Este guia aborda o contexto conceptual necessário para implementar uma carga de trabalho baseada em máquinas virtuais (VMs) num cluster isolado do Google Distributed Cloud (GDC) num sistema bare metal através de um tempo de execução de VMs. A carga de trabalho neste guia é uma plataforma de sistema de emissão de bilhetes de amostra que está disponível em hardware no local.
Arquitetura
Hierarquia de recursos
No GDC, implementa os componentes que constituem o sistema de emissão de pedidos num inquilino dedicado da organização para a equipa de operações, idêntico a qualquer organização de clientes. Uma organização é uma coleção de clusters, recursos de infraestrutura e cargas de trabalho de aplicações que são administrados em conjunto. Cada organização numa instância da GDC usa um conjunto dedicado de servidores, o que proporciona um forte isolamento entre inquilinos. Para mais informações sobre a infraestrutura, consulte o artigo Crie limites de acesso.
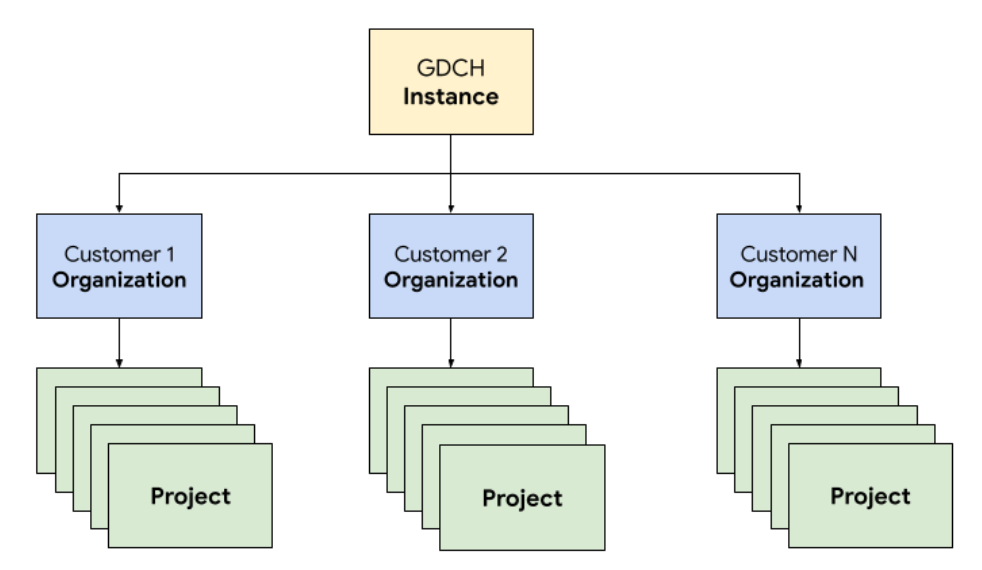
Além disso, implementa e gere os recursos do sistema de pedidos em conjunto num projeto, o que oferece isolamento lógico numa organização através de políticas de software e aplicação. Os recursos num projeto destinam-se a associar componentes que têm de permanecer juntos durante o respetivo ciclo de vida.
O sistema de emissão de bilhetes segue uma arquitetura de três camadas que se baseia num equilibrador de carga para direcionar o tráfego entre servidores de aplicações que se ligam a um servidor de base de dados que armazena dados persistentes.
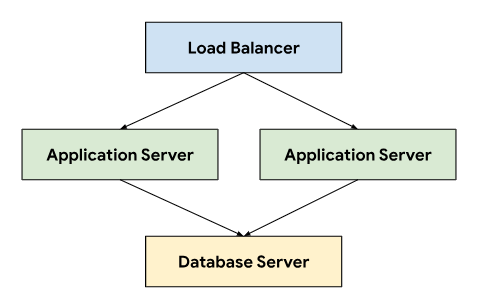
Esta arquitetura permite a escalabilidade e a capacidade de manutenção, uma vez que cada nível pode ser desenvolvido e mantido de forma independente. Também oferece uma separação clara de preocupações, o que simplifica a depuração e a resolução de problemas. Encapsular estes níveis num projeto do GDC permite implementar e gerir componentes em conjunto, por exemplo, os servidores de aplicações e de bases de dados.
Redes
A execução do sistema de emissão de bilhetes num ambiente de produção requer a implementação de dois ou mais servidores de aplicações para alcançar uma elevada disponibilidade em caso de falha do nó. Em combinação com um equilibrador de carga, esta topologia também permite distribuir a carga por várias máquinas para dimensionar horizontalmente a aplicação. A plataforma nativa do Kubernetes do GDC usa a malha de serviços na nuvem para encaminhar o tráfego de forma segura para os servidores de aplicações que compõem o sistema de emissão de bilhetes.
O Cloud Service Mesh é uma implementação da Google baseada no projeto de código aberto que gere, observa e protege os serviços. As seguintes funcionalidades do Cloud Service Mesh são usadas para alojar o sistema de emissão de bilhetes na GDC:
- Equilíbrio de carga: a malha de serviços na nuvem desvincula o fluxo de tráfego da escalabilidade da infraestrutura, o que abre muitas funcionalidades de gestão de tráfego, incluindo o encaminhamento dinâmico de pedidos. O sistema de emissão de bilhetes requer ligações de cliente persistentes, pelo que ativamos as sessões persistentes através da
DestinationRulespara configurar o comportamento de encaminhamento de tráfego.
Rescisão de TLS: o Cloud Service Mesh expõe gateways de entrada através de certificados TLS e fornece autenticação de transporte no cluster através de mTLS (Mutual Transport Layer Security) sem ter de alterar qualquer código de aplicação.
Recuperação de falhas: o Cloud Service Mesh oferece várias funcionalidades críticas de recuperação de falhas, incluindo limites de tempo, disjuntores, verificações de estado ativas e novas tentativas limitadas.
No cluster do Kubernetes, usamos objetos Service padrão como uma forma abstrata de expor os servidores de aplicações e bases de dados à rede. Os serviços oferecem uma forma conveniente de segmentar instâncias através de um seletor e fornecer resolução de nomes no cluster através de um servidor DNS compatível com o cluster.
apiVersion: v1
kind: Service
metadata:
name: http-ingress
spec:
selector:
app.kubernetes.io/component: application-server
ports:
- name: http
port: 80
---
apiVersion: v1
kind: Service
metadata:
name: database-ingress
spec:
selector:
app.kubernetes.io/component: database-server
ports:
- name: mysql
port: 3306
Computação
O sistema de emissão de bilhetes recomenda a utilização de hardware físico ou máquinas virtuais para alojar instalações no local, e utilizámos a gestão de máquinas virtuais (VM) do GDC para implementar os servidores de aplicações e de bases de dados como cargas de trabalho de VMs. A definição de recursos do Kubernetes permitiu-nos especificar o VirtualMachine e o VirtualMachineDisk para personalizar os recursos de acordo com as nossas necessidades para os diferentes tipos de servidores. VirtualMachineExternalAccess permite-nos configurar a transferência de dados de entrada e de saída para a VM.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineDisk
metadata:
name: vm1-boot-disk
spec:
size: 100G
source:
image:
name: ts-ticketing-system-app-server-2023-08-18-203258
namespace: vm-system
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachine
metadata:
labels:
app.kubernetes.io/component: application-server
name: vm1
namespace: support
spec:
compute:
vcpus: 8
memory: 12G
disks:
- boot: true
virtualMachineDiskRef:
name: vm1-boot-disk
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineExternalAccess
metadata:
name: vm1
namespace: support
spec:
enabled: true
ports:
- name: ssh
protocol: TCP
port: 22
Para a imagem do SO convidado, criámos uma imagem personalizada para cumprir os nossos requisitos de conformidade e segurança. É possível estabelecer ligação a instâncias de VM em execução através do SSH com o VirtualMachineAccessRequest, o que nos permite limitar a capacidade de estabelecer ligação a VMs através do RBAC do Kubernetes e evitar a necessidade de criar contas de utilizador locais nas imagens personalizadas. O pedido de acesso também define um tempo de vida (TTL) que permite que os pedidos de acesso baseados no tempo geram as VMs que expiram automaticamente.
Automatização
Como um resultado fundamental deste projeto, concebemos uma abordagem para instalar instâncias do sistema de emissão de bilhetes de forma repetível que possa suportar uma automatização extensiva e reduzir a variação da configuração entre implementações.
Pipeline de lançamento
A personalização das imagens do servidor de aplicações e de base de dados começa com uma imagem do sistema operativo base, modificando a imagem base conforme necessário para instalar as dependências necessárias para cada imagem do servidor. Selecionámos uma imagem do SO base pela sua adoção generalizada em sistemas de pedidos de alojamento em instalações no local. Esta imagem do SO base também oferece capacidades de reforço da segurança necessárias para cumprir os Guias de implementação técnica de segurança (STIGs) necessários para fornecer uma imagem em conformidade que cumpra os controlos NIST-800-53.
O nosso pipeline de integração contínua (CI) usou o seguinte fluxo de trabalho para personalizar imagens de servidores de aplicações e bases de dados:
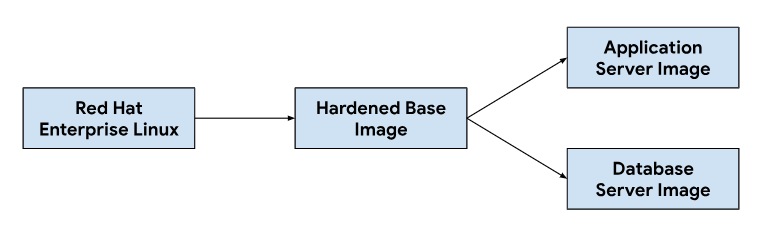
Quando os programadores fazem alterações aos scripts de personalização ou às dependências de imagens, acionamos um fluxo de trabalho automatizado nas nossas ferramentas de IC para gerar um novo conjunto de imagens que são incluídas nas versões do GDC. Como parte da criação de imagens, também atualizamos as dependências do SO (yum update) e tornamos a imagem esparsa com compressão para reduzir o tamanho da imagem necessário para transferir imagens para ambientes de clientes.
Ciclo de vida da programação de software
O ciclo de vida de desenvolvimento de software (SDLC) é um processo que ajuda as organizações a planear, criar, testar e implementar software. Seguindo um SDLC bem definido, as organizações garantem que o software é desenvolvido de forma consistente e repetível e identificam potenciais problemas numa fase inicial. Além de criar imagens na nossa pipeline de integração contínua (IC), também definimos ambientes para desenvolver e preparar versões de pré-lançamento do sistema de emissão de bilhetes para testes e controlo de qualidade.
A implementação de uma instância separada do sistema de emissão de bilhetes por projeto do GDC permitiu-nos testar as alterações de forma isolada, sem afetar as instâncias existentes na mesma instância do GDC. Usámos a API ResourceManager para criar e desativar declarativamente projetos através de recursos do Kubernetes.
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-dev
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-qa
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-staging
Em combinação com a criação de pacotes de gráficos e a gestão de infraestruturas, como máquinas virtuais, como código, os programadores podem iterar rapidamente, fazendo alterações e testando novas funcionalidades juntamente com instâncias de produção. A API declarativa também permite que as frameworks de execução de testes automatizados realizem testes de regressão regulares e verifiquem as capacidades existentes.
Operabilidade
A operabilidade é a facilidade com que um sistema pode ser operado e mantido. É uma consideração importante no design de qualquer aplicação de software. A monitorização eficaz contribui para a operacionalidade porque permite identificar e resolver problemas antes que tenham um impacto significativo no sistema. A monitorização também pode ser usada para identificar oportunidades de melhoria e estabelecer uma base para os objetivos ao nível do serviço (SLO).
Monitorização
Integrámos o sistema de pedidos com a infraestrutura de observabilidade da GDC existente, incluindo registo e métricas. Para as métricas, expomos pontos finais HTTP de cada VM que permitem à aplicação extrair pontos de dados produzidos pelos servidores de aplicações e bases de dados. Estes pontos finais incluem métricas do sistema recolhidas através do exportador de nós da aplicação e métricas específicas da aplicação.
Com os pontos finais expostos em cada VM, configurámos o comportamento de sondagem da aplicação através do recurso personalizado MonitoringTarget para definir o intervalo de recolha e anotar as métricas.
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringTarget
metadata:
name: database-monitor
spec:
podMetricsEndpoints:
path:
value: /metrics
port:
annotation: application.io/dbMetrics
scrapeInterval: 60s
Para o registo, instalámos e configurámos um processador de registo e métricas em cada VM para monitorizar os registos relevantes e enviar dados de registo para a ferramenta de registo, onde os dados são indexados e consultados através da instância de monitorização. Os registos de auditoria são encaminhados para um ponto final especial configurado com retenção alargada para conformidade. As aplicações baseadas em contentores podem usar o recurso personalizado LoggingTarget e AuditLoggingTarget para dar instruções ao pipeline de registo para recolher registos de serviços específicos no seu projeto.
Com base nos dados disponíveis nos processadores de registo e monitorização, criámos alertas através do recurso personalizado MonitoringRule, que nos permite gerir esta configuração como código na nossa embalagem de gráficos. A utilização de uma API declarativa para definir alertas e painéis de controlo também nos permite armazenar esta configuração no nosso repositório de código e seguir os mesmos processos de revisão de código e integração contínua nos quais confiamos para quaisquer outras alterações de código.
Modos de falha
Os testes iniciais revelaram vários modos de falha relacionados com recursos que nos ajudaram a dar prioridade às métricas e aos alertas a adicionar primeiro. Começámos por monitorizar a utilização elevada de memória e disco, uma vez que a configuração incorreta da base de dados levou inicialmente a que as tabelas de buffer consumissem toda a memória disponível e o registo excessivo preenchesse o disco de volume persistente anexado. Depois de ajustar o tamanho do buffer de armazenamento e implementar uma estratégia de rotação de registos, introduzimos alertas que são executados se as VMs se aproximarem de uma utilização elevada de memória ou disco.
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringRule
metadata:
name: monitoring-rule
spec:
interval: 60s
limit: 0
alertRules:
- alert: vm1_disk_usage
expr:
(node_filesystem_size_bytes{container_name="compute"} -
node_filesystem_avail_bytes{container_name="compute"}) * 100 /
node_filesystem_size_bytes{container_name="compute"} > 90
labels:
severity: error
code: <a href="/distributed-cloud/hosted/docs/latest/gdch/gdch-io/service-manual/ts/runbooks/ts-r0001">TS-R0001</a>
resource: vm1
annotations:
message: "vm1 disk usage above 90% utilization"
Após a validação da estabilidade do sistema, mudámos o nosso foco para os modos de falha da aplicação no sistema de emissão de pedidos. Uma vez que a resolução de problemas na aplicação exigia frequentemente que usássemos o shell seguro (SSH) em cada VM do servidor de aplicações para verificar os registos do sistema de pedidos de apoio técnico, configurámos uma aplicação para encaminhar estes registos para a ferramenta de registo, de modo a criar a pilha de observabilidade da GDC e consultar todos os registos operacionais do sistema de pedidos de apoio técnico na instância de monitorização.
O registo centralizado também nos permitiu consultar registos de várias VMs ao mesmo tempo, consolidando a nossa vista de cada componente do sistema.
Cópias de segurança
As cópias de segurança são importantes para a operacionalidade de um sistema de software porque
permitem que o sistema seja restaurado em caso de falha.
O GDC oferece cópias de segurança e restauro de VMs através de recursos do Kubernetes. A criação de um VirtualMachineBackupRequest recurso personalizado
com um VirtualMachineBackupPlanTemplate recurso personalizado permite-nos fazer uma cópia de segurança do
volume persistente anexado a cada VM para o armazenamento de objetos, onde as cópias de segurança podem
ser retidas de acordo com uma política de retenção definida.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupPlanTemplate
metadata:
name: vm-backup-plan
spec:
backupRepository: "backup-repository"
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupRequest
metadata:
name: "db-vm-backup"
spec:
virtualMachineBackupPlanTemplate: vm-backup-plan
virtualMachine: db1
virtualMachineBackupName: db-vm-backup
Da mesma forma, o restauro do estado de uma VM a partir da cópia de segurança envolve a criação de um
VirtualMachineRestoreRequest recurso personalizado para restaurar os servidores de aplicações e
bases de dados sem modificar o código nem a configuração de nenhum dos
serviços.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineRestoreRequest
metadata:
name: vm-restore-1
spec:
virtualMachineBackup: db-vm-backup
restoreName: restore1
restoredResourceName: db1
Atualizações
Para suportar o ciclo de vida do software do sistema de emissão de bilhetes e as respetivas dependências, identificámos três tipos de atualizações de software, cada um processado individualmente para minimizar o tempo de inatividade e a interrupção do serviço:
- Atualizações do SO.
- Atualizações da plataforma, como patches e versões principais.
- Atualizações da configuração.
Para as atualizações do SO, criamos e lançamos continuamente novas imagens de VMs para servidores de aplicações e bases de dados que são distribuídas com cada lançamento do GDC. Estas imagens contêm correções para vulnerabilidades de segurança e atualizações ao sistema operativo subjacente.
As atualizações da plataforma do sistema de emissão de bilhetes requerem a aplicação de atualizações às imagens de VMs existentes, pelo que não podemos confiar na infraestrutura imutável para aplicar patches e atualizações de versões principais. Para atualizações de plataformas, testamos e validamos a versão de patch ou de lançamento principal nos nossos ambientes de desenvolvimento e teste antes de lançar um pacote de atualização autónomo juntamente com o lançamento do GDC.
Por último, as atualizações de configuração são aplicadas sem tempo de inatividade através das APIs do sistema de pedidos para conjuntos de atualizações e outros dados do utilizador. Desenvolvemos e testamos atualizações de configuração nos nossos ambientes de desenvolvimento e preparação antes de reunirmos vários conjuntos de atualizações durante o processo de lançamento da GDC.
Integrações
Fornecedores de identidade
Para oferecer aos clientes um percurso perfeito e permitir que as organizações integrem os respetivos utilizadores, integramos o sistema de emissão de bilhetes com vários fornecedores de identidades disponíveis no GDC. Normalmente, os clientes empresariais e do setor público têm os seus próprios fornecedores de identidade bem geridos para conceder e revogar a autorização aos respetivos funcionários. Devido aos requisitos de conformidade e à facilidade de governação de identidade e acesso, estes clientes querem usar os respetivos fornecedores de identidade existentes como a fonte de verdade para gerir o acesso dos funcionários ao sistema de pedidos.
O sistema de emissão de pedidos suporta fornecedores SAML 2.0 e OIDC através do respetivo módulo de vários fornecedores de identidade, que pré-ativámos na nossa imagem de VM do servidor de aplicações. Os clientes autenticam-se através do fornecedor de identidade da respetiva organização, o que cria automaticamente utilizadores e atribui funções no sistema de emissão de bilhetes.
A saída para servidores de fornecedores de identidade é permitida através do recurso personalizado ProjectNetworkPolicy, que limita se os serviços externos são acessíveis a partir de uma organização no GDC. Estas políticas
permitem-nos controlar declarativamente a que pontos finais o sistema de emissão de bilhetes pode aceder
na rede.
Carregamento de alertas
Além de permitir que os utilizadores iniciem sessão para criar manualmente registos de apoio técnico, também criamos incidentes do sistema de registo de pedidos em resposta a alertas do sistema.
Para alcançar esta integração, personalizámos um webhook Kubernetes de código aberto para receber alertas da aplicação e gerir o ciclo de vida dos incidentes através do ponto final da API do sistema de pedidos exposto através do Cloud Service Mesh.
As chaves de API são armazenadas através do armazenamento secreto do GDC, suportado por segredos do Kubernetes controlados através do controlo de acesso baseado em funções (CABF). Outras configurações, como os pontos finais da API e os campos de personalização de incidentes, são geridas através do armazenamento de pares chave-valor do ConfigMap do Kubernetes.
O sistema de emissão de pedidos oferece integrações de servidores de correio para permitir que os clientes recebam apoio técnico baseado em email. Os fluxos de trabalho automatizados convertem emails de clientes recebidos em registos de apoio técnico e enviam respostas automáticas aos clientes com links para os registos, o que permite à nossa equipa de apoio técnico gerir melhor a respetiva caixa de entrada, monitorizar e resolver sistematicamente as solicitações por email e oferecer um melhor serviço de apoio ao cliente.
apiVersion: networking.gdc.goog/v1
kind: ProjectNetworkPolicy
metadata:
name: allow-ingress-traffic-from-ticketing-system
spec:
subject:
subjectType: UserWorkload
ingress:
- from:
- projects:
matchNames:
- ticketing-system
Expor o email como um serviço Kubernetes também fornece deteção de serviços e resolução de nomes de domínio, e desvincula ainda mais o back-end do servidor de email de clientes como o sistema de pedidos.
Conformidade
Registo de auditoria
Os registos de auditoria contribuem para a postura de conformidade, oferecendo uma forma de acompanhar e monitorizar a utilização de software, bem como fornecer um registo da atividade do sistema. Os registos de auditoria registam tentativas de acesso por utilizadores não autorizados, monitorizam a utilização da API e identificam potenciais riscos de segurança. Os registos de auditoria cumprem os requisitos de conformidade, como os impostos pela Health Insurance Portability and Accountability Act (HIPAA), pela Norma de Segurança de Dados do Setor de Cartões de Pagamento (PCI DSS) e pela Sarbanes-Oxley Act (SOX).
O GDC oferece um sistema para registar atividades e acessos administrativos na plataforma e reter estes registos durante um período configurável. A implementação do recurso personalizado AuditLoggingTargetconfigura o pipeline de registo para recolher registos de auditoria da nossa aplicação.
Para o sistema de emissão de bilhetes, configurámos destinos de registo de auditoria para eventos de auditoria do sistema recolhidos e eventos específicos da aplicação gerados pelo registo de auditoria de segurança do sistema de emissão de bilhetes. Ambos os tipos de registos são enviados para uma instância Loki centralizada, onde podemos escrever consultas e ver painéis de controlo na instância de monitorização.
Controlo de acesso
O controlo de acesso é o processo de concessão ou negação de acesso a recursos com base na identidade do utilizador ou do processo que solicita o acesso. Isto ajuda a proteger os dados contra o acesso não autorizado e a garantir que apenas os utilizadores autorizados podem fazer alterações ao sistema. No GDC, baseamo-nos no RBAC do Kubernetes para declarar políticas e aplicar a autorização aos recursos do sistema que consistem na aplicação do sistema de emissão de bilhetes.
A definição de um ProjectRole no GDC permite-nos conceder
acesso detalhado aos recursos do Kubernetes através de uma função de autorização predefinida.
apiVersion: resourcemanager.gdc.goog/v1
kind: ProjectRole
metadata:
name: ticketing-system-admin
labels:
resourcemanager.gdc.goog/rbac-selector: system
spec:
rules:
- apiGroups:
- ""
resources:
- configmaps
- events
- pods/log
- services
verbs:
- get
- list
Recuperação de desastres
Replicação de base de dados
Para cumprir os requisitos de recuperação de desastres (RD), implementamos o sistema de pedidos numa configuração primária-secundária em várias instâncias do GDC. Neste modo, os pedidos ao sistema de emissão de bilhetes são normalmente encaminhados para o site principal, enquanto o site secundário replica continuamente o registo binário da base de dados. No caso de um evento de comutação por falha, o site secundário é promovido a novo site principal e os pedidos são, em seguida, encaminhados para o novo site principal.
Tiramos partido das capacidades de replicação da base de dados para configurar os servidores de base de dados principal e de réplica por instância do GDC com base nos parâmetros definidos.
Para ativar a replicação para uma instância existente que está em execução há mais tempo do que o período de retenção do registo binário, podemos restaurar a base de dados de réplica através da cópia de segurança da base de dados para iniciar a replicação a partir da base de dados principal.
No modo principal, os servidores de aplicações e a base de dados funcionam da mesma forma que atualmente, mas a base de dados principal está configurada para ativar a replicação. Por exemplo:
Ative o registo binário.
Defina o ID do servidor.
Crie uma conta de utilizador de replicação.
Crie uma cópia de segurança.
No modo de réplica, os servidores de aplicações desativam o serviço Web de emissão de bilhetes para evitar a ligação direta à base de dados de réplica. A base de dados de réplica tem de ser configurada para iniciar a replicação a partir da base de dados principal, por exemplo:
Defina o ID do servidor.
Configure as credenciais do utilizador de replicação e os detalhes da ligação principal, como o anfitrião e a porta.
Restaurar a partir da cópia de segurança: retomar a posição do registo binário.
A replicação da base de dados requer conetividade de rede para que a réplica se ligue à base de dados principal para iniciar a replicação. Para expor o ponto final da base de dados principal para replicação, usamos a Cloud Service Mesh para criar uma malha de serviços de entrada que suporta a terminação TLS na malha de serviços, de forma semelhante à forma como processamos a transferência de dados HTTPS na aplicação Web do sistema de emissão de bilhetes.