Dieses Dokument bietet einen Überblick über die Verwaltung von Arbeitslasten in Google Distributed Cloud (GDC) mit Air Gap. Dabei werden die folgenden Themen behandelt:
Einige der Designs für die Bereitstellung von Arbeitslasten werden zwar empfohlen, es ist jedoch nicht erforderlich, sie genau wie beschrieben zu befolgen. Für jedes GDC-Universum gelten individuelle Anforderungen und Überlegungen, die von Fall zu Fall erfüllt werden müssen.
Dieses Dokument richtet sich an IT-Administratoren in der Gruppe „Plattformadministrator“, die für die Verwaltung von Ressourcen in ihrer Organisation verantwortlich sind, und an Anwendungsentwickler in der Gruppe „Anwendungsoperator“, die für die Entwicklung und Wartung von Anwendungen in einem GDC-Universum verantwortlich sind.
Weitere Informationen finden Sie unter Zielgruppen für die GDC-Dokumentation für Air-Gap-Umgebungen.
Wo Arbeitslasten bereitgestellt werden
Auf der GDC-Plattform unterscheiden sich die Vorgänge zum Bereitstellen von VM-Arbeitslasten und Containerarbeitslasten. Das folgende Diagramm veranschaulicht die Trennung von Arbeitslasten in der Datenebene Ihrer Organisation.
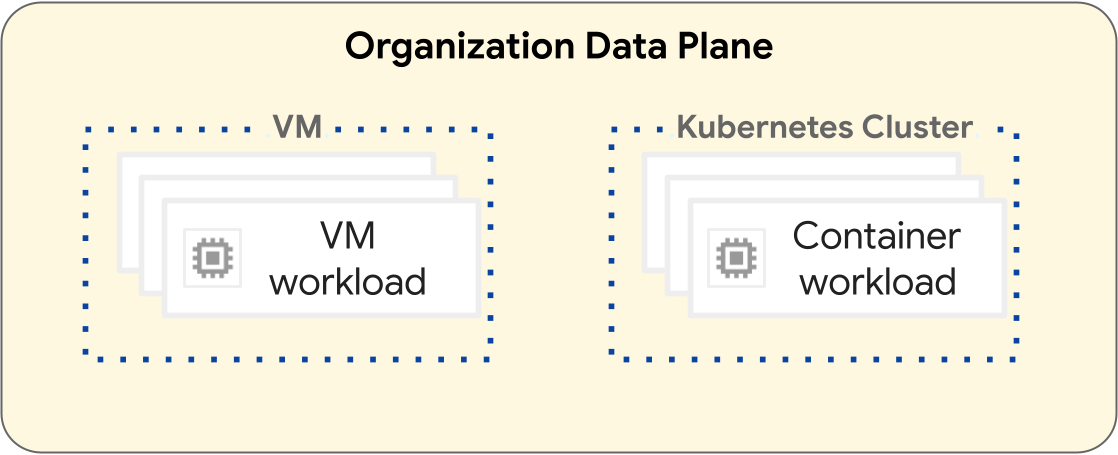
VM-basierte Arbeitslasten werden in einer VM ausgeführt. Containerarbeitslasten werden dagegen in einem Kubernetes-Cluster ausgeführt. Die grundlegende Trennung zwischen VMs und Kubernetes-Clustern bietet Isolationsgrenzen zwischen Ihren VM-Arbeitslasten und Containerarbeitslasten. Weitere Informationen finden Sie unter Ressourcenhierarchie.
In den folgenden Abschnitten werden die Unterschiede zwischen den einzelnen Arbeitslasttypen und ihrem Bereitstellungslebenszyklus beschrieben.
VM-basierte Arbeitslasten
Sie können VMs erstellen, um Ihre VM-basierten Arbeitslasten zu hosten. Sie haben viele Konfigurationsoptionen für die Form und Größe Ihrer VM, um die Anforderungen Ihrer VM-basierten Arbeitslast bestmöglich zu erfüllen. Sie müssen eine VM in einem Projekt erstellen, das viele VM-Arbeitslasten haben kann. VMs sind untergeordnete Ressourcen eines Projekts. Weitere Informationen finden Sie in der VM-Übersicht.
Für Projekte, die nur VM-basierte Arbeitslasten enthalten, ist kein Kubernetes-Cluster erforderlich. Daher müssen Sie keine Kubernetes-Cluster für VM-basierte Arbeitslasten bereitstellen.
Containerbasierte Arbeitslasten
Sie können containerbasierte Arbeitslasten in einem Pod in einem Kubernetes-Cluster bereitstellen. Ein Kubernetes-Cluster besteht aus den folgenden Knotentypen:
Knoten der Steuerungsebene: Führt die Verwaltungsdienste aus, z. B. Planung, etcd und einen API-Server.
Worker-Knoten: Führt Ihre Pods und Containeranwendungen aus.
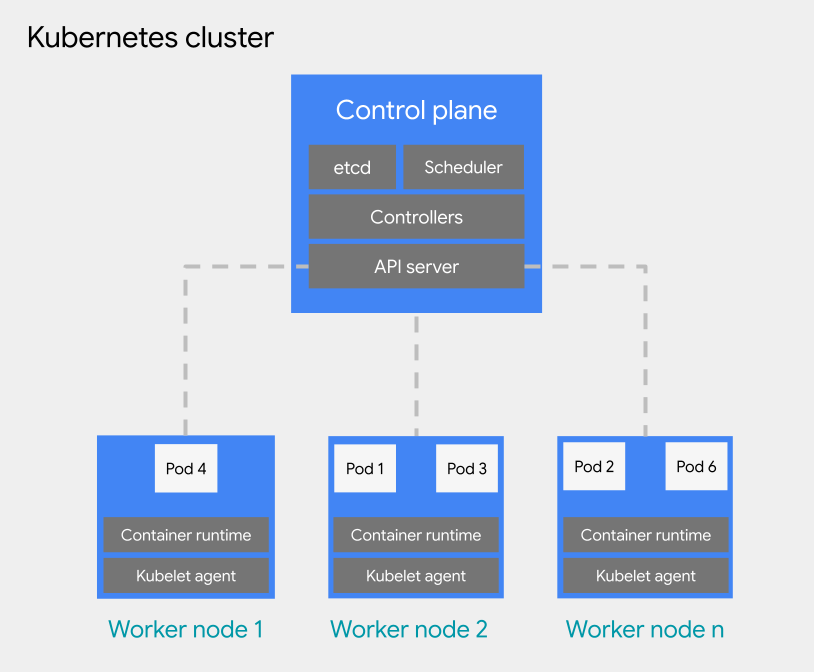
Kubernetes-Cluster können mit einem oder mehreren Projekten verknüpft werden, sind aber keine untergeordnete Ressource eines Projekts. Das ist ein grundlegender Unterschied zwischen Kubernetes-Clustern und VMs. Eine VM ist eine untergeordnete Ressource eines Projekts, während Kubernetes-Cluster als untergeordnete Ressource einer Organisation fungieren, sodass sie an mehrere Projekte angehängt werden können.
Für die Pod-Planung in einem Kubernetes-Cluster verwendet GDC die allgemeinen Kubernetes-Konzepte für Planung, Vorabzuweisung und Entfernung. Best Practices für die Planung von Pods in einem Cluster variieren je nach den Anforderungen Ihrer Arbeitslast.
Weitere Informationen zu Kubernetes-Clustern finden Sie in der Übersicht über Kubernetes-Cluster. Weitere Informationen zum Verwalten von Containern in einem Kubernetes-Cluster finden Sie unter Containerarbeitslasten in GDC.
Best Practices für das Entwerfen von Kubernetes-Clustern
In diesem Abschnitt werden Best Practices für das Entwerfen von Kubernetes-Clustern vorgestellt:
- Separate Cluster pro Softwareentwicklungsumgebung erstellen
- Weniger, größere Cluster erstellen
- Weniger, größere Knotenpools in einem Cluster erstellen
Berücksichtigen Sie jede Best Practice, um ein stabiles Clusterdesign für den Lebenszyklus Ihrer Containerarbeitslast zu entwickeln.
Separate Cluster für jede Softwareentwicklungsumgebung erstellen
Zusätzlich zu separaten Projekten pro Softwareentwicklungsumgebung empfehlen wir, separate Kubernetes-Cluster pro Softwareentwicklungsumgebung zu entwerfen. Eine Softwareentwicklungsumgebung ist ein Bereich in Ihrem GDC-Universum, der für alle Vorgänge vorgesehen ist, die einer bestimmten Lebenszyklusphase entsprechen. Wenn Sie beispielsweise zwei Softwareentwicklungsumgebungen mit den Namen development und production in Ihrer Organisation haben, können Sie für jede Umgebung einen separaten Satz von Kubernetes-Clustern erstellen und Projekte nach Bedarf an die einzelnen Cluster anhängen. Wir empfehlen, dass an Kubernetes-Cluster im Vorproduktions- und Produktionslebenszyklus mehrere Projekte angehängt sind.
Für jede Softwareentwicklungsumgebung sind Cluster definiert. Das bedeutet, dass sich Arbeitslasten innerhalb einer Softwareentwicklungsumgebung Cluster teilen können. Anschließend weisen Sie dem Kubernetes-Cluster der entsprechenden Umgebung Projekte zu. Ein Kubernetes-Cluster kann in mehrere Knotenpools unterteilt werden oder Markierungen zur Isolierung von Arbeitslasten verwenden.
Wenn Sie Kubernetes-Cluster nach Softwareentwicklungsumgebung trennen, isolieren Sie den Ressourcenverbrauch, die Zugriffsrichtlinien, die Wartungsereignisse und die Konfigurationsänderungen auf Clusterebene zwischen Ihren Produktions- und Nichtproduktionsarbeitslasten.
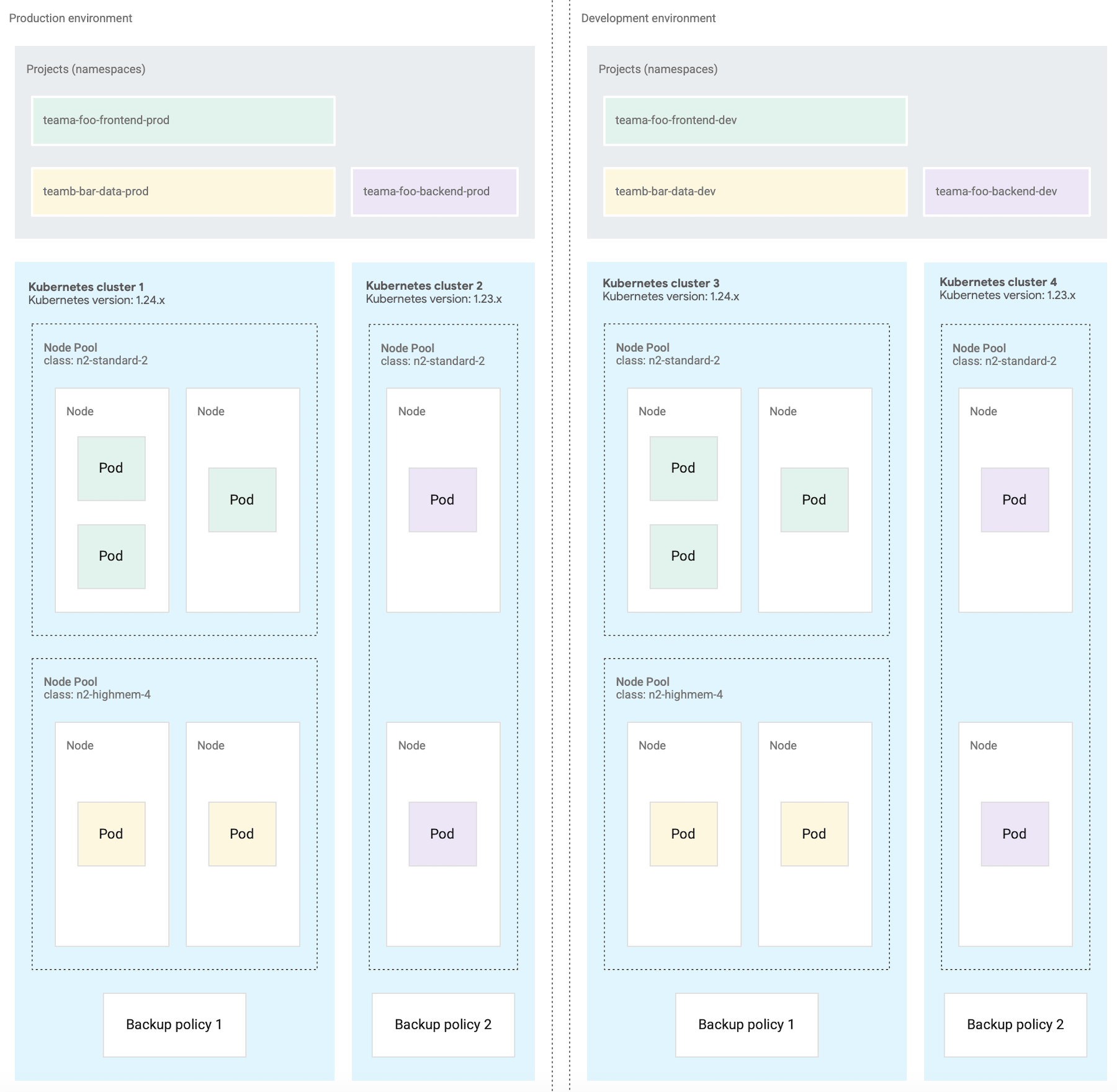
Das folgende Diagramm zeigt ein Beispiel für ein Kubernetes-Clusterdesign für mehrere Arbeitslasten, die sich über Projekte, Cluster, Softwareentwicklungsumgebungen und Maschinenklassen erstrecken.

Bei dieser Beispielarchitektur wird davon ausgegangen, dass Arbeitslasten in einer Produktions- und Entwicklungsumgebung für die Softwareentwicklung Cluster gemeinsam nutzen können. Jede Umgebung hat einen separaten Satz von Kubernetes-Clustern, die weiter in mehrere Knotenpools für unterschiedliche Anforderungen an die Maschinenklasse unterteilt sind.
Alternativ ist es für Container-Vorgänge wie die folgenden Szenarien sinnvoll, mehrere Kubernetes-Cluster zu entwerfen:
- Sie haben einige Arbeitslasten an eine bestimmte Kubernetes-Version angepinnt und verwalten daher verschiedene Cluster mit unterschiedlichen Versionen.
- Sie haben einige Arbeitslasten, für die unterschiedliche Clusterkonfigurationen erforderlich sind, z. B. die Sicherungsrichtlinie. Daher erstellen Sie mehrere Cluster mit unterschiedlichen Konfigurationen.
- Sie führen Kopien eines Clusters parallel aus, um disruptive Versionsupgrades oder eine Blau/Grün-Bereitstellungsstrategie zu ermöglichen.
- Sie erstellen eine experimentelle Arbeitslast, die das Risiko birgt, dass der API-Server oder andere Single Points of Failure in einem Cluster gedrosselt werden. Daher isolieren Sie sie von vorhandenen Arbeitslasten.
Das folgende Diagramm zeigt ein Beispiel, in dem mehrere Cluster pro Softwareentwicklungsumgebung konfiguriert sind. Das ist aufgrund von Anforderungen wie den im vorherigen Abschnitt beschriebenen Containeroperationen erforderlich.
Weniger Cluster erstellen
Für eine effiziente Ressourcennutzung empfehlen wir, die Anzahl der Kubernetes-Cluster so gering wie möglich zu halten, die Ihre Anforderungen an die Trennung von Softwareentwicklungs- und Containerbetriebsumgebungen erfüllen. Jeder zusätzliche Cluster führt zu einem zusätzlichen Ressourcenverbrauch, z. B. durch zusätzliche Knoten der Steuerungsebene. Ein großer Cluster mit vielen Arbeitslasten nutzt die zugrunde liegenden Rechenressourcen daher effizienter als viele kleine Cluster.
Wenn es mehrere Cluster mit ähnlichen Konfigurationen gibt, entsteht zusätzlicher Wartungsaufwand für die Überwachung der Clusterkapazität und die Planung von clusterübergreifenden Abhängigkeiten.
Wenn ein Cluster sich der Kapazitätsgrenze nähert, empfehlen wir, einem Cluster zusätzliche Knoten hinzuzufügen, anstatt einen neuen Cluster zu erstellen.
Weniger Knotenpools in einem Cluster erstellen
Für eine effiziente Ressourcennutzung empfehlen wir, weniger, aber größere Knotenpools in einem Kubernetes-Cluster zu erstellen.
Die Konfiguration mehrerer Knotenpools ist nützlich, wenn Sie Pods planen müssen, die eine andere Maschinenklasse als andere benötigen. Erstellen Sie für jede Maschinenklasse, die für Ihre Arbeitslasten erforderlich ist, einen Knotenpool und legen Sie die Knotenkapazität auf Autoscaling fest, um eine effiziente Nutzung der Rechenressourcen zu ermöglichen.