実行プランの最初の演算子が分散ユニオンであるクエリです。これらのクエリは、Data Boost を利用するために変更する必要はありません。
Data Boost は、リソース競合による既存のトランザクション システムに悪影響が及ばないようにする次のシナリオで、最も効果的です。
- 大量のデータを処理するアドホック クエリや頻度の低いクエリ。典型的な例は、BigQuery から Spanner への連携クエリです。
- レポートまたはデータ エクスポート ジョブ。たとえば、Spanner データを Cloud Storage にエクスポートする Dataflow ジョブがあります。
次の図は、Data Boost が Spanner インスタンスと連携して独立したコンピューティング リソースを提供する方法を示しています。
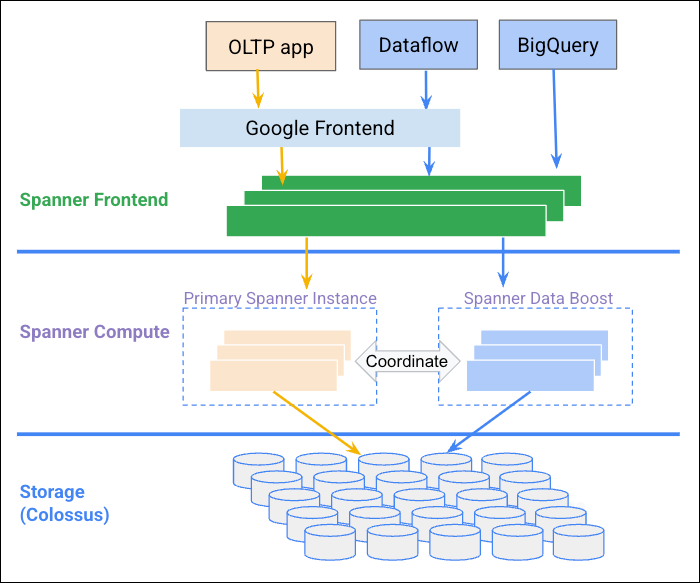
利点
Data Boost には次の利点があります。
- ワークロードの分離を提供する。クエリの複雑さや処理されるデータの量に関係なく、最新のデータに対してサポートされているクエリを実行しても、既存のトランザクション ワークロードへの影響はほぼゼロです。
- レイテンシが同等以上である。
- 時折発生する分析クエリをサポートするためだけに Spanner インスタンスを過剰にプロビジョニングすることを回避する。
- 高度なスケーラビリティを提供する。より多くのクエリ並列処理により、負荷の急増に応じて弾力的にスケーリングします。
- 包括的な指標を提供する。これにより、管理者は最も費用のかかるクエリを特定し、最適化する費用コンポーネントを決定できます。管理者は、クエリの次回の実行時のサーバーレス プロセッシング ユニットの消費量を監視することで、最適化の影響を検証できます。
- 追加の運用上のオーバーヘッドは必要ない。管理のための追加のサービスはありません。容量の計画やプロビジョニング、スケーリングの待機、メンテナンスは不要です。
権限
Data Boost をリクエストするクエリまたはエクスポートを実行するプリンシパルには、spanner.databases.useDataBoost Identity and Access Management(IAM)権限が必要です。Cloud Spanner Database Reader With DataBoost(roles/spanner.databaseReaderWithDataBoost)IAM ロールを使用することをおすすめします。
課金と割り当て
料金は、Data Boost で実行されるクエリで使用された実際の処理ユニットに対してのみ発生します。管理者は、費用超過を回避するために使用量の上限を設定できます。
次のステップ
- Data Boost で連携クエリを実行する
- Data Boost でデータをエクスポートする
- アプリケーションで Data Boost を使用する
- Data Boost 使用量のモニタリング
- Data Boost 割り当て使用量のモニタリングと管理