Ce guide fournit le contexte conceptuel nécessaire pour déployer une charge de travail basée sur une machine virtuelle (VM) dans un cluster Google Distributed Cloud (GDC) isolé sur Bare Metal à l'aide d'un environnement d'exécution de VM. La charge de travail de ce guide est un exemple de plate-forme de système de billetterie disponible sur du matériel sur site.
Architecture
Hiérarchie des ressources
Dans GDC, vous déployez les composants qui constituent le système de billetterie dans une organisation locataire dédiée à l'équipe des opérations, identique à n'importe quelle organisation cliente. Une organisation est un ensemble de clusters, de ressources d'infrastructure et de charges de travail d'application qui sont administrés ensemble. Chaque organisation d'une instance GDC utilise un ensemble de serveurs dédiés, ce qui permet une forte isolation entre les locataires. Pour en savoir plus sur l'infrastructure, consultez Concevoir des limites d'accès.
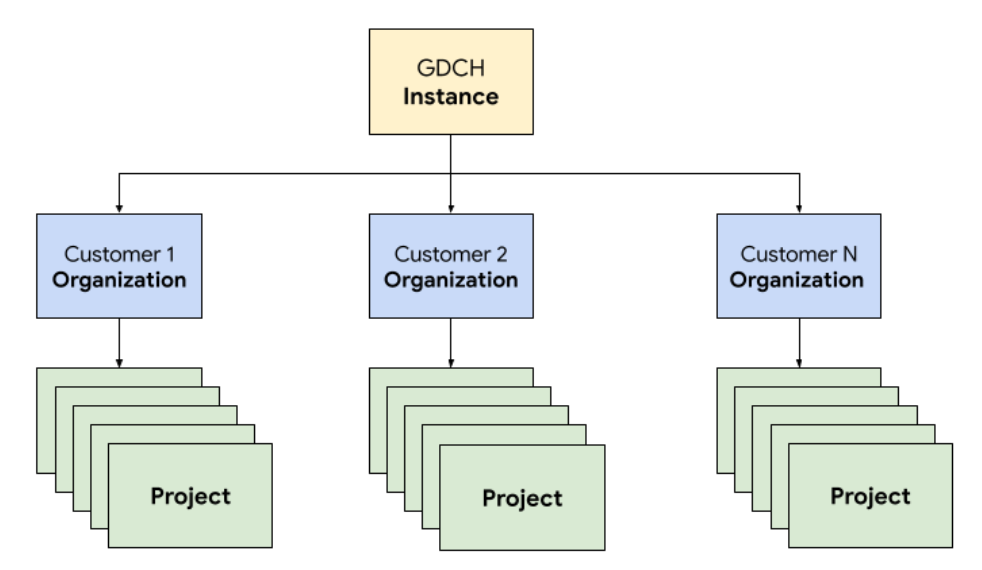
De plus, vous déployez et gérez les ressources du système de gestion des tickets ensemble dans un projet, ce qui permet une isolation logique au sein d'une organisation à l'aide de règles logicielles et de leur application. Les ressources d'un projet sont destinées à coupler les composants qui doivent rester ensemble pendant leur cycle de vie.
Le système de gestion des tickets suit une architecture à trois niveaux qui s'appuie sur un équilibreur de charge pour diriger le trafic vers les serveurs d'applications qui se connectent à un serveur de base de données stockant les données persistantes.
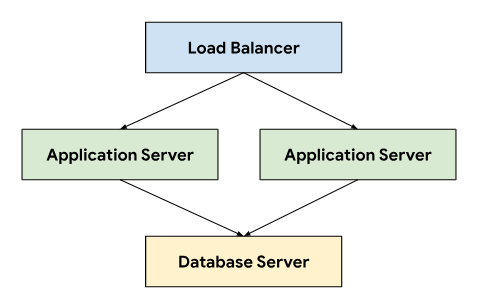
Cette architecture permet l'évolutivité et la facilité de maintenance, car chaque niveau peut être développé et géré de manière indépendante. Il permet également de séparer clairement les préoccupations, ce qui simplifie le débogage et le dépannage. En encapsulant ces niveaux dans un projet GDC, vous pouvez déployer et gérer les composants ensemble, par exemple vos serveurs d'application et de base de données.
Mise en réseau
Pour exécuter le système de gestion des tickets dans un environnement de production, vous devez déployer au moins deux serveurs d'application afin d'assurer une haute disponibilité en cas de défaillance d'un nœud. Combinée à un équilibreur de charge, cette topologie permet également de répartir la charge sur plusieurs machines pour mettre à l'échelle l'application de manière horizontale. La plate-forme Kubernetes native de GDC utilise Cloud Service Mesh pour acheminer le trafic de manière sécurisée vers les serveurs d'application qui composent le système de billetterie.
Cloud Service Mesh est une implémentation Google basée sur le projet Open Source qui gère, observe et sécurise les services. Les fonctionnalités suivantes de Cloud Service Mesh sont utilisées pour héberger le système de billetterie sur GDC :
- Équilibrage de charge : Cloud Service Mesh dissocie le flux de trafic du scaling de l'infrastructure, et offre de nombreuses fonctionnalités de gestion du trafic, y compris le routage dynamique des requêtes. Le système de tickets nécessite des connexions client persistantes. Nous activons donc les sessions persistantes à l'aide de
DestinationRulespour configurer le comportement de routage du trafic.
Arrêt TLS : Cloud Service Mesh expose les passerelles d'entrée à l'aide de certificats TLS et fournit une authentification du transport au sein du cluster via mTLS (Mutual Transport Layer Security) sans avoir à modifier le code de l'application.
Reprise après échec : Cloud Service Mesh offre un certain nombre de fonctionnalités majeures de reprise après échec, y compris des délais avant expiration, des disjoncteurs, des vérifications d'état actives et des tentatives limitées.
Dans le cluster Kubernetes, nous utilisons des objets Service standards comme moyen abstrait d'exposer les serveurs d'application et de base de données au réseau. Les services permettent de cibler facilement les instances à l'aide d'un sélecteur et de fournir une résolution de nom dans le cluster à l'aide d'un serveur DNS compatible avec le cluster.
apiVersion: v1
kind: Service
metadata:
name: http-ingress
spec:
selector:
app.kubernetes.io/component: application-server
ports:
- name: http
port: 80
---
apiVersion: v1
kind: Service
metadata:
name: database-ingress
spec:
selector:
app.kubernetes.io/component: database-server
ports:
- name: mysql
port: 3306
Calcul
Le système de gestion des tickets recommande d'utiliser des machines physiques ou virtuelles pour héberger les installations sur site. Nous avons utilisé la gestion des machines virtuelles (VM) GDC pour déployer les serveurs d'application et de base de données en tant que charges de travail de VM. La définition des ressources Kubernetes nous a permis de spécifier à la fois VirtualMachine et VirtualMachineDisk pour adapter les ressources à nos besoins pour les différents types de serveurs. VirtualMachineExternalAccess nous permet de configurer le transfert de données vers et depuis la VM.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineDisk
metadata:
name: vm1-boot-disk
spec:
size: 100G
source:
image:
name: ts-ticketing-system-app-server-2023-08-18-203258
namespace: vm-system
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachine
metadata:
labels:
app.kubernetes.io/component: application-server
name: vm1
namespace: support
spec:
compute:
vcpus: 8
memory: 12G
disks:
- boot: true
virtualMachineDiskRef:
name: vm1-boot-disk
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineExternalAccess
metadata:
name: vm1
namespace: support
spec:
enabled: true
ports:
- name: ssh
protocol: TCP
port: 22
Pour l'image de l'OS invité, nous avons créé une image personnalisée afin de répondre à nos exigences de conformité et de sécurité. Il est possible de se connecter à des instances de VM en cours d'exécution via SSH à l'aide de VirtualMachineAccessRequest, ce qui nous permet de limiter la possibilité de se connecter à des VM via Kubernetes RBAC et d'éviter d'avoir à créer des comptes utilisateur locaux dans les images personnalisées. La demande d'accès définit également une durée de vie (TTL, Time To Live) qui permet de gérer les VM dont l'accès expire automatiquement.
Automatisation
En tant que livrable clé de ce projet, nous avons conçu une approche permettant d'installer des instances du système de billetterie de manière répétable, ce qui peut prendre en charge une automatisation étendue et réduire la dérive de configuration entre les déploiements.
Pipeline de versions
La personnalisation des images de serveur d'application et de base de données commence par une image de système d'exploitation de base. Vous devez modifier cette image de base selon vos besoins pour installer les dépendances nécessaires à chaque image de serveur. Nous avons sélectionné une image d'OS de base pour son adoption généralisée dans l'hébergement de systèmes de gestion des tickets dans des installations sur site. Cette image d'OS de base fournit également les fonctionnalités de renforcement de la sécurité requises pour répondre aux guides d'implémentation technique de sécurité (STIG) nécessaires pour fournir une image conforme aux contrôles NIST-800-53.
Notre pipeline d'intégration continue (CI) utilisait le workflow suivant pour personnaliser les images de serveur d'application et de base de données :
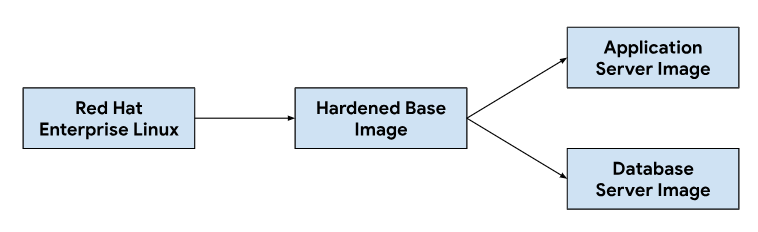
Lorsque les développeurs apportent des modifications aux scripts de personnalisation ou aux dépendances d'image, nous déclenchons un workflow automatisé dans notre outil CI pour générer un nouvel ensemble d'images qui sont regroupées avec les versions GDC. Lors de la création d'images, nous actualisons également les dépendances de l'OS (yum update) et nous rendons l'image clairsemée avec compression pour réduire la taille de l'image nécessaire au transfert d'images vers les environnements client.
Cycle de vie du développement logiciel
Le cycle de développement logiciel (SDLC, software development lifecycle) est un processus qui aide les organisations à planifier, créer, tester et déployer des logiciels. En suivant un cycle de vie du développement logiciel bien défini, les entreprises s'assurent que les logiciels sont développés de manière cohérente et reproductible, et identifient les problèmes potentiels dès le début. En plus de créer des images dans notre pipeline d'intégration continue (CI), nous avons également défini des environnements pour développer et mettre en scène des versions préliminaires du système de billetterie à des fins de test et d'assurance qualité.
Le déploiement d'une instance distincte du système de billetterie par projet GDC nous a permis de tester les modifications de manière isolée, sans affecter les instances existantes sur la même instance GDC. Nous avons utilisé l'API Resource Manager pour créer et supprimer des projets de manière déclarative à l'aide de ressources Kubernetes.
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-dev
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-qa
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-staging
Combinés au packaging de graphiques et à la gestion de l'infrastructure, comme les machines virtuelles en tant que code, les développeurs peuvent rapidement itérer, apporter des modifications et tester de nouvelles fonctionnalités en parallèle des instances de production. L'API déclarative permet également aux frameworks d'exécution de tests automatisés d'effectuer des tests de régression réguliers et de vérifier les fonctionnalités existantes.
Fonctionnement
L'opérabilité désigne la facilité avec laquelle un système peut être utilisé et entretenu. Il s'agit d'un aspect important à prendre en compte lors de la conception de toute application logicielle. Une surveillance efficace contribue à l'opérabilité, car elle permet d'identifier et de résoudre les problèmes avant qu'ils n'aient un impact significatif sur le système. La surveillance peut également être utilisée pour identifier les axes d'amélioration et établir une référence pour les objectifs de niveau de service (SLO).
Surveillance
Nous avons intégré le système de tickets à l'infrastructure d'observabilité GDC existante, y compris la journalisation et les métriques. Pour les métriques, nous exposons des points de terminaison HTTP à partir de chaque VM, ce qui permet à l'application d'extraire les points de données produits par les serveurs d'application et de base de données. Ces points de terminaison incluent les métriques système collectées à l'aide de l'exportateur de nœuds d'application et les métriques spécifiques aux applications.
Avec les points de terminaison exposés dans chaque VM, nous avons configuré le comportement d'interrogation de l'application à l'aide de la ressource personnalisée MonitoringTarget pour définir l'intervalle de scraping et annoter les métriques.
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringTarget
metadata:
name: database-monitor
spec:
podMetricsEndpoints:
path:
value: /metrics
port:
annotation: application.io/dbMetrics
scrapeInterval: 60s
Pour la journalisation, nous avons installé et configuré un processeur de journaux et de métriques dans chaque VM afin de suivre les journaux pertinents et d'envoyer les données de journaux à l'outil de journalisation, où les données sont indexées et interrogées via l'instance de surveillance. Les journaux d'audit sont transférés vers un point de terminaison spécial configuré avec une durée de conservation étendue pour la conformité. Les applications basées sur des conteneurs peuvent utiliser la ressource personnalisée LoggingTarget et AuditLoggingTarget pour indiquer au pipeline de journalisation de collecter les journaux de services spécifiques dans votre projet.
Sur la base des données disponibles dans les processeurs de journalisation et de surveillance, nous avons créé des alertes à l'aide de la ressource personnalisée MonitoringRule, qui nous permet de gérer cette configuration en tant que code dans notre packaging de graphique. L'utilisation d'une API déclarative pour définir des alertes et des tableaux de bord nous permet également de stocker cette configuration dans notre dépôt de code et de suivre les mêmes processus d'examen du code et d'intégration continue que ceux sur lesquels nous nous appuyons pour toute autre modification du code.
Modes de défaillance
Les premiers tests ont révélé plusieurs modes de défaillance liés aux ressources, ce qui nous a aidés à déterminer les métriques et les alertes à ajouter en premier. Nous avons commencé par surveiller l'utilisation élevée de la mémoire et du disque, car une mauvaise configuration de la base de données avait initialement entraîné la consommation de toute la mémoire disponible par les tables de tampon et le remplissage du disque du volume persistant associé par une journalisation excessive. Après avoir ajusté la taille du tampon de stockage et mis en œuvre une stratégie de rotation des journaux, nous avons introduit des alertes qui s'exécutent si les VM approchent d'une utilisation élevée de la mémoire ou du disque.
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringRule
metadata:
name: monitoring-rule
spec:
interval: 60s
limit: 0
alertRules:
- alert: vm1_disk_usage
expr:
(node_filesystem_size_bytes{container_name="compute"} -
node_filesystem_avail_bytes{container_name="compute"}) * 100 /
node_filesystem_size_bytes{container_name="compute"} > 90
labels:
severity: error
code: <a href="/distributed-cloud/hosted/docs/latest/gdch/gdch-io/service-manual/ts/runbooks/ts-r0001">TS-R0001</a>
resource: vm1
annotations:
message: "vm1 disk usage above 90% utilization"
Après avoir vérifié la stabilité du système, nous nous sommes concentrés sur les modes de défaillance des applications dans le système de billetterie. Étant donné que le débogage des problèmes dans l'application nous obligeait souvent à utiliser Secure Shell (SSH) dans chaque VM de serveur d'application pour vérifier les journaux du système de gestion des tickets, nous avons configuré une application pour transférer ces journaux vers l'outil de journalisation afin de nous appuyer sur la pile d'observabilité GDC et d'interroger tous les journaux opérationnels du système de gestion des tickets dans l'instance de surveillance.
La journalisation centralisée nous a également permis d'interroger les journaux de plusieurs VM en même temps, ce qui a consolidé notre vue de chaque composant du système.
Sauvegardes
Les sauvegardes sont importantes pour le fonctionnement d'un système logiciel, car elles permettent de restaurer le système en cas de défaillance.
GDC propose la sauvegarde et la restauration de VM via des ressources Kubernetes. La création d'une ressource personnalisée VirtualMachineBackupRequest avec une ressource personnalisée VirtualMachineBackupPlanTemplate nous permet de sauvegarder le volume persistant associé à chaque VM dans un stockage d'objets, où les sauvegardes peuvent être conservées conformément à une règle de conservation définie.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupPlanTemplate
metadata:
name: vm-backup-plan
spec:
backupRepository: "backup-repository"
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupRequest
metadata:
name: "db-vm-backup"
spec:
virtualMachineBackupPlanTemplate: vm-backup-plan
virtualMachine: db1
virtualMachineBackupName: db-vm-backup
De même, la restauration de l'état d'une VM à partir d'une sauvegarde implique la création d'une ressource personnalisée VirtualMachineRestoreRequest pour restaurer les serveurs d'application et de base de données sans modifier le code ni la configuration de l'un ou l'autre service.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineRestoreRequest
metadata:
name: vm-restore-1
spec:
virtualMachineBackup: db-vm-backup
restoreName: restore1
restoredResourceName: db1
Mises à niveau
Pour prendre en charge le cycle de vie logiciel du système de billetterie et de ses dépendances, nous avons identifié trois types de mises à niveau logicielles, chacune étant traitée individuellement pour minimiser les temps d'arrêt et les interruptions de service :
- Mises à niveau de l'OS.
- Mises à niveau de la plate-forme, telles que les versions correctives et majeures.
- Mises à jour de la configuration.
Pour les mises à niveau de l'OS, nous créons et publions en continu de nouvelles images de VM pour les serveurs d'application et de base de données, qui sont distribuées avec chaque version de GDC. Ces images contiennent des correctifs pour les failles de sécurité et des mises à jour du système d'exploitation sous-jacent.
Les mises à niveau de la plate-forme du système de gestion des tickets nécessitent l'application de mises à jour aux images de VM existantes. Nous ne pouvons donc pas nous appuyer sur une infrastructure immuable pour effectuer des mises à jour de correctifs et de versions majeures. Pour les mises à niveau de la plate-forme, nous testons et vérifions la version du correctif ou de la version majeure dans nos environnements de développement et de préproduction avant de publier un package de mise à niveau autonome avec la version GDC.
Enfin, les mises à jour de configuration sont appliquées sans temps d'arrêt grâce aux API du système de gestion des tickets pour les ensembles de mises à jour et autres données utilisateur. Nous développons et testons les mises à jour de configuration dans nos environnements de développement et de préproduction avant de regrouper plusieurs ensembles de mises à jour lors du processus de publication GDC.
Intégrations
Fournisseurs d'identité
Pour offrir aux clients un parcours fluide et permettre aux organisations d'intégrer leurs utilisateurs, nous intégrons le système de gestion des demandes à plusieurs fournisseurs d'identité disponibles dans GDC. En général, les clients Enterprise et du secteur public disposent de leurs propres fournisseurs d'identité bien gérés pour accorder et révoquer les droits d'accès de leurs employés. En raison des exigences de conformité et de la facilité de gestion des identités et des accès, ces clients souhaitent utiliser leurs fournisseurs d'identité existants comme source de vérité pour gérer l'accès de leurs employés au système de tickets.
Le système de gestion des tickets est compatible avec les fournisseurs SAML 2.0 et OIDC grâce à son module multifournisseur d'identité, que nous avons préactivé dans notre image de VM de serveur d'application. Les clients s'authentifient via le fournisseur d'identité de leur organisation, ce qui crée automatiquement des utilisateurs et attribue des rôles dans le système de gestion des demandes.
La sortie vers les serveurs du fournisseur d'identité est autorisée via la ressource personnalisée ProjectNetworkPolicy, qui limite l'accessibilité des services externes depuis une organisation dans GDC. Ces règles nous permettent de contrôler de manière déclarative les points de terminaison auxquels le système de billetterie peut accéder sur le réseau.
Ingestion des alertes
En plus de permettre aux utilisateurs de se connecter pour créer manuellement des demandes d'assistance, nous créons également des incidents dans le système de gestion des demandes en réponse aux alertes système.
Pour réaliser cette intégration, nous avons personnalisé un webhook Kubernetes Open Source afin de recevoir les alertes de l'application et de gérer le cycle de vie des incidents à l'aide du point de terminaison de l'API du système de gestion des tickets exposé via Cloud Service Mesh.
Les clés API sont stockées à l'aide du secret store GDC, qui s'appuie sur des secrets Kubernetes contrôlés par le contrôle des accès basé sur les rôles (RBAC). D'autres configurations, telles que les points de terminaison d'API et les champs de personnalisation des incidents, sont gérées via le stockage de paires clé-valeur Kubernetes ConfigMap.
Le système de tickets propose des intégrations de serveur de messagerie pour permettre aux clients de recevoir une assistance par e-mail. Les workflows automatisés convertissent les e-mails entrants des clients en demandes d'assistance et envoient des réponses automatiques aux clients avec des liens vers les demandes. Notre équipe d'assistance peut ainsi mieux gérer sa boîte de réception, suivre et résoudre systématiquement les demandes par e-mail, et fournir un meilleur service client.
apiVersion: networking.gdc.goog/v1
kind: ProjectNetworkPolicy
metadata:
name: allow-ingress-traffic-from-ticketing-system
spec:
subject:
subjectType: UserWorkload
ingress:
- from:
- projects:
matchNames:
- ticketing-system
L'exposition de l'e-mail en tant que service Kubernetes fournit également la détection de services et la résolution de noms de domaine, et découple davantage le backend du serveur de messagerie des clients tels que le système de billetterie.
Conformité
Audit Logging
Les journaux d'audit contribuent à la conformité en permettant de suivre et de surveiller l'utilisation des logiciels, et en fournissant un enregistrement de l'activité du système. Les journaux d'audit enregistrent les tentatives d'accès des utilisateurs non autorisés, suivent l'utilisation des API et identifient les risques de sécurité potentiels. Les journaux d'audit répondent aux exigences de conformité, telles que celles imposées par la loi HIPAA (Health Insurance Portability and Accountability Act), la norme PCI DSS (Payment Card Industry Data Security Standard) et la loi SOX (Sarbanes-Oxley Act).
GDC fournit un système permettant d'enregistrer les activités d'administration et les accès au sein de la plate-forme, et de conserver ces journaux pendant une période configurable. Le déploiement de la ressource personnalisée AuditLoggingTarget configure le pipeline de journalisation pour collecter les journaux d'audit de notre application.
Pour le système de gestion des tickets, nous avons configuré des cibles de journalisation d'audit pour les événements d'audit système collectés et les événements spécifiques à l'application générés par le journal d'audit de sécurité du système de gestion des tickets. Les deux types de journaux sont envoyés à une instance Loki centralisée où nous pouvons écrire des requêtes et afficher des tableaux de bord dans l'instance de surveillance.
Contrôle des accès
Le contrôle des accès est le processus qui consiste à accorder ou refuser l'accès à des ressources en fonction de l'identité de l'utilisateur ou du processus qui demande l'accès. Cela permet de protéger les données contre les accès non autorisés et de s'assurer que seuls les utilisateurs autorisés peuvent apporter des modifications au système. Dans GDC, nous nous appuyons sur le RBAC Kubernetes pour déclarer des règles et appliquer l'autorisation aux ressources système qui composent l'application du système de billetterie.
Définir un ProjectRole dans GDC nous permet d'accorder un accès précis aux ressources Kubernetes à l'aide d'un rôle d'autorisation prédéfini.
apiVersion: resourcemanager.gdc.goog/v1
kind: ProjectRole
metadata:
name: ticketing-system-admin
labels:
resourcemanager.gdc.goog/rbac-selector: system
spec:
rules:
- apiGroups:
- ""
resources:
- configmaps
- events
- pods/log
- services
verbs:
- get
- list
Reprise après sinistre
Réplication de base de données
Pour répondre aux exigences de reprise après sinistre, nous déployons le système de billetterie dans une configuration primaire-secondaire sur plusieurs instances GDC. Dans ce mode, les requêtes adressées au système de billetterie sont normalement acheminées vers le site principal, tandis que le site secondaire réplique en continu le journal binaire de la base de données. En cas de basculement, le site secondaire est promu au rang de nouveau site principal, et les requêtes sont alors acheminées vers le nouveau site principal.
Nous nous appuyons sur les capacités de réplication de la base de données pour configurer les serveurs de base de données principal et répliqué par instance GDC en fonction des paramètres définis.
Pour activer la réplication pour une instance existante qui s'exécute depuis plus longtemps que la période de conservation du journal binaire, nous pouvons restaurer la base de données répliquée à l'aide de la sauvegarde de la base de données pour commencer la réplication à partir de la base de données principale.
En mode principal, les serveurs d'applications et la base de données fonctionnent comme aujourd'hui, mais la base de données principale est configurée pour permettre la réplication. Exemple :
Activez le journal binaire.
Définissez l'ID du serveur.
Créez un compte utilisateur de réplication.
Créer une sauvegarde
En mode réplique, les serveurs d'applications désactivent le service Web de gestion des tickets pour éviter de se connecter directement à la base de données de réplique. La base de données répliquée doit être configurée pour démarrer la réplication à partir de la base de données principale. Par exemple :
Définissez l'ID du serveur.
Configurez les identifiants de l'utilisateur de la réplication et les détails de la connexion principale, tels que l'hôte et le port.
Restaurez à partir de la position du journal binaire de reprise de la sauvegarde.
La réplication de base de données nécessite une connectivité réseau pour que la base de données répliquée se connecte à la base de données principale et lance la réplication. Pour exposer le point de terminaison de la base de données principale pour la réplication, nous utilisons Cloud Service Mesh pour créer un maillage de services Ingress qui prend en charge l'arrêt TLS au niveau du maillage de services, de la même manière que nous gérons le transfert de données HTTPS pour l'application Web du système de billetterie.