En este documento se ofrece una descripción general de la gestión de cargas de trabajo en Google Distributed Cloud (GDC) aislado. Se tratan los siguientes temas:
Aunque se recomiendan algunos diseños de implementación de cargas de trabajo, no es obligatorio seguirlos al pie de la letra. Cada universo de GDC tiene requisitos y consideraciones únicos que deben cumplirse caso por caso.
Este documento está dirigido a los administradores de TI del grupo de administradores de la plataforma, que se encargan de gestionar los recursos de su organización, y a los desarrolladores de aplicaciones del grupo de operadores de aplicaciones, que se encargan de desarrollar y mantener aplicaciones en un universo de GDC.
Para obtener más información, consulta Audiencias de la documentación aislada de GDC.
Dónde desplegar cargas de trabajo
En la plataforma de GDC, las operaciones para desplegar cargas de trabajo de máquinas virtuales (VMs) y cargas de trabajo de contenedores son diferentes. En el siguiente diagrama se ilustra la separación de cargas de trabajo en la capa del plano de datos de tu organización.
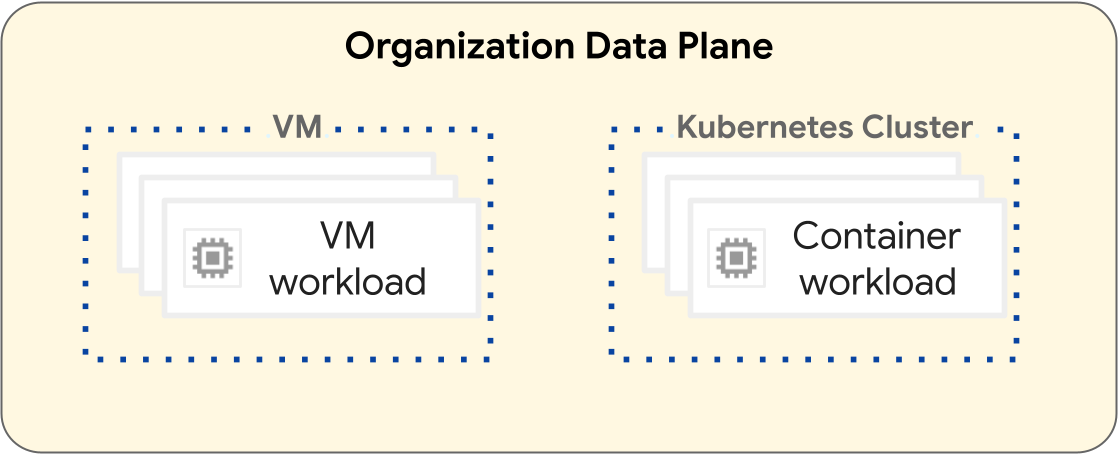
Las cargas de trabajo basadas en VMs operan en una VM. Por el contrario, las cargas de trabajo de contenedores operan en un clúster de Kubernetes. La separación fundamental entre las máquinas virtuales y los clústeres de Kubernetes proporciona límites de aislamiento entre las cargas de trabajo de las máquinas virtuales y las cargas de trabajo de los contenedores. Para obtener más información, consulta Jerarquía de recursos.
En las siguientes secciones se explican las diferencias entre cada tipo de carga de trabajo y su ciclo de vida de implementación.
Cargas de trabajo basadas en máquinas virtuales
Puedes crear VMs para alojar tus cargas de trabajo basadas en VMs. Tienes muchas opciones de configuración para la forma y el tamaño de tu máquina virtual, lo que te ayudará a satisfacer los requisitos de tu carga de trabajo basada en máquinas virtuales. Debes crear una VM en un proyecto, que puede tener muchas cargas de trabajo de VM. Las VMs son un recurso secundario de un proyecto. Para obtener más información, consulta la descripción general de las VMs.
Los proyectos que solo contienen cargas de trabajo basadas en VMs no requieren un clúster de Kubernetes. Por lo tanto, no es necesario aprovisionar clústeres de Kubernetes para cargas de trabajo basadas en VMs.
Cargas de trabajo basadas en contenedores
Puedes desplegar cargas de trabajo basadas en contenedores en un pod de un clúster de Kubernetes. Un clúster de Kubernetes consta de los siguientes tipos de nodos:
Nodo del plano de control: ejecuta los servicios de gestión, como la programación, etcd y un servidor de API.
Nodo de trabajador: ejecuta tus pods y aplicaciones de contenedor.
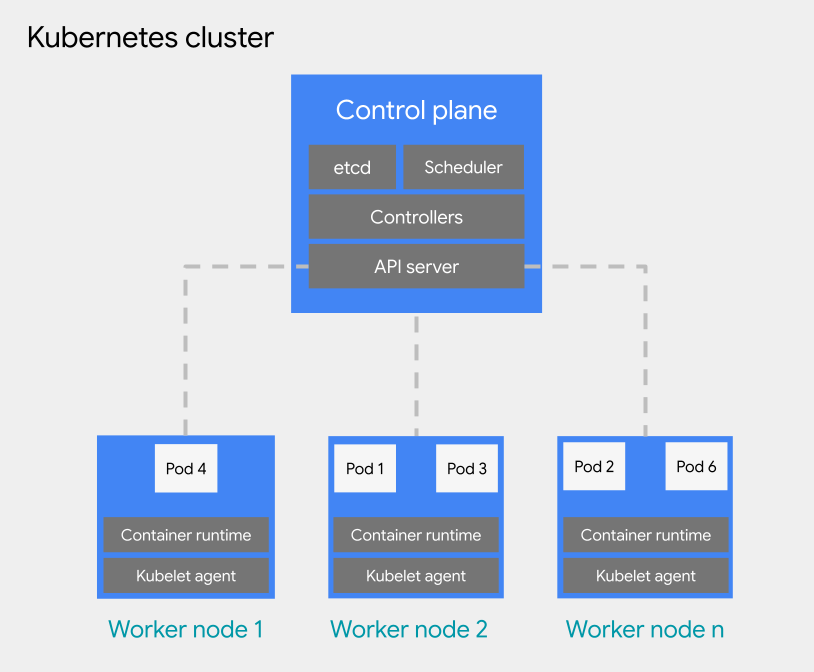
Los clústeres de Kubernetes se pueden asociar a uno o varios proyectos, pero no son un recurso secundario de un proyecto. Esta es una diferencia fundamental que tienen los clústeres de Kubernetes en comparación con las VMs. Una VM es un recurso secundario de un proyecto, mientras que los clústeres de Kubernetes funcionan como recursos secundarios de una organización, lo que les permite asociarse a varios proyectos.
Para programar pods en un clúster de Kubernetes, GDC adopta los conceptos generales de Kubernetes de programación, preferencia y desalojo. Las prácticas recomendadas para programar pods en un clúster varían en función de los requisitos de tu carga de trabajo.
Para obtener más información sobre los clústeres de Kubernetes, consulta la descripción general de los clústeres de Kubernetes. Para obtener más información sobre cómo gestionar tus contenedores en un clúster de Kubernetes, consulta Cargas de trabajo de contenedores en GDC.
Prácticas recomendadas para diseñar clústeres de Kubernetes
En esta sección se presentan las prácticas recomendadas para diseñar clústeres de Kubernetes:
- Crear clústeres independientes para cada entorno de desarrollo de software
- Crear menos clústeres, pero más grandes
- Crear menos grupos de nodos más grandes en un clúster
Ten en cuenta cada práctica recomendada para diseñar un clúster resistente para el ciclo de vida de tu carga de trabajo de contenedor.
Crear clústeres independientes por entorno de desarrollo de software
Además de tener un proyecto independiente por entorno de desarrollo de software, te recomendamos que diseñes clústeres de Kubernetes independientes por entorno de desarrollo de software. Un entorno de desarrollo de software es un área de tu universo de GDC destinada a todas las operaciones que corresponden a una fase del ciclo de vida designada. Por ejemplo, si tienes dos entornos de desarrollo de software llamados development y production en tu organización, puedes crear un conjunto independiente de clústeres de Kubernetes para cada entorno y asociar proyectos a cada clúster en función de tus necesidades. Recomendamos que los clústeres de Kubernetes en los ciclos de vida de preproducción y producción tengan varios proyectos vinculados.
Los clústeres definidos para cada entorno de desarrollo de software presuponen que las cargas de trabajo de un entorno de desarrollo de software pueden compartir clústeres. A continuación, asigna proyectos al clúster de Kubernetes del entorno correspondiente. Un clúster de Kubernetes se puede subdividir en varios grupos de nodos o usar intolerancias para aislar las cargas de trabajo.
Al separar los clústeres de Kubernetes por entorno de desarrollo de software, puedes aislar el consumo de recursos, las políticas de acceso, los eventos de mantenimiento y los cambios de configuración a nivel de clúster entre tus cargas de trabajo de producción y de no producción.
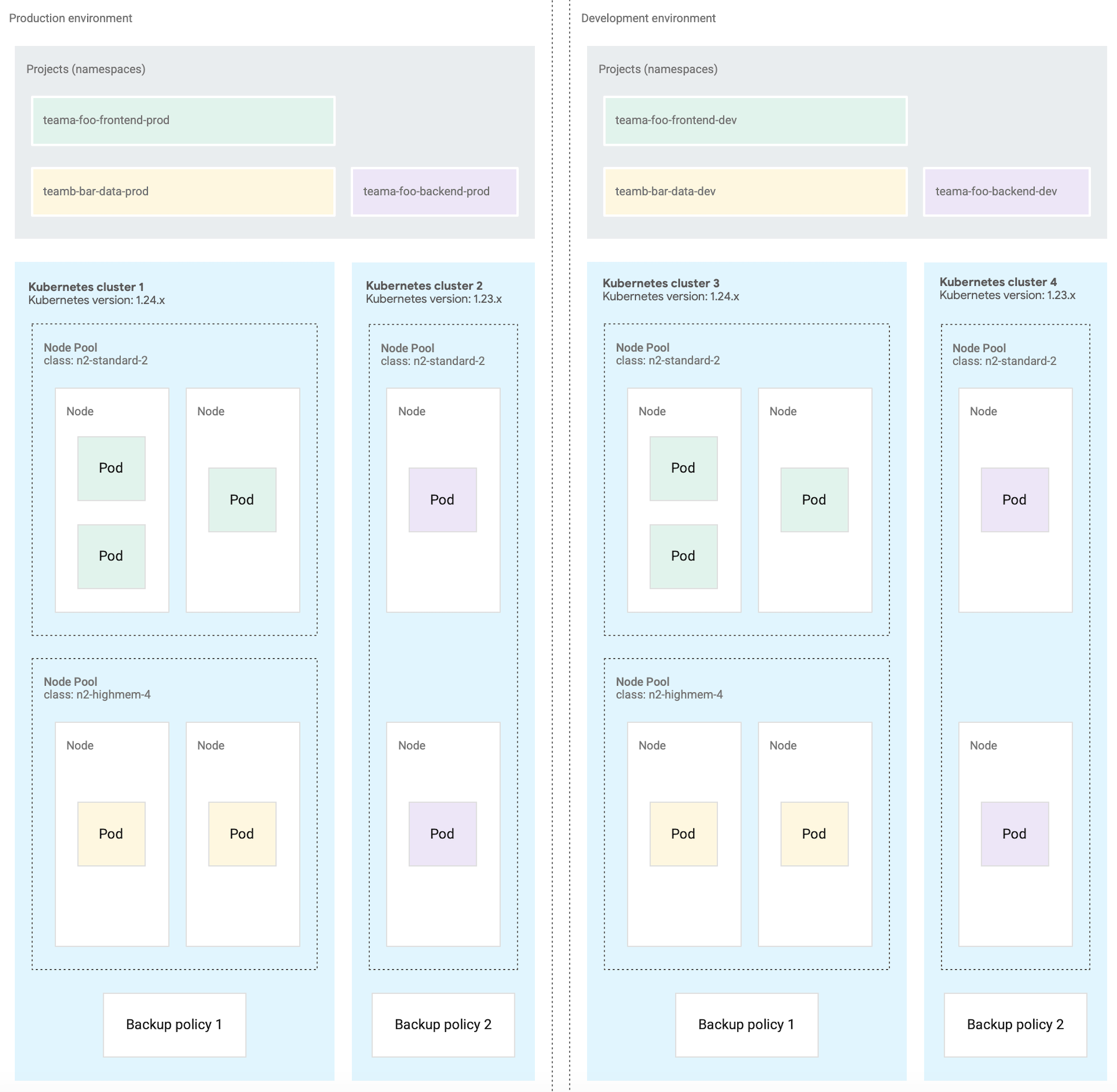
En el siguiente diagrama se muestra un diseño de clúster de Kubernetes de ejemplo para varias cargas de trabajo que abarcan proyectos, clústeres, entornos de desarrollo de software y clases de máquinas.

En esta arquitectura de ejemplo se presupone que las cargas de trabajo de un entorno de desarrollo de software de producción y de desarrollo pueden compartir clústeres. Cada entorno tiene un conjunto independiente de clústeres de Kubernetes, que se subdividen en varios grupos de nodos para diferentes requisitos de clase de máquina.
También es útil diseñar varios clústeres de Kubernetes para operaciones de contenedores como las siguientes:
- Tienes algunas cargas de trabajo fijadas a una versión específica de Kubernetes, por lo que mantienes diferentes clústeres en diferentes versiones.
- Tienes algunas cargas de trabajo que requieren diferentes configuraciones de clúster, como la política de copia de seguridad, por lo que creas varios clústeres con diferentes configuraciones.
- Ejecutas copias de un clúster en paralelo para facilitar las actualizaciones de versiones disruptivas o una estrategia de implementación azul-verde.
- Creas una carga de trabajo experimental que puede limitar el servidor de la API u otro punto único de fallo de un clúster, por lo que la aíslas de las cargas de trabajo existentes.
En el siguiente diagrama se muestra un ejemplo en el que se configuran varios clústeres por entorno de desarrollo de software debido a requisitos como las operaciones de contenedores descritas en la sección anterior.
Crear menos clústeres
Para utilizar los recursos de forma eficiente, te recomendamos que diseñes el menor número posible de clústeres de Kubernetes que cumplan tus requisitos para separar los entornos de desarrollo de software y las operaciones de contenedores. Cada clúster adicional conlleva un consumo de recursos adicional, como los nodos de plano de control adicionales que se necesitan. Por lo tanto, un clúster más grande con muchas cargas de trabajo utiliza los recursos de computación subyacentes de forma más eficiente que muchos clústeres pequeños.
Cuando hay varios clústeres con configuraciones similares, se genera una carga de mantenimiento adicional para monitorizar la capacidad de los clústeres y planificar las dependencias entre clústeres.
Si un clúster se acerca a su capacidad, te recomendamos que añadas nodos a un clúster en lugar de crear uno nuevo.
Crear menos grupos de nodos en un clúster
Para utilizar los recursos de forma eficiente, te recomendamos que diseñes menos grupos de nodos, pero más grandes, en un clúster de Kubernetes.
Configurar varios grupos de nodos es útil cuando necesitas programar pods que requieren una clase de máquina diferente a la de otros. Crea un grupo de nodos para cada clase de máquina que necesiten tus cargas de trabajo y configura la capacidad de los nodos para que se autoescale, lo que permitirá usar los recursos de computación de forma eficiente.
Siguientes pasos
- Jerarquía de recursos
- Crear una aplicación de contenedor de alta disponibilidad
- Crear una aplicación de VM de alta disponibilidad