Log e metriche ti consentono di monitorare i servizi e risolvere i problemi relativi alle prestazioni del servizio. Puoi visualizzare i log e le metriche dei servizi Vertex AI utilizzando le risorse di monitoraggio e logging di Google Distributed Cloud (GDC) air-gapped. Puoi anche creare query per monitorare metriche Vertex AI specifiche.
Questa pagina descrive come eseguire query e visualizzare log e metriche dei servizi Vertex AI in l'istanza di monitoraggio di Distributed Cloud.
Questa pagina contiene anche query di esempio che puoi utilizzare per monitorare la piattaforma e i servizi Vertex AI, come il riconoscimento ottico dei caratteri (OCR), Speech-to-Text e Vertex AI Translation. Per ulteriori informazioni sulle soluzioni di logging e monitoraggio in Distributed Cloud, consulta Monitorare metriche e log.
Prima di iniziare
Per ottenere le autorizzazioni necessarie per visualizzare log e metriche da
Vertex AI, chiedi all'amministratore IAM del progetto di concederti il ruolo
Visualizzatore Grafana progetto (project-grafana-viewer) nello spazio dei nomi del progetto.
Per saperne di più su questo ruolo, consulta Preparare le autorizzazioni IAM.
Visualizzare log e metriche nelle dashboard
Puoi visualizzare le metriche e i log di Vertex AI nelle dashboard. Ad esempio, puoi creare una query per visualizzare l'impatto di Vertex AI sull'utilizzo della CPU.
Per visualizzare i log e le metriche di Vertex AI nelle dashboard:
Nel menu di navigazione, fai clic su Vertex AI > API preaddestrate.
Nella pagina API preaddestrate, assicurati che l'API Vertex AI per il servizio che vuoi monitorare sia abilitata.
Fai clic su Monitora i servizi in Grafana per aprire la home page di Grafana.
Nel menu di navigazione della home page, fai clic su Esplora Esplora per aprire la pagina Esplora.
Nel menu della pagina Esplora, seleziona una delle seguenti origini dati:
- Log operativi: recupera i log operativi.
- Audit log: recupera i log di controllo.
- Prometheus: recupera le metriche.
Se vuoi visualizzare le metriche, inserisci una query utilizzando le espressioni PromQL (Prometheus Query Language).
Se vuoi visualizzare i log, inserisci una query utilizzando le espressioni LogQL (Log Query Language).
La pagina mostra le metriche o i log corrispondenti alla query.
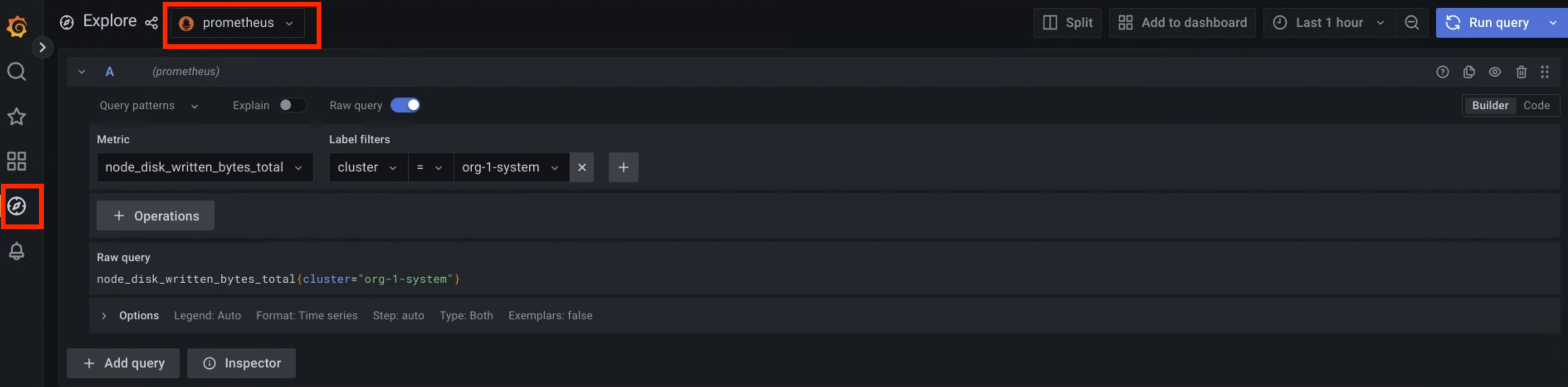
Figura 1. Opzione di menu in Grafana per eseguire query sulle metriche.
Nella figura 1, l'opzione Prometheus mostra l'interfaccia che ti consente di creare query per recuperare le metriche.
Query di esempio
La tabella seguente contiene query di esempio per monitorare la piattaforma Vertex AI nel tuo ambiente:
| Vertex AI Platform | |||
|---|---|---|---|
| Origine dati | Descrizione | Componente | Query |
| Metriche | Percentuale di utilizzo della CPU del container | Operatore di livello 1 | rate(container_cpu_usage_seconds_total{namespace="ai-system",container="l1operator"}[30s]) * 100 |
| Operatore di livello 2 | rate(container_cpu_usage_seconds_total{namespace="ai-system",container="l2operator"}[30s]) * 100 |
||
| Utilizzo della memoria in MB del container | Operatore di livello 1 | container_memory_usage_bytes{namespace="ai-system",container="l1operator"} * 1e-6 |
|
| Operatore di livello 2 | container_memory_usage_bytes{namespace="ai-system",container="l2operator"} * 1e-6 |
||
| Log operativi | Log operatore L1 | Operatore di livello 1 | {service_name="vai-l1operator"} |
| Log operatore L2 | Operatore di livello 2 | {service_name="vai-l2operator"} |
|
| Audit log | Log di controllo del frontend della piattaforma | Frontend del plug-in web Vertex AI | {service_name="istio"} |~ upstream_cluster:.*(vai-web-plugin-frontend) |
| Log di controllo del backend della piattaforma | Backend del plug-in web Vertex AI | {service_name="istio"} |~ upstream_cluster:.*(vai-web-plugin-backend) |
|
La seguente tabella contiene query di esempio per monitorare i servizi API Vertex AI, come OCR, Speech-to-Text e Vertex AI Translation, nel tuo ambiente:
| Servizi Vertex AI | |||
|---|---|---|---|
| Origine dati | Descrizione | Servizio | Query |
| Metriche | L'effetto di un'API preaddestrata sull'utilizzo della CPU. |
OCR | rate(container_cpu_usage_seconds_total{namespace="g-vai-ocr-sie",container="CONTAINER_NAME"}[30s]) * 100 CONTAINER_NAME values: vision-extractor | vision-frontend | vision-vms-ocr |
| Speech-to-Text | rate(container_cpu_usage_seconds_total{namespace="g-vai-speech-sie",container="CONTAINER_NAME"}[30s]) * 100 |
||
| Vertex AI Translation | rate(container_cpu_usage_seconds_total{namespace="g-vai-translation-sie",container="CONTAINER_NAME"}[30s]) * 100 CONTAINER_NAME values: translation-aligner | translation-frontend | translation-prediction |
||
Utilizza l'etichetta del filtro destination_service per ottenere il tasso di errore negli ultimi 60 minuti. |
OCR | rate(istio_requests_total{destination_service=~".*g-vai-ocr-sie.svc.cluster.local",response_code=~"[4-5][0-9][0-9]"}[60m]) |
|
| Speech-to-Text | rate(istio_requests_total{destination_service=~".*g-vai-speech-sie.svc.cluster.local",response_code=~"[4-5][0-9][0-9]"}[60m]) |
||
| Vertex AI Translation | rate(istio_requests_total{destination_service=~".*g-vai-translation-sie.svc.cluster.local",response_code=~"[4-5][0-9][0-9]"}[60m]) |
||
| Log operativi | Log operativi dei servizi Vertex AI |
OCR | {namespace="g-vai-ocr-sie"} |
| Speech-to-Text | {namespace="g-vai-speech-sie"} |
||
| Vertex AI Translation | {namespace="g-vai-translation-sie"} |
||
| Audit log | Audit log dei servizi Vertex AI | OCR | {service_name="istio"} |= "vision-frontend-server" |
| Speech-to-Text | {service_name="istio"} |= "speech-frontend-server" |
||
| Vertex AI Translation | {service_name="istio"} |= "translation-frontend-server" |
||