Questa guida illustra il contesto concettuale necessario per eseguire il deployment di un carico di lavoro basato su macchina virtuale (VM) in un cluster air-gap Google Distributed Cloud (GDC) su bare metal utilizzando un runtime VM. Il workload in questa guida è una piattaforma di sistema di ticketing di esempio disponibile su hardware on-premise.
Architettura
Gerarchia delle risorse
In GDC, implementi i componenti che costituiscono il sistema di gestione dei ticket in un'organizzazione tenant dedicata per il team delle operazioni, identica a qualsiasi organizzazione cliente. Un'organizzazione è un insieme di cluster, risorse di infrastruttura e carichi di lavoro delle applicazioni che vengono amministrati insieme. Ogni organizzazione in un'istanza GDC utilizza un insieme dedicato di server, garantendo un forte isolamento tra i tenant. Per ulteriori informazioni sull'infrastruttura, consulta Progettare i limiti di accesso.
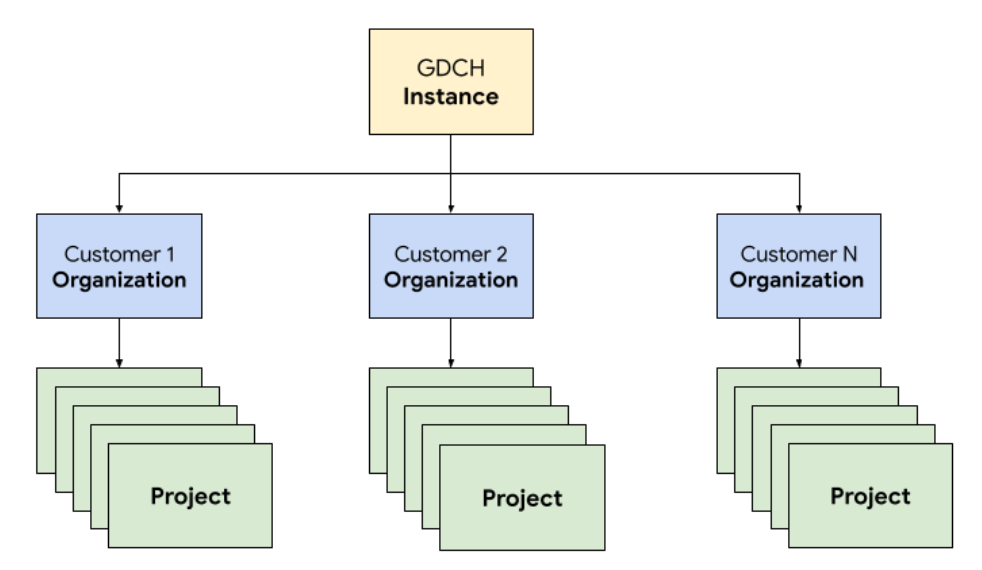
Inoltre, esegui il deployment e gestisci le risorse del sistema di gestione dei ticket insieme in un progetto, che fornisce l'isolamento logico all'interno di un'organizzazione utilizzando criteri software e applicazione. Le risorse di un progetto sono pensate per accoppiare i componenti che devono rimanere insieme per il loro ciclo di vita.
Il sistema di ticketing segue un'architettura a tre livelli che si basa su un bilanciatore del carico per indirizzare il traffico tra i server delle applicazioni che si connettono a un server di database che archivia i dati persistenti.
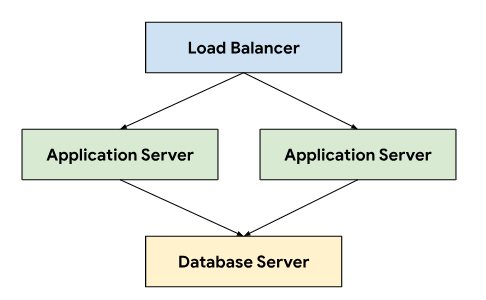
Questa architettura consente scalabilità e manutenibilità, poiché ogni livello può essere sviluppato e gestito in modo indipendente. Fornisce inoltre una chiara separazione delle competenze, il che semplifica il debug e la risoluzione dei problemi. L'incapsulamento di questi livelli all'interno di un progetto GDC consente di eseguire il deployment e gestire i componenti insieme, ad esempio i server delle applicazioni e dei database.
Networking
L'esecuzione del sistema di ticketing in un ambiente di produzione richiede il deployment di due o più server delle applicazioni per ottenere un'alta disponibilità in caso di errore del nodo. In combinazione con un bilanciatore del carico, questa topologia consente anche di distribuire il carico su più macchine per scalare orizzontalmente l'applicazione. La piattaforma Kubernetes nativa di GDC utilizza Cloud Service Mesh per instradare in modo sicuro il traffico ai server delle applicazioni che compongono il sistema di emissione dei biglietti.
Cloud Service Mesh è un'implementazione di Google basata sul progetto open source che gestisce, osserva e protegge i servizi. Per ospitare il sistema di ticketing su GDC vengono utilizzate le seguenti funzionalità di Cloud Service Mesh:
- Bilanciamento del carico: Cloud Service Mesh disaccoppia il flusso di traffico dalla scalabilità dell'infrastruttura, offrendo numerose funzionalità per la gestione del traffico, incluso il routing dinamico delle richieste. Il sistema di gestione dei ticket richiede connessioni client persistenti, pertanto attiviamo le sessioni permanenti utilizzando
DestinationRulesper configurare il comportamento di routing del traffico.
Terminazione TLS: Cloud Service Mesh espone i gateway di ingresso utilizzando i certificati TLS e fornisce l'autenticazione del trasporto all'interno del cluster tramite mTLS (Mutual Transport Layer Security) senza dover modificare il codice dell'applicazione.
Recupero da errori: Cloud Service Mesh fornisce una serie di funzionalità critiche per il recupero da errori, tra cui timeout, interruttori di sicurezza, controlli di integrità attivi e limitazione di nuovi tentativi.
All'interno del cluster Kubernetes, utilizziamo oggetti Service standard come modo astratto per esporre i server di applicazioni e database alla rete. I servizi forniscono un modo pratico per scegliere come target le istanze utilizzando un selettore e forniscono la risoluzione dei nomi all'interno del cluster utilizzando un server DNS compatibile con il cluster.
apiVersion: v1
kind: Service
metadata:
name: http-ingress
spec:
selector:
app.kubernetes.io/component: application-server
ports:
- name: http
port: 80
---
apiVersion: v1
kind: Service
metadata:
name: database-ingress
spec:
selector:
app.kubernetes.io/component: database-server
ports:
- name: mysql
port: 3306
Computing
Il sistema di gestione dei ticket consiglia di utilizzare macchine virtuali o bare metal per ospitare installazioni on-premise e abbiamo utilizzato la gestione delle macchine virtuali (VM) GDC per eseguire il deployment dei server delle applicazioni e dei database come carichi di lavoro VM. La definizione delle risorse Kubernetes ci ha consentito di specificare sia VirtualMachine sia VirtualMachineDisk per personalizzare le risorse in modo da soddisfare le nostre esigenze per i diversi tipi di server. VirtualMachineExternalAccess ci consente di configurare il trasferimento dei dati in entrata e in uscita per la VM.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineDisk
metadata:
name: vm1-boot-disk
spec:
size: 100G
source:
image:
name: ts-ticketing-system-app-server-2023-08-18-203258
namespace: vm-system
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachine
metadata:
labels:
app.kubernetes.io/component: application-server
name: vm1
namespace: support
spec:
compute:
vcpus: 8
memory: 12G
disks:
- boot: true
virtualMachineDiskRef:
name: vm1-boot-disk
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineExternalAccess
metadata:
name: vm1
namespace: support
spec:
enabled: true
ports:
- name: ssh
protocol: TCP
port: 22
Per l'immagine del sistema operativo guest, abbiamo creato un'immagine personalizzata per soddisfare i nostri requisiti di conformità e sicurezza. La connessione alle istanze VM in esecuzione è possibile tramite SSH utilizzando VirtualMachineAccessRequest, che ci consente di limitare la possibilità di connettersi alle VM tramite il controllo dell'accesso basato sui ruoli (RBAC) di Kubernetes ed evitare la necessità di creare account utente locali nelle immagini personalizzate. La richiesta di accesso definisce anche un
durata (TTL) che consente alle richieste di accesso basate sul tempo di gestire le VM che
scadono automaticamente.
Automazione
Come risultato chiave di questo progetto, abbiamo progettato un approccio per installare le istanze del sistema di gestione dei ticket in modo ripetibile, in grado di supportare un'ampia automazione e ridurre la deriva della configurazione tra i deployment.
Pipeline di rilascio
La personalizzazione delle immagini del server di applicazioni e del database inizia da un'immagine del sistema operativo di base, modificando l'immagine di base in base alle necessità per installare le dipendenze necessarie per ogni immagine del server. Abbiamo selezionato un'immagine del sistema operativo di base per la sua diffusa adozione di sistemi di gestione dei ticket di hosting in installazioni on-premise. Questa immagine del sistema operativo di base fornisce anche funzionalità di hardening della sicurezza necessarie per soddisfare le guide tecniche di implementazione della sicurezza (STIG) necessarie per fornire un'immagine conforme che soddisfi i controlli NIST-800-53.
La nostra pipeline di integrazione continua (CI) ha utilizzato il seguente flusso di lavoro per personalizzare le immagini dei server di applicazioni e database:
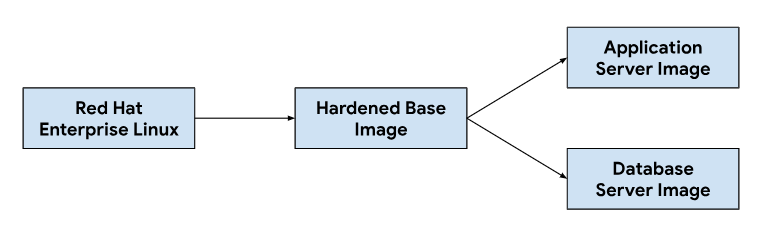
Quando gli sviluppatori apportano modifiche agli script di personalizzazione o alle dipendenze delle immagini, attiviamo un flusso di lavoro automatizzato nei nostri strumentiCIa per generare un nuovo set di immagini che vengono raggruppate con le release di GDC. Nell'ambito della creazione di immagini, aggiorniamo anche le dipendenze del sistema operativo (yum update) e rendiamo sparsa l'immagine con la compressione per ridurre le dimensioni dell'immagine necessarie per trasferire le immagini agli ambienti dei clienti.
Ciclo di vita dello sviluppo software
Il ciclo di vita dello sviluppo del software (SDLC) è un processo che aiuta le organizzazioni a pianificare, creare, testare ed eseguire il deployment del software. Seguendo un SDLC ben definito, le organizzazioni garantiscono che il software venga sviluppato in modo coerente e ripetibile e identificano potenziali problemi in anticipo. Oltre a creare immagini nella nostra pipeline di integrazione continua (CI), abbiamo anche definito ambienti per sviluppare e preparare le versioni di pre-release del sistema di ticketing per i test e il controllo qualità.
Il deployment di un'istanza separata del sistema di gestione dei ticket per progetto GDC ci ha consentito di testare le modifiche in isolamento, senza influire sulle istanze esistenti nella stessa istanza GDC. Abbiamo utilizzato l'API ResourceManager per creare e eliminare in modo dichiarativo i progetti utilizzando le risorse Kubernetes.
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-dev
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-qa
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-staging
In combinazione con il packaging dei grafici e la gestione dell'infrastruttura, ad esempio le macchine virtuali come codice, gli sviluppatori possono iterare rapidamente apportando modifiche e testando nuove funzionalità insieme alle istanze di produzione. L'API dichiarativa consente inoltre ai framework di esecuzione dei test automatizzati di eseguire test di regressione regolari e verificare le funzionalità esistenti.
Operabilità
L'operatività è la facilità con cui un sistema può essere utilizzato e mantenuto. È un aspetto importante da considerare nella progettazione di qualsiasi applicazione software. Un monitoraggio efficace contribuisce all'operatività perché consente di identificare e risolvere i problemi prima che abbiano un impatto significativo sul sistema. Il monitoraggio può essere utilizzato anche per identificare opportunità di miglioramento e stabilire una base di riferimento per gli obiettivi del livello di servizio (SLO).
Monitoraggio
Abbiamo integrato il sistema di gestione delle richieste con l'infrastruttura di osservabilità GDC esistente, inclusi logging e metriche. Per le metriche, esponiamo endpoint HTTP da ogni VM che consentono all'applicazione di recuperare i punti dati prodotti dai server di applicazioni e database. Questi endpoint includono metriche di sistema raccolte utilizzando l'esportatore di nodi dell'applicazione e metriche specifiche dell'applicazione.
Con gli endpoint esposti in ogni VM, abbiamo configurato il comportamento di polling dell'applicazione utilizzando la risorsa personalizzata MonitoringTarget per definire l'intervallo di scraping e annotare le metriche.
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringTarget
metadata:
name: database-monitor
spec:
podMetricsEndpoints:
path:
value: /metrics
port:
annotation: application.io/dbMetrics
scrapeInterval: 60s
Per la registrazione, abbiamo installato e configurato un processore di log e metriche in ogni VM per seguire i log pertinenti e inviare i dati di log allo strumento di logging, dove i dati vengono indicizzati ed eseguiti tramite query tramite l'istanza di monitoraggio. I log di controllo vengono
inoltrati a un endpoint speciale configurato con un periodo di conservazione esteso per
la conformità. Le applicazioni basate su container possono utilizzare le risorse personalizzate LoggingTarget e
AuditLoggingTarget per indicare alla pipeline di logging di
raccogliere i log di servizi specifici nel tuo progetto.
In base ai dati disponibili nei processori di logging e monitoraggio, abbiamo creato
avvisi utilizzando la risorsa personalizzata MonitoringRule, che ci consente di gestire
questa configurazione come codice nel nostro packaging dei grafici. L'utilizzo di un'API dichiarativa per definire avvisi e dashboard ci consente anche di archiviare questa configurazione nel nostro repository di codice e seguire gli stessi processi di revisione del codice e integrazione continua su cui facciamo affidamento per qualsiasi altra modifica del codice.
Modalità di errore
I test iniziali hanno rivelato diverse modalità di errore correlate alle risorse che ci hanno aiutato a dare la priorità alle metriche e agli avvisi da aggiungere per primi. Abbiamo iniziato con il monitoraggio dell'utilizzo elevato di memoria e disco, poiché la configurazione errata del database inizialmente ha portato a tabelle buffer che consumavano tutta la memoria disponibile e il logging eccessivo riempiva il disco del volume permanente collegato. Dopo aver modificato le dimensioni del buffer di archiviazione e implementato una strategia di rotazione dei log, abbiamo introdotto avvisi che vengono eseguiti se le VM si avvicinano a un utilizzo elevato della memoria o del disco.
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringRule
metadata:
name: monitoring-rule
spec:
interval: 60s
limit: 0
alertRules:
- alert: vm1_disk_usage
expr:
(node_filesystem_size_bytes{container_name="compute"} -
node_filesystem_avail_bytes{container_name="compute"}) * 100 /
node_filesystem_size_bytes{container_name="compute"} > 90
labels:
severity: error
code: <a href="/distributed-cloud/hosted/docs/latest/gdch/gdch-io/service-manual/ts/runbooks/ts-r0001">TS-R0001</a>
resource: vm1
annotations:
message: "vm1 disk usage above 90% utilization"
Dopo aver verificato la stabilità del sistema, abbiamo spostato l'attenzione sulle modalità di errore dell'applicazione all'interno del sistema di ticketing. Poiché il debug dei problemi all'interno dell'applicazione spesso richiedeva l'utilizzo di Secure Shell (SSH) in ogni VM del server delle applicazioni per controllare i log del sistema di gestione dei ticket, abbiamo configurato un'applicazione per inoltrare questi log allo strumento di logging per creare lo stack di osservabilità GDC e interrogare tutti i log operativi del sistema di gestione dei ticket nell'istanza di monitoraggio.
Il logging centralizzato ci ha anche consentito di eseguire query sui log di più VM contemporaneamente, consolidando la nostra visualizzazione di ogni componente del sistema.
Backup
I backup sono importanti per l'operatività di un sistema software perché
consentono di ripristinare il sistema in caso di guasto.
GDC offre il backup e il ripristino delle VM tramite
risorse Kubernetes. La creazione di una risorsa personalizzata VirtualMachineBackupRequest
con una risorsa personalizzata VirtualMachineBackupPlanTemplate ci consente di eseguire il backup del
volume permanente collegato a ogni VM nello spazio di archiviazione degli oggetti, dove i backup possono
essere conservati seguendo un criterio di conservazione impostato.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupPlanTemplate
metadata:
name: vm-backup-plan
spec:
backupRepository: "backup-repository"
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupRequest
metadata:
name: "db-vm-backup"
spec:
virtualMachineBackupPlanTemplate: vm-backup-plan
virtualMachine: db1
virtualMachineBackupName: db-vm-backup
Analogamente, il ripristino dello stato di una VM dal backup prevede la creazione di una risorsa personalizzata VirtualMachineRestoreRequest per ripristinare sia i server delle applicazioni sia quelli di database senza modificare il codice o la configurazione di nessuno dei due servizi.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineRestoreRequest
metadata:
name: vm-restore-1
spec:
virtualMachineBackup: db-vm-backup
restoreName: restore1
restoredResourceName: db1
Upgrade
Per supportare il ciclo di vita del software del sistema di emissione dei biglietti e delle relative dipendenze, abbiamo identificato tre tipi di aggiornamenti software, ognuno gestito individualmente per ridurre al minimo i tempi di inattività e l'interruzione del servizio:
- Aggiornamenti del sistema operativo.
- Upgrade della piattaforma, ad esempio patch e versioni principali.
- Aggiornamenti della configurazione.
Per gli upgrade del sistema operativo, creiamo e rilasciamo continuamente nuove immagini VM per i server di applicazioni e database che vengono distribuite con ogni release di GDC. Queste immagini contengono correzioni per le vulnerabilità di sicurezza e aggiornamenti del sistema operativo sottostante.
Gli upgrade della piattaforma del sistema di gestione dei ticket richiedono l'applicazione di aggiornamenti alle immagini VM esistenti, pertanto non possiamo fare affidamento su un'infrastruttura immutabile per eseguire patch e aggiornamenti delle versioni principali. Per gli upgrade della piattaforma, testiamo e verifichiamo la patch o la versione principale in uscita nei nostri ambienti di sviluppo e gestione temporanea prima di rilasciare un pacchetto di upgrade autonomo insieme al rilascio di GDC.
Infine, gli aggiornamenti della configurazione vengono applicati senza tempi di inattività tramite le API del sistema di gestione dei ticket per i set di aggiornamenti e altri dati utente. Sviluppiamo e testiamo gli aggiornamenti della configurazione nei nostri ambienti di sviluppo e staging prima di raggruppare più set di aggiornamenti durante la procedura di rilascio di GDC.
Integrazioni
Provider di identità
Per offrire ai clienti un percorso senza interruzioni e consentire alle organizzazioni di eseguire l'onboarding dei propri utenti, integriamo il sistema di gestione dei ticket con più provider di identità disponibili in GDC. In genere, i clienti enterprise e del settore pubblico hanno i propri provider di identità ben gestiti per concedere e revocare i diritti ai propri dipendenti. A causa dei requisiti di conformità e della facilità di gestione dell'identità e dell'accesso, questi clienti vogliono utilizzare i loro provider di identità esistenti come fonte di riferimento per gestire l'accesso dei dipendenti al sistema di ticketing.
Il sistema di gestione dei ticket supporta sia i provider SAML 2.0 sia OIDC tramite il modulo multi-provider di identità, che abbiamo preattivato nell'immagine VM del server delle applicazioni. I clienti si autenticano tramite il provider di identità della loro organizzazione, che crea automaticamente gli utenti e assegna i ruoli all'interno del sistema di gestione dei ticket.
L'uscita verso i server del provider di identità è consentita tramite la risorsa personalizzata ProjectNetworkPolicy, che limita la raggiungibilità dei servizi esterni da un'organizzazione in GDC. Queste norme
ci consentono di controllare in modo dichiarativo a quali endpoint può accedere il sistema di ticketing
sulla rete.
Importazione degli avvisi
Oltre a consentire agli utenti di accedere per creare manualmente richieste di assistenza, creiamo anche incidenti nel sistema di gestione dei ticket in risposta agli avvisi di sistema.
Per ottenere questa integrazione, abbiamo personalizzato un webhook Kubernetes open source per ricevere avvisi dall'applicazione e gestire il ciclo di vita degli incidenti utilizzando l'endpoint API del sistema di gestione dei ticket esposto tramite Cloud Service Mesh.
Le chiavi API vengono archiviate utilizzando l'archivio dei secret GDC, supportato dai secret di Kubernetes controllati tramitecontrollo dell'accessoo basato sui ruoli (RBAC). Altre configurazioni, come endpoint API e campi di personalizzazione degli incident, sono gestite tramite l'archiviazione di coppie chiave-valore ConfigMap di Kubernetes.
Il sistema di gestione dei ticket offre integrazioni del server di posta per consentire ai clienti di ricevere assistenza via email. I flussi di lavoro automatizzati convertono le email in arrivo dei clienti in richieste di assistenza e inviano risposte automatiche ai clienti con i link alle richieste, consentendo al nostro team di assistenza di gestire meglio la posta in arrivo, monitorare e risolvere sistematicamente le richieste via email e fornire un servizio clienti migliore.
apiVersion: networking.gdc.goog/v1
kind: ProjectNetworkPolicy
metadata:
name: allow-ingress-traffic-from-ticketing-system
spec:
subject:
subjectType: UserWorkload
ingress:
- from:
- projects:
matchNames:
- ticketing-system
L'esposizione dell'email come servizio Kubernetes fornisce anche Service Discovery e la risoluzione dei nomi di dominio e disaccoppia ulteriormente il backend del server di posta dai client come il sistema di gestione dei ticket.
Conformità
Audit logging
I log di controllo contribuiscono alla conformità fornendo un modo per monitorare l'utilizzo del software e fornire un record dell'attività di sistema. I log di controllo registrano i tentativi di accesso da parte di utenti non autorizzati, monitorano l'utilizzo delle API e identificano potenziali rischi per la sicurezza. I log di controllo soddisfano i requisiti di conformità, come quelli imposti da HIPAA (Health Insurance Portability and Accountability Act), PCI DSS (Payment Card Industry Data Security Standard) e SOX (Sarbanes-Oxley Act).
GDC fornisce un sistema per registrare le attività e gli accessi amministrativi all'interno della piattaforma e conservare questi log per un periodo di tempo configurabile. Il deployment della risorsa personalizzata AuditLoggingTarget
configura la pipeline di logging per raccogliere i log di controllo dalla nostra applicazione.
Per il sistema di gestione dei ticket, abbiamo configurato le destinazioni dell'audit logging sia per gli eventi di controllo del sistema raccolti sia per gli eventi specifici dell'applicazione generati dal log di controllo della sicurezza del sistema di gestione dei ticket. Entrambi i tipi di log vengono inviati a un'istanza Loki centralizzata in cui possiamo scrivere query e visualizzare le dashboard nell'istanza di monitoraggio.
Controllo degli accessi
Il controllo dell'accesso è il processo di concessione o negazione dell'accesso alle risorse in base all'identità dell'utente o del processo che richiede l'accesso. In questo modo, i dati vengono protetti da accessi non autorizzati e solo gli utenti autorizzati possono apportare modifiche al sistema. In GDC, ci affidiamo al controllo dell'accesso basato sui ruoli (RBAC) di Kubernetes per dichiarare le norme e applicare l'autorizzazione alle risorse di sistema che consistono nell'applicazione del sistema di gestione dei ticket.
La definizione di un ProjectRole in GDC ci consente di concedere
un accesso granulare alle risorse Kubernetes utilizzando un ruolo di autorizzazione preimpostato.
apiVersion: resourcemanager.gdc.goog/v1
kind: ProjectRole
metadata:
name: ticketing-system-admin
labels:
resourcemanager.gdc.goog/rbac-selector: system
spec:
rules:
- apiGroups:
- ""
resources:
- configmaps
- events
- pods/log
- services
verbs:
- get
- list
Disaster recovery
Replica dei database
Per soddisfare i requisiti di ripristino di emergenza, implementiamo il sistema di gestione dei ticket in una configurazione primaria-secondaria in più istanze GDC. In questa modalità, le richieste al sistema di gestione dei ticket vengono normalmente indirizzate al sito principale, mentre il sito secondario replica continuamente il log binario del database. In caso di evento di failover, il sito secondario viene promosso a nuovo sito principale e le richieste vengono quindi indirizzate al nuovo sito principale.
Sfruttiamo le funzionalità di replica del database per configurare i server di database primario e di replica per istanza GDC in base ai parametri impostati.
Per abilitare la replica per un'istanza esistente in esecuzione da più tempo del periodo di conservazione per il log binario, possiamo ripristinare il database di replica utilizzando il backup del database per iniziare la replica dal database principale.
In modalità primaria, i server delle applicazioni e il database funzionano come oggi, ma il database principale è configurato per abilitare la replica. Ad esempio:
Abilita il log binario.
Imposta l'ID server.
Crea un account utente di replica.
Creazione backup
In modalità di replica, i server delle applicazioni disattiveranno il servizio web di ticketing per evitare di connettersi direttamente al database di replica. Il database di replica deve essere configurato per avviare la replica dal database principale, ad esempio:
Imposta l'ID server.
Configura le credenziali dell'utente di replica e i dettagli della connessione primaria, come l'host e la porta.
Ripristina dalla posizione del log binario di ripristino del backup.
La replica del database richiede la connettività di rete per consentire alla replica di connettersi al database principale per avviare la replica. Per esporre l'endpoint del database principale per la replica, utilizziamo Cloud Service Mesh per creare un mesh di servizi Ingress che supporti la terminazione TLS nel mesh di servizi, in modo simile a come gestiamo il trasferimento dei dati HTTPS per l'applicazione web del sistema di ticketing.