광학 문자 인식 (OCR)은 Google Distributed Cloud (GDC) 에어갭에 있는 세 가지 Vertex AI 사전 학습 API 중 하나입니다. OCR 서비스는 이미지, 문서 파일, 필기 텍스트와 같은 다양한 파일 형식의 텍스트를 감지합니다.
OCR은 Distributed Cloud에서 텍스트를 인식하는 데 사용할 수 있는 다음 메서드를 제공합니다.
| 메서드 | 설명 |
|---|---|
BatchAnnotateImages |
인라인 요청에 제공된 JPEG 또는 PNG 이미지 배치에서 텍스트를 감지합니다. |
BatchAnnotateFiles |
인라인 요청에 제공된 PDF 또는 TIFF 파일 배치에서 텍스트를 감지합니다. |
AsyncBatchAnnotateFiles |
오프라인 요청을 위해 스토리지 버킷에 있는 PDF 또는 TIFF 파일의 텍스트를 감지합니다. |
텍스트 인식 기능에서 감지하는 지원되는 언어에 대해 자세히 알아보세요.
광학 문자 인식 기능
OCR API는 이미지에서 텍스트를 감지하고 추출할 수 있습니다. 다음 두 가지 주석 기능은 광학 문자 인식을 지원합니다.
TEXT_DETECTION은 임의의 이미지에서 텍스트를 감지하고 추출합니다. 예를 들어 간판이나 표지판이 찍힌 사진을 들 수 있습니다. OCR 서비스는 추출된 문자열, 개별 단어, 해당 경계 상자가 포함된 JSON 파일을 반환합니다.
그림 1. OCR API가 단어와 해당 경계 상자를 감지하는 도로 표지판 사진
DOCUMENT_TEXT_DETECTION도 이미지에서 텍스트를 추출하지만, 서비스는 밀집된 텍스트와 문서에 맞게 응답을 최적화합니다. 예를 들어 입력된 텍스트를 스캔한 이미지에는 여러 단락과 제목이 포함될 수 있습니다. OCR 서비스는 페이지, 블록, 단락, 단어, 줄바꿈 정보가 포함된 JSON 파일을 반환합니다.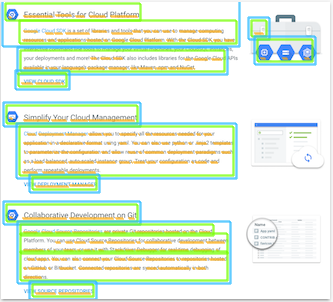
그림 2. OCR API가 단어, 페이지, 단락과 같은 정보를 감지하는 입력된 텍스트의 스캔된 이미지
손글씨 텍스트
그림 3은 손으로 쓴 텍스트의 이미지입니다. OCR API는 이러한 이미지에서 텍스트를 감지하고 추출합니다. 필기 인식을 지원하는 필기 스크립트 목록은 필기 스크립트를 참고하세요.

그림 3. OCR API가 텍스트를 감지하는 필기 이미지
광학 문자 인식 한도
BatchAnnotateImages 및 BatchAnnotateFiles API 메서드는 일괄 호출당 단일 요청만 지원합니다.
다음 표에는 Distributed Cloud의 OCR 서비스의 현재 한도가 나와 있습니다.
| OCR 파일 한도 | 값 |
|---|---|
| 최대 페이지 수 | 5개 |
| 최대 파일 크기 | 20MB |
| 최대 이미지 크기 | 2천만 픽셀 (길이 x 너비) |
OCR API에 제출된 파일이 최대 페이지 수 또는 최대 파일 크기를 초과하면 오류가 반환됩니다. 최대 이미지 크기를 초과하는 제출된 파일은 2,000만 픽셀로 축소됩니다.
OCR에 지원되는 파일 형식
OCR 사전 학습된 API는 다음 파일 형식의 텍스트를 감지하고 전사합니다.
- TIFF
- JPG
- PNG
Distributed Cloud 환경에 파일을 로컬로 저장해야 합니다. Cloud Storage에 호스팅된 파일이나 공개적으로 사용 가능한 파일에 액세스하여 텍스트를 감지할 수는 없습니다.