En esta guía, se abarca el contexto conceptual necesario para implementar una carga de trabajo basada en máquina virtual (VMs) en un clúster aislado de Google Distributed Cloud (GDC) en hardware bare metal con un entorno de ejecución de VM. La carga de trabajo de esta guía es una plataforma de sistema de tickets de muestra que está disponible en hardware local.
Arquitectura
Jerarquía de recursos
En GDC, implementas los componentes que conforman el sistema de tickets en una organización de inquilino dedicada para el equipo de Operaciones, idéntica a cualquier organización de clientes. Una organización es una colección de clústeres, recursos de infraestructura y cargas de trabajo de aplicaciones que se administran en conjunto. Cada organización en una instancia de GDC usa un conjunto dedicado de servidores, lo que proporciona un aislamiento sólido entre los arrendatarios. Para obtener más información sobre la infraestructura, consulta Cómo diseñar límites de acceso.
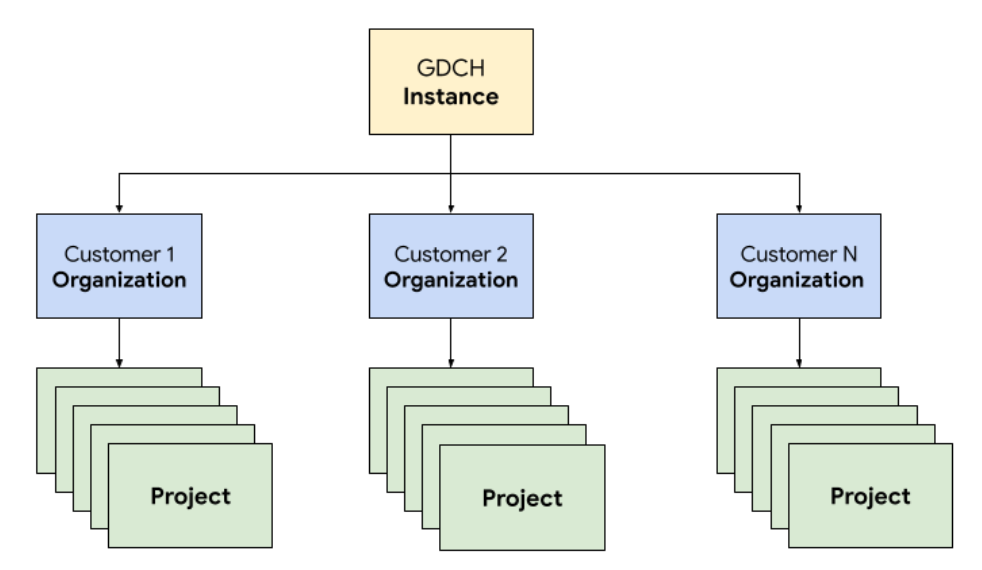
Además, implementas y administras los recursos del sistema de tickets en conjunto en un proyecto, lo que proporciona aislamiento lógico dentro de una organización con políticas de software y aplicación. Los recursos de un proyecto están diseñados para unir componentes que deben permanecer juntos durante su ciclo de vida.
El sistema de tickets sigue una arquitectura de tres niveles que se basa en un balanceador de cargas para dirigir el tráfico a través de servidores de aplicaciones que se conectan a un servidor de bases de datos que almacena datos persistentes.
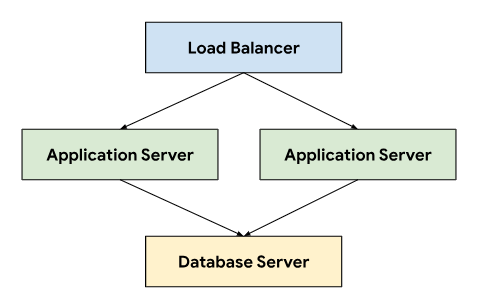
Esta arquitectura permite la escalabilidad y el mantenimiento, ya que cada nivel se puede desarrollar y mantener de forma independiente. También proporciona una separación clara de los problemas, lo que simplifica la depuración y la solución de problemas. Encapsular estos niveles dentro de un proyecto de GDC te permite implementar y administrar componentes juntos, por ejemplo, los servidores de aplicaciones y bases de datos.
Redes
Para ejecutar el sistema de tickets en un entorno de producción, se deben implementar dos o más servidores de aplicaciones para lograr una alta disponibilidad en caso de falla de nodos. En combinación con un balanceador de cargas, esta topología también permite distribuir la carga entre varias máquinas para escalar la aplicación de forma horizontal. La plataforma nativa de Kubernetes de GDC utiliza Cloud Service Mesh para enrutar de forma segura el tráfico a los servidores de aplicaciones que componen el sistema de venta de entradas.
Cloud Service Mesh es una implementación de Google basada en el proyecto de código abierto que administra, observa y protege los servicios. Las siguientes funciones de Cloud Service Mesh se aprovechan para alojar el sistema de venta de entradas en la GDC:
- Balanceo de cargas: Cloud Service Mesh desacopla el flujo de tráfico del escalamiento de la infraestructura, lo que proporciona muchas funciones de administración del tráfico, como el enrutamiento de solicitudes dinámicas. El sistema de tickets requiere conexiones persistentes del cliente, por lo que habilitamos las sesiones permanentes con
DestinationRulespara configurar el comportamiento del enrutamiento del tráfico.
Finalización de TLS: Cloud Service Mesh expone las puertas de enlace de entrada con certificados TLS y proporciona autenticación de transporte dentro del clúster a través de mTLS (seguridad mutua de la capa de transporte) sin tener que cambiar ningún código de la aplicación.
Recuperación ante fallas: Cloud Service Mesh proporciona diversas funciones fundamentales de recuperación ante fallas, como tiempos de espera, disyuntores, verificaciones de estado activas y límites de reintentos.
Dentro del clúster de Kubernetes, usamos objetos Service estándar como una forma abstracta de exponer los servidores de aplicaciones y bases de datos a la red. Los servicios proporcionan una forma conveniente de segmentar instancias con un selector y proporcionar resolución de nombres dentro del clúster con un servidor DNS compatible con el clúster.
apiVersion: v1
kind: Service
metadata:
name: http-ingress
spec:
selector:
app.kubernetes.io/component: application-server
ports:
- name: http
port: 80
---
apiVersion: v1
kind: Service
metadata:
name: database-ingress
spec:
selector:
app.kubernetes.io/component: database-server
ports:
- name: mysql
port: 3306
Procesamiento
El sistema de tickets recomienda usar máquinas virtuales o bare metal para alojar instalaciones locales, y utilizamos la administración de máquina virtual (VM) de GDC para implementar los servidores de aplicaciones y bases de datos como cargas de trabajo de VM. La definición de recursos de Kubernetes nos permitió especificar VirtualMachine y VirtualMachineDisk para adaptar los recursos a nuestras necesidades para los diferentes tipos de servidores. VirtualMachineExternalAccess nos permite configurar la transferencia de datos entrantes y salientes para la VM.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineDisk
metadata:
name: vm1-boot-disk
spec:
size: 100G
source:
image:
name: ts-ticketing-system-app-server-2023-08-18-203258
namespace: vm-system
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachine
metadata:
labels:
app.kubernetes.io/component: application-server
name: vm1
namespace: support
spec:
compute:
vcpus: 8
memory: 12G
disks:
- boot: true
virtualMachineDiskRef:
name: vm1-boot-disk
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineExternalAccess
metadata:
name: vm1
namespace: support
spec:
enabled: true
ports:
- name: ssh
protocol: TCP
port: 22
Para la imagen de SO invitado, creamos una imagen personalizada que cumpliera con nuestros requisitos de cumplimiento y seguridad. Es posible conectarse a instancias de VM en ejecución a través de SSH con VirtualMachineAccessRequest, lo que nos permite limitar la capacidad de conectarse a las VMs a través del RBAC de Kubernetes y evitar la necesidad de crear cuentas de usuario locales en las imágenes personalizadas. La solicitud de acceso también define un tiempo de actividad (TTL) que permite que las solicitudes de acceso basadas en el tiempo administren las VMs que vencen automáticamente.
Automatización
Como resultado clave de este proyecto, diseñamos un enfoque para instalar instancias del sistema de tickets de forma repetible que pueda admitir una automatización extensa y reducir la desviación de la configuración entre las implementaciones.
Canalización de versión
La personalización de las imágenes del servidor de aplicaciones y de la base de datos comienza con una imagen base del sistema operativo, que se modifica según sea necesario para instalar las dependencias necesarias para cada imagen del servidor. Seleccionamos una imagen de SO base por su adopción generalizada en los sistemas de tickets de alojamiento en instalaciones locales. Esta imagen base del SO también proporciona capacidades de refuerzo de la seguridad necesarias para cumplir con las Guías de implementación técnica de seguridad (STIG) que se necesitan para entregar una imagen compatible que cumpla con los controles de NIST-800-53.
Nuestra canalización de integración continua (CI) usaba el siguiente flujo de trabajo para personalizar las imágenes de los servidores de aplicaciones y bases de datos:
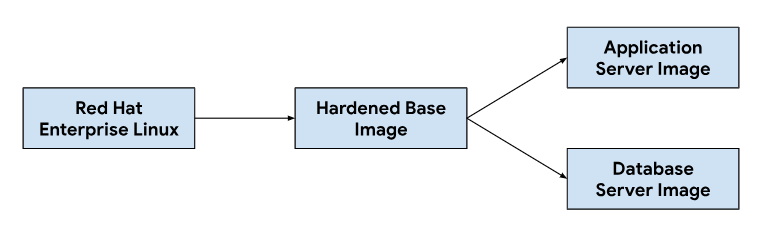
Cuando los desarrolladores realizan cambios en las secuencias de comandos de personalización o en las dependencias de imágenes, activamos un flujo de trabajo automatizado en nuestras herramientas de CI para generar un nuevo conjunto de imágenes que se incluyen en las versiones de GDC. Como parte de la compilación de imágenes, también actualizamos las dependencias del SO (yum update) y reducimos la densidad de la imagen con compresión para disminuir el tamaño de la imagen necesario para transferir imágenes a los entornos de los clientes.
Ciclo de vida del desarrollo de software
El ciclo de vida del desarrollo de software (SDLC) es un proceso que ayuda a las organizaciones a planificar, crear, probar e implementar software. Si siguen un SDLC bien definido, las organizaciones se aseguran de que el software se desarrolle de manera coherente y repetible, y de identificar posibles problemas desde el principio. Además de compilar imágenes en nuestra canalización de integración continua (CI), también definimos entornos para desarrollar y organizar versiones previas al lanzamiento del sistema de tickets para pruebas y control de calidad.
Implementar una instancia separada del sistema de tickets por proyecto de GDC nos permitió probar los cambios de forma aislada, sin afectar las instancias existentes en la misma instancia de GDC. Usamos la API de Resource Manager para crear y desmantelar proyectos de forma declarativa con recursos de Kubernetes.
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-dev
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-qa
---
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
name: ticketing-system-staging
En combinación con el empaquetado de gráficos y la administración de infraestructura, como máquinas virtuales como código, los desarrolladores pueden iterar rápidamente, realizar cambios y probar nuevas funciones junto con las instancias de producción. La API declarativa también permite que los frameworks de ejecución de pruebas automatizadas realicen pruebas de regresión periódicas y verifiquen las capacidades existentes.
Operatividad
La operabilidad es la facilidad con la que se puede operar y mantener un sistema. Es una consideración importante en el diseño de cualquier aplicación de software. La supervisión eficaz contribuye a la operabilidad porque permite identificar y abordar los problemas antes de que tengan un impacto significativo en el sistema. La supervisión también se puede usar para identificar oportunidades de mejora y establecer un valor de referencia para los objetivos de nivel de servicio (SLO).
Supervisión
Integramos el sistema de tickets con la infraestructura de observabilidad existente de GDC, incluidos los registros y las métricas. En el caso de las métricas, exponemos extremos HTTP desde cada VM que permiten que la aplicación extraiga puntos de datos producidos por los servidores de aplicaciones y bases de datos. Estos extremos incluyen métricas del sistema recopiladas con el exportador de nodos de la aplicación y métricas específicas de la aplicación.
Con los extremos expuestos en cada VM, configuramos el comportamiento de sondeo de la aplicación con el recurso personalizado MonitoringTarget para definir el intervalo de recopilación y anotar las métricas.
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringTarget
metadata:
name: database-monitor
spec:
podMetricsEndpoints:
path:
value: /metrics
port:
annotation: application.io/dbMetrics
scrapeInterval: 60s
Para el registro, instalamos y configuramos un procesador de registros y métricas en cada VM para seguir los registros pertinentes y enviar los datos de registro a la herramienta de registro, en la que los datos se indexan y se consultan a través de la instancia de supervisión. Los registros de auditoría se reenvían a un extremo especial configurado con una retención extendida para el cumplimiento. Las aplicaciones basadas en contenedores pueden usar el recurso personalizado LoggingTarget y AuditLoggingTarget para indicarle a la canalización de registros que recopile registros de servicios específicos en tu proyecto.
Según los datos disponibles en los procesadores de registro y supervisión, creamos alertas con el recurso personalizado MonitoringRule, que nos permite administrar esta configuración como código en el empaquetado de gráficos. Usar una API declarativa para definir alertas y paneles también nos permite almacenar esta configuración en nuestro repositorio de código y seguir los mismos procesos de revisión de código y de integración continua en los que confiamos para cualquier otro cambio de código.
Modos de falla
Las pruebas iniciales revelaron varios modos de falla relacionados con los recursos que nos ayudaron a priorizar qué métricas y alertas agregar primero. Comenzamos con la supervisión del uso elevado de memoria y disco, ya que la configuración incorrecta de la base de datos inicialmente provocó que las tablas de búfer consumieran toda la memoria disponible y el registro excesivo llenó el disco del volumen persistente adjunto. Después de ajustar el tamaño del búfer de almacenamiento y de implementar una estrategia de rotación del registro, introdujimos alertas que se ejecutan si las VMs se acercan a un uso alto de memoria o disco.
apiVersion: monitoring.gdc.goog/v1
kind: MonitoringRule
metadata:
name: monitoring-rule
spec:
interval: 60s
limit: 0
alertRules:
- alert: vm1_disk_usage
expr:
(node_filesystem_size_bytes{container_name="compute"} -
node_filesystem_avail_bytes{container_name="compute"}) * 100 /
node_filesystem_size_bytes{container_name="compute"} > 90
labels:
severity: error
code: <a href="/distributed-cloud/hosted/docs/latest/gdch/gdch-io/service-manual/ts/runbooks/ts-r0001">TS-R0001</a>
resource: vm1
annotations:
message: "vm1 disk usage above 90% utilization"
Después de verificar la estabilidad del sistema, cambiamos nuestro enfoque a los modos de falla de la aplicación dentro del sistema de tickets. Dado que, a menudo, la depuración de problemas dentro de la aplicación requería que usáramos Secure Shell (SSH) en cada VM del servidor de aplicaciones para verificar los registros del sistema de tickets, configuramos una aplicación para reenviar estos registros a la herramienta de registro y, así, aprovechar la pila de observabilidad de GDC y consultar todos los registros operativos del sistema de tickets en la instancia de supervisión.
El registro centralizado también nos permitió consultar los registros de varias VMs al mismo tiempo, lo que consolidó nuestra vista de cada componente del sistema.
Copias de seguridad
Las copias de seguridad son importantes para la operatividad de un sistema de software porque permiten restablecer el sistema en caso de falla.
GDC ofrece copias de seguridad y restablecimiento de VM a través de recursos de Kubernetes. La creación de un recurso personalizado VirtualMachineBackupRequest con un recurso personalizado VirtualMachineBackupPlanTemplate nos permite crear copias de seguridad del volumen persistente conectado a cada VM en el almacenamiento de objetos, donde las copias de seguridad se pueden conservar según una política de retención establecida.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupPlanTemplate
metadata:
name: vm-backup-plan
spec:
backupRepository: "backup-repository"
---
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineBackupRequest
metadata:
name: "db-vm-backup"
spec:
virtualMachineBackupPlanTemplate: vm-backup-plan
virtualMachine: db1
virtualMachineBackupName: db-vm-backup
Del mismo modo, restablecer el estado de una VM desde una copia de seguridad implica crear un recurso personalizado VirtualMachineRestoreRequest para restablecer los servidores de aplicaciones y bases de datos sin modificar el código ni la configuración de ninguno de los servicios.
apiVersion: virtualmachine.gdc.goog/v1
kind: VirtualMachineRestoreRequest
metadata:
name: vm-restore-1
spec:
virtualMachineBackup: db-vm-backup
restoreName: restore1
restoredResourceName: db1
Actualizaciones
Para admitir el ciclo de vida del software del sistema de tickets y sus dependencias, identificamos tres tipos de actualizaciones de software, cada una de las cuales se maneja de forma individual para minimizar el tiempo de inactividad y la interrupción del servicio:
- Actualizaciones del SO
- Actualizaciones de la plataforma, como parches y versiones principales
- Se actualizaron los parámetros de configuración.
Para las actualizaciones del SO, compilamos y lanzamos continuamente nuevas imágenes de VM para los servidores de aplicaciones y de bases de datos que se distribuyen con cada lanzamiento de GDC. Estas imágenes contienen correcciones para las vulnerabilidades de seguridad y actualizaciones del sistema operativo subyacente.
Las actualizaciones de la plataforma del sistema de tickets requieren que se apliquen actualizaciones a las imágenes de VM existentes, por lo que no podemos depender de una infraestructura inmutable para realizar la aplicación de parches y las actualizaciones de versiones principales. En el caso de las actualizaciones de la plataforma, probamos y verificamos la versión del parche o de la versión principal en nuestros entornos de desarrollo y de etapa de pruebas antes de lanzar un paquete de actualización independiente junto con la versión de GDC.
Por último, las actualizaciones de configuración se aplican sin tiempo de inactividad a través de las APIs del sistema de tickets para los conjuntos de actualización y otros datos del usuario. Desarrollamos y probamos las actualizaciones de configuración en nuestros entornos de desarrollo y de etapa de pruebas antes de empaquetar varios conjuntos de actualizaciones durante el proceso de lanzamiento de GDC.
Integraciones
Proveedores de identidad
Para brindar a los clientes un recorrido sin interrupciones y permitir que las organizaciones incorporen a sus usuarios, integramos el sistema de tickets con varios proveedores de identidad disponibles en GDC. Por lo general, los clientes empresariales y del sector público tienen sus propios proveedores de identidad bien administrados para otorgar y revocar derechos a sus empleados. Debido a los requisitos de cumplimiento y la facilidad de la administración de identidades y accesos, estos clientes desean usar sus proveedores de identidad existentes como fuente de información para administrar el acceso de sus empleados al sistema de tickets.
El sistema de tickets admite proveedores de SAML 2.0 y OIDC a través de su módulo de varios proveedores de identidad, que habilitamos previamente en la imagen de VM del servidor de aplicaciones. Los clientes se autentican a través del proveedor de identidad de su organización, que crea usuarios y asigna roles automáticamente dentro del sistema de tickets.
El tráfico de salida a los servidores del proveedor de identidad se permite a través del recurso personalizado ProjectNetworkPolicy, que limita si se puede acceder a los servicios externos desde una organización en GDC. Estas políticas nos permiten controlar de forma declarativa a qué extremos puede acceder el sistema de tickets en la red.
Ingesta de alertas
Además de permitir que los usuarios accedan para crear casos de asistencia de forma manual, también creamos incidentes del sistema de tickets en respuesta a las alertas del sistema.
Para lograr esta integración, personalizamos un webhook de Kubernetes de código abierto para recibir alertas de la aplicación y administrar el ciclo de vida de los incidentes con el extremo de API del sistema de tickets expuesto a través de Cloud Service Mesh.
Las claves de API se almacenan con el almacén de secretos de GDC, respaldado por secretos de Kubernetes controlados a través del control de acceso basado en roles (RBAC). Otras configuraciones, como los extremos de API y los campos de personalización de incidentes, se administran a través del almacenamiento de clave-valor de ConfigMap de Kubernetes.
Correo electrónico
El sistema de tickets ofrece integraciones de servidores de correo electrónico para permitir que los clientes reciban asistencia por correo electrónico. Los flujos de trabajo automatizados convierten los correos electrónicos entrantes de los clientes en casos de asistencia y envían respuestas automáticas a los clientes con vínculos a los casos, lo que permite que nuestro equipo de asistencia administre mejor su bandeja de entrada, realice un seguimiento sistemático de las solicitudes por correo electrónico y las resuelva, y brinde un mejor servicio de atención al cliente.
apiVersion: networking.gdc.goog/v1
kind: ProjectNetworkPolicy
metadata:
name: allow-ingress-traffic-from-ticketing-system
spec:
subject:
subjectType: UserWorkload
ingress:
- from:
- projects:
matchNames:
- ticketing-system
Exponer el correo electrónico como un servicio de Kubernetes también proporciona detección de servicios y resolución de nombres de dominio, y desacopla aún más el backend del servidor de correo electrónico de los clientes, como el sistema de tickets.
Cumplimiento
Registros de auditorías
Los registros de auditoría contribuyen a la postura de cumplimiento, ya que proporcionan una forma de hacer un seguimiento y supervisar el uso del software, y proporcionan un registro de la actividad del sistema. Los registros de auditoría registran los intentos de acceso de usuarios no autorizados, hacen un seguimiento del uso de la API y permiten identificar posibles riesgos de seguridad. Los registros de auditoría cumplen con los requisitos de cumplimiento, como los impuestos por la Ley de Responsabilidad y Portabilidad de Seguros Médicos (HIPAA), el Estándar de Seguridad de Datos de la Industria de Tarjetas de Pago (PCI DSS) y la Ley Sarbanes-Oxley (SOX).
GDC proporciona un sistema para registrar las actividades y los accesos administrativos dentro de la plataforma, y conservar estos registros durante un período configurable. Implementar el recurso personalizado AuditLoggingTarget configura la canalización de registros para recopilar registros de auditoría de nuestra aplicación.
En el caso del sistema de tickets, configuramos destinos de registros de auditoría para los eventos de auditoría del sistema recopilados y los eventos específicos de la aplicación que genera el registro de auditoría de seguridad del sistema de tickets. Ambos tipos de registros se envían a una instancia centralizada de Loki en la que podemos escribir consultas y ver paneles en la instancia de supervisión.
Control de acceso
El control de acceso es el proceso de otorgar o denegar el acceso a los recursos según la identidad del usuario o el proceso que solicita el acceso. Esto ayuda a proteger los datos del acceso no autorizado y garantiza que solo los usuarios autorizados puedan realizar cambios en el sistema. En GDC, usamos el RBAC de Kubernetes para declarar políticas y aplicar la autorización a los recursos del sistema que componen la aplicación del sistema de tickets.
Definir un ProjectRole en GDC nos permite otorgar acceso detallado a los recursos de Kubernetes con un rol de autorización preestablecido.
apiVersion: resourcemanager.gdc.goog/v1
kind: ProjectRole
metadata:
name: ticketing-system-admin
labels:
resourcemanager.gdc.goog/rbac-selector: system
spec:
rules:
- apiGroups:
- ""
resources:
- configmaps
- events
- pods/log
- services
verbs:
- get
- list
Recuperación ante desastres
Replicación de bases de datos
Para cumplir con los requisitos de recuperación ante desastres (DR), implementamos el sistema de tickets en una configuración principal-secundaria en varias instancias de GDC. En este modo, las solicitudes al sistema de tickets se enrutan normalmente al sitio principal, mientras que el sitio secundario replica de forma continua el registro binario de la base de datos. En caso de un evento de conmutación por error, el sitio secundario se promueve para convertirse en el nuevo sitio principal y, luego, las solicitudes se enrutan al nuevo sitio principal.
Aprovechamos las capacidades de replicación de la base de datos para configurar los servidores de bases de datos principal y de réplica por instancia de GDC según los parámetros establecidos.
Para habilitar la replicación en una instancia existente que se ha ejecutado durante más tiempo que el período de retención del registro binario, podemos restablecer la base de datos de réplica con una copia de seguridad de la base de datos para comenzar la replicación desde la base de datos principal.
En el modo principal, los servidores de aplicaciones y la base de datos funcionan igual que en la actualidad, pero la base de datos principal está configurada para habilitar la replicación. Por ejemplo:
Habilita el registro binario.
Establece el ID del servidor.
Crea una cuenta de usuario de replicación.
Crear una copia de seguridad
En el modo de réplica, los servidores de aplicaciones inhabilitarán el servicio web de emisión de tickets para evitar la conexión directa a la base de datos de réplica. La base de datos de réplica debe configurarse para iniciar la replicación desde la base de datos principal, por ejemplo:
Establece el ID del servidor.
Configura las credenciales del usuario de replicación y los detalles de la conexión principal, como el host y el puerto.
Posición del registro binario de reanudación de la restauración desde la copia de seguridad.
La replicación de la base de datos requiere conectividad de red para que la réplica se conecte a la base de datos principal y comience la replicación. Para exponer el extremo de la base de datos principal para la replicación, usamos Cloud Service Mesh para crear una malla de servicios de Ingress que admita la finalización de TLS en la malla de servicios, de manera similar a cómo controlamos la transferencia de datos HTTPS en la aplicación web del sistema de tickets.