Este guia aborda o contexto conceitual necessário para implantar uma carga de trabalho baseada em máquina virtual (VM) em um cluster isolado do Google Distributed Cloud (GDC) em bare metal usando um ambiente de execução de VM. A carga de trabalho neste guia é uma plataforma de sistema de emissão de passagens de exemplo disponível em hardware local.
Arquitetura
Hierarquia de recursos
No GDC, você implanta os componentes que compõem o sistema de emissão de passagens em uma organização de locatário dedicada para a equipe de operações, idêntica a qualquer organização de cliente. Uma organização é um conjunto de clusters, recursos de infraestrutura e cargas de trabalho de aplicativos administrados em conjunto. Cada organização em uma instância do GDC usa um conjunto dedicado de servidores, oferecendo um isolamento forte entre os locatários. Para mais informações sobre infraestrutura, consulte Projetar limites de acesso.
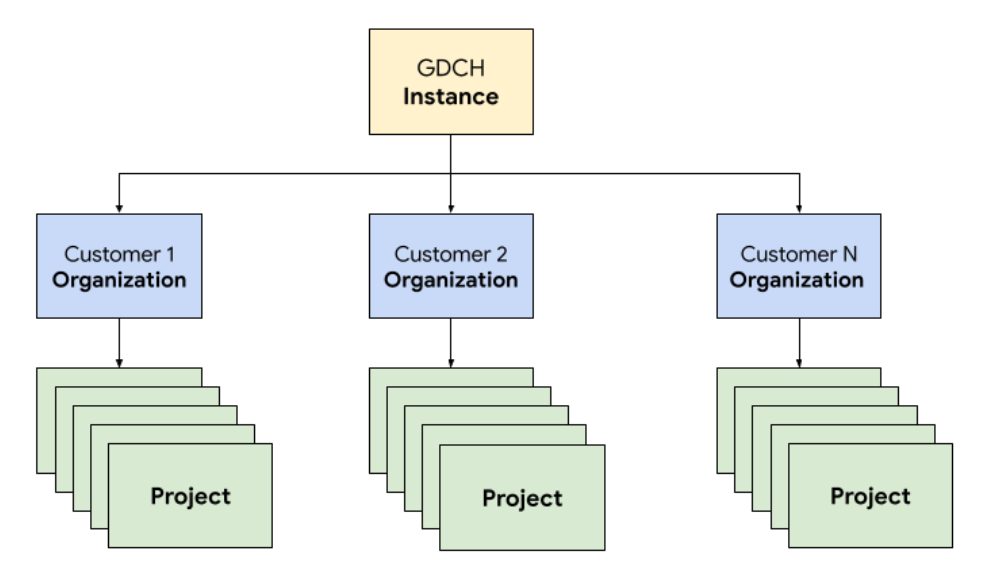
Além disso, você implanta e gerencia os recursos do sistema de tíquetes juntos em um projeto, o que fornece isolamento lógico em uma organização usando políticas e aplicação de software. Os recursos em um projeto são destinados a acoplar componentes que precisam permanecer juntos durante o ciclo de vida.
O sistema de tíquetes segue uma arquitetura de três camadas que depende de um balanceador de carga para direcionar o tráfego entre servidores de aplicativos que se conectam a um servidor de banco de dados que armazena dados permanentes.
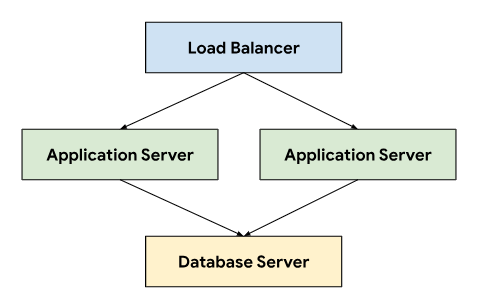
Essa arquitetura permite escalonabilidade e capacidade de manutenção, já que cada camada pode ser desenvolvida e mantida de forma independente. Ele também oferece uma separação clara de responsabilidades, o que simplifica a depuração e a solução de problemas. Encapsular essas camadas em um projeto do GDC permite implantar e gerenciar componentes juntos, por exemplo, os servidores de aplicativos e de banco de dados.
Rede
Para executar o sistema de emissão de passagens em um ambiente de produção, é necessário implantar dois ou mais servidores de aplicativos para alcançar alta disponibilidade em caso de falha de nó. Combinada com um balanceador de carga, essa topologia também permite distribuir a carga entre várias máquinas para escalonar horizontalmente o aplicativo. A plataforma nativa do Kubernetes do GDC usa o Cloud Service Mesh para rotear o tráfego com segurança para os servidores de aplicativos que compõem o sistema de emissão de passagens.
O Cloud Service Mesh é uma implementação do Google baseada no projeto de código aberto que gerencia, observa e protege serviços. Os seguintes recursos do Cloud Service Mesh são usados para hospedar o sistema de venda de ingressos no GDC:
- Balanceamento de carga: a malha de serviço do Cloud separa o fluxo de tráfego do escalonamento da infraestrutura, o que viabiliza muitos recursos de gerenciamento de tráfego, incluindo o roteamento de solicitações dinâmico. O sistema de tíquetes exige conexões de cliente persistentes. Por isso, ativamos sessões fixas usando
DestinationRulespara configurar o comportamento de roteamento de tráfego.
Encerramento de TLS: o Cloud Service Mesh expõe gateways de entrada usando certificados TLS e fornece autenticação de transporte no cluster por mTLS (Mutual Transport Layer Security) sem precisar mudar nenhum código de aplicativo.
Recuperação de falhas: a Malha de serviço do Cloud oferece vários recursos essenciais de recuperação de falhas, incluindo tempos limite, disjuntores, verificações de integridade ativas e novas tentativas vinculadas.
No cluster do Kubernetes, usamos objetos Service padrão como uma maneira abstrata de expor os servidores de aplicativos e de banco de dados à rede. Os serviços oferecem uma maneira conveniente de segmentar instâncias usando um seletor e fornecem resolução de nomes no cluster usando um servidor DNS compatível com o cluster.
apiVersion: v1
kind: Service
metadata:
name: http-ingress
spec:
selector:
app.kubernetes.io/component: application-server
ports:
- name: http
port: 80
---
apiVersion: v1
kind: Service
metadata:
name: database-ingress
spec:
selector:
app.kubernetes.io/component: database-server
ports:
- name: mysql
port: 3306
Computação
O sistema de tíquetes recomenda o uso de bare metal ou máquinas virtuais para hospedar instalações locais. Usamos o gerenciamento de máquina virtual (VMs) do GDC para implantar os servidores de aplicativos e de banco de dados como cargas de trabalho de VM. A definição de recursos do Kubernetes permitiu especificar VirtualMachine e VirtualMachineDisk para adaptar os recursos e atender às nossas necessidades para os diferentes tipos de servidores. VirtualMachineExternalAccess permite configurar a transferência de dados de entrada e saída para a VM.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineDisk
metadata:
name: vm1-boot-disk
spec:
size: 100G
source:
image:
name: ts-ticketing-system-app-server-2023-08-18-203258
namespace: vm-system
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachine
metadata:
labels:
app.kubernetes.io/component: application-server
name: vm1
namespace: support
spec:
compute:
vcpus: 8
memory: 12G
disks:
- boot: true
virtualMachineDiskRef:
name: vm1-boot-disk
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineExternalAccess
metadata:
name: vm1
namespace: support
spec:
enabled: true
ports:
- name: ssh
protocol: TCP
port: 22
Para a imagem do SO convidado, criamos uma imagem personalizada para atender aos nossos requisitos de
compliance e segurança. É possível se conectar a instâncias de VM em execução por SSH usando o VirtualMachineAccessRequest, o que permite limitar a capacidade de se conectar a VMs pelo RBAC do Kubernetes e evitar a necessidade de criar contas de usuário locais nas imagens personalizadas. A solicitação de acesso também define um
time to live (TTL) que permite gerenciar as VMs que
expiram automaticamente.
Automação
Como um dos principais resultados desse projeto, criamos uma abordagem para instalar instâncias do sistema de emissão de passagens de maneira repetível, que pode oferecer suporte a uma automação extensa e reduzir o desvio de configuração entre implantações.
Fluxo de lançamentos
A personalização das imagens do aplicativo e do servidor de banco de dados começa com uma imagem de sistema operacional de base, modificando-a conforme necessário para instalar as dependências necessárias para cada imagem de servidor. Selecionamos uma imagem do SO base para a adoção generalizada de sistemas de emissão de tíquetes de hospedagem em instalações locais. Essa imagem de SO base também oferece recursos de reforço de segurança necessários para atender aos guias de implementação técnica de segurança (STIGs, na sigla em inglês) necessários para fornecer uma imagem compatível que atenda aos controles NIST-800-53.
Nosso pipeline de integração contínua (CI) usou o seguinte fluxo de trabalho para personalizar imagens de servidor de banco de dados e aplicativos:
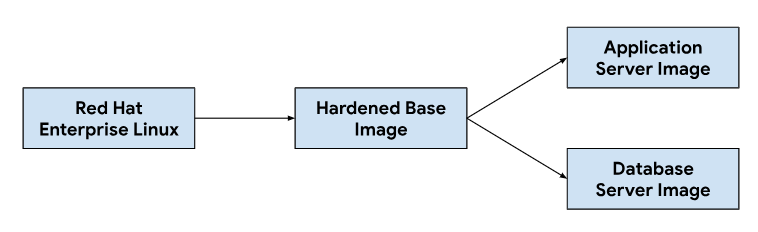
Quando os desenvolvedores fazem mudanças nos scripts de personalização ou nas dependências de imagem, acionamos um fluxo de trabalho automatizado nas nossas ferramentas de CI para gerar um novo conjunto de imagens que são agrupadas com os lançamentos do GDC. Como parte da criação de imagens, também atualizamos as dependências do SO (yum update) e esparsamos a imagem com compactação para reduzir o tamanho necessário para transferir imagens para ambientes de clientes.
Ciclo de vida de desenvolvimento de software
O ciclo de vida de desenvolvimento de software (SDLC, na sigla em inglês) é um processo que ajuda as organizações a planejar, criar, testar e implantar software. Ao seguir um SDLC bem definido, as organizações garantem que o software seja desenvolvido de maneira consistente e repetível e identificam possíveis problemas no início. Além de criar imagens no nosso pipeline de integração contínua (CI), também definimos ambientes para desenvolver e preparar versões de pré-lançamento do sistema de emissão de passagens para testes e garantia de qualidade.
A implantação de uma instância separada do sistema de tíquetes por projeto da GDC permitiu testar mudanças de forma isolada, sem afetar as instâncias atuais na mesma instância da GDC. Usamos a API ResourceManager para criar e encerrar projetos de forma declarativa usando recursos do Kubernetes.
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-dev
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-qa
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-staging
Combinado com o empacotamento de gráficos e o gerenciamento de infraestrutura, como máquinas virtuais como código, os desenvolvedores podem iterar rapidamente, fazendo mudanças e testando novos recursos junto com instâncias de produção. A API declarativa também permite que frameworks de execução de testes automatizados realizem testes de regressão regulares e verifiquem os recursos atuais.
Operabilidade
Operabilidade é a facilidade com que um sistema pode ser operado e mantido. É uma consideração importante no design de qualquer aplicativo de software. O monitoramento eficaz contribui para a capacidade operacional porque permite que os problemas sejam identificados e resolvidos antes que tenham um impacto significativo no sistema. O monitoramento também pode ser usado para identificar oportunidades de melhoria e estabelecer uma base para objetivos de nível de serviço (SLOs).
Monitoramento
Integramos o sistema de tíquetes à infraestrutura de observabilidade do GDC, incluindo registros e métricas. Para métricas, expomos endpoints HTTP de cada VM que permitem que o aplicativo extraia pontos de dados produzidos pelos servidores de aplicativos e de banco de dados. Esses endpoints incluem métricas do sistema coletadas usando o exportador de nós do aplicativo e métricas específicas do aplicativo.
Com os endpoints expostos em cada VM, configuramos o comportamento de sondagem do aplicativo usando o recurso personalizado MonitoringTarget para definir o intervalo de raspagem e anotar as métricas.
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringTarget
metadata:
name: database-monitor
spec:
podMetricsEndpoints:
path:
value: /metrics
port:
annotation: application.io/dbMetrics
scrapeInterval: 60s
Para o registro, instalamos e configuramos um processador de registros e métricas em
cada VM para rastrear registros relevantes e enviar dados de registro à ferramenta de registro, em que os
dados são indexados e consultados pela instância de monitoramento. Os registros de auditoria são encaminhados para um endpoint especial configurado com retenção estendida para compliance. Os aplicativos baseados em contêineres podem usar o recurso personalizado LoggingTarget e AuditLoggingTarget para instruir o pipeline de geração de registros a coletar registros de serviços específicos no seu projeto.
Com base nos dados disponíveis nos processadores de geração de registros e monitoramento, criamos alertas usando o recurso personalizado MonitoringRule, que permite gerenciar essa configuração como código no nosso pacote de gráficos. Usar uma API declarativa para definir alertas e painéis também permite armazenar essa configuração no repositório de código e seguir os mesmos processos de revisão de código e integração contínua em que confiamos para qualquer outra mudança de código.
Modos de falha
Os testes iniciais descobriram vários modos de falha relacionados a recursos que nos ajudaram a priorizar quais métricas e alertas adicionar primeiro. Começamos monitorando o uso alto de memória e disco, já que a configuração incorreta do banco de dados inicialmente levou a tabelas de buffer consumindo toda a memória disponível, e o excesso de registros preencheu o disco de volume permanente anexado. Depois de ajustar o tamanho do buffer de armazenamento e implementar uma estratégia de rotação de registros, introduzimos alertas que são executados se as VMs se aproximarem de um uso alto de memória ou disco.
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringRule
metadata:
name: monitoring-rule
spec:
interval: 60s
limit: 0
alertRules:
- alert: vm1_disk_usage
expr:
(node_filesystem_size_bytes{container_name="compute"} -
node_filesystem_avail_bytes{container_name="compute"}) * 100 /
node_filesystem_size_bytes{container_name="compute"} > 90
labels:
severity: error
code: <a href="/distributed-cloud/hosted/docs/latest/gdch/gdch-io/service-manual/ts/runbooks/ts-r0001">TS-R0001</a>
resource: vm1
annotations:
message: "vm1 disk usage above 90% utilization"
Depois de verificar a estabilidade do sistema, mudamos o foco para os modos de falha do aplicativo no sistema de tíquetes. Como a depuração de problemas no aplicativo geralmente exigia o uso do shell seguro (SSH) em cada VM do servidor de aplicativos para verificar os registros do sistema de tíquetes, configuramos um aplicativo para encaminhar esses registros para a ferramenta de geração de registros e criar a pilha de observabilidade do GDC e consultar todos os registros operacionais do sistema de tíquetes na instância de monitoramento.
A geração de registros centralizada também permitiu consultar registros de várias VMs ao mesmo tempo, consolidando nossa visão de cada componente do sistema.
Backups
Os backups são importantes para a operabilidade de um sistema de software porque permitem que ele seja restaurado em caso de falha.
O GDC oferece backup e restauração de VM usando
recursos do Kubernetes. Criar um recurso personalizado VirtualMachineBackupRequest
com um recurso personalizado VirtualMachineBackupPlanTemplate permite fazer backup do
volume permanente anexado a cada VM no armazenamento de objetos, em que os backups podem
ser retidos seguindo uma política de retenção definida.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupPlanTemplate
metadata:
name: vm-backup-plan
spec:
backupRepository: "backup-repository"
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupRequest
metadata:
name: "db-vm-backup"
spec:
virtualMachineBackupPlanTemplate: vm-backup-plan
virtualMachine: db1
virtualMachineBackupName: db-vm-backup
Da mesma forma, restaurar um estado de VM do backup envolve criar um
recurso personalizado VirtualMachineRestoreRequest para restaurar os servidores de aplicativos e
banco de dados sem modificar o código ou a configuração de nenhum dos
serviços.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineRestoreRequest
metadata:
name: vm-restore-1
spec:
virtualMachineBackup: db-vm-backup
restoreName: restore1
restoredResourceName: db1
Upgrades
Para oferecer suporte ao ciclo de vida do software do sistema de emissão de passagens e das dependências dele, identificamos três tipos de upgrades de software, cada um processado individualmente para minimizar o tempo de inatividade e a interrupção do serviço:
- Upgrades do SO.
- Upgrades de plataforma, como patch e versões principais.
- Atualizações de configuração.
Para upgrades de SO, criamos e lançamos continuamente novas imagens de VM para servidores de aplicativos e de banco de dados, que são distribuídas com cada versão do GDC. Essas imagens contêm correções para vulnerabilidades de segurança e atualizações do sistema operacional subjacente.
Os upgrades da plataforma do sistema de tíquetes exigem a aplicação de atualizações nas imagens de VM atuais. Por isso, não podemos confiar em uma infraestrutura imutável para fazer correções e atualizações de versão principal. Para upgrades de plataforma, testamos e verificamos a versão do patch ou do lançamento principal nos nossos ambientes de desenvolvimento e de preparo antes de lançar um pacote de upgrade independente junto com a versão do GDC.
Por fim, as atualizações de configuração são aplicadas sem tempo de inatividade pelas APIs do sistema de tíquetes para conjuntos de atualização e outros dados do usuário. Desenvolvemos e testamos atualizações de configuração nos nossos ambientes de desenvolvimento e de preparo antes de empacotar vários conjuntos de atualizações juntos durante o processo de lançamento da GDC.
Integrações
Provedores de identidade
Para oferecer aos clientes uma jornada perfeita e permitir que as organizações integrem os usuários, integramos o sistema de tíquetes com vários provedores de identidade disponíveis no GDC. Normalmente, os clientes empresariais e do setor público têm provedores de identidade bem gerenciados para conceder e revogar direitos aos funcionários. Devido aos requisitos de compliance e à facilidade de governança de identidade e acesso, esses clientes querem usar os provedores de identidade atuais como fonte de verdade para gerenciar o acesso dos funcionários ao sistema de tíquetes.
O sistema de tíquetes é compatível com provedores SAML 2.0 e OIDC pelo módulo de vários provedores de identidade, que já está ativado na imagem da VM do servidor de aplicativos. Os clientes se autenticam pelo provedor de identidade da organização, que cria usuários e atribui funções automaticamente no sistema de tíquetes.
A saída para servidores de provedores de identidade é permitida pelo recurso personalizado
ProjectNetworkPolicy, que limita se os serviços externos podem ser
acessados de uma organização no GDC. Essas políticas
permitem controlar de forma declarativa quais endpoints o sistema de emissão de passagens pode acessar
na rede.
Ingestão de alertas
Além de permitir que os usuários façam login para criar casos de suporte manualmente, também criamos incidentes do sistema de tíquetes em resposta a alertas do sistema.
Para fazer essa integração, personalizamos um webhook do Kubernetes de código aberto para receber alertas do aplicativo e gerenciar o ciclo de vida dos incidentes usando o endpoint de API do sistema de tíquetes exposto pelo Cloud Service Mesh.
As chaves de API são armazenadas usando o repositório de secrets do GDC, com suporte de secrets do Kubernetes controlados pelo controle de acesso baseado em papéis (RBAC). Outras configurações, como endpoints de API e campos de personalização de incidentes, são gerenciadas pelo armazenamento de chave-valor do ConfigMap do Kubernetes.
O sistema de tíquetes oferece integrações com servidores de e-mail para que os clientes recebam suporte por e-mail. Os fluxos de trabalho automatizados convertem e-mails de clientes recebidos em casos de suporte e enviam respostas automáticas com links para os casos. Assim, nossa equipe de suporte gerencia melhor a caixa de entrada, rastreia e resolve sistematicamente os pedidos por e-mail e oferece um atendimento ao cliente melhor.
apiVersion: networking.gdc.goog/v1
kind: ProjectNetworkPolicy
metadata:
name: allow-ingress-traffic-from-ticketing-system
spec:
subject:
subjectType: UserWorkload
ingress:
- from:
- projects:
matchNames:
- ticketing-system
Expor o e-mail como um serviço do Kubernetes também oferece descoberta de serviços e resolução de nomes de domínio, além de desacoplar ainda mais o back-end do servidor de e-mail de clientes como o sistema de emissão de tíquetes.
Compliance
Registro de auditoria
Os registros de auditoria contribuem para a postura de compliance ao fornecer uma maneira de rastrear e monitorar o uso de software e fornecer um registro da atividade do sistema. Os registros de auditoria registram tentativas de acesso por usuários não autorizados, rastreiam o uso da API e identificam possíveis riscos de segurança. Os registros de auditoria atendem aos requisitos de compliance, como os impostos pela Lei de Portabilidade e Responsabilidade de Seguros de Saúde (HIPAA), pelo Padrão de Segurança de Dados do Setor de Cartões de Pagamento (PCI DSS) e pela Lei Sarbanes-Oxley (SOX).
O GDC oferece um sistema para registrar atividades e acessos administrativos na plataforma e reter esses registros por um período configurável. A implantação do recurso personalizado AuditLoggingTarget
configura o pipeline de geração de registros para coletar registros de auditoria do aplicativo.
Para o sistema de tíquetes, configuramos destinos de registro de auditoria para eventos de auditoria do sistema coletados e eventos específicos do aplicativo gerados pelo registro de auditoria de segurança do sistema de tíquetes. Os dois tipos de registros são enviados a uma instância centralizada do Loki, em que podemos gravar consultas e visualizar painéis na instância de monitoramento.
Controle de acesso
O controle de acesso é o processo de conceder ou negar acesso a recursos com base na identidade do usuário ou do processo que solicita o acesso. Isso ajuda a proteger os dados contra acesso não autorizado e garante que apenas usuários autorizados possam fazer mudanças no sistema. No GDC, usamos o RBAC do Kubernetes para declarar políticas e aplicar autorização aos recursos do sistema que consistem no aplicativo do sistema de tíquetes.
Ao definir um ProjectRole no GDC, podemos conceder acesso refinado aos recursos do Kubernetes usando um papel de autorização predefinido.
apiVersion: resourcemanager.gdc.goog/v1
kind: ProjectRole
metadata:
name: ticketing-system-admin
labels:
resourcemanager.gdc.goog/rbac-selector: system
spec:
rules:
- apiGroups:
- ""
resources:
- configmaps
- events
- pods/log
- services
verbs:
- get
- list
Recuperação de desastres
Réplica do banco de dados
Para atender aos requisitos de recuperação de desastres (DR), implantamos o sistema de emissão de tíquetes em uma configuração principal-secundária em várias instâncias do GDC. Nesse modo, as solicitações ao sistema de emissão de tíquetes são normalmente encaminhadas para o site principal, enquanto o site secundário replica continuamente o registro binário do banco de dados. Em caso de failover, o site secundário é promovido a site principal, e as solicitações são encaminhadas para ele.
Usamos recursos de replicação de banco de dados para configurar os servidores de banco de dados principal e de réplica por instância do GDC com base nos parâmetros definidos.
Para ativar a replicação em uma instância que está em execução há mais tempo do que o período de armazenamento do registro binário, podemos restaurar o banco de dados de réplica usando o backup do banco de dados para iniciar a replicação do banco de dados principal.
No modo principal, os servidores de aplicativos e o banco de dados funcionam da mesma forma que hoje, mas o banco de dados principal é configurado para ativar a replicação. Exemplo:
Ative o registro binário.
Defina o ID do servidor.
Crie uma conta de usuário de replicação.
Criar um backup.
No modo de réplica, os servidores de aplicativos desativam o serviço da Web de emissão de tíquetes para evitar a conexão direta com o banco de dados de réplica. O banco de dados de réplica precisa ser configurado para iniciar a replicação do banco de dados principal, por exemplo:
Defina o ID do servidor.
Configure as credenciais do usuário de replicação e os detalhes da conexão principal, como host e porta.
Restaure a posição do registro binário de retomada do backup.
A replicação de banco de dados exige conectividade de rede para que a réplica se conecte ao banco de dados principal e inicie a replicação. Para expor o endpoint do banco de dados principal para replicação, usamos o Cloud Service Mesh para criar uma malha de serviço de entrada que oferece suporte à término de TLS na malha de serviço, semelhante a como processamos a transferência de dados HTTPS no aplicativo da Web do sistema de emissão de passagens.