Les tables dérivées offrent de nombreuses possibilités d'analyse avancée, mais elles peuvent être intimidantes à aborder, à implémenter et à dépanner. Ce guide pratique contient les cas d'utilisation les plus courants des tables dérivées dans Looker.
Cette page contient les exemples suivants :
- Créer un tableau tous les jours à 3h du matin
- Ajouter de nouvelles données à une grande table
- Utiliser les fonctions de fenêtrage SQL
- Créer des colonnes dérivées pour des valeurs calculées
- Stratégies d'optimisation
- Utiliser les PDT pour tester les optimisations
UNIONdeux tables- Calculer la somme d'une somme (dimensionner une mesure)
- Tableaux récapitulatifs avec notoriété globale
Ressources de tables dérivées
Ces manuels partent du principe que vous avez des connaissances de base sur LookML et les tables dérivées. Vous devez être à l'aise pour créer des vues et modifier le fichier de modèle. Si vous souhaitez revoir l'un de ces thèmes, consultez les ressources suivantes :
- Tables dérivées
- Termes et concepts LookML
- Créer des tables dérivées natives
- Documentation de référence du paramètre
derived_table - Mettre en cache des requêtes et recompiler des tables PDT avec des groupes de données
Créer un tableau tous les jours à 3h
Dans cet exemple, les données arrivent tous les jours à 2h du matin. Les résultats d'une requête sur ces données seront les mêmes, qu'elle soit exécutée à 3h ou à 21h. Il est donc judicieux de créer le tableau une fois par jour et de laisser les utilisateurs extraire les résultats d'un cache.
En incluant votre groupe de données dans le fichier de modèle, vous pouvez le réutiliser avec plusieurs tables et explorations. Ce groupe de données contient un paramètre sql_trigger_value qui indique au groupe de données quand déclencher et reconstruire la table dérivée.
Pour obtenir d'autres exemples d'expressions de déclencheur, consultez la documentation sql_trigger_value.
## in the model file
datagroup: standard_data_load {
sql_trigger_value: SELECT FLOOR(((TIMESTAMP_DIFF(CURRENT_TIMESTAMP(),'1970-01-01 00:00:00',SECOND)) - 60*60*3)/(60*60*24)) ;;
max_cache_age: "24 hours"
}
explore: orders {
…
Ajoutez le paramètre datagroup_trigger à la définition derived_table dans le fichier de vue, puis spécifiez le nom du groupe de données que vous souhaitez utiliser. Dans cet exemple, le groupe de données est standard_data_load.
view: orders {
derived_table: {
indexes: ["id"]
datagroup_trigger: standard_data_load
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
…
}
Ajouter de nouvelles données à une grande table
Une augmentation de table PDT est une table dérivée persistante que Looker crée en ajoutant des données à jour à la table, au lieu de régénérer la totalité de la table.
L'exemple suivant s'appuie sur l'exemple de tableau orders pour montrer comment le tableau est créé de manière incrémentielle. De nouvelles données de commandes sont ajoutées chaque jour. Vous pouvez les ajouter à la table existante en ajoutant les paramètres increment_key et increment_offset.
view: orders {
derived_table: {
indexes: ["id"]
increment_key: "created_at"
increment_offset: 3
datagroup_trigger: standard_data_load
distribution_style: all
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;; }
…
}
La valeur increment_key est définie sur created_at, qui correspond à l'incrément de temps pour lequel de nouvelles données doivent être interrogées et ajoutées à la PDT dans cet exemple.
La valeur increment_offset est définie sur 3 pour spécifier le nombre de périodes précédentes (selon la granularité de la clé d'incrémentation) qui sont régénérées pour tenir compte des données tardives.
Utilisation des fonctions de fenêtrage SQL
Certains dialectes de base de données sont compatibles avec les fonctions de fenêtre, en particulier pour créer des numéros de séquence, des clés primaires, des totaux cumulés et d'autres calculs utiles sur plusieurs lignes. Une fois la requête primaire exécutée, les éventuelles déclarations derived_column sont exécutées lors d'une autre passe.
Si votre dialecte de base de données prend en charge les fonctions de fenêtrage, vous pouvez les utiliser dans votre table dérivée native. Créez un paramètre derived_column avec un paramètre sql contenant votre fonction de fenêtrage. Pour référencer ces valeurs, vous devez utiliser le nom de colonne défini dans la table dérivée native.
L'exemple suivant montre comment créer une table dérivée native qui inclut les colonnes user_id, order_id et created_time. Vous utiliserez ensuite une colonne dérivée avec une fonction de fenêtrage SQL ROW_NUMBER() pour calculer une colonne contenant le numéro de séquence d'une commande client.
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
Création de colonnes dérivées pour des valeurs calculées
Vous pouvez ajouter des paramètres derived_column pour spécifier des colonnes qui n'existent pas dans l'exploration du paramètre explore_source. Chaque paramètre derived_column comporte un paramètre sql qui spécifie comment construire la valeur.
Votre calcul sql peut utiliser toutes les colonnes que vous avez spécifiées à l'aide des paramètres column. Les colonnes dérivées ne peuvent pas inclure de fonctions d'agrégation, mais peuvent en revanche contenir des calculs réalisables sur une seule ligne de la table.
Cet exemple crée une colonne average_customer_order, qui est calculée à partir des colonnes lifetime_customer_value et lifetime_number_of_orders de la table dérivée native.
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: users.id
}
column: lifetime_number_of_orders {
field: order_items.count
}
column: lifetime_customer_value {
field: order_items.total_profit
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
Stratégies d'optimisation
Étant donné que des PDT sont stockées dans votre base de données, vous devriez optimiser vos PDT en suivant les stratégies suivantes, selon ce que prend en charge votre dialecte :
Par exemple, pour ajouter de la persistance, vous pouvez définir la régénération de la PDT lorsque le groupe de données orders_datagroup se déclenche, puis ajouter des index sur customer_id et first_order, comme indiqué ci-dessous :
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
Si vous n'ajoutez aucun index (ni équivalent pour votre dialecte), Looker vous invite à le faire pour améliorer les performances des requêtes.
Utiliser les PDT pour tester les optimisations
Vous pouvez utiliser les PDT pour tester différentes options d'indexation, de distribution et d'optimisation sans avoir besoin d'une assistance importante de la part de votre administrateur de base de données ou de vos développeurs ETL.
Prenons l'exemple d'une table pour laquelle vous souhaitez tester différents index. Voici un exemple de code LookML initial pour la vue :
view: customer {
sql_table_name: warehouse.customer ;;
}
Pour tester des stratégies d'optimisation, vous pouvez utiliser le paramètre indexes pour ajouter des index au LookML, comme indiqué ci-dessous :
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Interrogez la vue une fois pour générer la PDT. Exécutez ensuite vos requêtes de test et comparez vos résultats. Si vos résultats sont favorables, vous pouvez demander à votre équipe DBA ou ETL d'ajouter les index à la table d'origine.
UNION : deux tables
Vous pouvez exécuter un opérateur SQL UNION ou UNION ALL dans les deux tables dérivées si votre dialecte SQL le permet. Les opérateurs UNION et UNION ALL combinent les ensembles de résultats de deux requêtes.
Cet exemple montre à quoi ressemble une table dérivée basée sur SQL avec un UNION :
view: first_and_second_quarter_sales {
derived_table: {
sql:
SELECT * AS sales_records
FROM sales_records_first_quarter
UNION
SELECT * AS sales_records
FROM sales_records_second_quarter ;;
}
}
L'instruction UNION du paramètre sql produit une table dérivée qui combine les résultats des deux requêtes.
La différence entre UNION et UNION ALL est que UNION ALL ne supprime pas les lignes en double. Il existe des considérations de performances à prendre en compte lorsque vous utilisez UNION par rapport à UNION ALL, car le serveur de base de données doit effectuer des tâches supplémentaires pour supprimer les lignes en double.
Calculer la somme d'une somme (dimensionner une mesure)
En règle générale, en SQL (et par extension dans Looker), vous ne pouvez pas regrouper une requête par les résultats d'une fonction d'agrégation (représentée dans Looker par des mesures). Vous ne pouvez regrouper les données que par champs non agrégés (représentés dans Looker sous forme de dimensions).
Pour regrouper les données par agrégat (par exemple, pour obtenir la somme d'une somme), vous devez "dimensionnaliser" une mesure. Pour ce faire, vous pouvez utiliser une table dérivée, qui crée une sous-requête de l'agrégat.
À partir d'une exploration, Looker peut générer un code LookML pour tout ou partie d'une table dérivée. Il suffit de créer une exploration et de sélectionner tous les champs souhaités dans la table. Ensuite, pour générer le code LookML de la table dérivée native (ou basée sur SQL), procédez comme suit :
Cliquez sur le menu en forme d'engrenage de l'exploration, puis sélectionnez Obtenir LookML.
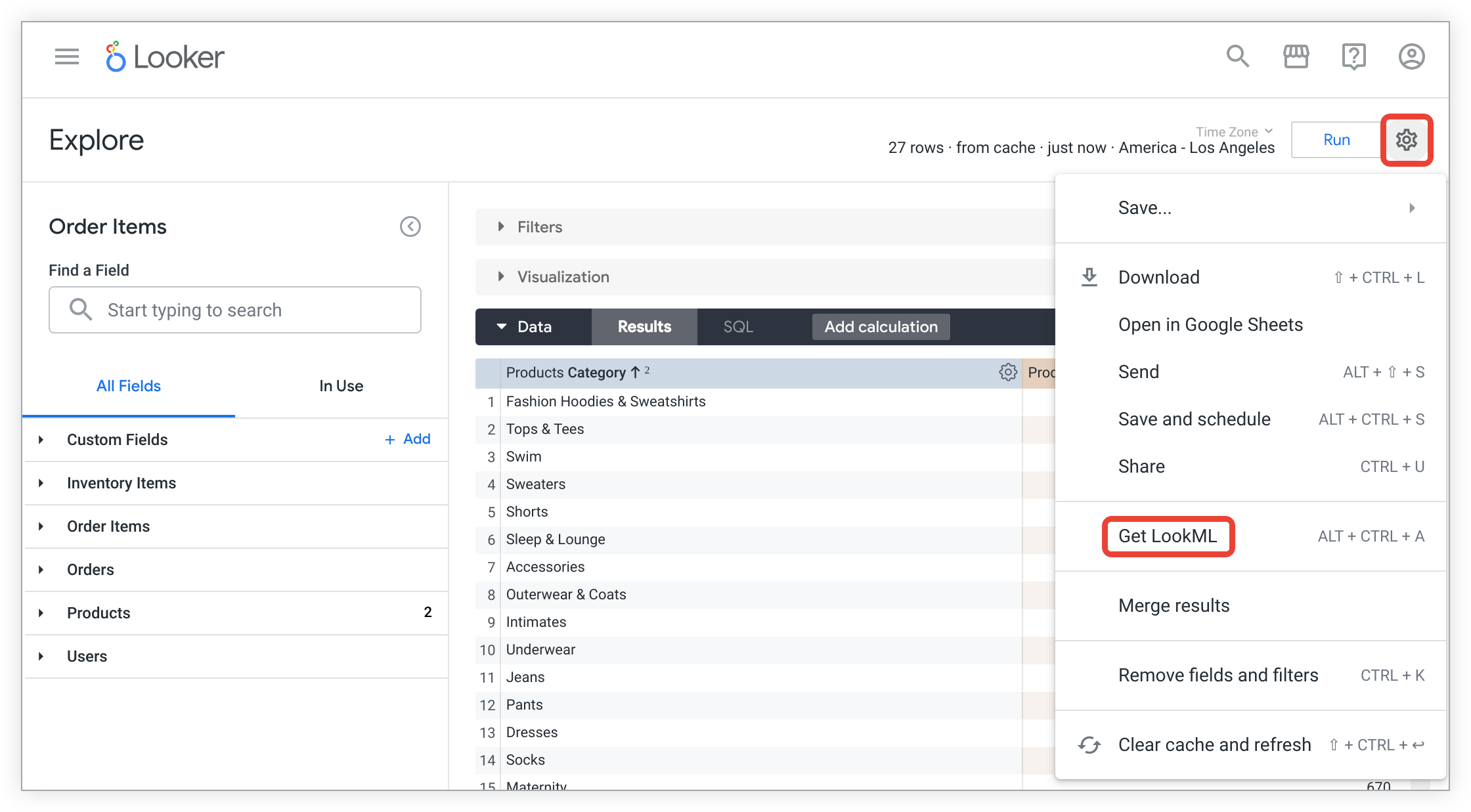
Pour afficher le code LookML permettant de créer une table dérivée native pour l'exploration, cliquez sur l'onglet Table dérivée.
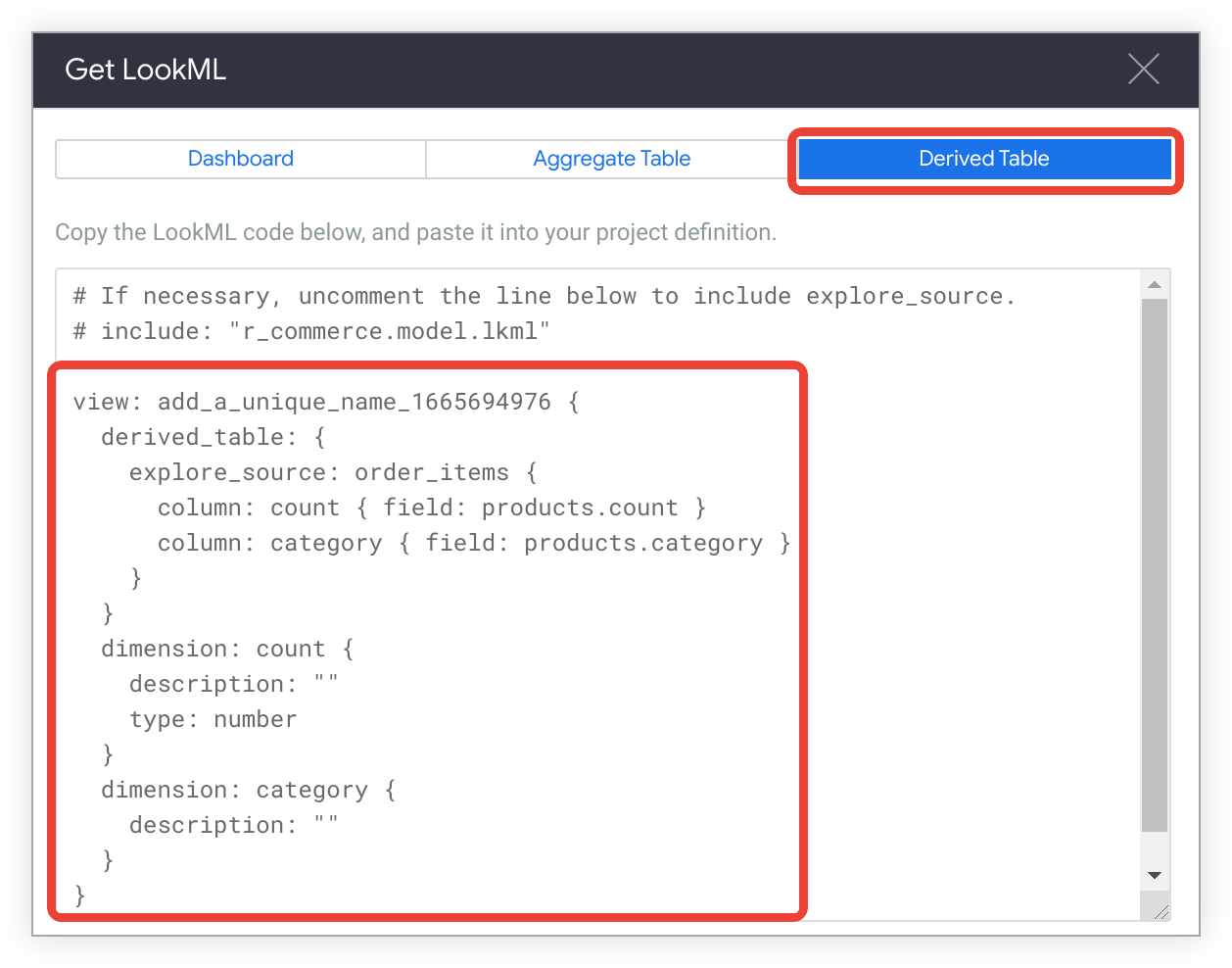
Copiez le code LookML.
Après avoir copié le code LookML généré, collez-le dans un fichier de vue en procédant comme suit :
En mode Développement, accédez aux fichiers de votre projet.
Dans l'IDE Looker, cliquez sur + en haut de la liste des fichiers du projet, puis sélectionnez Créer une vue. Vous pouvez également créer le fichier dans le dossier. Pour cela, cliquez sur le menu d'un dossier, puis sélectionnez Créer une vue.
Donnez un nom représentatif à la vue.
Au besoin, changez le nom des colonnes, désignez des colonnes dérivées et ajoutez des filtres.
Tables récapitulatives avec reconnaissance d'agrégats
Dans Looker, vous pouvez souvent rencontrer des ensembles de données ou des tables très volumineux qui, pour être performants, nécessitent des tables d'agrégation ou des cumuls.
Grâce à la reconnaissance des agrégats de Looker, vous pouvez préconstruire des tables agrégées à différents niveaux de granularité, de dimensionnalité et d'agrégation. Vous pouvez également indiquer à Looker comment les utiliser dans les explorations existantes. Les requêtes utiliseront ensuite ces tables récapitulatives lorsque Looker le jugera approprié, sans aucune intervention de l'utilisateur. Cela permettra de réduire la taille des requêtes et les temps d'attente, et d'améliorer l'expérience utilisateur.
L'exemple suivant montre une implémentation très simple dans un modèle Looker pour illustrer la légèreté de la reconnaissance des agrégats. Imaginons que vous disposiez d'une table de vols hypothétique dans la base de données, avec une ligne pour chaque vol enregistré par la FAA. Vous pouvez modéliser cette table dans Looker avec sa propre vue et son propre Explore. Voici le code LookML d'une table agrégée que vous pouvez définir pour l'exploration :
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Avec ce tableau agrégé, un utilisateur peut interroger l'exploration flights. Looker utilisera automatiquement le tableau agrégé pour répondre aux requêtes. Pour obtenir un tutoriel plus détaillé sur la reconnaissance des agrégats, consultez le tutoriel sur la reconnaissance des agrégats.