その他の詳細については、集約テーブルの自動認識のドキュメント ページをご覧ください。
はじめに
このページは、実際のシナリオで集約テーブルの自動認識を実装するためのガイドです。実装する機会の特定、集約テーブルの自動認識が推進する価値、実際のモデルで実装するための簡単なワークフローなどについて説明します。このページは、すべての集約テーブルの自動認識の機能やエッジケースの詳細な説明ではありません。また、そのすべての機能を網羅したカタログでもありません。
集約テーブルの自動認識とは
Looker では、主にデータベース内の生テーブルまたはビューに対してクエリを実行します。Looker の永続的な派生テーブル(PDT)である場合もあります。
非常に大きなデータセットやテーブルが発生し、パフォーマンスを改善させるために集約テーブルやロールアップが必要になることがあります。
一般的に、限定されたディメンションを含む orders_daily テーブルのような集約テーブルを作成できます。これらは、Explore で個別に扱い、個別にモデル化する必要があり、モデルにきちんと配置されていません。これらの制限により、ユーザーが同じデータで複数の Explore を選択する必要がある場合、ユーザー エクスペリエンスが低下します。
今では、Looker の集約テーブルの自動認識により、さまざまな粒度、ディメンション、集計に対する集約テーブルを事前構築できます。そして、既存の Explore でそれらを使用する方法を Looker に知らせることができます。その後、クエリは、Looker が適切と判断するこうしたロールアップ テーブルを、ユーザーからの入力なしで使用します。これにより、クエリのサイズが削減され、待ち時間が短縮されて、ユーザー エクスペリエンスが向上します。
注: Looker の集約テーブルは永続派生テーブル(PDT)の一種です。つまり、集約テーブルのデータベースと接続の要件は PDT と同じです。データベース言語と Looker 接続が PDT をサポートできるかどうかを確認するには、Looker の派生テーブルのドキュメント ページに記載されている要件をご覧ください。
データベース言語が集約テーブルの自動認識をサポートしているかどうかを確認するには、集約テーブルの自動認識のドキュメント ページをご覧ください。
集約テーブルの自動認識の価値
既存の Looker モデルからさらなる価値を生み出すために、集約テーブルの自動認識には数多くの価値提案がある。
- パフォーマンス向上: 集約テーブルの自動認識の実装により、ユーザークエリが高速化します。ユーザーのクエリの完了に必要なデータが含まれていれば、Looker は小さなテーブルを使用します。
- 費用削減: 消費モデルでのクエリのサイズによって、一定の言語料金が課されます。Looker クエリのテーブルを小さくすれば、ユーザーのクエリあたりの費用を削減可能。
- ユーザー エクスペリエンスの向上: 回答をより迅速に取得するエクスペリエンスの向上に加えて、統合すると冗長な Explore の作成が不要。
- LookML のフットプリントの削減: 既存の Liquid を使用した集約テーブルの自動認識の戦略を、柔軟でネイティブな実装に置き換えることで、復元力が高まりエラーが減少。
- 既存の LookML の活用: 集約テーブルでは、明示的なカスタム SQL を使用してロジックを複製するのではなく、既存のモデル化されたロジックを再利用する
queryオブジェクトを使用します。
基本的な例
ここでは、Looker モデルでの非常に単純な実装で、集約テーブルの自動認識がいかに軽量になるかを説明します。FAA を通じて記録されたすべてのフライトの行がある、データベース内の仮想的な flights テーブルを考えると、独自のビューと Explore を使用して Looker でこのテーブルをモデル化できます。Explore 用に定義できる集約テーブルの LookML は次のとおりです。
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
この集約テーブルを使用して、ユーザーは flights Explore をクエリできます。Looker は、LookML で定義された集約テーブルを自動的に活用し、集約テーブルを使用してクエリに回答します。Looker に特別な条件を伝える必要はありません。ユーザーが選択したフィールドにテーブルが適合する場合、Looker がそのテーブルを使用します。
see_sql 権限を持つユーザーは、Explore の [SQL] タブのコメントを使用して、クエリに使用される集約テーブルを確認できます。
集約テーブル flights:flights_by_week_and_carrier in teach_scratch を使用するクエリ用の Looker の [SQL] タブの例を次に示します。
![基本的な SQL を表示する Explore と、使用されている集約テーブルのスクラッチ スキーマを指定するコメントの [SQL] タブ。](https://cloud.google.com/static/looker/docs/images/hc-aggaware-orig-sql-withagg.png?hl=ja)
集約テーブルがクエリに使用されているかどうかを判断する方法については、集約テーブルの自動認識のドキュメント ページをご覧ください。
販売機会の特定
集約テーブルの自動認識のメリットを最大限に活用するには、最適化または集約テーブルの自動認識の価値を促進するうえで、集約テーブルの自動認識が果たす役割を特定する必要があります。
高ランタイムを持つダッシュボードを特定する
集約テーブルの自動認識が非常に優れているところは、1 つには実行時間が非常に長く、使用頻度が高いダッシュボードの集約テーブルを作成できることですお客様からは、遅いダッシュボードについて話を聞くことがあるかもしれませんが、see_system_activity がある場合は、Looker の システムアクティビティ履歴 Explore を使用して、平均ランタイムよりも遅いダッシュボードを見つけることもできます。ブラウザで次の URL を使用し、HOSTNAME を Looker インスタンスの名前に置き換えるのが簡単です(例: example.cloud.looker.com)。
https://HOSTNAME/explore/system__activity/history?fields=dashboard.title,dashboard.link,history.count,history.average_runtime,history.cache_result_query_count,history.database_result_query_count,query.count_of_explores&f[history.created_date]=30+days&f[dashboard.title]=-NULL%2C-Limejump+Dashboard&sorts=history.count+desc&limit=500&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22gray%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_column_widths%22%3A%7B%22dashboard.link%22%3A80%2C%22history.average_runtime%22%3A94%2C%22history.count%22%3A96%7D%2C%22series_cell_visualizations%22%3A%7B%22history.count%22%3A%7B%22is_active%22%3Afalse%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%232196F3%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22constraints%22%3A%7B%22min%22%3A%7B%22type%22%3A%22minimum%22%7D%2C%22mid%22%3A%7B%22type%22%3A%22number%22%2C%22value%22%3A0%7D%2C%22max%22%3A%7B%22type%22%3A%22maximum%22%7D%7D%2C%22mirror%22%3Atrue%2C%22reverse%22%3Atrue%2C%22stepped%22%3Afalse%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%2C%22hidden_fields%22%3A%5B%22history.cache_result_query_count%22%2C%22history.database_result_query_count%22%2C%22dashboard.link%22%5D%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22dashboard.title%22%3A%5B%7B%22type%22%3A%22%21null%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22%22%7D%2C%7B%7D%5D%2C%22id%22%3A2%2C%22error%22%3Afalse%7D%2C%7B%22type%22%3A%22%21%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Limejump+Dashboard%22%7D%2C%7B%7D%5D%2C%22id%22%3A3%2C%22error%22%3Afalse%7D%5D%7D&dynamic_fields=%5B%7B%22table_calculation%22%3A%22ratio_from_cache_vs_database%22%2C%22label%22%3A%22Ratio+from+Cache+vs+Database%22%2C%22expression%22%3A%22%24%7Bhistory.cache_result_query_count%7D%2F%24%7Bhistory.database_result_query_count%7D%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3A%22decimal_2%22%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22number%22%7D%2C%7B%22table_calculation%22%3A%22is_performing_worse_than_mean%22%2C%22label%22%3A%22Is+Performing+Worse+Than+Mean%22%2C%22expression%22%3A%22%24%7Bhistory.average_runtime%7D%3Emean%28%24%7Bhistory.average_runtime%7D%29%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3Anull%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22yesno%22%7D%5D&origin=share-expanded" rel="undefined">this System Activity History Explore link
タイトル、履歴、Explore の数、キャッシュとデータベースの比率、平均以下のパフォーマンスといったインスタンスのダッシュボードに関するデータを使用して、Explore が可視化されます。
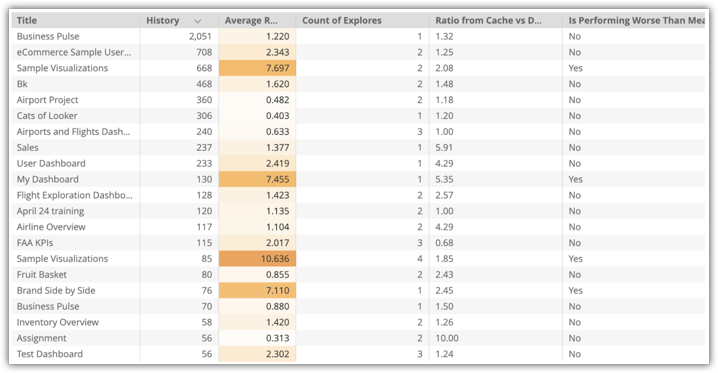
この例には、[サンプル ビジュアリゼーション] ダッシュボードなど、使用率が高く、平均よりパフォーマンスが低いダッシュボードが複数あります。[サンプル ビジュアリゼーション] ダッシュボードでは 2 つの Explore を使用するため、両方の Explore で集約テーブルを作成することをおすすめします。
遅く、ユーザーによって頻繁にクエリが実行される Explore を特定する
集約テーブルの自動認識のもう 1 つの機会は、ユーザーによるクエリ実行が頻繁に行われ、クエリのレスポンスが平均未満である Explore についてです。
[システムアクティビティ履歴 Explore] は、Explore を最適化する機会を特定するための出発点として使用できます。ブラウザで次の URL を使用し、HOSTNAME を Looker インスタンスの名前に置き換えるのが簡単です(例: example.cloud.looker.com)。
https://HOSTNAME/explore/system__activity/history?fields=query.view,history.query_run_count,user.count,query.model,history.average_runtime&f[history.created_date]=30+days&f[history.source]=Explore&sorts=history.query_run_count+desc&limit=15&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22white%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_labels%22%3A%7B%22user.count%22%3A%22User+Count%22%7D%2C%22series_column_widths%22%3A%7B%22query.model%22%3A179%2C%22query.view%22%3A128%7D%2C%22series_cell_visualizations%22%3A%7B%22history.query_run_count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A106%7D%2C%22user.count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A108%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%233EB0D5%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22reverse%22%3Atrue%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22truncate_column_names%22%3Afalse%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22history.source%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Explore%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Explore、モデル、クエリ実行数、ユーザー数、平均ランタイム(秒)といった、インスタンスの Explore に関するデータを使用して Explore が可視化されます。

History Explore では、インスタンスで次のタイプの Explore を特定できます。
- ユーザーによってクエリされる Explore(API からのクエリ、またはスケジュールされた配信からのクエリからではなく)
- 頻繁にクエリされる Explore
- パフォーマンスが低い(他の Explore と比較して)Explore
前述のシステム アクティビティ履歴 Explore の例では、flights と order_items の Explore が、集約テーブルの自動認識実装の候補になります。
クエリで頻繁に使用されるフィールドを特定する
最後に、クエリやフィルタによく使用されるフィールドを把握することで、データレベルで他の機会を特定することが可能となります。
ブラウザで次の URL を使用し、HOSTNAME を Looker インスタンスの名前に置き換えるのが簡単です(例: example.cloud.looker.com)。
https://HOSTNAME/explore/system__activity/field_usage?fields=field_usage.model,field_usage.explore,field_usage.field,field_usage.times_used&f[field_usage.model]=faa%2C%22advanced_data_analyst_bootcamp%22&f[field_usage.explore]=flights%2C%22order_items%22&sorts=field_usage.times_used+desc&limit=500&query_timezone=America%2FNew_York&vis=%7B%22x_axis_gridlines%22%3Afalse%2C%22y_axis_gridlines%22%3Atrue%2C%22show_view_names%22%3Afalse%2C%22show_y_axis_labels%22%3Atrue%2C%22show_y_axis_ticks%22%3Atrue%2C%22y_axis_tick_density%22%3A%22default%22%2C%22y_axis_tick_density_custom%22%3A5%2C%22show_x_axis_label%22%3Atrue%2C%22show_x_axis_ticks%22%3Atrue%2C%22y_axis_scale_mode%22%3A%22linear%22%2C%22x_axis_reversed%22%3Afalse%2C%22y_axis_reversed%22%3Afalse%2C%22plot_size_by_field%22%3Afalse%2C%22trellis%22%3A%22%22%2C%22stacking%22%3A%22%22%2C%22limit_displayed_rows%22%3Atrue%2C%22legend_position%22%3A%22center%22%2C%22point_style%22%3A%22none%22%2C%22show_value_labels%22%3Afalse%2C%22label_density%22%3A25%2C%22x_axis_scale%22%3A%22auto%22%2C%22y_axis_combined%22%3Atrue%2C%22ordering%22%3A%22none%22%2C%22show_null_labels%22%3Afalse%2C%22show_totals_labels%22%3Afalse%2C%22show_silhouette%22%3Afalse%2C%22totals_color%22%3A%22%23808080%22%2C%22limit_displayed_rows_values%22%3A%7B%22show_hide%22%3A%22show%22%2C%22first_last%22%3A%22first%22%2C%22num_rows%22%3A%2215%22%7D%2C%22series_types%22%3A%7B%7D%2C%22type%22%3A%22looker_bar%22%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22field_usage.model%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22faa%2Cadvanced_data_analyst_bootcamp%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22field_usage.explore%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22flights%2Corder_items%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
適宜フィルタを置き換えます。フィールドがクエリで使用された回数を棒グラフで視覚化した Explore が表示されます。
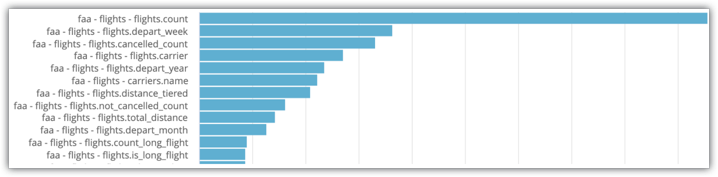
画像に示されている System Activity Explore の例では、flights.count と flights.depart_week が Explore で最も一般的に選択されている 2 つのフィールドであることがわかります。このため、これらは集約テーブルに含めるフィールドに適しています。
このような具体的なデータは便利ですが、選択基準の指針となる主観的な要素があります。たとえば、前の 4 つの項目を確認すると、ユーザーは予定したフライト数とキャンセルされたフライト数をよく見ており、そのデータを週間別、運送業者別の両方に分類することを望んでいると確かに推測できます。これは、フィールドと指標の明確で論理的な実際の組み合わせの例です。
概要
このドキュメント ページの手順は、最適化を考慮する必要があるダッシュボード、Explore、フィールドを見つけるためのガイドとしてご利用ください。また、これら 3 つはすべて相互排他的である可能性があることも理解しておく必要があります。問題のあるダッシュボードは、問題のある Explore を活用していない可能性があります。また、よく使用されるフィールドを含む集約テーブルを作成しても、これらのダッシュボードでまったく機能しない可能性もあります。3 つの個別の集約テーブルの自動認識の実装が考えられます。
集約テーブルの設計
集約テーブルの自動認識の機会を特定したら、これらの機会に最適な集約テーブルを設計できます。集約テーブルでサポートされているフィールド、メジャー、期間、および集約テーブルを設計するためのその他のガイドラインについては、集約テーブルの自動認識のドキュメント ページをご覧ください。
注: 集約テーブルは、クエリを使用するために完全に一致する必要はありません。クエリが 1 週間ごとの粒度で、日次ロールアップ テーブルがある場合は、Looker は未加工のタイムスタンプ テーブルの代わりに集約テーブルを使用します。同様に、brandとdateレベルにロールアップされる集約テーブルと、brandレベルにのみロールアップされるユーザークエリがある場合、そのテーブルは引き続き、Looker で集約テーブルの自動認識に使用するための候補になります。
集約テーブルの自動認識は、以下のメジャーでサポートされています。
- 標準メジャー: タイプ SUM、COUNT、AVERAGE、MIN、MAX のメジャー
- 複合メジャー: タイプ NUMBER、STRING、YESNO、DATE のメジャー
- 近似区分メジャー: HyperLogLog 機能を使用可能な言語
集約テーブルの自動認識は、以下のメジャーではサポートされていません。
- 区分メジャー: 区分性は、アトミックな非集約データでのみ計算可能なため、
*_DISTINCTメジャーは、HyperLogLog を使用するこれらの近似の外ではサポートされていません。 - カーディナリティ ベースのメジャー: 区分メジャーと同様に、中央値とパーセンタイルは事前集約ができず、サポートされていません。
注: 集約テーブルの自動認識でサポートされないメジャーのタイプを使用したユーザークエリがあることがわかっている場合は、クエリに完全に一致する集約テーブルを作成する場合があります。クエリと完全に一致する集約テーブルは、集約テーブルの自動認識でサポートされることのないメジャータイプを使用したクエリに対して回答を得るために使用することができます。
集約テーブルの粒度
ディメンションとメジャーの組み合わせのテーブルを構築する前に、使用とフィールド選択の共通パターンを特定し、使用頻度が高く、影響の大きい集約テーブルを作成します。テーブルをクエリで使用するようにするには、クエリで使用されるすべてのフィールド(選択済みまたはフィルタ済み)が集約テーブルに存在する必要があります。ただし前述したように、クエリに使用される集約テーブルは、クエリと完全に一致している必要はありません。1 つの集約テーブル内の多数の潜在的ユーザー クエリに対処でき、かつ、パフォーマンスが大幅に向上します。
クエリで頻繁に使用されるフィールドの特定の例では、頻繁に選択される 2 つのディメンション(flights.depart_week と flights.carrier)と 2 つのメジャー( flights.count と flights.cancelled_count)があります。したがって、これら 4 つのフィールドすべてを使用する集約テーブルを構築することは理にかなっています。さらに、flights_by_week_and_carrier 用の 1 つの集約テーブルを作成すると、flights_by_week テーブルと flights_by_carrier テーブルの 2 つの異なる集約テーブルを使用するよりも集約テーブルの使用頻度が高くなります。
次に示すのは、一般的なフィールドに対するクエリ用に作成する集約テーブルの例です。
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
ビジネス ユーザーと事例証拠、さらには Looker のシステム アクティビティからのデータは、意思決定プロセスのガイドとして役立ちます。
適用範囲とパフォーマンスのバランス
次の例は、flights_by_week_and_carrier 集約テーブルの Flights Depart Week、Flights Details Carrier、Flights Count、Flights Detailed Cancelled Count の各フィールドの Explore クエリを示しています。
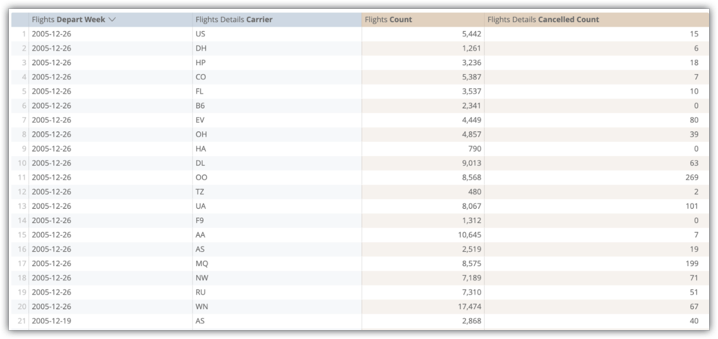
元のデータベース テーブルからのこのクエリの実行は 15.8 秒かかり、Amazon Redshift を使用して結合せずに 3,800 万行をスキャンしました。通常のユーザー オペレーションであるクエリのピボットには 29.5 秒かかりました。
flights_by_week_and_carrier 集約テーブルを実装した後、後続のクエリは 7.2 秒 かかり、4,592 行をスキャンしました。これは、99.98% のテーブルのサイズの削減です。クエリのピボットには 9.8 秒かかりました。
システム アクティビティ フィールド使用状況 Explore で、ユーザーがクエリにこれらのフィールドを含める頻度を確認できます。この例では、flights.count が 47,848 回、flights.depart_week が 18,169 回、flights.cancelled_count が 16,570 回、flights.carrier が 13,517 回使用されています。
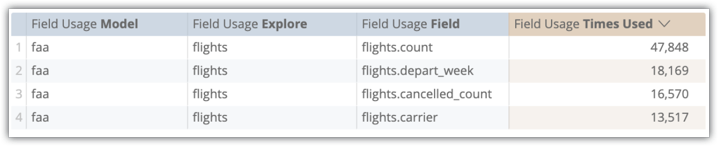
控え目に概算して、クエリの 25% が最も単純な方法(単純な SELECT、ピボットなし)で 4 つのフィールドをすべて使用したとすると、3,379 × 8.6 秒 = 8 時間 4 分の合計ユーザー待機時間が推定されます。
注: ここで使用したサンプル モデルは、ごく基本的なものです。これらの結果をモデルのベンチマークや参照フレームとして使用しないでください。
e コマースモデル order_items(インスタンスで頻繁に使用される Explore)にまったく同じフローを適用すると、結果は次のようになります。
| ソース | Query Time | スキャンされた行数 |
|---|---|---|
| ベーステーブル | 13.1 秒 | 285,000 |
| 集約テーブル | 5.1 秒 | 138,000 |
| デルタ | 8 秒 | 147,000 |
クエリと後続の集約テーブルで使用されるフィールドは、2 つの結合を使用した brand、created_date、orders_count、total_revenue でした。フィールドは、合計 11,000 回使用されました。同じく合計の使用を 25% と推定すると、ユーザーの合計短縮時間は 6 時間 6 分(8 秒 × 2,750 = 22,000 秒)になります。集約テーブルの構築には 17.9 秒かかりました。
以上の結果を見れば、しばらく考えて、生み出される可能性のあるメリットを評価することをおすすめします。
- 「許容できる」パフォーマンスで、より良いモデリング手法からパフォーマンスの向上が得られるかも知れない、より大規模で複雑なモデル / Explore の最適化
対
- 集約テーブルの自動認識を使用して、使用頻度が高くパフォーマンスが低い、より単純なモデルの最適化
Looker とデータベースからパフォーマンスをぎりぎりまで得ようとすると、努力に対するリターンが減少していくのがわかります。ベースラインのパフォーマンスの期待値(特にビジネス ユーザーからの期待値)と、データベースによって課せられる制限(同時実行、クエリのしきい値、費用など)を常に認識しておく必要があります。このような制限を克服するために、集約テーブルに期待すべきではありません。
また、集約テーブルを設計する際は、フィールドが多いほど集約テーブルのサイズが大きく、遅くなることに注意してください。テーブルのサイズが大きいほど多くのクエリを最適化できるため、より多くの状況で使用できますが、大きいテーブルは、より小さく、単純なテーブルほど高速ではありません。
例:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week,flights.distance, flights.arrival_week,flights.cancelled]
measures: [cancelled_count, count, flights.average_distance, flights.total_distance]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}これにより、表示されるディメンションとメジャーの組み合わせに集約テーブルが使用されるため、このテーブルを使用して、さまざまなユーザークエリに答えることができます。しかし、このテーブルを carrier と count のシンプルな SELECT クエリに使用するには、885,000 行のテーブルをスキャンする必要があります。これに対し、テーブルが 2 つのディメンションに基づいている場合、同じクエリでスキャンが必要なのは 4,592 行のみです。885,000 行のテーブルは、(以前の 3,800 万行から)テーブルサイズを 97% 削減したものですが、ディメンションをもう 1 つ追加すると、テーブルサイズが 2,000 万行になります。そのため、クエリに対する適用範囲を増やすために集約テーブルに含めるフィールドを増やすにつれて、リターンは減少します。
集約テーブルの構築
最適化の機会として特定したフライト Explore の例の場合、最適な戦略は、3 つの異なる集約テーブルを作成することです。
-
flights_by_week_and_carrier -
flights_by_month_and_distance -
flights_by_year
これらの集約テーブルを作成する最も簡単な方法は、Explore のクエリまたはダッシュボードから LookML の集約テーブルを取得して、Looker プロジェクト ファイルに LookML を追加することです。
集約テーブルを LookML プロジェクトに追加し、更新内容を本番環境にデプロイすると、Explore では集約テーブルをユーザーのクエリに利用します。
永続性
集約テーブルの自動認識にアクセスするには、データベースで集約テーブルを保持する必要があります。データグループを利用して、これらの集約テーブルの自動更新をキャッシュ ポリシーに合わせることをおすすめします。関連付けられた Explore で使用されている集約テーブルには、同じデータグループを使用する必要があります。データグループを使用できない場合は、代わりに sql_trigger_value パラメータを使用することもできます。sql_trigger_value の一般的な日付ベースの値を以下に示します。
sql_trigger_value: SELECT CURRENT_DATE() ;;
これにより、毎日深夜に集約テーブルが自動的に構築される。
期間のロジック
Looker で集約テーブルが作成されると、集約テーブルを作成した時点までのデータが格納されます。その後データベース内のベーステーブルに追加されたデータは、通常、その集約テーブルを使用したクエリの結果から除外されます。
次の図は、注文を受け取ってデータベースのログに記録されたタイムラインと Orders 集約テーブルが作成された日時を比較したものです。集約テーブルの作成後に注文を受け取ったため、注文集約テーブルにはない、今日受け付けた 2 つの注文があります。
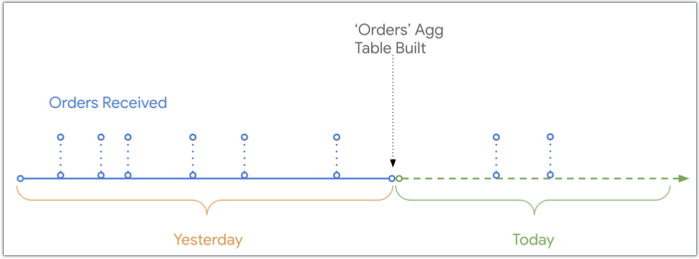
ただし、同じタイムライン図に示すように、ユーザーが集約テーブルと重複する期間をクエリすると、Looker が集約テーブルに新しいデータを UNION で結合できます。
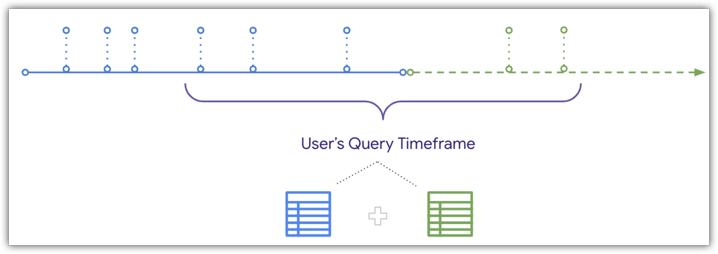
Looker では集約テーブルに新しいデータを UNION で結合できるため、集約テーブルとベーステーブルの両方の最後で重複する期間を設定すると、集約テーブルの作成後に受信した注文がユーザー結果に含まるようになります。詳細、および、新しいデータを集約テーブルのクエリに UNION 結合するために必要な条件については、集約テーブルの自動認識のドキュメント ページをご覧ください。
概要
まとめると、集約テーブルの自動認識の実装の構築には、次の 3 つの基本的なステップがあります。
- 集約テーブルを使用した最適化が適切で、影響の大きい箇所を特定する。
- 一般的なユーザークエリのほとんどをカバーしつつ、クエリのサイズを十分に小さくできる集約テーブルを設計する。
- 集約テーブルを Looker モデルで構築し、テーブルの永続性を Explore のキャッシュの永続性と組み合わせる。