このページでは、セルフホスト型デプロイでよく利用されているアーキテクチャ パターンと、その実装に関するベスト プラクティスについて説明します。 このページを効果的に使用するには、システム アーキテクチャのコンセプトとプラクティスについて十分に理解している必要があります。
ワークフロー戦略
Looker を実装するための実行可能なオプションとしてセルフホスティングを特定したら、次のステップは、デプロイで提供される戦略を詳細に作成することです。
- 評価を実施します。計画されたワークフローと既存のワークフローの候補リストを特定します。
- 該当するアーキテクチャ パターンをリストします。明らかになった候補ワークフローから、適用可能なアーキテクチャ パターンを特定します。
- 最適なアーキテクチャ パターンに優先順位を付けて選択します。アーキテクチャ パターンを最も重要なタスクと結果に合わせます。
- アーキテクチャ コンポーネントを構成し、Looker アプリケーションをデプロイします。安全なクライアント接続を確立するために必要なホスト、サードパーティの依存関係、ネットワーク トポロジを実装します。
アーキテクチャ オプション
専用の仮想マシン
Looker を 単一インスタンスとして専用の仮想マシン(VM)で実行することもできます。単一インスタンスは、ホストを垂直方向にスケーリングし、デフォルトのスレッドプールを増やすことで、要求の厳しいワークロードに対応できます。ただし、大きな Java ヒープを管理する処理オーバーヘッドでは、収穫逓減の法則に従って垂直方向のスケーリングが発生します。一般的には、中小規模のワークロードで許容されます。 次の図は、専用 VM で実行される Looker インスタンス、ローカル リポジトリとリモート リポジトリ、SMTP サーバー、このオプションの [利点] セクションと [ベスト プラクティス] セクションでハイライト表示されたデータソース間のデフォルトの設定とオプションの設定を示しています。
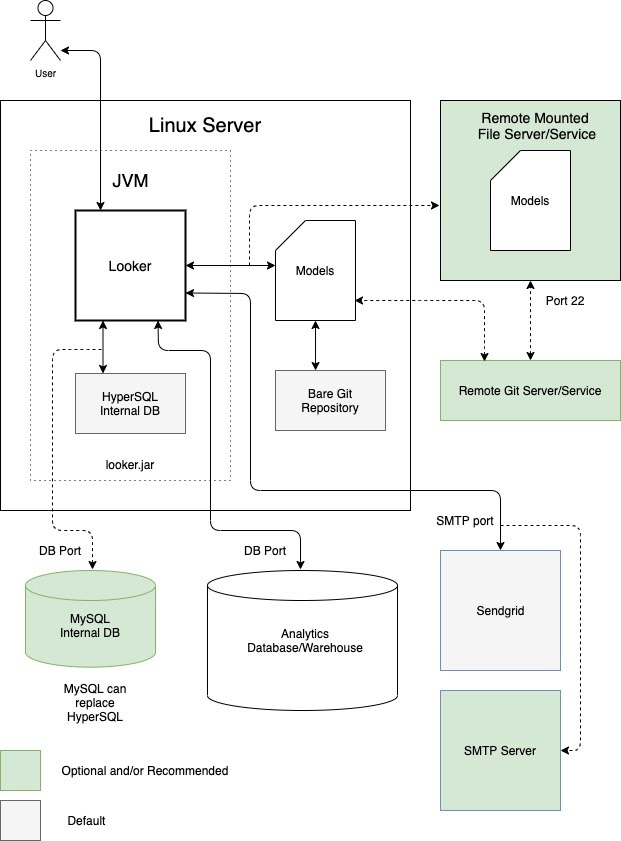
利点
- 専用 VM は、デプロイとメンテナンスが容易です。
- 内部データベースは Looker アプリケーション内でホストされます。
- Looker モデル、Git リポジトリ、SMTP サーバー、バックエンド データベース コンポーネントは、ローカルまたはリモートで構成できます。
- メール通知とスケジュールされたタスク用に、Looker のデフォルトの SMTP サーバーを独自のものに置き換えることができます。
ベスト プラクティス
- デフォルトでは、Looker はプロジェクトのベア Git リポジトリを生成できます。リモート Git リポジトリを設定して冗長性を確保することをおすすめします。
-
デフォルトでは、Looker はメモリ内 HyperSQL データベースから始めます。このデータベースは便利で軽量ですが、頻繁に使用すると、パフォーマンスの問題が発生する可能性があります。大規模なデプロイには MySQL データベースを使用することをおすすめします。
~/looker/.db/looker.scriptファイルが 600 MB に達したら、リモート MySQL データベースに移行することをおすすめします。 - Looker をデプロイするには、Looker のライセンス サービスに対して検証する必要があります。ポート 443 での送信トラフィックが必要です。
- 使用可能なリソースと Looker スレッドプールを増やすことで、専用の VM デプロイを垂直にスケーリングできます。 ただし、ガベージ コレクション イベントがシングル スレッドで実行され、他のスレッドの実行がすべて停止するため、RAM を増やすと、64 GB に達したときに収穫逓減の法則が適用されます。16 個の CPU と 64 GB の RAM を搭載したノードが、価格とパフォーマンスのバランスが良好です。
- デプロイには、GB あたり 1 秒で 2 オペレーション(IOPS)のストレージを使用することをおすすめします。
VM のクラスタ
複数の VM にまたがるインスタンスのクラスタとして Looker を実行することは、サービス フェイルオーバーと冗長性というメリットを享受できる柔軟なパターンです。水平方向のスケーラビリティにより、ヒープの肥大や過度なガベージ コレクションのコストを発生させずに、スループットが向上します。ノードにはワークロード専用のオプションがあり、さまざまなビジネス要件に合わせて複数のデプロイ オプションを調整できます。クラスタのデプロイには、Linux システムに精通し、コンポーネント パーツを管理できるシステム管理者が少なくとも 1 人必要です。
標準クラスタ
ほとんどの標準デプロイでは、同一サービスノードのクラスタで十分です。クラスタ内のすべてのノードは同じ方法で構成され、すべて同じロードバランサ プールにあります。この構成のいずれのノードも、Looker ユーザー リクエスト、レンダリング タスク、スケジュールされたタスク、API リクエストなどを処理する可能性が高くなったり低くなったりすることはありません。
この構成は、クエリを実行して Looker を操作している Looker ユーザーから直接送信されるリクエストが大部分の場合に適しています。スケジューラ、レンダラ、または別のソースから大量のリクエストが送信されると、機能しなくなります。この場合、スケジュールやレンダリングなどのタスクを処理する特定のサービスノードを指定すると便利です。
たとえば、ユーザーは月曜日の朝にデータ配信を実行するように、一般的にスケジュールを設定します。月曜日の朝に Looker クエリを実行しようとすると、Looker がスケジュールされたリクエストのバックログを処理している間にパフォーマンスの問題が発生する可能性があります。サービスノード数を増やせば、クラスタはそれに比例して Looker のすべての機能でスループットを向上させることができます。
次の図は、ユーザー、アプリ、スクリプトからの Looker へのリクエストが、クラスタ化された Looker インスタンス間でどのように分散されるかを示しています。
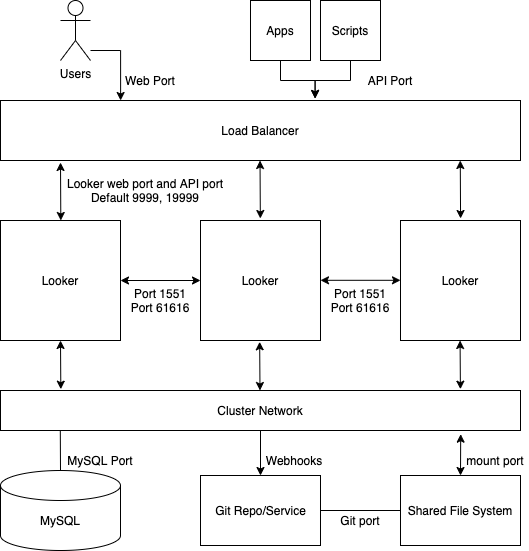
利点
- 標準クラスタでは、クラスタ トポロジの構成を最小限にして、全般的なスループットが最大化されます。
- Java VM は、割り当てられたメモリが 64 GB に達するとパフォーマンスが低下します。そのため、水平スケーリングは垂直スケーリングよりも効果があります。
- クラスタ構成により、サービスの冗長性とフェイルオーバーが確保されます。
ベスト プラクティス
- Looker の各ノードは、専用 VM でホストする必要があります。
- クラスタの Ingress ポイントであるロードバランサは、レイヤ 4 ロードバランサである必要があります。タイムアウトが長く(3,600 秒)、署名付き SSL 証明書を搭載し、ポート 443(https)から 9999(Looker サーバーがリッスンする)のポート転送構成である必要があります。
- デプロイには GB あたり 2 IOPS のストレージを使用することをおすすめします。
開発 / ステージング / 本番
エンドユーザーにとってコンテンツの最大稼働時間を優先するユースケースでは、開発作業と分析作業を分離するために、個別の Looker 環境を使用することをおすすめします。このアーキテクチャでは、隔離された開発環境とテスト環境の背後で本番環境の変更を制御することで、可能な限り安定した本番環境を維持します。
これらの利点には、相互接続された環境の設定と堅牢なリリース サイクルの導入が必要です。開発 / ステージング / 本番のデプロイには、ワークフローを管理するために Looker API と Git について十分に理解したデベロッパー チームも必要となります。
次の図は、Dev インスタンスでコンテンツを開発する LookML デベロッパー、QA インスタンスでコンテンツをテストする品質保証(QA)テスター、Production インスタンスでコンテンツを使用するユーザー、アプリ、スクリプトの間のコンテンツの流れを示しています。
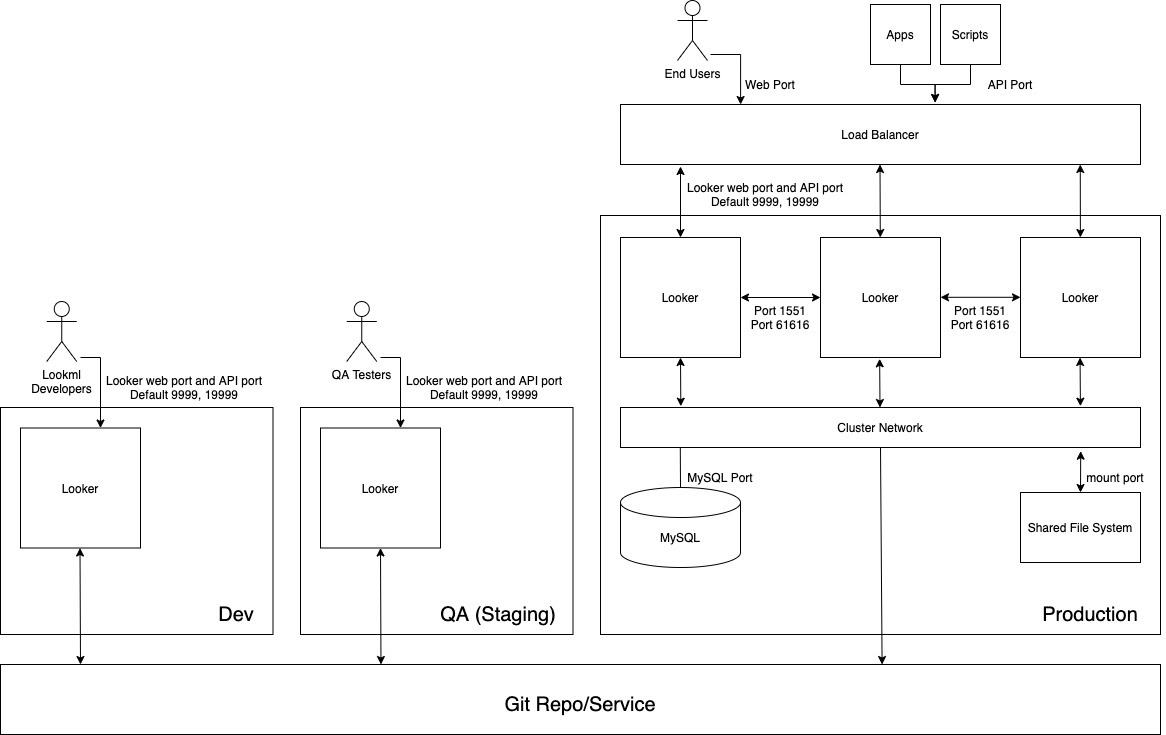
利点
- LookML とコンテンツの検証は非本番環境で行われます。したがって、モデルのロジックに対する変更は、本番環境のユーザーに提供する前に詳細に調査できます。
- Labs 機能や認証プロトコルなどのインスタンス全体の機能は、本番環境で有効にする前に、個別にテストできます。
- データグループとキャッシュ保存ポリシーは、本番環境以外でテストできます。
- Looker の本番環境モードのテストは、エンドユーザーにサービスを提供する本番環境から切り離されます。
- Looker のリリースは非本番環境でテストできるため、本番環境を更新する前に、新機能、ワークフローの変更、問題を十分にテストできます。
ベスト プラクティス
- 同時に発生するさまざまなアクティビティを少なくとも 3 つの別々のインスタンスに分離します。
- 開発インスタンス: デベロッパーは開発環境を使用して、コードを commit し、テストを行い、バグを修正して、安全にミスを犯します。
- QA インスタンス: テスト環境またはステージング環境とも呼ばれ、デベロッパーが手動テストと自動テストを実行します。QA 環境は複雑で、多くのリソースを消費する可能性があります。
- 本番環境インスタンス: お客様やビジネスのために価値が創造される環境。本番環境は目に見える環境であるため、エラーを発生させないようにする必用があります。
- 文書化された、繰り返し可能なリリース サイクルのワークフローを維持します。
- 多数のデベロッパーや QA テスターに対応する必要がある場合は、開発または QA インスタンスをクラスタ化できます。開発 VM と QA インスタンスは、スタンドアロン VM または VM のクラスタのいずれについても、前述の各セクションで示したものと同じアーキテクチャに関する考慮事項が適用されます。
高スケジューリング スループット
スケジュール設定された高いデータ配信スループットとタイムリーで信頼性の高い配信が必要なユースケースでは、スケジュール専用のノードプールを持つクラスタを構成することをおすすめします。この構成により、ウェブ アプリケーションと組み込みアプリケーションの高速性と応答性を維持できます。こうした利点を獲得するには、以下の図に示され、このオプションの [利点] セクションと [ベスト プラクティス] セクションで概説されているように、カスタマイズされた起動オプションと適切なロード バランシング ルールを使用してノードを設定する必要があります。
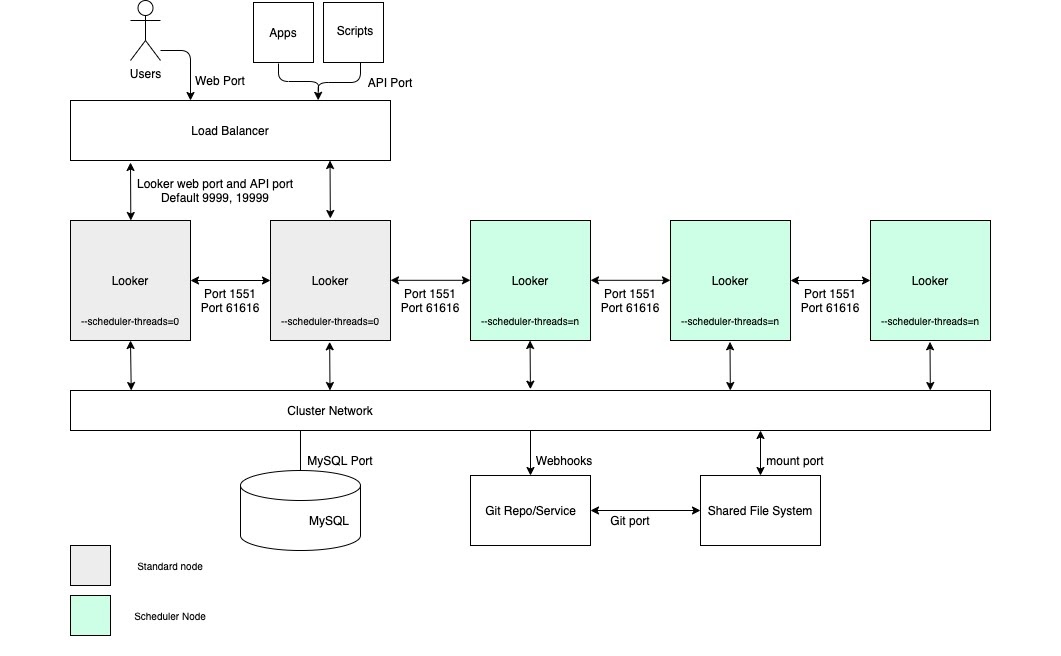
利点
- 特定の関数専用のノードにより、開発やアドホック分析関数から、スケジューリングするためのリソースを区画分けします。
- ユーザーは、LookML を開発し、スケジュールされたデータ配信を処理するノードからのサイクルを経ることなく、コンテンツを探索できます。
- 通常のノードに流れる高いユーザー トラフィックによって、スケジュールするノードによって処理されるスケジュール設定されたワークロードが妨げられることはありません。
ベスト プラクティス
- Looker の各ノードは、専用 VM でホストする必要があります。
- クラスタの Ingress ポイントであるロードバランサは、レイヤ 4 ロードバランサである必要があります。タイムアウトが長く(3,600 秒)、署名付き SSL 証明書を搭載し、ポート 443(https)から 9999(Looker サーバーがリッスンする)のポート転送構成である必要があります。
- エンドユーザー トラフィックと内部 API リクエストが処理されないように、スケジューラ ノードを負荷分散ルールから除外します。
- デプロイには GB あたり 2 IOPS のストレージを使用することをおすすめします。
高レンダリング スループット
高いレンダリング レポートのスループットが必要なユースケースでは、レンダリング専用のノードプールを持つクラスタを構成することをおすすめします。PDF ファイルや PNG / JPEG 画像のレンダリングは、Looker では比較的リソースを消費する処理です。レンダリングはメモリを大量に消費し、CPU の負荷が高くなることがあります。また、Linux がメモリ不足の場合、実行中のプロセスが強制終了される可能性があります。レンダリング ジョブのメモリ使用量は事前に決定できないため、レンダリング ジョブを開始すると Looker プロセスが強制終了される可能性があります。専用のレンダリング ノードを構成すると、インタラクティブ アプリケーションと埋め込みアプリケーションの応答性を維持しながら、レンダリング ジョブを最適に調整できます。
こうした利点を獲得するには、以下の図に示され、このオプションの [利点] セクションと [ベスト プラクティス] セクションで説明されているように、カスタマイズされた起動オプションと適切なロード バランシング ルールを使用してノードを設定する必要があります。また、Looker のレンダリング サービスは、CPU 時間とメモリを共有するサードパーティの Chromium プロセスに依存しているため、レンダリング ノードには標準ノードよりも多くのホストリソースが必要になる場合があります。
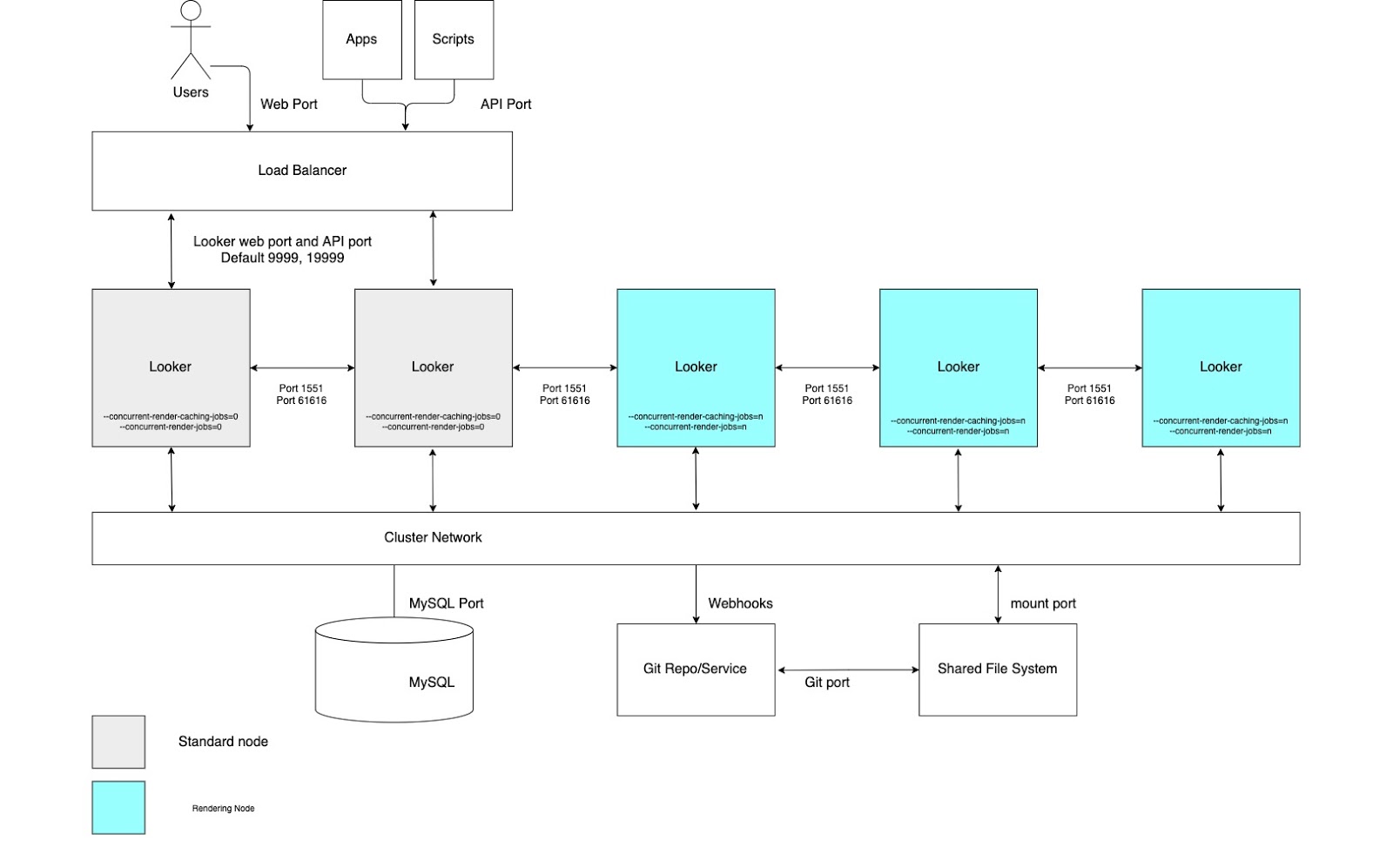
利点
- 特定の関数専用のノードにより、開発やアドホック分析関数から、レンダリングするためのリソースを区画分けします。
- ユーザーは、LookML を開発し、PNG と PDF をレンダリングするノードからのサイクルを経ることなく、コンテンツを探索できます。
- 通常のノードに流れる高いユーザー トラフィックによって、レンダリングするノードによって処理されるレンダリング ワークロードが妨げられることはありません。
ベスト プラクティス
- Looker の各ノードは、専用 VM でホストする必要があります。
- クラスタの Ingress ポイントであるロードバランサは、レイヤ 4 ロードバランサである必要があります。タイムアウトが長く(3,600 秒)、署名付き SSL 証明書を搭載し、ポート 443(https)から 9999(Looker サーバーがリッスンする)のポート転送構成である必要があります。
- エンドユーザー トラフィックと内部 API リクエストが処理されないように、スケジューラ ノードを負荷分散ルールから除外します。
- レンダリング ノードで Java に割り当てるメモリを比較的少なくして、Chromium のプロセスに大きなメモリバッファを割り当てます。メモリの 60% を Java に割り当てるのではなく、40 ~ 50% を割り当てます。
- レンダリングされていないノードではメモリ負荷のリスクが軽減されたため、Looker 専用のメモリ量を増やすことができます。デフォルトの 60% ではなく 80% などの大きい数字を検討してください。
- デプロイには GB あたり 2 IOPS のストレージを使用することをおすすめします。