Sie können den Datencache nur mit GKE Standard-Clustern verwenden. In dieser Anleitung wird beschrieben, wie Sie GKE Data Cache aktivieren, wenn Sie einen neuen GKE Standard-Cluster oder einen Knotenpool erstellen, und wie Sie GKE-angehängte Laufwerke mit Data Cache-Beschleunigung bereitstellen.
GKE-Datencache
Mit GKE Data Cache können Sie lokale SSDs auf Ihren GKE-Knoten als Cacheebene für Ihren persistenten Speicher wie nichtflüchtige Speicher oder Hyperdisks verwenden. Durch die Verwendung lokaler SSDs wird die Leselatenz von Festplatten verringert und die Anzahl der Abfragen pro Sekunde für Ihre zustandsorientierten Arbeitslasten erhöht, während der Speicherbedarf minimiert wird. GKE Data Cache unterstützt alle Arten von Persistent Disk oder Hyperdisk als Sicherungslaufwerke.
Wenn Sie GKE Data Cache für Ihre Anwendung verwenden möchten, konfigurieren Sie Ihren GKE-Knotenpool mit angehängten lokalen SSDs. Sie können GKE Data Cache so konfigurieren, dass die gesamte oder ein Teil der angehängten lokalen SSD verwendet wird. Lokale SSDs, die von der GKE Data Cache-Lösung verwendet werden, werden im Ruhezustand mit der Standardverschlüsselung Google Cloud verschlüsselt.
Vorteile
GKE Data Cache bietet folgende Vorteile:
- Höhere Anzahl von Abfragen, die pro Sekunde für herkömmliche Datenbanken wie MySQL oder Postgres und Vektordatenbanken verarbeitet werden.
- Verbesserte Leseleistung für zustandsorientierte Anwendungen durch Minimierung der Festplattenlatenz.
- Schnellere Daten-Hydrierung und ‑Rehydrierung, da sich die SSDs lokal auf dem Knoten befinden. Data Hydration bezieht sich auf den anfänglichen Prozess des Ladens der erforderlichen Daten aus dem nichtflüchtigen Speicher auf die lokale SSD. Datenrehydrierung bezieht sich auf den Prozess der Wiederherstellung der Daten auf den lokalen SSDs nach dem Recycling eines Knotens.
Bereitstellungsarchitektur
Das folgende Diagramm zeigt ein Beispiel für eine GKE Data Cache-Konfiguration mit zwei Pods, in denen jeweils eine App ausgeführt wird. Die Pods werden auf demselben GKE-Knoten ausgeführt. Jeder Pod verwendet eine separate lokale SSD und einen zugrunde liegenden nichtflüchtigen Speicher.
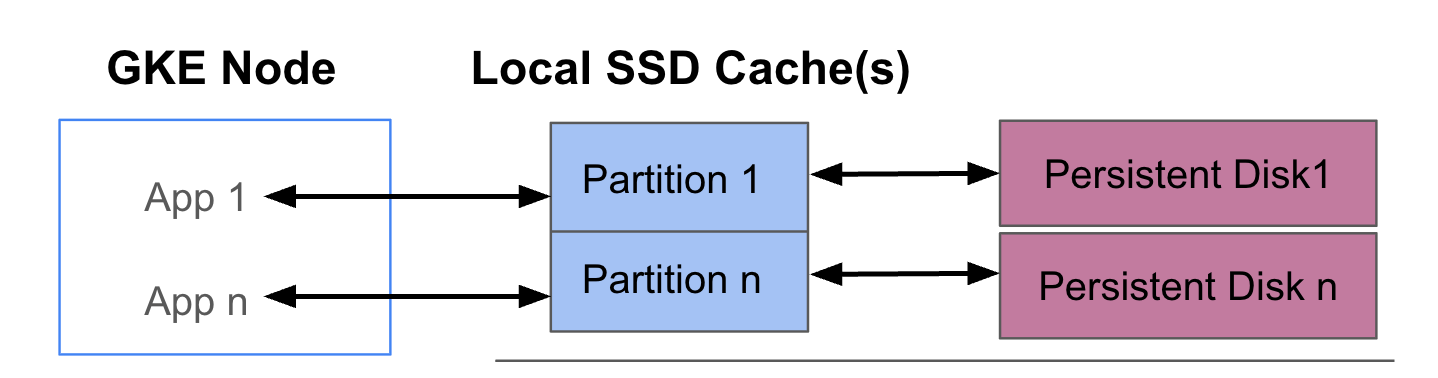
Bereitstellungsmodi
Sie können GKE Data Cache in einem von zwei Modi einrichten:
- Writethrough (empfohlen): Wenn Ihre Anwendung Daten schreibt, werden die Daten synchron sowohl in den Cache als auch auf die zugrunde liegende nichtflüchtige Festplatte geschrieben. Im Modus
writethroughwird Datenverlust verhindert und er eignet sich für die meisten Produktionsarbeitslasten. - Rückschreiben: Wenn Ihre Anwendung Daten schreibt, werden die Daten nur in den Cache geschrieben. Die Daten werden dann asynchron (im Hintergrund) auf den nichtflüchtigen Speicher geschrieben. Der Modus
writebackverbessert die Schreibleistung und eignet sich für Arbeitslasten, bei denen es auf Geschwindigkeit ankommt. Dieser Modus beeinträchtigt jedoch die Zuverlässigkeit. Wenn der Knoten unerwartet heruntergefahren wird, gehen nicht geleerte Cache-Daten verloren.
Ziele
In diesem Leitfaden erfahren Sie, wie Sie:
- Erstellen Sie eine zugrunde liegende GKE-Infrastruktur, um GKE Data Cache zu verwenden.
- Erstellen Sie einen dedizierten Knotenpool mit angehängten lokalen SSDs.
- Erstellen Sie eine StorageClass für die dynamische Bereitstellung eines PersistentVolume (PV), wenn ein Pod sie über einen PersistentVolumeClaim (PVC) anfordert.
- Erstellen Sie einen PVC, um ein PV anzufordern.
- Erstellen Sie ein Deployment, das einen PVC verwendet, um sicherzustellen, dass Ihre Anwendung auch nach einem Neustart eines Pods und während der Neuplanung Zugriff auf persistenten Speicher hat.
Anforderungen und Planung
Achten Sie darauf, dass Sie die folgenden Anforderungen für die Verwendung von GKE Data Cache erfüllen:
- Auf Ihrem GKE-Cluster muss Version 1.32.3-gke.1440000 oder höher ausgeführt werden.
- Für Ihre Knotenpools müssen Maschinentypen verwendet werden, die lokale SSDs unterstützen. Weitere Informationen finden Sie unter Unterstützung für Maschinenserien.
Planung
Berücksichtigen Sie die folgenden Aspekte, wenn Sie die Speicherkapazität für GKE Data Cache planen:
- Die maximale Anzahl von Pods pro Knoten, die GKE Data Cache gleichzeitig verwenden.
- Die erwarteten Cachegrößenanforderungen von Pods, die GKE Data Cache verwenden.
- Die Gesamtkapazität der auf Ihren GKE-Knoten verfügbaren lokalen SSDs. Informationen dazu, bei welchen Maschinentypen standardmäßig lokale SSDs angehängt sind und bei welchen Sie lokale SSDs anhängen müssen, finden Sie unter Gültige Anzahl lokaler SSD-Laufwerke auswählen.
- Bei Maschinentypen der dritten oder einer späteren Generation (an die eine Standardanzahl lokaler SSDs angehängt ist) werden die lokalen SSDs für den Datencache aus den insgesamt verfügbaren lokalen SSDs auf dieser Maschine reserviert.
- Der Dateisystem-Overhead, der den nutzbaren Speicherplatz auf lokalen SSDs verringern kann. Selbst wenn Sie beispielsweise einen Knoten mit zwei lokalen SSDs mit einer rohen Gesamtkapazität von 750 GiB haben, ist der verfügbare Speicherplatz für alle Data Cache-Volumes aufgrund des Dateisystem-Overheads möglicherweise geringer. Ein Teil der lokalen SSD-Kapazität ist für die Systemnutzung reserviert.
Beschränkungen
Inkompatibilität mit Backup for GKE
Um die Datenintegrität in Szenarien wie der Notfallwiederherstellung oder der Anwendungsmigration aufrechtzuerhalten, müssen Sie Ihre Daten möglicherweise sichern und wiederherstellen. Wenn Sie Backup for GKE verwenden, um einen PVC wiederherzustellen, der für die Verwendung des Datencache konfiguriert ist, schlägt der Wiederherstellungsvorgang fehl. Dieser Fehler tritt auf, weil beim Wiederherstellungsvorgang die erforderlichen Daten-Cache-Parameter nicht korrekt von der ursprünglichen StorageClass übernommen werden.
Preise
Ihnen wird die gesamte bereitgestellte Kapazität Ihrer lokalen SSDs und der angehängten nichtflüchtigen Speicher in Rechnung gestellt. Die Abrechnung erfolgt pro GiB und Monat.
Weitere Informationen finden Sie in der Compute Engine-Dokumentation unter Laufwerkspreise.
Hinweise
Führen Sie die folgenden Aufgaben aus, bevor Sie beginnen:
- Aktivieren Sie die Google Kubernetes Engine API. Google Kubernetes Engine API aktivieren
- Wenn Sie die Google Cloud CLI für diesen Task verwenden möchten, müssen Sie die gcloud CLI installieren und dann initialisieren. Wenn Sie die gcloud CLI bereits installiert haben, rufen Sie die neueste Version mit dem Befehl
gcloud components updateab. In früheren gcloud CLI-Versionen werden die Befehle in diesem Dokument möglicherweise nicht unterstützt.
- Sehen Sie sich die Maschinentypen an, die lokale SSDs unterstützen.
GKE-Knoten für die Verwendung des Datencache konfigurieren
Damit Sie GKE Data Cache für beschleunigten Speicher verwenden können, müssen Ihre Knoten die erforderlichen lokalen SSD-Ressourcen haben. In diesem Abschnitt finden Sie Befehle zum Bereitstellen lokaler SSDs und zum Aktivieren von GKE Data Cache, wenn Sie einen neuen GKE-Cluster erstellen oder einem vorhandenen Cluster einen neuen Knotenpool hinzufügen. Sie können einen vorhandenen Knotenpool nicht so aktualisieren, dass er den Datencache verwendet. Wenn Sie Data Cache in einem vorhandenen Cluster verwenden möchten, fügen Sie dem Cluster einen neuen Knotenpool hinzu.
In einem neuen Cluster
Verwenden Sie den folgenden Befehl, um einen GKE-Cluster mit konfiguriertem Data Cache zu erstellen:
gcloud container clusters create CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
Ersetzen Sie Folgendes:
CLUSTER_NAMEist der Name des Clusters. Geben Sie einen eindeutigen Namen für den GKE-Cluster ein, den Sie erstellen.LOCATION: Die Google Cloud Region oder Zone für den neuen Cluster.MACHINE_TYPE: Der Maschinentyp, der für Ihren Cluster aus einer Maschinenserie der zweiten, dritten oder einer späteren Generation verwendet werden soll, z. B.n2-standard-2oderc3-standard-4-lssd. Dieses Feld ist erforderlich, da lokale SSDs nicht mit dem Standardtype2-mediumverwendet werden können. Weitere Informationen finden Sie unter Verfügbare Maschinenserien.DATA_CACHE_COUNTist die Anzahl der lokalen SSD-Volumes, die ausschließlich für den Datencache auf jedem Knoten im Standardknotenpool vorgesehen werden sollen. Jede dieser lokalen SSDs hat eine Kapazität von 375 GiB. Die maximale Anzahl der Volumes variiert je nach Maschinentyp und Region. Beachten Sie, dass ein Teil der lokalen SSD-Kapazität für die Systemnutzung reserviert ist.(Optional)
LOCAL_SSD_COUNT: Die Anzahl der lokalen SSD-Volumes, die für andere Anforderungen an den sitzungsspezifischen Speicher bereitgestellt werden sollen. Verwenden Sie das Flag--ephemeral-storage-local-ssd count, wenn Sie zusätzliche lokale SSDs bereitstellen möchten, die nicht für den Datencache verwendet werden.Beachten Sie bei Maschinentypen der dritten oder späteren Generation Folgendes:
- Bei Maschinentypen der dritten oder einer späteren Generation ist standardmäßig eine bestimmte Anzahl lokaler SSDs angehängt. Die Anzahl der lokalen SSDs, die an jeden Knoten angehängt sind, hängt vom angegebenen Maschinentyp ab.
- Wenn Sie das Flag
--ephemeral-storage-local-ssd countfür zusätzlichen sitzungsspezifischen Speicher verwenden möchten, legen Sie den Wert vonDATA_CACHE_COUNTauf eine Zahl fest, die kleiner als die insgesamt verfügbaren lokalen SSD-Laufwerke auf der Maschine ist. Die Gesamtzahl der verfügbaren lokalen SSDs umfasst die standardmäßig angehängten Laufwerke und alle neuen Laufwerke, die Sie mit dem Flag--ephemeral-storage-local-ssd counthinzufügen.
Mit diesem Befehl wird ein GKE-Cluster erstellt, der für seinen Standardknotenpool auf einem Maschinentyp der zweiten, dritten oder einer späteren Generation ausgeführt wird. Außerdem werden lokale SSDs für den Datencache bereitgestellt und optional zusätzliche lokale SSDs für andere kurzlebige Speicheranforderungen, sofern angegeben.
Diese Einstellungen gelten nur für den Standardknotenpool.
In einem vorhandenen Cluster
Wenn Sie den Datencache in einem vorhandenen Cluster verwenden möchten, müssen Sie einen neuen Knotenpool mit konfiguriertem Datencache erstellen.
Verwenden Sie den folgenden Befehl, um einen GKE-Knotenpool mit konfiguriertem Datencache zu erstellen:
gcloud container node-pool create NODE_POOL_NAME \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
Ersetzen Sie Folgendes:
NODE_POOL_NAMEist der Name des Knotenpools. Geben Sie einen eindeutigen Namen für den Knotenpool an, den Sie erstellen.CLUSTER_NAME: Der Name eines vorhandenen GKE-Clusters, in dem Sie den Knotenpool erstellen möchten.LOCATION: dieselbe Google Cloud Region oder ‑Zone wie Ihr Cluster.MACHINE_TYPE: Der Maschinentyp, der für Ihren Cluster aus einer Maschinenserie der zweiten, dritten oder einer späteren Generation verwendet werden soll, z. B.n2-standard-2oderc3-standard-4-lssd. Dieses Feld ist erforderlich, da lokale SSDs nicht mit dem Standardtype2-mediumverwendet werden können. Weitere Informationen finden Sie unter Verfügbare Maschinenserien.DATA_CACHE_COUNTist die Anzahl der lokalen SSD-Volumes, die ausschließlich für den Datencache auf jedem Knoten im Knotenpool bereitgestellt werden sollen. Jede dieser lokalen SSDs hat eine Kapazität von 375 GiB. Die maximale Anzahl der Volumes variiert je nach Maschinentyp und Region. Beachten Sie, dass ein Teil der lokalen SSD-Kapazität für die Systemnutzung reserviert ist.(Optional)
LOCAL_SSD_COUNT: Die Anzahl der lokalen SSD-Volumes, die für andere Anforderungen an den sitzungsspezifischen Speicher bereitgestellt werden sollen. Verwenden Sie das Flag--ephemeral-storage-local-ssd count, wenn Sie zusätzliche lokale SSDs bereitstellen möchten, die nicht für den Datencache verwendet werden.Beachten Sie bei Maschinentypen der dritten oder späteren Generation Folgendes:
- Bei Maschinentypen der dritten oder einer späteren Generation ist standardmäßig eine bestimmte Anzahl lokaler SSDs angehängt. Die Anzahl der lokalen SSDs, die an jeden Knoten angehängt sind, hängt vom angegebenen Maschinentyp ab.
- Wenn Sie das Flag
--ephemeral-storage-local-ssd countfür zusätzlichen sitzungsspezifischen Speicher verwenden möchten, müssen SieDATA_CACHE_COUNTauf einen Wert kleiner als die insgesamt verfügbaren lokalen SSD-Laufwerke auf der Maschine festlegen. Die Gesamtzahl der verfügbaren lokalen SSDs umfasst die standardmäßig angehängten Laufwerke und alle neuen Laufwerke, die Sie mit dem Flag--ephemeral-storage-local-ssd counthinzufügen.
Mit diesem Befehl wird ein GKE-Knotenpool erstellt, der auf einem Maschinentyp der zweiten, dritten oder einer späteren Generation ausgeführt wird. Außerdem werden lokale SSDs für den Datencache bereitgestellt und optional zusätzliche lokale SSDs für andere kurzlebige Speicheranforderungen, sofern angegeben.
Data Cache für nichtflüchtigen Speicher in GKE bereitstellen
In diesem Abschnitt finden Sie ein Beispiel dafür, wie Sie die Leistungsvorteile von GKE Data Cache für Ihre zustandsorientierten Anwendungen nutzen können.
Knotenpool mit lokalen SSDs für den Datencache erstellen
Erstellen Sie zuerst einen neuen Knotenpool mit angehängten lokalen SSDs in Ihrem GKE-Cluster. GKE Data Cache verwendet die lokalen SSDs, um die Leistung der angehängten nichtflüchtigen Speicher zu beschleunigen.
Mit dem folgenden Befehl wird ein Knotenpool erstellt, der eine Maschine der zweiten Generation verwendet: n2-standard-2:
gcloud container node-pools create datacache-node-pool \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--num-nodes=2 \
--data-cache-count=1 \
--machine-type=n2-standard-2
Ersetzen Sie Folgendes:
CLUSTER_NAMEist der Name des Clusters. Geben Sie den GKE-Cluster an, in dem Sie den neuen Knotenpool erstellen.LOCATION: dieselbe Google Cloud Region oder -Zone wie Ihr Cluster.
Mit diesem Befehl wird ein Knotenpool mit den folgenden Spezifikationen erstellt:
--num-nodes=2: Legt die anfängliche Anzahl der Knoten in diesem Pool auf zwei fest.--data-cache-count=1: Gibt eine lokale SSD pro Knoten an, die für GKE Data Cache vorgesehen ist.
Die Gesamtzahl der lokalen SSDs, die für diesen Knotenpool bereitgestellt werden, beträgt zwei, da für jeden Knoten eine lokale SSD bereitgestellt wird.
StorageClass für Datencache erstellen
Erstellen Sie ein Kubernetes-StorageClass, das GKE anweist, wie ein nichtflüchtiges Volume, das den Datencache verwendet, dynamisch bereitgestellt werden soll.
Verwenden Sie das folgende Manifest, um einen StorageClass mit dem Namen pd-balanced-data-cache-sc zu erstellen und anzuwenden:
kubectl apply -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: pd-balanced-data-cache-sc
provisioner: pd.csi.storage.gke.io
parameters:
type: pd-balanced
data-cache-mode: writethrough
data-cache-size: "100Gi"
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
EOF
Die StorageClass-Parameter für den Datencache umfassen Folgendes:
type: gibt den zugrunde liegenden Laufwerkstyp für das persistente Volume an. Weitere Optionen finden Sie unter den unterstützten Persistent Disk-Typen oder Hyperdisk-Typen.data-cache-mode: Verwendet den empfohlenen Moduswritethrough. Weitere Informationen finden Sie unter Bereitstellungsmodi.data-cache-size: Legt die Kapazität der lokalen SSD auf 100 GiB fest, die als Lesecache für jeden PVC verwendet wird.
Speicher mit einem PersistentVolumeClaim (PVC) anfordern
Erstellen Sie einen PVC, der auf die von Ihnen erstellte StorageClass pd-balanced-data-cache-sc verweist. Der PVC fordert ein nichtflüchtiges Volume an, für das der Datencache aktiviert ist.
Verwenden Sie das folgende Manifest, um einen PVC mit dem Namen pvc-data-cache zu erstellen, der ein nichtflüchtiges Volume von mindestens 300 GiB mit ReadWriteOnce-Zugriff anfordert.
kubectl apply -f - <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-data-cache
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 300Gi
storageClassName: pd-balanced-data-cache-sc
EOF
Deployment erstellen, das den PVC verwendet
Erstellen Sie ein Deployment mit dem Namen postgres-data-cache, das einen Pod ausführt, der den zuvor erstellten PVC pvc-data-cache verwendet. Der Knotenselektor cloud.google.com/gke-data-cache-count sorgt dafür, dass der Pod auf einem Knoten geplant wird, der die für die Verwendung von GKE Data Cache erforderlichen lokalen SSD-Ressourcen hat.
Erstellen Sie das folgende Manifest und wenden Sie es an, um einen Pod zu konfigurieren, der einen Postgres-Webserver mit dem PVC bereitstellt:
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-data-cache
labels:
name: database
app: data-cache
spec:
replicas: 1
selector:
matchLabels:
service: postgres
app: data-cache
template:
metadata:
labels:
service: postgres
app: data-cache
spec:
nodeSelector:
cloud.google.com/gke-data-cache-disk: "1"
containers:
- name: postgres
image: postgres:14-alpine
volumeMounts:
- name: pvc-data-cache-vol
mountPath: /var/lib/postgresql/data2
subPath: postgres
env:
- name: POSTGRES_USER
value: admin
- name: POSTGRES_PASSWORD
value: password
restartPolicy: Always
volumes:
- name: pvc-data-cache-vol
persistentVolumeClaim:
claimName: pvc-data-cache
EOF
Prüfen Sie, ob das Deployment erfolgreich erstellt wurde:
kubectl get deployment
Es kann einige Minuten dauern, bis die Bereitstellung des Postgres-Containers abgeschlossen ist und der Status READY angezeigt wird.
Data Cache-Bereitstellung prüfen
Prüfen Sie nach dem Erstellen der Bereitstellung, ob der nichtflüchtige Speicher mit Data Cache richtig bereitgestellt wurde.
Führen Sie den folgenden Befehl aus, um zu prüfen, ob Ihr
pvc-data-cacheerfolgreich an ein persistentes Volume gebunden wurde:kubectl get pvc pvc-data-cacheDie Ausgabe sieht etwa so aus:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE pvc-data-cache Bound pvc-e9238a16-437e-45d7-ad41-410c400ae018 300Gi RWO pd-balanced-data-cache-sc <unset> 10mSo prüfen Sie, ob die LVM-Gruppe (Logical Volume Manager) für den Datencache auf dem Knoten erstellt wurde:
Rufen Sie den Pod-Namen des PDCSI-Treibers auf diesem Knoten ab:
NODE_NAME=$(kubectl get pod --output json | jq '.items[0].spec.nodeName' | sed 's/\"//g') kubectl get po -n kube-system -o wide | grep ^pdcsi-node | grep $NODE_NAMEKopieren Sie aus der Ausgabe den Namen des
pdcsi-node-Pods.PDCSI-Treiberlogs für die Erstellung von LVM-Gruppen ansehen:
PDCSI_POD_NAME="PDCSI-NODE_POD_NAME" kubectl logs -n kube-system $PDCSI_POD_NAME gce-pd-driver | grep "Volume group creation"Ersetzen Sie
PDCSI-NODE_POD_NAMEdurch den tatsächlichen Pod-Namen, den Sie im vorherigen Schritt kopiert haben.Die Ausgabe sieht etwa so aus:
Volume group creation succeeded for LVM_GROUP_NAME
Diese Meldung bestätigt, dass die LVM-Konfiguration für den Datencache auf dem Knoten korrekt eingerichtet ist.
Bereinigen
Löschen Sie die in dieser Anleitung erstellten Speicherressourcen, damit Ihrem Google Cloud Konto keine Gebühren in Rechnung gestellt werden.
Löschen Sie das Deployment.
kubectl delete deployment postgres-data-cacheLöschen Sie den PersistentVolumeClaim.
kubectl delete pvc pvc-data-cacheLöschen Sie den Knotenpool.
gcloud container node-pools delete datacache-node-pool \ --cluster CLUSTER_NAMEErsetzen Sie
CLUSTER_NAMEdurch den Namen des Clusters, in dem Sie den Knotenpool erstellt haben, der den Datencache verwendet.
Nächste Schritte
- Weitere Informationen finden Sie unter Fehlerbehebung bei Speicher in GKE.
- Weitere Informationen zum CSI-Treiber für Persistent Disk auf GitHub